




Kafka快速入門(二)——Kafka架構
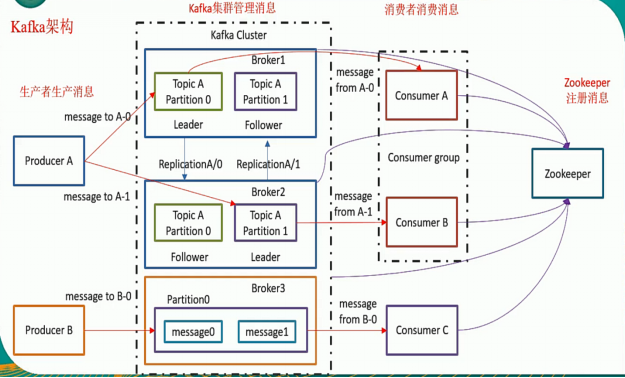
一、Kafka架構簡介
1、Kafka架構簡介
2、Record
Record即Kafka消息,是Kafka處理的主要對象。
3、Topic
Topic是承載Kafka消息數據的邏輯容器,用於區分具體的業務,但在物理上,不同Topic的消息分開存儲,邏輯上一個Topic的消息雖然保存在一個或多個Broker上,但用戶只需指定消息的Topic即可生產或消費數據而不必關心數據存儲在何處。
4、Partition
Topic被分割爲一個或多個Partition,Partition是一個物理概念,對應一個或若干個目錄。Partition內部的消息是有序的,Partition間的消息是無序的。
Kafka Broker配置文件中的num.partitions參數用於指定Topic的Partition數量,在創建Topic時也可以通過partitions參數指定Partition數量。
5、Broker
Kafka集羣包含一個或多個服務器,每個服務器節點稱爲一個Broker。
Broker存儲Topic的數據。如果某Topic有N個Partition,集羣有N個Broker,那麼每個Broker存儲該Topic的一個Partition。
如果某Topic有N個Partition,集羣有(N+M)個Broker,那麼其中有N個Broker各存儲Topic的一個Partition,剩下的M個Broker不存儲Topic的Partition數據。
如果某Topic有N個Partition,集羣中Broker數目少於N個,那麼每個Broker存儲Topic的一個或多個Partition。實際生產環境中應儘量避免,否則容易導致Kafka集羣數據不均衡。
6、Producer
Producer(生產者)是消息的發佈者,生產者負責選擇將消息數據分配給Topic中的某個分區,即生產者生產的每一條消息,會被寫入到某一個Partition。
7、Consumer
Consumer(消費者)從Broker中消費消息,一個Consumer可以消費多個Topic的消息,也可以消費同一個Topic中的多個Partition中的消息,Partition允許多個Consumer同時消費,提高Kafka Broker的吞吐量。
8、Consumer Group
Consumer Group是Kafka提供的可擴展且具有容錯性的消費者機制,多個消費者實例共同組成的一個組,同時消費多個分區以實現高吞吐。Consumer Group內可以有多個消費者,共享一個公共的ID,即Group ID,Consumer Group內的所有消費者協調在一起來消費訂閱Topic的所有分區。
Kafka保證同一個Consumer Group中只有一個Consumer會消費某條消息,Kafka保證的是穩定狀態下每一個Consumer 實例只會消費某一個或多個特定的Partition,而某個Partition的數據只會被某一個特定的Consumer實例所消費。
兩臺Broker組成的Kafka羣集,包含四個屬於兩個Consumer Group的分區(P0-P3)。Consumer Group A有兩個消費者實例,Consumer Group B有四個消費者實例。
Consumers使用Consumer Group的名字來標識自己,並且每個發佈到Topic的消息(Record)都會被傳遞到每個Consumer Group中的一個消費者實例,消費者實例可以在單獨的進程中或者在不同的機器中。
如果所有消費者實例都劃分到一個Consumer Group中,那麼消息將會輪流被Consumer Group中的消費者消費,即單播;如果所有的消費者實例都在不同的Consumer Group中,那麼每一條消息都會被所有的消費者消費,即廣播。
Consumer Group包含Consumer的數量可以預先在配置文件中配置。多個Consumer可以組成一個Consumer Group,Partition中的每一條消息只能被一個Consumer Group中的一個Consumer進行消費,其它Consumer不能消費同一個Topic中同一個Partition的數據,不同Consumer Group的Consumer可以消費同一個Topic的同一個Partition的數據。
9、Replica
Replica(分區副本)是一個分區的備份,是爲了防止消息丟失而創建的分區備份。Kafka中同一條消息能夠被拷貝到多個地方以提供數據冗餘。副本分爲領導者副本和追隨者副本,各自有不同的角色劃分。副本是在分區層級下的,即每個分區可配置多個副本實現高可用。
10、Partition Leader
每個Partition有多個副本,其中有且僅有一個作爲Leader,Leader是當前負責消息讀寫的Partition,所有讀寫操作只能發生於Leader分區上。
11、Partition Follower
所有Follower都需要從Leader同步消息,Follower與Leader始終保持消息同步。Leader與Follower的關係是主備關係,而非主從關係。
12、Zookeeper
Apache Zookeeper是一個分佈式配置和同步服務,是Apache Kafka的一個關鍵依賴,是Kafka Broker和Consumer之間的協調接口。Kafka Broker通過Zookeeper集羣共享信息,Kafka Broker在Zookeeper中存儲基本元數據,例如關於主題、代理、消費者偏移(隊列讀取器)等的信息。Zookeeper負責維護和協調Kafka Broker以及Broker Controller的選舉。
Kafka 0.9版本前,offset由Zookeeper負責管理。
二、Kafka分區機制
1、分區機制簡介
分區機制指的是將每個Topic劃分成多個分區(Partition),每個分區是一組有序的消息日誌。生產者生產的每條消息只會被髮送到一個分區中。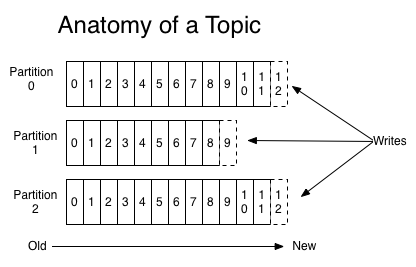
對每個 Topic,Kafka集羣維護了一個分區的記錄(log),分區 (Partition) 都是一個有序的、不可變的數據序列,消息數據被不斷的添加到序列的尾部。分區中的每一條消息數據都被賦予了一個連續的數字ID,即偏移量 (offset) ,用於唯一標識分區中的每條消息數據。
分區的作用就是提供負載均衡的能力,實現系統的高伸縮性(Scalability)。不同的分區能夠被放置到不同節點的機器上,而數據的讀寫操作也都是針對分區進行的,每個節點的機器都能獨立地執行各自分區的讀寫請求處理,同時可以通過添加新的節點機器來增加整體系統的吞吐量。
2、消息位移
Offset(消息位移)是消息在分區內的偏移量。每條消息都有一個當前Partition下唯一的64字節的消息位移,是相對於當前分區第一條消息的偏移量。
3、Log Segment機制
Kafka使用消息日誌(Log)來保存數據,日誌是磁盤上一個只能追加寫(Append-only)消息的物理文件。因爲只能追加寫入,因此避免了緩慢的隨機I/O操作,改爲性能較好的順序I/O寫操作。Kafka通過日誌段(Log Segment)機制定期地刪除消息以回收磁盤。Kafka日誌文件分爲多個日誌段,消息被追加寫到當前最新的日誌段中,當寫滿了一個日誌段後,Kafka會自動切分出一個新的日誌段,並將舊的日誌段封存。Kafka在後臺會定期地檢查舊的日誌段是否能夠被刪除,從而實現回收磁盤空間的目的。
Kafka將消息數據根據Partition進行存儲,Partition分爲若干Segment,每個Segment的大小相等。
Segment由index file 和 data file組成,後綴爲".index"和".log",分別表示爲Segment索引文件、數據文件,每一個Segment存儲着多條信息。
Segment文件的生命週期由Broker配置參數決定,默認24x7小時後刪除。
依據Kafka消息在分區的全局offset,可以使用二分查找算法查找到相應的Segment的.index索引文件和.log數據文件; 根據索引文件找到消息在分區的邏輯偏移量和物理地址偏移量,並取出消息數據。
4、分區策略
分區策略是決定生產者將消息發送到哪個分區的算法。Kafka提供默認的分區策略,同時支持自定義分區策略。如果要自定義分區策略,需要顯式地配置生產者端的參數partitioner.class。編寫生產者程序時,可以編寫一個具體的類實現org.apache.kafka.clients.producer.Partitioner接口(partition()和close()),通常只需要實現最重要的partition方法。
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
topic、key、keyBytes、value和valueBytes都屬於消息數據,cluster則是集羣信息(比如當前Kafka集羣共有多少主題、多少Broker等)。設置partitioner.class參數爲自己實現類的Full Qualified Name,生產者程序就會按照自定義分區策略的代碼邏輯對消息進行分區。
5、輪詢策略
輪詢策略(Round-robin),即順序分配策略。如果一個Topic有3個分區,則第1條消息被髮送到分區0,第2條被髮送到分區1,第3條被髮送到分區2,以此類推。當生產第4條消息時又會重新輪詢將其分配到分區0。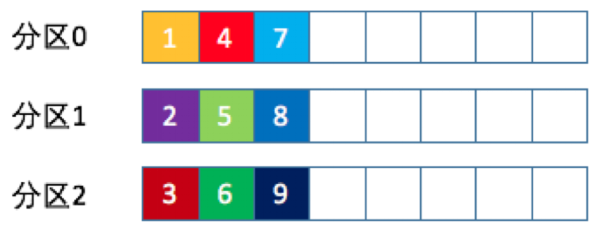
輪詢策略是Kafka Java生產者API默認提供的分區策略。如果未指定partitioner.class參數,那麼生產者程序會按照輪詢的方式在Topic的所有分區間均勻地存儲消息。輪詢策略有非常優秀的負載均衡表現,能保證消息最大限度地被平均分配到所有分區上。
6、隨機策略
隨機策略(Randomness)是將消息隨機地放置到任意一個分區上。
如果要實現隨機策略版的partition方法,Java版如下:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());先計算出Topic的總分區數,然後隨機地返回一個小於分區數的正整數。隨機策略本質上是力求將數據均勻地分散到各個分區,但實際表現要遜於輪詢策略,如果追求數據的均勻分佈,推薦使用輪詢策略。
7、按消息鍵保序策略
Kafka允許爲每條消息定義消息鍵,簡稱爲Key。Key可以是一個有着明確業務含義的字符串,如客戶代碼、部門編號或是業務ID等,也可以用來表徵消息元數據。一旦消息被定義了Key,就可以保證同一個Key的所有消息都進入到相同的分區中。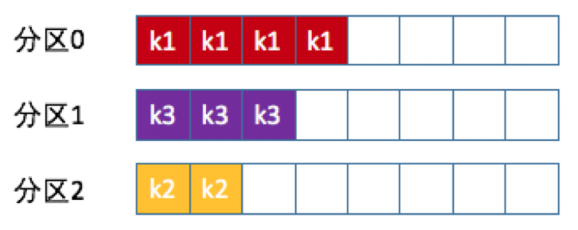
實現分區策略的partition方法只需要兩行代碼即可:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return Math.abs(key.hashCode()) % partitions.size();Kafka 默認分區策略同時實現了兩種策略:如果指定Key,那麼默認實現按消息鍵保序策略;如果沒有指定Key,則使用輪詢策略。
8、基於地理位置的分區策略
基於地理位置的分區策略通常只針對大規模的Kafka集羣,特別是跨城市、跨國家甚至跨大洲的集羣。假設天貓計劃爲每個新註冊用戶提供一份註冊禮品,比如歐美的用戶註冊天貓時可以免費得到一臺iphone SE手機,而中國的新註冊用戶可以得到一臺華爲P40 Pro。爲了實現相應的註冊業務邏輯,只需要創建一個雙分區的主題,然後再創建兩個消費者程序分別處理歐美和中國用戶的註冊用戶邏輯即可,同時必須把不同地理位置的用戶註冊的消息發送到不同機房中,因爲處理註冊消息的消費者程序只可能在某一個機房中啓動着。基於地理位置的分區策略可以根據Broker的IP地址實現定製化的分區策略。
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return partitions.stream().filter(p -> isChina(p.leader().host())).map(PartitionInfo::partition).findAny().get();可以從所有分區中找出Leader副本在中國的所有分區,然後隨機挑選一個進行消息發送。
9、消息保序
爲了實現消息保序,可以將Topic設置成單分區,單分區的Topic的所有的消息都只在一個分區內讀寫,保證全局的順序性,但會喪失Kafka多分區帶來的高吞吐量和負載均衡的性能優勢。
實現消息保序的另一種方式是按消息鍵保序策略。通過對具體業務進行分析,提取出需要保序的消息的邏輯主體並建立消息標誌位ID,
對標誌位設定專門的分區策略,保證同一標誌位的所有消息都發送到同一分區,既可以保證分區內的消息順序,也可以享受到多分區帶來的搞吞吐量。
消息重試只是簡單將消息重新發送到原來的分區,不會重新選擇分區。
10、消息生產過程
生產者生產消息,將消息發送給Broker並形成可供消費者消費的消息數據的過程如下:
(1)Producer先從Zookeeper中找到Partition的Leader
(2)Producer將消息發送給分區的Leader。
(3)Leader將消息接入本地的Log,並通知ISR的Followers。
(4)ISR中的Followers從Leader中pull消息,寫入本地Log後向Leader發送ACK。
(5)Leader收到所有ISR中的Followers的ACK後,增加HW並向Producer發送ACK,表示消息寫入成功。
11、消息路由策略
在通過API方式發佈消息時,生產者是以Record爲消息進行發佈的。Record中包含key與value,value纔是消息本身,而key用於路由消息所要存放Partition。消息要寫入到哪個Partition並不是隨機的,而是由路由策略決定。
(1)如果指定了Partition,則直接寫入到指定的Partition。
(2)如果沒有指定Partition但指定了key,則通過對key的hash值與Partition數量取模,結果就是要選出的Partition索引。
(3)如果Partition和key都未指定,則使用輪詢算法選出一個Partition。
(4)增加分區時,Partition內的消息不會重新進行分配,隨着數據繼續寫入,新分區纔會參與再平衡。
三、Kafka Consumer Group
1、Consumer Group簡介
傳統消息隊列模型的消息一旦被消費,就會從隊列中被刪除,而且只能被一個Consumer消費,因此伸縮性(scalability)很差;發佈/訂閱模型允許消息被多個Consumer消費,但其伸縮性也不高,因爲每個訂閱者都必須要訂閱Topic的所有分區。
Consumer Group(消費者組)是Kafka提供的可擴展且具有容錯性的消費者機制,可以避免傳統消息隊列模型、發佈/訂閱模型的缺陷。
當Consumer Group訂閱多個Topic後,組內的每個Consumer實例不要求一定要訂閱Topic的所有分區,只會消費部分分區中的消息;而Consumer Group間彼此獨立,互不影響,能夠訂閱相同的一組Topic而互不干涉。再加上Broker端的消息留存機制,Kafka的Consumer Group避免了伸縮性差的問題,同時實現了傳統消息引擎系統的兩大模型:如果所有Consumer實例都屬於同一個Group,是消息隊列模型;如果所有Consumer實例分別屬於不同的Group,是發佈/訂閱模型。理想情況下,Consumer 實例的數量應該等於Consumer Group訂閱主題的分區總數。
Consumer Group可以有多個消費者或消費者實例(Consumer Instance),共享一個公共的ID(Group ID)。Consumer Group組內的所有消費者協調在一起來消費訂閱Topic(Subscribed Topics)的所有分區(Partition),每個分區只能由同一個消費者組內的一個Consumer實例來消費。
2、Consumer Group特性
(1)Consumer Group可以有一個或多個Consumer實例,Consumer實例可以是一個單獨的進程,也可以是同一進程下的線程。
(2)Group ID是一個字符串,在一個Kafka集羣中標識唯一的一個Consumer Group。
(3)Consumer Group的所有Consumer實例訂閱的Topic的某個分區只能分配給組內的某個Consumer實例消費,但可以被其它Consumer Group消費。
3、消費者組位移
Consumer Group的位移是一組 KV 對,Key是分區,V是Consumer消費Key分區的最新位移。
舊版本的Consumer Group把位移保存在ZooKeeper中。ZooKeeper 是一個分佈式的協調服務框架,Kafka重度依賴ZooKeeper實現各種各樣的協調管理,將位移保存在ZooKeeper的優點是減少了Kafka Broker端的狀態保存開銷。但ZooKeeper並不適合進行頻繁的寫更新,而Consumer Group的位移更新是一個非常頻繁的操作,大吞吐量的寫操作會極大地拖慢ZooKeeper集羣的性能,因此Kafka 0.9版本的 Consumer Group中重新設計了Consumer Group的位移管理方式,將位移保存在Kafka內置Topic(__consumer_offsets)中。
4、Rebalance
Rebalance本質上是一種協議,規定了一個Consumer Group下的所有Consumer如何達成一致,來分配訂閱Topic的每個分區。如某個Group下有20個Consumer實例,訂閱了一個具有100個分區的Topic。正常情況下,Kafka平均會爲每個Consumer分配5個分區,分區的分配的過程就叫Rebalance。Consumer Group觸發Rebalance的條件有 3 個:
(1)組成員數發生變更。如有新的Consumer實例加入組或者離開組,或有Consumer實例崩潰從組中刪除。
(2)訂閱Topic數發生變更。Consumer Group可以使用正則表達式的方式訂閱主題,在Consumer Group運行過程中,如果新創建一個滿足正則匹配條件的Topic,那麼Consumer Group就會觸發Rebalance。
(3)訂閱Topic的分區數發生變更。Kafka當前只能允許增加一個Topic的分區數。當分區數增加時,就會觸發訂閱Topic的所有Consumer Group開啓Rebalance。
Rebalance發生時,Consumer Group下所有的Consumer實例都會協調在一起共同參與。Kafka默認提供了3種Topic分區的分配策略,每個Consumer實例都能夠得到較爲平均的分區數。
Rebalance的缺點如下:
(1)Rebalance過程對Consumer Group消費過程有極大的影響。在Rebalance過程中,所有Consumer實例都會停止消費,等待Rebalance完成。
(2)Rebalance過程中所有Consumer實例共同參與,全部重新分配所有分區,更高效的做法是儘量減少分配方案的變動。
(3)Rebalance過程太慢。
5、Coordinator
Coordinator一般指的是運行在每個Broker上的Group Coordinator進程,用於管理Consumer Group中的各個成員,主要用於offset位移管理和Rebalance。一個Coordinator可以同時管理多個消費者組。
kafka引入Coordinator有其歷史背景,原來consumer信息依賴於Zookeeper存儲,當代理或消費者發生變化時,引發消費者平衡,此時消費者之間是互不透明的,每個消費者和Zookeeper單獨通信,容易造成羊羣效應和腦裂問題。
爲了解決這些問題,kafka引入了Coordinator。服務端引入組協調器(Group Coordinator),消費者端引入消費者協調器(Consumer Coordinator)。每個Broker啓動的時候,都會創建Group Coordinator實例,管理部分消費組(集羣負載均衡)和組下每個消費者消費的偏移量(offset)。每個Consumer實例化時,同時實例化一個Consumer Coordinator對象,負責同一個消費組下各個消費者和服務端組協調器之前的通信。
四、Kafka Rebalance機制
1、Rebalance簡介
當消費者組中的數量發生變化,或者Topic中的Partition數量發生了變化時,Partition的所有權會在消費者間轉移,即Partition會重新分配,分配過程稱爲Rebalance。
Rebalance能夠給消費者組及Broker帶來高性能、高可用性和伸縮,但在Rebalance期間消費者是無法讀取消息的,即整Broker集羣有小一段時間是不可用的。因此要避免不必要的Rebalance。
Rebalance是讓一個Consumer Group下所有的Consumer實例就如何消費訂閱主題的所有分區達成共識的過程。Rebalance過程中,所有Consumer實例共同參與,在Coordinator組件的幫助下,完成訂閱主題分區的分配。Rebalance過程中,所有Consumer實例都不能消費任何消息,因此對Consumer的TPS影響很大。
在Kafka中,Coordinator負責爲Consumer Group 執行Rebalance以及提供位移管理和組成員管理等。Consumer端應用程序在提交位移時,向Coordinator所在的Broker提交位移。當Consumer應用啓動時,向Coordinator所在的Broker發送各種請求,然後由Coordinator負責執行消費者組的註冊、成員管理記錄等元數據管理操作。
所有Broker在啓動時,都會創建和開啓相應的Coordinator組件,Consumer Group確定爲其服務的Coordinator在哪臺Broker上的算法有2 個步驟:
(1)確定由位移主題的哪個分區來保存Consumer Group數據:partitionId=Math.abs(groupId.hashCode() % offsetsTopicPartitionCount)。
(2)找出分區Leader副本所在的Broker,即爲對應Coordinator。
2、StickyAssignor粘性分區分配策略
Kafka每次Rebalance時,所有Consumer實例會共同參與重新分配所有分區,效率不高,因此Kafka 0.11.0.0版本推出了StickyAssignor(有粘性的分區分配策略)。有粘性分區分配是指每次Rebalance時會儘可能地保留原來的分區分配方案,儘量實現分區分配的最小變動。
3、Rebalance觸發條件
觸發Rebalance的情況有三種:Consumer Group的Consumer成員數量發生變化;訂閱主題數量發生變化;訂閱主題的分區數發生變化。
如果Consumer Group下的Consumer實例數量發生變化,就一定會引發Rebalance,也是Rebalance發生的最常見的原因。
當啓動一個配置有相同group.id值的Consumer程序時,就向Group添加一個新的Consumer實例。此時,Coordinator會接納新實例,將其加入到組中,並重新分配分區。增加Consumer實例的操作都是計劃內的,可能出於增加TPS或提高伸縮性的需要。
當Consumer Group完成Rebalance後,每個Consumer實例都會定期地向Coordinator發送心跳請求。如果某個Consumer實例不能及時地發送心跳請求,Coordinator會認爲Consumer已經死,從而將其從Group中移除,然後開啓新一輪Rebalance。
Consumer端session.timeout.ms參數用於指定Consumer的心跳超時,默認值10秒,如果Coordinator在 10 秒內沒有收到Group下某Consumer實例的心跳,會認爲Consumer實例已經掛了。
Consumer的heartbeat.interval.ms參數允許控制發送心跳請求頻率,值越小,Consumer實例發送心跳請求的頻率就越高,頻繁地發送心跳請求會額外消耗帶寬資源,但能夠更加快速地知曉當前是否開啓Rebalance。Coordinator通知各個Consumer實例開啓Rebalance的方法就是將REBALANCE_NEEDED標誌封裝進心跳請求的響應體中。
Consumer端max.poll.interval.ms參數用於控制Consumer實際消費能力對Rebalance的影響,限定Consumer端應用程序兩次調用poll方法的最大時間間隔,默認值是5分鐘,表示Consumer程序如果在5 分鐘內無法消費完poll方法返回的消息,Consumer會主動發起離開組的請求,Coordinator會開啓新一輪Rebalance。
有多種原因會導致產生非必要的Rebalance:
(1)未能及時發送心跳,導致Consumer被踢出Group而引發。因此,需要仔細地設置session.timeout.ms和heartbeat.interval.ms的值。生產環境中推薦設置session.timeout.ms = 6s,heartbeat.interval.ms = 2s。將session.timeout.ms設置成6s主要是爲了讓Coordinator能夠更快地定位已經掛掉的Consumer。
(2)Consumer消費時間過長導致的。max.poll.interval.ms參數值的設置需要爲業務處理邏輯留下充足的時間。
(3)生產環境中,Consumer端如果出現頻繁的Full GC導致的長時間停頓,也會引發Rebalance。
五、Kafka內置Topic
1、位移主題簡介
__consumer_offsets是Kafka的內置Topic,即位移主題(Offsets Topic)。舊版本Consumer的位移管理是依託於Apache ZooKeeper,會自動或手動地將位移數據提交到ZooKeeper中保存,當Consumer重啓後,會自動從ZooKeeper中讀取位移數據,從而在上次消費截止的地方繼續消費。因此,Kafka Broker不需要保存位移數據,減少了Broker端需要持有的狀態空間,因而有利於實現高伸縮性。但ZooKeeper不適合高吞吐量的寫操作,因此,Kafka 0.9版本Consumer中正式推出全新的位移管理機制,將Consumer的位移數據作爲普通的Kafka消息,提交到__consumer_offsets中。
2、位移主題的消息格式
__consumer_offsets位移主題的消息格式是Kafka自己定義的,用戶不能修改,即不能隨意地向__consumer_offsets主題寫消息,因爲如果寫入的消息不滿足Kafka規定的格式,那Kafka內部無法成功解析,就會造成Broker崩潰。Kafka Consumer的位移提交API用於提交位移,即向__consumer_offsets位移主題寫消息。__consumer_offsets位移主題的消息格式如下:
(1)位移消息
位移消息的Key和Value分別表示消息的鍵值和消息體。
Key中保存3部分內容:<Group ID,主題名,分區號>。
(2)Consumer Group註冊消息
Consumer Group註冊消息用於註冊Consumer Group。
(3)tombstone消息
tombstone消息,即墓碑消息,也稱delete mark,用於刪除Group過期位移或是刪除Group的消息,墓碑消息的消息體是null。
如果某個Consumer Group下的所有Consumer實例都停止,而且其位移數據都已被刪除時,Kafka會向位移主題的對應分區寫入 tombstone消息,表明要徹底刪除Group的信息。
3、位移主題創建
當Kafka集羣中的第一個Consumer程序啓動時,Kafka會自動創建位移主題。位移主題是普通的Kafka主題,其分區數由Broker端參數offsets.topic.num.partitions參數的值指定,默認值是 50,因此Kafka會自動創建一個50分區的位移主題。
位移主題的副本數由Broker端參數offsets.topic.replication.factor指定,默認值是3。
如果位移主題是Kafka自動創建的,則分區數是50,副本數是3。可以選擇手動創建位移主題,在Kafka集羣尚未啓動任何Consumer前,使用Kafka API創建位移主題。
4、位移提交
Kafka Consumer提交位移的方式有兩種:自動提交位移和手動提交位移。Consumer端參數enable.auto.commit用於控制位移提交方式。
enable.auto.commit參數值爲true,表示自動提交,Consumer在後臺定期提交位移,提交間隔由一個專屬的參數auto.commit.interval.ms控制。對於自動提交位移,如果只要Consumer一直啓動着,Consumer會定期的向位移主題寫入消息。
enable.auto.commit參數值爲false,表示手動提交,Consumer應用需要進行位移提交。Kafka Consumer API提供了位移提交的方法consumer.commitSync。當調用位移提交方法時,Kafka會向位移主題寫入相應的消息。
5、位移消息刪除
位移主題中的某類消息只需要保存最新的一條即可,其它過期消息可以刪除,否則位移主題的消息會越來越多,撐爆磁盤。Kafka使用Compaction對位移主題的過期消息進行刪除。
上圖,位移爲0、2和3的消息的Key都是K1。Compact後,分區只需要保存最新的消息(位移爲3的消息)。Kafka提供專門的後臺線程Log Cleaner定期地巡檢待Compact的主題,看看是否存在滿足條件的可刪除數據。生產環境中如果出現過位移主題無限膨脹佔用過多磁盤空間的問題,需要檢查Log Cleaner線程的狀態。
六、Consumer Offset
1、消費位移簡介
Consumer Offset是消費位移,記錄Consumer要消費的下一條消息的位移,用於表徵消費者消費進度,每個消費者都有自己的消費者位移。
Consumer需要向Kafka彙報自己的位移數據,即提交位移(Committing Offsets)。Consumer能夠同時消費多個分區的數據,因此位移的提交是在分區粒度上進行的,即Consumer需要爲消費的每個分區提交各自的位移數據。提交位移主要是爲了表徵Consumer的消費進度,當Consumer發生故障重啓後,就能夠從Kafka中讀取原來提交的位移值,然後從相應的位移處繼續消費,從而避免整個消費過程重來一遍。
對位移提交的管理直接影響Consumer所能提供的消息語義保障。
Kafka Consumer API提供了多種提交位移的方法。基於用戶角度,位移提交分爲自動提交和手動提交;基於Consumer角度,位移提交分爲同步提交和異步提交。
2、offset commit
Consumer從Broker中取一批消息寫入buffer進行消費,在規定的時間內消費完消息後,會自動將其消費消息的offset提交給Broker,以記錄下哪些消息是消費過的。當然,若在時限內沒有消費完畢,其是不會提交offset的。
3、自動提交位移
自動提交是指Kafka Consumer在後臺定期自動提交位移;手動提交是指要自己提交位移。Consumer端參數enable.auto.commit用於控制提交位移的方式,默認值爲true,表示自動提交,即Java Consumer 默認自動提交位移。Consumer端參數auto.commit.interval.ms用於控制自動提交位移的間隔,默認值是5秒,表明Kafka Consumer每5秒會自動提交一次位移。
enable.auto.commit參數設置爲false表示手動提交位移,Kafka Consumer不會自動提交位移,需要調用相應的API手動提交位移。KafkaConsumer#commitSync()方法會提交KafkaConsumer#poll()返回的最新位移,是一個同步操作,會一直等待直到位移被成功提交纔會返回;如果提交過程中出現異常,會將異常信息拋出。commitSync()使用示例如下:
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
process(records); // 處理消息
try {
consumer.commitSync();
} catch (CommitFailedException e) {
handle(e); // 處理提交失敗異常
}
}需要在處理完poll()方法返回的所有消息後調用consumer.commitSync()方法。如果過早提交位移,就可能會出現消費數據丟失的情況。對於自動提交位移,Kafka Consumer會保證在開始調用poll方法時,提交上次poll返回的所有消息。因此,poll方法的邏輯是先提交上一批消息的位移,再處理下一批消息,因此能保證不出現消費丟失的情況,但自動提交位移存在可能會出現重複消費的缺陷。在默認情況下,Consumer每 5秒自動提交一次位移,如果提交位移後3秒發生Rebalance操作,在Rebalance後,所有Consumer從上一次提交的位移處繼續消費,但位移已經是3秒前的位移數據,因此在Rebalance發生前3秒消費的所有數據都要重新再消費一次。雖然能夠通過減少auto.commit.interval.ms的值來提高提交頻率,但只能縮小重複消費的時間窗口,不可能完全消除。
4、手動提交位移
手動提交位移則更加靈活,完全能夠把控位移提交的時機和頻率,但在調用commitSync()時,Consumer程序會處於阻塞狀態,直到遠端的Broker返回提交結果。在任何系統中,因爲程序而非資源限制而導致的阻塞都可能是系統的瓶頸,會影響整個應用程序的TPS。雖然可以選擇拉長提交間隔,但會導致Consumer的提交頻率下降,在下次Consumer重啓回來後,會有更多的消息被重新消費。
因此,Kafka爲手動提交位移提供了一個異步API方法:KafkaConsumer#commitAsync()。調用commitAsync() 後,會立即返回,不會阻塞,因此不會影響Consumer應用的TPS。同時,Kafka Consumer針對異步提交位移接口提供了回調函數(callback),供實現提交後的邏輯,比如記錄日誌或處理異常等。commitAsync()使用示例如下:
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
process(records); // 處理消息
consumer.commitAsync((offsets, exception) -> {
if (exception != null)
handle(exception);
});
}commitAsync在提交失敗時不會自動重試,不能替代commitSync,因爲commitAsync是異步操作,倘若提交失敗後自動重試,那麼重試時提交的位移值可能早已經過期。因此,針對手動提交位移,需要將commitSync和commitAsync組合使用才能到達最理想的效果,可以利用commitSync的自動重試來規避瞬時錯誤(如網絡瞬時抖動,Broker端GC等),使Consumer程序不會一直處於阻塞狀態,不影響TPS。commitSync和commitAsync組合使用示例如下:
try {
while(true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
process(records); // 處理消息
commitAysnc(); // 使用異步提交規避阻塞
}
} catch(Exception e) {
handle(e); // 處理異常
} finally {
try {
consumer.commitSync(); // 最後一次提交使用同步阻塞式提交
} finally {
consumer.close();
}
}上述代碼對於常規性、階段性的手動提交,調用commitAsync()避免程序阻塞;而在Consumer要關閉前,調用commitSync()方法執行同步阻塞式的位移提交,以確保Consumer關閉前能夠保存正確的位移數據。因此,既實現了異步無阻塞式的位移管理,也確保了Consumer位移的正確性。
commitAsync()和commitSync()提交的位移是poll方法返回的所有消息的位移,如果想更加細粒度化地提交位移,如提交poll返回的部分消息的位移,或是在消費的中間進行位移提交,需要新的Kafka Consumer API接口。爲了幫助實現更精細化的位移管理功能,Kafka Consumer API還針對同步/異步提交提供了一組更爲方便的方法,commitSync(Map<TopicPartition, OffsetAndMetadata>)和commitAsync(Map<TopicPartition, OffsetAndMetadata>),參數是Map對象,鍵就是TopicPartition,即消費的分區,而值是一個OffsetAndMetadata對象,保存的主要是位移數據。示例代碼如下:
private Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
int count = 0;
……
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record: records) {
process(record); // 處理消息
offsets.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1);
if(count % 100 == 0)
consumer.commitAsync(offsets, null); // 回調處理邏輯是null
count++;
}
}創建Map對象,用於保存Consumer消費處理過程中要提交的分區位移,開始逐條處理消息,並構造要提交的位移值。要提交的位移是下一條消息的位移,因此構造OffsetAndMetadata對象時,使用當前消息位移加1。與調用無參的commitAsync不同,帶Map對象參數的commitAsync進行細粒度的位移提交。
5、CommitFailedException
CommitFailedException表示Consumer客戶端在提交位移時出現不可恢復錯誤或異常。如果異常是可恢復的瞬時錯誤,提交位移的API可以避免,很多提交位移的API方法支持自動錯誤重試。
CommitFailedException異常通常發生在手動提交位移時,即用戶顯式調用KafkaConsumer.commitSync()方法時。
當消息處理的總時間超過預設的max.poll.interval.ms參數值時,Kafka Consumer端會拋出CommitFailedException異常。CommitFailedException異常復現代碼如下:
…
Properties props = new Properties();
…
props.put("max.poll.interval.ms", 5000);
consumer.subscribe(Arrays.asList("test-topic"));
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
// 使用Thread.sleep模擬真實的消息處理邏輯
Thread.sleep(6000L);
consumer.commitSync();
}使用KafkaConsumer.subscribe方法隨意訂閱一個Topic,設置Consumer端參數max.poll.interval.ms=5秒,最後在循環調用 KafkaConsumer.poll 方法間,插入Thread.sleep(6000)和手動提交位移,成功復現異常。
避免CommitFailedException異常:
(1)縮短單條消息處理的時間。
(2)增加Consumer端允許下游系統消費一批消息的最大時長。如果消費邏輯不能簡化,那麼應該提高Consumer端參數max.poll.interval.ms(Kafka 0.10.1.0版本引入)值。
(3)減少下游系統一次性消費的消息總數。減少Consumer端參數 max.poll.records的值,默認值是500條,因此調用一次Kafka Consumer.poll方法,最多返回500條消息。
(4)下游系統使用多線程來加速消費。使用Kafka Consumer消費數據是單線程,當消費速度無法匹配Kafka Consumer消息返回的速度時,會拋出CommitFailedException異常。如果多線程進行消費,可以靈活地控制線程數量,隨時調整消費承載能力,但實現較爲複雜。主流的大數據流處理框架使用多線程消費方案,如Apache Flink在集成 Kafka 時就是創建了多個Kafka Consumer Thread線程,自行處理多線程間的數據消費。
Kafka Java Consumer端還提供了一個名爲Standalone Consumer的獨立消費者,每個Standalone Consumer實例都是獨立工作的,彼此之間毫無聯繫。獨立消費者的位移提交機制和Consumer Group是一樣的,比如獨立消費者也需要指定group.id參數才能提交位移。
如果應用中同時出現具有相同group.id值的Consumer Group程序和Standalone Consumer程序,那麼當獨立消費者程序手動提交位移時,Kafka就會立即拋出CommitFailedException異常,因爲Kafka無法識別具有相同group.id的消費者實例,返回一個錯誤,表明不是消費者組內合法的成員。
七、Kafka副本機制
1、副本機制簡介
副本機制(Replication)是指分佈式系統在多臺網絡互聯的機器上保存有相同的數據拷貝。副本機制的優點如下:
(1)提供數據冗餘。即使系統部分組件失效,系統依然能夠繼續運轉,因而增加了整體可用性以及數據持久性。
(2)提供高伸縮性。支持橫向擴展,能夠通過增加機器的方式來提升讀性能,進而提高讀操作吞吐量。
(3)改善數據局部性。允許將數據放入與用戶地理位置相近的地方,從而降低系統延時。
2、Kafka副本簡介
Kafka副本(Replica)本質是一個只能追加寫消息的提交日誌。根據Kafka副本機制的定義,同一個分區下的所有副本保存有相同的消息序列,並分散保存在不同的Broker上,從而能夠對抗部分Broker宕機帶來的數據不可用。生產環境中,每臺Broker都可能保存有各個主題下不同分區的不同副本,因此,單個Broker上存有成百上千個副本是正常的。
3臺Broker的Kafka集羣上,主題1分區0的3個副本分散在3臺Broker上,其它主題分區的副本分散在不同的Broker上,從而實現數據冗餘。
3、Kafka副本機制簡介
Kafka採用基於領導者(Leader-based)的副本機制。
(1)在Kafka中,副本分爲領導者副本(Leader Replica)和追隨者副本(Follower Replica)。每個分區在創建時都要選舉一個副本,稱爲Leader副本,其餘副本自動稱爲Follower副本。
(2)Kafka副本機制比其它分佈式系統要更嚴格。Kafka中Follower副本不對外提供服務,任何一個Follower副本都不能響應消費者和生產者的讀寫請求,所有的請求都必須由Leader副本來處理,即所有的讀寫請求都必須發往Leader副本所在的Broker進行處理。Follower副本不處理客戶端請求,唯一的任務是從Leader副本異步拉取消息,並寫入到自己的提交日誌中,從而實現與Leader副本的同步。
(3)當Leader副本掛掉時,Kafka依託於ZooKeeper提供的監控功能能夠實時感知到,並立即開啓新一輪的Leader選舉,從Follower副本中選一個作爲新的Leader。原Leader副本重啓後,只能作爲Follower副本加入到集羣中。
4、Kafka副本機制優點
Kafka副本機制的Follower副本不對外提供服務,因此Kafka不能提供讀操作橫向擴展以及改善局部性,但Kafka副本機制的優點如下:
(1)方便實現Read-your-writes。Read-your-writes是當使用生產者API向Kafka成功寫入消息後,馬上使用消費者API去讀取剛纔生產的消息。如果允許Follower副本對外提供服務,由於副本同步是異步的,因此有可能出現Follower副本還沒有從Leader副本拉取到最新的消息,從而使得客戶端看不到最新寫入的消息。
(2)方便實現單調讀(Monotonic Reads)一致性。對於一個消費者用戶,在多次消費消息時,不會看到某條消息一會兒存在一會兒不存在。如果允許Follower副本提供讀服務,那麼假設當前有2個Follower副本 F1 和 F2,異步地拉取Leader副本數據。倘若F1拉取了Leader 的最新消息而F2還未及時拉取,那麼,此時如果有一個消費者先從F1讀取消息後又從F2拉取消息,可能會出現第一次消費時看到的最新消息在第二次消費時不見。
5、ISR簡介
Kafka引入了In-sync Replicas(副本同步列表)。ISR中的副本都是與Leader同步的副本,不在ISR中的Follower副本是與Leader不同步的。Leader副本天然就在 ISR 中,但ISR不只是Follower副本集合,是一個動態調整的集合,由Leader負責維護。
AR(Assigned Replicas)即已分配的副本列表,是指某個Partition的所有副本。
OSR,Out of-Sync Replicas, 即非同步的副本列表。
AR = ISR + OSR
Follower副本要進入ISR需要滿足一定條件:
圖中Leader副本當前寫入10條消息,Follower1副本同步了其中的6條消息,而Follower2副本只同步了其中的3條消息。但Kafka判斷 Follower是否與Leader同步的標準,並不是看Follower副本與Leader副本相差的消息數,而是Broker端replica.lag.time.max.ms參數值。replica.lag.time.max.ms參數表示Follower副本能夠落後Leader副本的最長時間間隔,默認值是10秒。只要一個Follower副本落後Leader 副本的時間不連續超過10秒,Kafka認爲Follower副本與Leader是同步的,即使此時Follower副本中保存的消息明顯少於Leader副本中的消息。Follower副本唯一的工作就是不斷地從Leader副本拉取消息,然後寫入到自己的提交日誌中。如果同步過程的速度持續慢於Leader副本的消息寫入速度,在replica.lag.time.max.ms時間後,Follower副本會被認爲是與Leader副本不同步的,因此不能再放入ISR中。Kafka會自動收縮ISR集合,將Follower副本踢出ISR。
6、Leader選舉
ISR是可以動態調整的,如果ISR爲空,則表明Leader副本已經掛掉,因此Kafka需要重新選舉一個新的Leader。
Kafka把所有不在ISR中的存活副本都稱爲非同步副本。通常,非同步副本落後Leader副本太多,因此,如果選擇非同步副本作爲新Leader,可能會出現數據丟失。Kafka中,如果ISR爲空,從非同步副本選舉Leader的過程稱爲Unclean領導者選舉(Unclean Leader Election)。
Broker端參數unclean.leader.election.enable控制是否允許Unclean領導者選舉。開啓Unclean領導者選舉可能會造成數據丟失,但會使得分區Leader副本一直存在,不會停止對外提供服務,提高可用性。禁止Unclean領導者選舉可以維護數據的一致性,避免消息丟失,但犧牲了高可用性。
當Leader宕機後,Broker Controller會從ISR中挑選一個Follower成爲新的Leader。如果ISR中沒有其它副本,可以通過unclean.leader.election.enable的值來設置Leader選舉範圍。
false:必須等到ISR列表中所有的副本都活過來才進行新的選舉,可靠性有保證,但可用性低。
true:在ISR列表中沒有副本的情況下,可以選擇任意一個沒有宕機的Broker作爲新的Leader,可用性高,但可靠性沒有保證。