




Consumer之自動提交
在上文中介紹了Producer API的使用,現在我們已經知道如何將消息通過API發送到Kafka中了,那麼現在的生產者/消費者模型就還差一位扮演消費者的角色了。因此,本文將介紹Consumer API的使用,使用API從Kafka中消費消息,讓應用成爲一個消費者角色。
還是老樣子,首先我們得創建一個Consumer實例,並指定相關配置項,有了這個實例對象後我們才能進行其他的操作。代碼示例:
/**
* 創建Consumer實例
*/
public static Consumer<String, String> createConsumer() {
Properties props = new Properties();
// 指定Kafka服務的ip地址及端口
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "127。0.0.1:9092");
// 指定group.id,Kafka中的消費者需要在消費者組裏
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "test");
// 是否開啓自動提交
props.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 自動提交的間隔,單位毫秒
props.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 消息key的序列化器
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
// 消息value的序列化器
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
return new KafkaConsumer<>(props);
}在以上代碼中,可以看到設置了group.id這個配置項,這是一個Consumer的必要配置項,因爲在Kafka中,Consumer需要位於一個Consumer Group裏。具體如下圖所示:
在上圖中是一個Consumer消費一個Partition,是一對一的關係。但Consumer Group裏可以只有一個Consumer,此時該Consumer可以消費多個Partition,是一對多的關係。如下圖所示: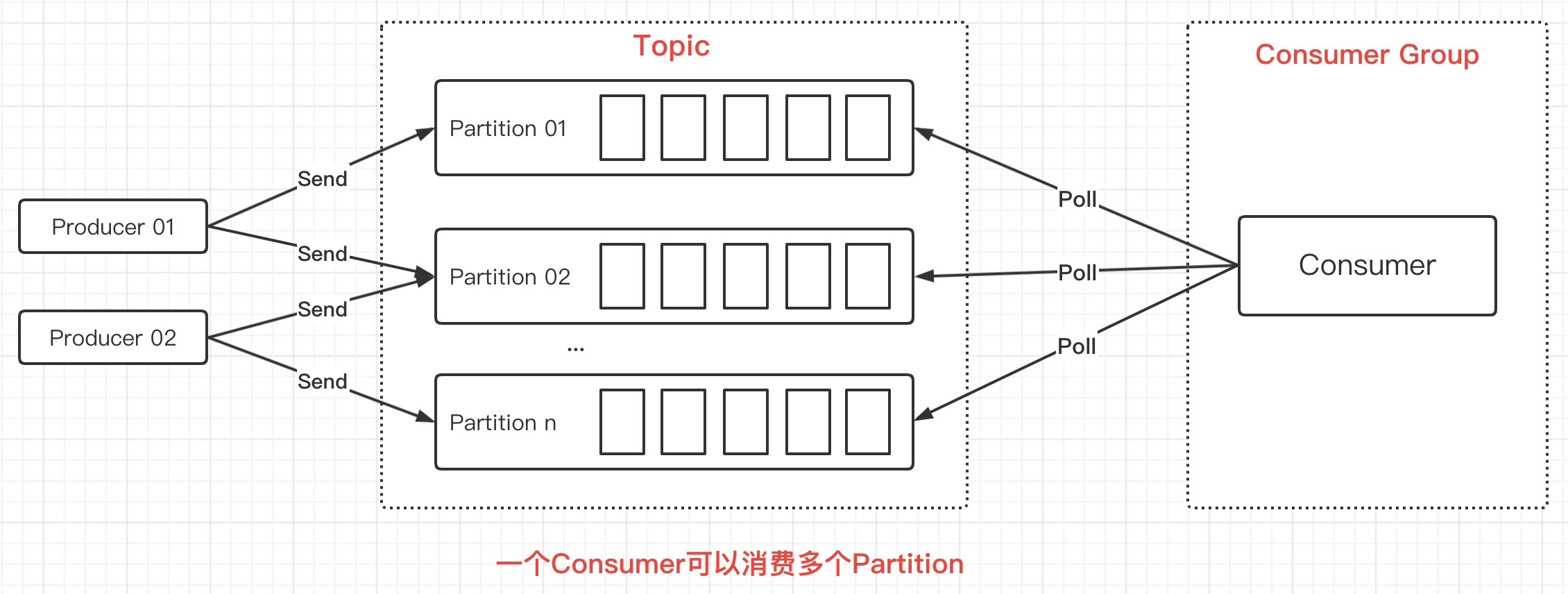
一個Consumer可以只消費一個Partition,也可以消費多個Partition,但需要注意的是多個Consumer不能消費同一個Partition:
總結一下Consumer的注意事項:
- 單個
Partition的消息只能由Consumer Group中的某個Consumer來消費 Consumer從Partition中消費消息是順序的,默認從頭開始消費- 如果Consumer Group中只有一個
Consumer,那麼這個Consumer會消費所有Partition中的消息
在Kafka中,當消費者消費數據後,需要提交數據的offset來告知服務端成功消費了哪些數據。然後服務端就會移動數據的offset,下一次消費的時候就是從移動後的offset位置開始消費。
這樣可以在一定程度上保證數據是被消費成功的,並且由於數據不會被刪除,而只是移動數據的offset,這也保證了數據不易丟失。若消費者處理數據失敗時,只要不提交相應的offset,就可以在下一次重新進行消費。
和數據庫的事務一樣,Kafka消費者提交offset的方式也有兩種,分別是自動提交和手動提交。在本例中演示的是自動提交,這也是消費數據最簡單的方式。代碼示例:
/**
* 演示自動提交offset
*/
public static void autoCommitOffset() {
Consumer<String, String> consumer = createConsumer();
List<String> topics = List.of("MyTopic");
// 訂閱一個或多個Topic
consumer.subscribe(topics);
while (true) {
// 從Topic中拉取數據,每1000毫秒拉取一次
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
// 每次拉取可能都是一組數據,需要遍歷出來
for (ConsumerRecord<String, String> record : records) {
System.out.printf("partition = %d, offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
}
}
}Consumer之手動提交
自動提交的方式是最簡單的,但不建議在實際生產中使用,因爲可控性不高。所以更多時候我們使用的是手動提交,但想要使用手動提交,就需要先關閉自動提交,修改配置項如下:
props.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");關閉了自動提交後,就得在代碼中調用commit相關的方法來提交offset,主要就是兩個方法:commitAsync和commitSync,看方法名也知道一個是異步提交一個是同步提交。
這裏以commitAsync爲例,實現思路主要是在發生異常的時候不要調用commitAsync方法,而在正常執行完畢後才調用commitAsync方法。代碼示例:
/**
* 演示手動提交offset
*/
public static void manualCommitOffset() {
Consumer<String, String> consumer = createConsumer();
List<String> topics = List.of("MyTopic");
// 訂閱一個或多個Topic
consumer.subscribe(topics);
while (true) {
// 從Topic中拉取數據,每1000毫秒拉取一次
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
// 每次拉取可能都是一組數據,需要遍歷出來
for (ConsumerRecord<String, String> record : records) {
try {
// 模擬將數據寫入數據庫
Thread.sleep(1000);
System.out.println("save to db...");
System.out.printf("partition = %d, offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
} catch (Exception e) {
// 寫入失敗則不要調用commit,這樣就相當於起到回滾的作用,
// 下次消費還是從之前的offset開始消費
e.printStackTrace();
return;
}
}
// 寫入成功則調用commit相關方法去手動提交offset
consumer.commitAsync();
}
}##針對Partition提交offset
在前文中有介紹到,一個Consumer Group裏可以只有一個Consumer,該Consumer可以消費多個Partition。在這種場景下,我們可能會在Consumer中開啓多線程去處理多個Partition中的數據,以提高性能。
爲了防止某些Partition裏的數據消費成功,而某些Partition裏的數據消費失敗,卻都一併提交了offset。我們就需要針對單個Partition去提交offset,也就是將offset的提交粒度控制在Partition級別。
這裏先簡單演示一下如何針對單個Partition提交offset,代碼示例:
/**
* 演示手動提交單個Partition的offset
*/
public static void manualCommitOffsetWithPartition() {
Consumer<String, String> consumer = createConsumer();
List<String> topics = List.of("MyTopic");
// 訂閱一個或多個Topic
consumer.subscribe(topics);
while (true) {
// 從Topic中拉取數據,每1000毫秒拉取一次
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
// 單獨處理每一個Partition中的數據
for (TopicPartition partition : records.partitions()) {
System.out.println("======partition: " + partition + " start======");
// 從Partition中取出數據
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
try {
// 模擬將數據寫入數據庫
Thread.sleep(1000);
System.out.println("save to db...");
System.out.printf("partition = %d, offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
} catch (Exception e) {
// 發生異常直接結束,不提交offset
e.printStackTrace();
return;
}
}
// 執行成功則取出當前消費到的offset
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
// 由於下一次開始消費的位置是最後一次offset+1的位置,所以這裏要+1
OffsetAndMetadata metadata = new OffsetAndMetadata(lastOffset + 1);
// 針對Partition提交offset
Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
offsets.put(partition, metadata);
// 同步提交offset
consumer.commitSync(offsets);
System.out.println("======partition: " + partition + " end======");
}
}
}Consumer針對一個或多個Partition進行訂閱
在之前的例子中,我們都是針對Topic去訂閱並消費數據,實際上也可以更細粒度一些針對Partition進行訂閱,這通常應用在一個Consumer多線程消費的場景下。代碼示例:
/**
* 演示將訂閱粒度控制到Partition級別
* 針對單個或多個Partition進行訂閱
*/
public static void manualCommitOffsetWithPartition2() {
Consumer<String, String> consumer = createConsumer();
// 該Topic中有兩個Partition
TopicPartition p0 = new TopicPartition("MyTopic", 0);
TopicPartition p1 = new TopicPartition("MyTopic", 1);
// 訂閱該Topic下的一個Partition
consumer.assign(List.of(p0));
// 也可以訂閱該Topic下的多個Partition
// consumer.assign(List.of(p0, p1));
while (true) {
...與上一小節中的代碼一致,略...
}
}Consumer多線程併發處理
前面兩個小節的內容基本都是爲了本小節所介紹的多線程併發處理消息而鋪墊的,因爲爲了提高應用對消息的處理效率,我們通常會使用多線程來並行消費消息,從而加快消息的處理速度。
而多線程處理消息的方式主要有兩種,一種是按Partition數量創建線程,然後每個線程裏創建一個Consumer,多個Consumer對多個Partition進行消費。這就和之前在介紹Consumer Group時,給出的那張圖所展示的一樣:
這種屬於是經典模式,實現起來也比較簡單,適用於對消息的順序和offset控制有要求的場景。代碼示例:
package com.zj.study.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.errors.WakeupException;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
/**
* 經典模式
*
* @author 01
* @date 2020-05-21
**/
public class ConsumerThreadSample {
private final static String TOPIC_NAME = "MyTopic";
/**
* 這種類型是經典模式,每一個線程單獨創建一個KafkaConsumer,用於保證線程安全
*/
public static void main(String[] args) throws InterruptedException {
KafkaConsumerRunner r1 = new KafkaConsumerRunner();
Thread t1 = new Thread(r1);
t1.start();
Thread.sleep(15000);
r1.shutdown();
}
public static class KafkaConsumerRunner implements Runnable {
private final AtomicBoolean closed = new AtomicBoolean(false);
private final KafkaConsumer<String, String> consumer;
public KafkaConsumerRunner() {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.220.128:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "false");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<>(props);
TopicPartition p0 = new TopicPartition(TOPIC_NAME, 0);
TopicPartition p1 = new TopicPartition(TOPIC_NAME, 1);
consumer.assign(List.of(p0, p1));
}
@Override
public void run() {
try {
while (!closed.get()) {
//處理消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> pRecord = records.records(partition);
// 處理每個分區的消息
for (ConsumerRecord<String, String> record : pRecord) {
System.out.printf("patition = %d , offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
}
// 返回去告訴kafka新的offset
long lastOffset = pRecord.get(pRecord.size() - 1).offset();
// 注意加1
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
} catch (WakeupException e) {
if (!closed.get()) {
throw e;
}
} finally {
consumer.close();
}
}
public void shutdown() {
closed.set(true);
consumer.wakeup();
}
}
}另一種多線程的消費方式則是在一個線程池中只創建一個Consumer實例,然後通過這個Consumer去拉取數據後交由線程池中的線程去處理。如下圖所示:
但需要注意的是在這種模式下我們無法手動控制數據的offset,也無法保證數據的順序性,所以通常應用在流處理場景,對數據的順序和準確性要求不高。
經過之前的例子,我們知道每拉取一次數據返回的就是一個ConsumerRecords,這裏面存放了多條數據。然後我們對ConsumerRecords進行迭代,就可以將多條數據交由線程池中的多個線程去並行處理了。代碼示例:
package com.zj.study.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 一個Consumer,多個hander模式
*
* @author 01
* @date 2020-05-21
**/
public class ConsumerRecordThreadSample {
private final static String TOPIC_NAME = "MyTopic";
public static void main(String[] args) throws InterruptedException {
String brokerList = "192.168.220.128:9092";
String groupId = "test";
int workerNum = 5;
ConsumerExecutor consumers = new ConsumerExecutor(brokerList, groupId, TOPIC_NAME);
consumers.execute(workerNum);
Thread.sleep(1000000);
consumers.shutdown();
}
/**
* Consumer處理
*/
public static class ConsumerExecutor {
private final KafkaConsumer<String, String> consumer;
private ExecutorService executors;
public ConsumerExecutor(String brokerList, String groupId, String topic) {
Properties props = new Properties();
props.put("bootstrap.servers", brokerList);
props.put("group.id", groupId);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<>(props);
consumer.subscribe(List.of(topic));
}
public void execute(int workerNum) {
executors = new ThreadPoolExecutor(workerNum, workerNum, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(1000), new ThreadPoolExecutor.CallerRunsPolicy());
while (true) {
ConsumerRecords<String, String> records = consumer.poll(200);
for (final ConsumerRecord<String, String> record : records) {
executors.submit(new ConsumerRecordWorker(record));
}
}
}
public void shutdown() {
if (consumer != null) {
consumer.close();
}
if (executors != null) {
executors.shutdown();
}
try {
if (executors != null && !executors.awaitTermination(10, TimeUnit.SECONDS)) {
System.out.println("Timeout.... Ignore for this case");
}
} catch (InterruptedException ignored) {
System.out.println("Other thread interrupted this shutdown, ignore for this case.");
Thread.currentThread().interrupt();
}
}
}
/**
* 記錄處理
*/
public static class ConsumerRecordWorker implements Runnable {
private ConsumerRecord<String, String> record;
public ConsumerRecordWorker(ConsumerRecord<String, String> record) {
this.record = record;
}
@Override
public void run() {
// 假如說數據入庫操作
System.out.println("Thread - " + Thread.currentThread().getName());
System.err.printf("patition = %d , offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
}
}
}Consumer控制offset起始位置
上一小節中介紹的第二種多線程消息模式,通過Consumer拉取數據後交由多線程去處理是沒法控制offset的,如果此時程序出現錯誤或其他意外情況導致消息沒有被正確消費,我們就需要人爲控制offset的起始位置重新進行消費。
通過調用seek方法可以指定從哪個Partition的哪個offset位置進行消費,代碼示例:
/**
* 手動控制offset的起始位置
*/
public static void manualCommitOffsetWithPartition2() {
Consumer<String, String> consumer = createConsumer();
TopicPartition p0 = new TopicPartition("MyTopic", 0);
consumer.assign(List.of(p0));
// 指定offset的起始位置
consumer.seek(p0, 1);
while (true) {
...與上一小節中的代碼一致,略...
}
}實際應用中的設計思路:
- 第一次從某個
offset的起始位置進行消費 - 如果本次消費了
100條數據,那麼offset設置爲101並存入Redis等緩存數據庫中 - 後續每次
poll之前,從Redis中獲取offset值,然後從這個offset的起始位置進行消費 - 消費完後,再次將新的
offset值存入Redis,周而復始
Consumer限流
爲了避免Kafka中的流量劇增導致過大的流量打到Consumer端將Consumer給壓垮的情況,我們就需要針對Consumer進行限流。例如,當處理的數據量達到某個閾值時暫停消費,低於閾值時則恢復消費,這就可以讓Consumer保持一定的速率去消費數據,從而避免流量劇增時將Consumer給壓垮。大體思路如下:
- 在
poll到數據之後,先去令牌桶中拿取令牌 - 如果獲取到令牌,則繼續業務處理
- 如果獲取不到令牌,則調用
pause方法暫停Consumer,等待令牌 - 當令牌桶中的令牌足夠,則調用
resume方法恢復Consumer的消費狀態
接下來編寫具體的代碼案例簡單演示一下這個限流思路,令牌桶算法使用Guava裏內置的,所以需要在項目中添加對Guava的依賴。添加的依賴項如下:
<!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>然後我們就可以使用Guava的限流器對Consumer進行限流了,代碼示例:
public class ConsumerCurrentLimiting {
/*** 令牌生成速率,單位爲秒 */
public static final int permitsPerSecond = 1;
/*** 限流器 */
private static final RateLimiter LIMITER = RateLimiter.create(permitsPerSecond);
/**
* 創建Consumer實例
*/
public static Consumer<String, String> createConsumer() {
... 與之前小節的代碼類似,略 ...
}
/**
* 演示對Consumer限流
*/
public static void currentLimiting() {
Consumer<String, String> consumer = createConsumer();
TopicPartition p0 = new TopicPartition("MyTopic", 0);
TopicPartition p1 = new TopicPartition("MyTopic", 1);
consumer.assign(List.of(p0, p1));
while (true) {
// 從Topic中拉取數據,每100毫秒拉取一次
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1));
if (records.isEmpty()) {
continue;
}
// 限流
if (!LIMITER.tryAcquire()) {
System.out.println("無法獲取到令牌,暫停消費");
consumer.pause(List.of(p0, p1));
} else {
System.out.println("獲取到令牌,恢復消費");
consumer.resume(List.of(p0, p1));
}
// 單獨處理每一個Partition中的數據
for (TopicPartition partition : records.partitions()) {
System.out.println("======partition: " + partition + " start======");
// 從Partition中取出數據
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
try {
// 模擬將數據寫入數據庫
Thread.sleep(1000);
System.out.println("save to db...");
System.out.printf("partition = %d, offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
} catch (Exception e) {
// 發生異常直接結束,不提交offset
e.printStackTrace();
return;
}
}
// 執行成功則取出當前消費到的offset
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
// 由於下一次開始消費的位置是最後一次offset+1的位置,所以這裏要+1
OffsetAndMetadata metadata = new OffsetAndMetadata(lastOffset + 1);
// 針對Partition提交offset
Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
offsets.put(partition, metadata);
// 同步提交offset
consumer.commitSync(offsets);
System.out.println("======partition: " + partition + " end======");
}
}
}
public static void main(String[] args) {
currentLimiting();
}
}Consumer Rebalance解析
Consumer有個Rebalance的特性,即重新負載均衡,該特性依賴於一個協調器來實現。每當Consumer Group中有Consumer退出或有新的Consumer加入都會觸發Rebalance。
之所以要重新負載均衡,是爲了將退出的Consumer所負責處理的數據再重新分配到組內的其他Consumer上進行處理。或當有新加入的Consumer時,將組內其他Consumer的負載壓力,重新進均勻分配,而不會說新加入一個Consumer就閒在那。
下面就用幾張圖簡單描述一下,各種情況觸發Rebalance時,組內成員是如何與協調器進行交互的。
1、新成員加入組(member join):
- Tips:圖中的Coordinator是協調器,而
generation則類似於樂觀鎖中的版本號,每當成員入組成功就會更新,也是起到一個併發控制的作用
2、組成員崩潰/非正常退出(member failure):
3、組成員主動離組/正常退出(member leave group):
4、當Consumer提交位移(member commit offset)時,也會有類似的交互過程: