




0. 前言
動態查找樹主要有:二叉查找樹、平衡二叉樹、紅黑樹、B樹、B+樹。前面三種是典型的二叉查找樹,查找的時間複雜度是O(log2N)。涉及到磁盤的讀寫(比如每個節點都需要從磁盤獲取),讀寫的速度就與樹的深度有關係,那麼降低樹的深度也就可以提升查找效率。這時就提出了平衡多路查找樹,也就是B樹以及B+樹。
B樹和B+樹非常典型的場景就是用於關係型數據庫的索引(MySQL)
1. B類樹
1.2. B 樹
B樹是一種平衡多路搜索樹,B樹與紅黑樹最大的不同在於,B樹的結點可以有多個子女,從幾個到幾千個。那爲什麼又說B樹與紅黑樹很相似呢?因爲與紅黑樹一樣,一棵含n個結點的B樹的高度也爲O(l ogn),但可能比一棵紅黑樹的高度小許多,因爲它的分支因子比較大。所以,B樹可以在O(logn)時間內,實現各種如插入(insert),刪除(delete)等動態集合操作。
B樹的定義如下:
根節點至少有兩個子節點
每個節點有M-1個key,並且以升序排列
位於M-1和M key的子節點的值位於M-1 和M key對應的Value之間
其它節點至少有M/2個子節點
所有葉子結點位於同一層;
下圖是一個M=4的4階的B樹:

4階 B 樹
B樹的搜索:從根結點開始,對結點內的關鍵字(有序)序列進行二分查找,如果命中則結束,否則進入查詢關鍵字所屬範圍的兒子結點;重複,直到所對應的兒子指針爲空,或已經是葉子結點;
B樹的特性:
關鍵字集合分佈在整顆樹中;
任何一個關鍵字出現且只出現在一個結點中;
搜索有可能在非葉子結點結束(樹中所有結點都存儲數據,與B+樹這一點不同);
其搜索性能等價於在關鍵字全集內做一次二分查找;
1.2. B+樹
B+樹是對B樹的一種變形,與B樹的差異在於:
有n棵子樹的結點中含有n個關鍵字,每個關鍵字不保存數據,只用來索引,所有數據都保存在葉子節點。
所有的葉子結點中包含了全部關鍵字的信息,及指向含這些關鍵字記錄的指針,且葉子結點本身依關鍵字的大小自小而大順序鏈接。
所有的非終端結點可以看成是索引部分,結點中僅含其子樹(根結點)中的最大(或最小)關鍵字。
爲所有葉子結點增加一個鏈指針,便於區間查找和遍歷。
所有關鍵字都在葉子結點出現。

B+樹
B+樹的搜索:與B-樹也基本相同,區別是B+樹只有達到葉子結點才命中(B-樹可以在非葉子結點命中),其性能也等價於在關鍵字全集做一次二分查找;
B+的特性:
非葉子結點相當於是葉子結點的索引(稀疏索引),葉子結點相當於是存儲(關鍵字)數據的數據層;
B+樹的葉子結點都是相鏈的,因此對整棵樹的遍歷只需要一次線性遍歷葉子結點即可。而且由於數據順序排列並且相連,所以便於區間查找和搜索。而B樹則需要進行每一層的遞歸遍歷。相鄰的元素可能在內存中不相鄰,所以緩存命中性沒有B+樹好。
B+樹的分裂:
當一個結點滿時,分配一個新的結點,並將原結點中1/2的數據複製到新結點,最後在父結點中增加新結點的指針;
B+樹的分裂隻影響原結點和父結點,而不會影響兄弟結點,所以它不需要指向兄弟的指針。
1.3. B*樹
B*樹是B+樹的變體,在B+樹的非根和非葉子結點再增加指向兄弟的指針;

B*樹的分裂:
當一個結點滿時,如果它的下一個兄弟結點未滿,那麼將一部分數據移到兄弟結點中,再在原結點插入關鍵字,最後修改父結點中兄弟結點的關鍵字(因爲兄弟結點的關鍵字範圍改變了);
如果兄弟也滿了,則在原結點與兄弟結點之間增加新結點,並各複製1/3的數據到新結點,最後在父結點增加新結點的指針。
1.4. B 樹、 B+樹、B*樹總結和對比
B樹:多路搜索樹,每個結點存儲M/2到M個關鍵字,非葉子結點存儲指向關鍵字範圍的子結點;所有關鍵字在整顆樹中出現,且只出現一次,非葉子結點可以命中;
B+樹:在B-樹基礎上,爲葉子結點增加鏈表指針,所有關鍵字都在葉子結點中出現,非葉子結點作爲葉子結點的索引;B+樹總是到葉子結點才命中;
B*樹:在B+樹基礎上,爲非葉子結點也增加鏈表指針,將結點的最低利用率從1/2提高到2/3;
B+樹雖然優點很多,但是B樹也有優點,其優點在於,由於B樹的每一個節點都包含key和value,因此經常訪問的元素可能離根節點更近,因此訪問也更迅速。下面是B 樹和B+樹的區別圖:

B 樹和 B+樹對比
爲什麼說B+tree比B樹更適合實際應用中操作系統的文件索引和數據庫索引?
B+tree的磁盤讀寫代價更低
B+tree的內部結點並沒有指向關鍵字具體信息的指針。因此其內部結點相對B樹更小。如果把所有同一內部結點的關鍵字存放在同一盤塊中,那麼盤塊所能容納的關鍵字數量也越多。一次性讀入內存中的需要查找的關鍵字也就越多。相對來說IO讀寫次數也就降低了。舉個例子,假設磁盤中的一個盤塊容納16bytes,而一個關鍵字2bytes,一個關鍵字具體信息指針2bytes。一棵9階B-tree(一個結點最多8個關鍵字)的內部結點需要2個盤快。而B+ 樹內部結點只需要1個盤快。當需要把內部結點讀入內存中的時候,B 樹就比B+ 樹多一次盤塊查找時間(在磁盤中就是盤片旋轉的時間)。
B+tree的查詢效率更加穩定
由於非葉子結點並不是最終指向文件內容的結點,而只是葉子結點中關鍵字的索引。所以任何關鍵字的查找必須走一條從根結點到葉子結點的路。所有關鍵字查詢的路徑長度相同,導致每一個數據的查詢效率相當。B樹在提高了磁盤IO性能的同時並沒有解決元素遍歷的效率低下的問題。正是爲了解決這個問題,B+樹應運而生。B+樹只要遍歷葉子節點就可以實現整棵樹的遍歷。而且在數據庫中基於範圍的查詢是非常頻繁的,而B樹不支持這樣的操作(或者說效率太低)。
2. LSM 樹
目前常見的主要的三種存儲引擎是:哈希、B+樹、LSM樹:
哈希存儲引擎:是哈希表的持久化實現,支持增、刪、改以及隨機讀取操作,但不支持順序掃描,對應的存儲系統爲key-value存儲系統。對於key-value的插入以及查詢,哈希表的複雜度都是O(1),明顯比樹的操作O(n)快,如果不需要有序的遍歷數據,哈希表性能最好。
B+樹存儲引擎是B+樹的持久化實現,不僅支持單條記錄的增、刪、讀、改操作,還支持順序掃描(B+樹的葉子節點之間的指針),對應的存儲系統就是關係數據庫(Mysql等)。
LSM樹(Log-Structured MergeTree)存儲引擎和B+樹存儲引擎一樣,同樣支持增、刪、讀、改、順序掃描操作。而且通過批量存儲技術規避磁盤隨機寫入問題。當然凡事有利有弊,LSM樹和B+樹相比,LSM樹犧牲了部分讀性能,用來大幅提高寫性能。
上面三種引擎中,LSM樹存儲引擎的代表數據庫就是HBase.
LSM樹核心思想的核心就是放棄部分讀能力,換取寫入的最大化能力。LSM Tree ,這個概念就是結構化合並樹的意思,它的核心思路其實非常簡單,就是假定內存足夠大,因此不需要每次有數據更新就必須將數據寫入到磁盤中,而可以先將最新的數據駐留在內存中,等到積累到足夠多之後,再使用歸併排序的方式將內存內的數據合併追加到磁盤隊尾(因爲所有待排序的樹都是有序的,可以通過合併排序的方式快速合併到一起)。
日誌結構的合併樹(LSM-tree)是一種基於硬盤的數據結構,與B+tree相比,能顯著地減少硬盤磁盤臂的開銷,並能在較長的時間提供對文件的高速插入(刪除)。然而LSM-tree在某些情況下,特別是在查詢需要快速響應時性能不佳。通常LSM-tree適用於索引插入比檢索更頻繁的應用系統。
LSM樹和B+樹的差異主要在於讀性能和寫性能進行權衡。在犧牲的同時尋找其餘補救方案:
LSM具有批量特性,存儲延遲。當寫讀比例很大的時候(寫比讀多),LSM樹相比於B樹有更好的性能。因爲隨着insert操作,爲了維護B+樹結構,節點分裂。讀磁盤的隨機讀寫概率會變大,性能會逐漸減弱。
B樹的寫入過程:對B樹的寫入過程是一次原位寫入的過程,主要分爲兩個部分,首先是查找到對應的塊的位置,然後將新數據寫入到剛纔查找到的數據塊中,然後再查找到塊所對應的磁盤物理位置,將數據寫入去。當然,在內存比較充足的時候,因爲B樹的一部分可以被緩存在內存中,所以查找塊的過程有一定概率可以在內存內完成,不過爲了表述清晰,我們就假定內存很小,只夠存一個B樹塊大小的數據吧。可以看到,在上面的模式中,需要兩次隨機尋道(一次查找,一次原位寫),才能夠完成一次數據的寫入,代價還是很高的。
LSM優化方式:
a. Bloom filter: 就是個帶隨機概率的bitmap,可以快速的告訴你,某一個小的有序結構裏有沒有指定的那個數據的。於是就可以不用二分查找,而只需簡單的計算幾次就能知道數據是否在某個小集合裏啦。效率得到了提升,但付出的是空間代價。
b. compact:小樹合併爲大樹:因爲小樹性能有問題,所以要有個進程不斷地將小樹合併到大樹上,這樣大部分的老數據查詢也可以直接使用log2N的方式找到,不需要再進行(N/m)*log2n的查詢了
B樹存儲引擎是B樹的持久化實現,不僅支持單條記錄的增、刪、讀、改操作,還支持順序掃描(B+樹的葉子節點之間的指針),對應的存儲系統就是關係數據庫(Mysql等)。
LSM樹(Log-Structured Merge Tree)存儲引擎和B樹存儲引擎一樣,同樣支持增、刪、讀、改、順序掃描操作。而且通過批量存儲技術規避磁盤隨機寫入問題。當然凡事有利有弊,LSM樹和B+樹相比,LSM樹犧牲了部分讀性能,用來大幅提高寫性能。
LSM樹的設計思想非常樸素:將對數據的修改增量保持在內存中,達到指定的大小限制後將這些修改操作批量寫入磁盤,不過讀取的時候稍微麻煩,需要合併磁盤中歷史數據和內存中最近修改操作,所以寫入性能大大提升,讀取時可能需要先看是否命中內存,否則需要訪問較多的磁盤文件。極端的說,基於LSM樹實現的HBase的寫性能比Mysql高了一個數量級,讀性能低了一個數量級。
LSM樹原理把一顆大叔拆分成N顆小樹,它首先在內存中,它首先寫入內存中,隨着小樹越來越大,內存中的小樹會flush到磁盤中,磁盤中的樹定期可以做merge操作,合併成爲一個大樹,用來優化讀性能。
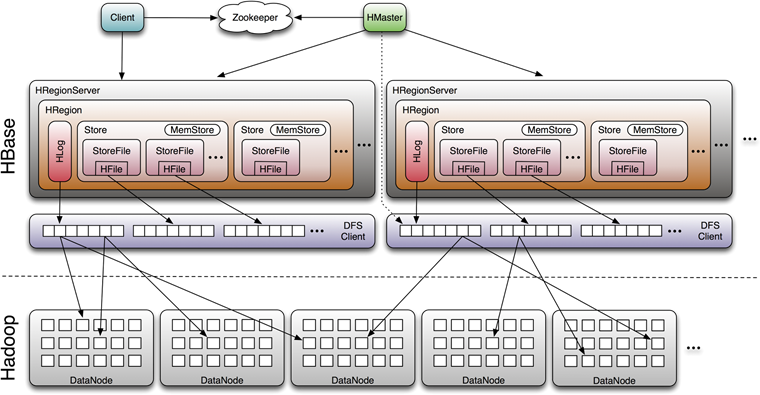
以上就是hbase存儲設計的重要思想,這裏說明一下:
因爲數據是先寫到內存中,所以爲了防止內存數據丟失,會先把數據寫入hlog中,也符合了數據庫中標準,先寫日誌,再寫數據
memstore上的樹達到一定大小之後,需要flush到磁盤中,然後再定期做合併,提高讀取的性能;
關於LSM Tree,對於最簡單的二層lsm而言。

lsm tree,理論上,可以是內存中樹的一部分和磁盤中一層數做merge,對於磁盤中的樹直接做update操作有可能會破壞物理block的連續性,在實際場景中,一般lsm有多層,當磁盤中的小樹合併成爲一個大樹的時候,可以重新排好順序,使block連續,優化讀性能。
hbase在視線中,是把整個內存在一定閾值後,flush到disk中,形成一個hfile文件。這個file的存儲也是一個小的b+樹,因爲hbase是存儲在hdfs上,hdfs不支持更新操作,所以hbase的數據也是定期flush到磁盤中,而不是和文件中的hfile做合併操作。
------------------------------------------------------------------------
原文作者:GOGOYAO
鏈接:https://www.jianshu.com/p/3fb899684392