




轉自:https://www.cnkirito.moe/timer/
1 前言
在開始正題之前,先閒聊幾句。有人說,計算機科學這個學科,軟件方向研究到頭就是數學,硬件方向研究到頭就是物理,最輕鬆的是中間這批使用者,可以不太懂物理,不太懂數學,依舊可以使用計算機作爲自己謀生的工具。這個規律具有普適應,看看“定時器”這個例子,往應用層研究,有 Quartz,Spring Schedule 等框架;往分佈式研究,又有 SchedulerX,ElasticJob 等分佈式任務調度;往底層實現看,又有多種定時器實現方案的原理、工作效率、數據結構可以深究…簡單上手使用一個框架,並不能體現出個人的水平,如何與他人構成區分度?我覺得至少要在某一個方向有所建樹:
- 深入研究某個現有框架的實現原理,例如:讀源碼
- 將一個傳統技術在分佈式領域很好地延伸,很多成熟的傳統技術可能在單機 work well,但分佈式場景需要很多額外的考慮。
- 站在設計者的角度,如果從零開始設計一個輪子,怎麼利用合適的算法、數據結構,去實現它。
回到這篇文章的主題,我首先會圍繞第三個話題討論:設計實現一個定時器,可以使用什麼算法,採用什麼數據結構。接着再聊聊第一個話題:探討一些優秀的定時器實現方案。
2 理解定時器
很多場景會用到定時器,例如
- 使用 TCP 長連接時,客戶端需要定時向服務端發送心跳請求。
- 財務系統每個月的月末定時生成對賬單。
- 雙 11 的 0 點,定時開啓秒殺開關。
定時器像水和空氣一般,普遍存在於各個場景中,一般定時任務的形式表現爲:經過固定時間後觸發、按照固定頻率週期性觸發、在某個時刻觸發。定時器是什麼?可以理解爲這樣一個數據結構:
存儲一系列的任務集合,並且 Deadline 越接近的任務,擁有越高的執行優先級
在用戶視角支持以下幾種操作:
NewTask:將新任務加入任務集合
Cancel:取消某個任務
在任務調度的視角還要支持:
Run:執行一個到期的定時任務
判斷一個任務是否到期,基本會採用輪詢的方式, 每隔一個時間片 去檢查 最近的任務 是否到期,並且,在 NewTask 和 Cancel 的行爲發生之後,任務調度策略也會出現調整。
說到底,定時器還是靠線程輪詢實現的。
3 數據結構
我們主要衡量 NewTask(新增任務),Cancel(取消任務),Run(執行到期的定時任務)這三個指標,分析他們使用不同數據結構的時間 / 空間複雜度。
3.1 雙向有序鏈表
在 Java 中,LinkedList 是一個天然的雙向鏈表
NewTask:O(N)
Cancel:O(1)
Run:O(1)
N:任務數
NewTask O(N) 很容易理解,按照 expireTime 查找合適的位置即可;Cancel O(1) ,任務在 Cancel 時,會持有自己節點的引用,所以不需要查找其在鏈表中所在的位置,即可實現當前節點的刪除,這也是爲什麼我們使用雙向鏈表而不是普通鏈表的原因是 ;Run O(1),由於整個雙向鏈表是基於 expireTime 有序的,所以調度器只需要輪詢第一個任務即可。
3.2 堆
在 Java 中,PriorityQueue 是一個天然的堆,可以利用傳入的 Comparator 來決定其中元素的優先級。
NewTask:O(logN)
Cancel:O(logN)
Run:O(1)
N:任務數
expireTime 是 Comparator 的對比參數。NewTask O(logN) 和 Cancel O(logN) 分別對應堆插入和刪除元素的時間複雜度 ;Run O(1),由 expireTime 形成的小根堆,我們總能在堆頂找到最快的即將過期的任務。
堆與雙向有序鏈表相比,NewTask 和 Cancel 形成了 trade off,但考慮到現實中,定時任務取消的場景並不是很多,所以堆實現的定時器要比雙向有序鏈表優秀。
3.3 時間輪
Netty 針對 I/O 超時調度的場景進行了優化,實現了 HashedWheelTimer 時間輪算法。
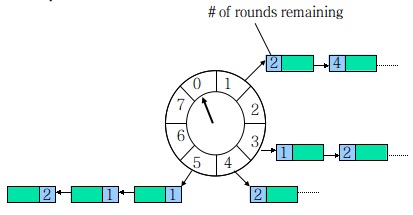
HashedWheelTimer 是一個環形結構,可以用時鐘來類比,鐘面上有很多 bucket ,每一個 bucket 上可以存放多個任務,使用一個 List 保存該時刻到期的所有任務,同時一個指針隨着時間流逝一格一格轉動,並執行對應 bucket 上所有到期的任務。任務通過 取模 決定應該放入哪個 bucket 。和 HashMap 的原理類似,newTask 對應 put,使用 List 來解決 Hash 衝突。
以上圖爲例,假設一個 bucket 是 1 秒,則指針轉動一輪表示的時間段爲 8s,假設當前指針指向 0,此時需要調度一個 3s 後執行的任務,顯然應該加入到 (0+3=3) 的方格中,指針再走 3 次就可以執行了;如果任務要在 10s 後執行,應該等指針走完一輪零 2 格再執行,因此應放入 2,同時將 round(1)保存到任務中。檢查到期任務時只執行 round 爲 0 的, bucket 上其他任務的 round 減 1。
再看圖中的 bucket5,我們可以知道在 $18+5=13s$ 後,有兩個任務需要執行,在 $28+5=21s$ 後有一個任務需要執行。
NewTask:O(1)
Cancel:O(1)
Run:O(M)
Tick:O(1)
M: bucket ,M ~ N/C ,其中 C 爲單輪 bucket 數,Netty 中默認爲 512
時間輪算法的複雜度可能表達有誤,比較難算,僅供參考。另外,其複雜度還受到多個任務分配到同一個 bucket 的影響。並且多了一個轉動指針的開銷。
傳統定時器是面向任務的,時間輪定時器是面向 bucket 的。
構造 Netty 的 HashedWheelTimer 時有兩個重要的參數:tickDuration 和 ticksPerWheel。
tickDuration:即一個 bucket 代表的時間,默認爲 100ms,Netty 認爲大多數場景下不需要修改這個參數;ticksPerWheel:一輪含有多少個 bucket ,默認爲 512 個,如果任務較多可以增大這個參數,降低任務分配到同一個 bucket 的概率。
3.4 層級時間輪
Kafka 針對時間輪算法進行了優化,實現了層級時間輪 TimingWheel
如果任務的時間跨度很大,數量也多,傳統的 HashedWheelTimer 會造成任務的 round 很大,單個 bucket 的任務 List 很長,並會維持很長一段時間。這時可將輪盤按時間粒度分級:
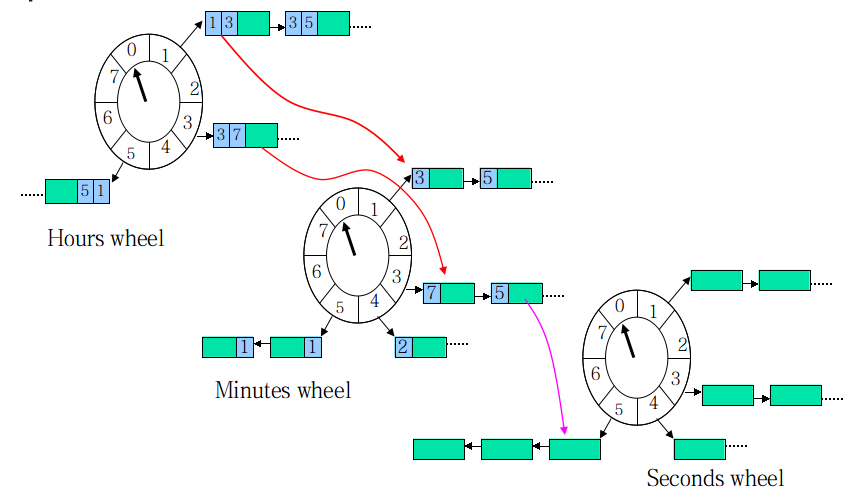
現在,每個任務除了要維護在當前輪盤的 round,還要計算在所有下級輪盤的 round。當本層的 round 爲 0 時,任務按下級 round 值被下放到下級輪子,最終在最底層的輪盤得到執行。
NewTask:O(H)
Cancel:O(H)
Run:O(M)
Tick:O(1)
H:層級數量
設想一下一個定時了 3 天,10 小時,50 分,30 秒的定時任務,在 tickDuration = 1s 的單層時間輪中,需要經過:$3246060+106060+5060+30$ 次指針的撥動才能被執行。但在 wheel1 tickDuration = 1 天,wheel2 tickDuration = 1 小時,wheel3 tickDuration = 1 分,wheel4 tickDuration = 1 秒 的四層時間輪中,只需要經過 $3+10+50+30$ 次指針的撥動!
相比單層時間輪,層級時間輪在時間跨度較大時存在明顯的優勢。
4 常見實現
4.1 Timer
JDK 中的 Timer 是非常早期的實現,在現在看來,它並不是一個好的設計。
|
|
使用 Timer 實現任務調度的核心是 Timer 和 TimerTask。其中 Timer 負責設定 TimerTask 的起始與間隔執行時間。使用者只需要創建一個 TimerTask 的繼承類,實現自己的 run 方法,然後將其丟給 Timer 去執行即可。
|
|
其中 TaskQueue 是使用數組實現的一個簡易的堆。另外一個值得注意的屬性是 TimerThread,Timer 使用唯一的線程負責輪詢並執行任務。Timer 的優點在於簡單易用,但也因爲所有任務都是由同一個線程來調度,因此整個過程是串行執行的,同一時間只能有一個任務在執行,前一個任務的延遲或異常都將會影響到之後的任務。
輪詢時如果發現 currentTime < heapFirst.executionTime,可以 wait(executionTime - currentTime) 來減少不必要的輪詢時間。這是普遍被使用的一個優化。
Timer只能被單線程調度TimerTask中出現的異常會影響到Timer的執行。
由於這兩個缺陷,JDK 1.5 支持了新的定時器方案 ScheduledExecutorService。
4.2 ScheduledExecutorService
|
|
相比 Timer,ScheduledExecutorService 解決了同一個定時器調度多個任務的阻塞問題,並且任務異常不會中斷 ScheduledExecutorService。
ScheduledExecutorService 提供了兩種常用的週期調度方法 ScheduleAtFixedRate 和 ScheduleWithFixedDelay。
ScheduleAtFixedRate 每次執行時間爲上一次任務開始起向後推一個時間間隔,即每次執行時間爲 : $initialDelay$, $initialDelay+period$, $initialDelay+2*period$, …
ScheduleWithFixedDelay 每次執行時間爲上一次任務結束起向後推一個時間間隔,即每次執行時間爲:$initialDelay$, $initialDelay+executeTime+delay$, $initialDelay+2executeTime+2delay$, …
由此可見,ScheduleAtFixedRate 是基於固定時間間隔進行任務調度,ScheduleWithFixedDelay 取決於每次任務執行的時間長短,是基於不固定時間間隔的任務調度。
ScheduledExecutorService 底層使用的數據結構爲 PriorityQueue,任務調度方式較爲常規,不做特別介紹。
4.3 HashedWheelTimer
|
|
前面已經介紹過了 Netty 中 HashedWheelTimer 內部的數據結構,默認構造器會配置輪詢週期爲 100ms,bucket 數量爲 512。其使用方法和 JDK 的 Timer 十分相似。
|
|
由於篇幅限制,我並不打算做詳細的源碼分析,但上述兩行來自 HashedWheelTimer 的代碼闡釋了一個事實:HashedWheelTimer 內部也同樣是使用單個線程進行任務調度。與 JDK 的 Timer 一樣,存在”前一個任務執行時間過長,影響後續定時任務執行“的問題。
理解 HashedWheelTimer 中的 ticksPerWheel,tickDuration,對二者進行合理的配置,可以使得用戶在合適的場景得到最佳的性能。
5 最佳實踐
5.1 選擇合適的定時器
毋庸置疑,JDK 的 Timer 使用的場景是最窄的,完全可以被後兩者取代。如何在 ScheduledExecutorService 和 HashedWheelTimer 之間如何做選擇,需要區分場景,做一個簡單的對比:
ScheduledExecutorService是面向任務的,當任務數非常大時,使用堆 (PriorityQueue) 維護任務的新增、刪除會導致性能下降,而HashedWheelTimer面向 bucket,設置合理的 ticksPerWheel,tickDuration ,可以不受任務量的限制。所以在任務非常多時,HashedWheelTimer可以表現出它的優勢。- 相反,如果任務量少,
HashedWheelTimer內部的 Worker 線程依舊會不停的撥動指針,雖然不是特別消耗性能,但至少不能說:HashedWheelTimer一定比ScheduledExecutorService優秀。 HashedWheelTimer由於開闢了一個 bucket 數組,佔用的內存會稍大。
上述的對比,讓我們得到了一個最佳實踐:在任務非常多時,使用 HashedWheelTimer 可以獲得性能的提升。例如服務治理框架中的心跳定時任務,服務實例非常多時,每一個客戶端都需要定時發送心跳,每一個服務端都需要定時檢測連接狀態,這是一個非常適合使用 HashedWheelTimer 的場景。
5.2 單線程與業務線程池
我們需要注意 HashedWheelTimer 使用單線程來調度任務,如果任務比較耗時,應當設置一個業務線程池,將 HashedWheelTimer 當做一個定時觸發器,任務的實際執行,交給業務線程池。
如果所有的任務都滿足: taskNStartTime - taskN-1StartTime > taskN-1CostTime,即任意兩個任務的間隔時間小於先執行任務的執行時間,則無需擔心這個問題。
5.3 全局定時器
實際使用 HashedWheelTimer 時, 應當將其當做一個全局的任務調度器,例如設計成 static 。時刻謹記一點:HashedWheelTimer 對應一個線程,如果每次實例化 HashedWheelTimer,首先是線程會很多,其次是時間輪算法將會完全失去意義。
5.4 爲 HashedWheelTimer 設置合理的參數
ticksPerWheel,tickDuration 這兩個參數尤爲重要,ticksPerWheel 控制了時間輪中 bucket 的數量,決定了衝突發生的概率,tickDuration 決定了指針撥動的頻率,一方面會影響定時的精度,一方面決定 CPU 的消耗量。當任務數量非常大時,考慮增大 ticksPerWheel;當時間精度要求不高時,可以適當加大 tickDuration,不過大多數情況下,不需要 care 這個參數。
5.5 什麼時候使用層級時間輪
當時間跨度很大時,提升單層時間輪的 tickDuration 可以減少空轉次數,但會導致時間精度變低,層級時間輪既可以避免精度降低,又避免了指針空轉的次數。如果有時間跨度較長的定時任務,則可以交給層級時間輪去調度。此外,也可以按照定時精度實例化多個不同作用的單層時間輪,dayHashedWheelTimer、hourHashedWheelTimer、minHashedWheelTimer,配置不同的 tickDuration,此法雖 low,但不失爲一個解決方案。Netty 設計的 HashedWheelTimer 是專門用來優化 I/O 調度的,場景較爲侷限,所以並沒有實現層級時間輪;而在 Kafka 中定時器的適用範圍則較廣,所以其實現了層級時間輪,以應對更爲複雜的場景。