




SageMaker功能模塊簡介
1Ground Truth
Ground Truth是一個給數據打標籤的平臺。可以選擇純人工打標籤,如果工作量特別大,也可以選擇人工和智能機器協作打標籤。

例如在Ground Truth平臺上操作,框選出貓眼睛,會自動生成一個json文件如圖中右上角,json描述了眼睛在圖中的左上角、右下角座標。
生成的json文件(即標籤信息)可以作爲對象檢測訓練的輸入數據。
標記任務
創建一個打標籤任務,主要包含待打標籤圖片所在路徑、生成的標籤信息文件json所在路徑。
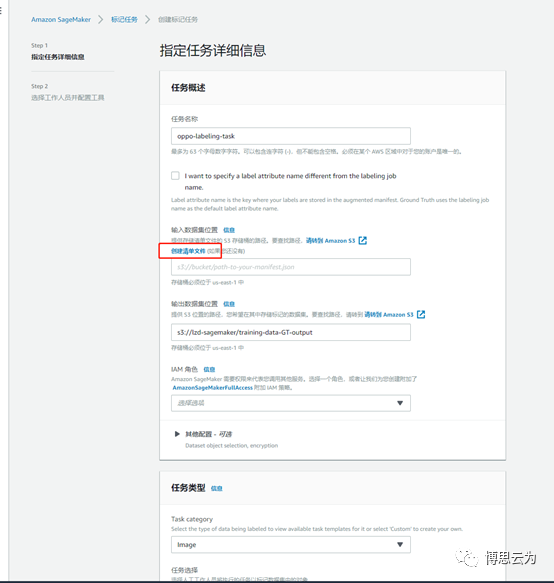
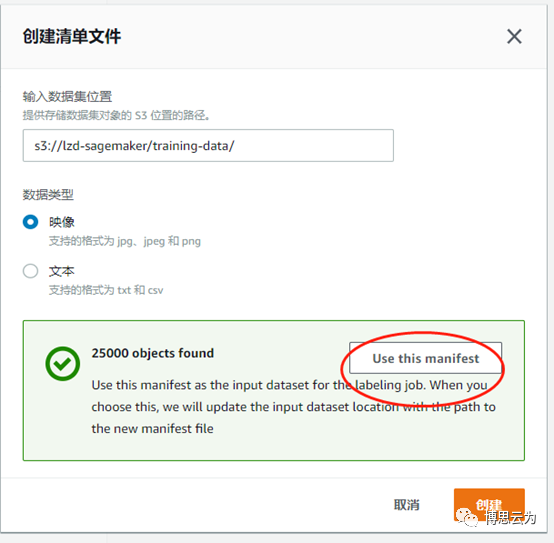
輸入任務名稱、輸出路徑後,點擊“創建清單文件==>輸入圖片路徑==>創建==>use this manifest
IAM角色下拉框==>create a new role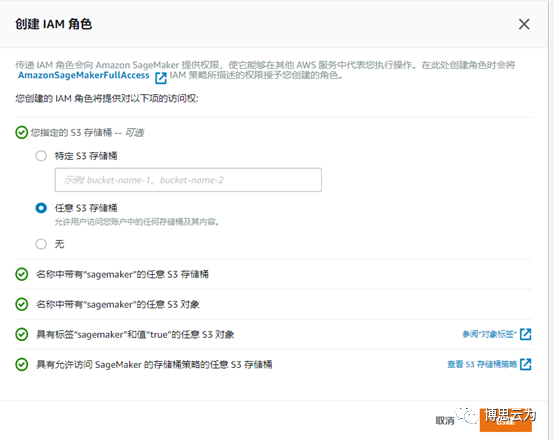
這裏以對象識別模型爲例,任務類型選“邊界框”
下一步把標籤任務分配給相關工作人員:
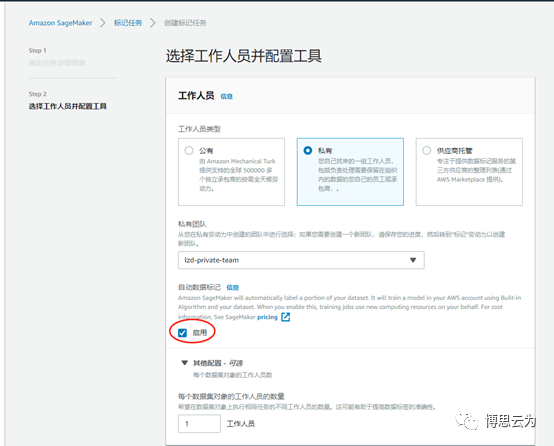
公有:aws龐大的人工團隊,需要付費。
私有:貴公司自己的員工。
供應商:第三方專業打標籤的供應商,需要付費。
選擇“私有”需要先創建一個團隊(後面講)
紅框“啓用”代表人和機器共同勞作,系統自動將圖片分發給人和機器,機器一開始並不知道怎麼打標籤,所以打出來的標籤往往是錯誤的,
這時系統會自動將機器打完標籤的圖片又回傳給人工複覈,機器通過學習複覈結果提升技能。
這個過程是來來回回、反反覆覆的直到機器掌握足夠的水平。接下來機器開始自動打標籤,對於一些機器不能確定的圖片仍然會交由人工處理。
待識別的圖片必須大於1250張纔可啓用機器標籤,建議5000張圖片以上,才選擇啓用。
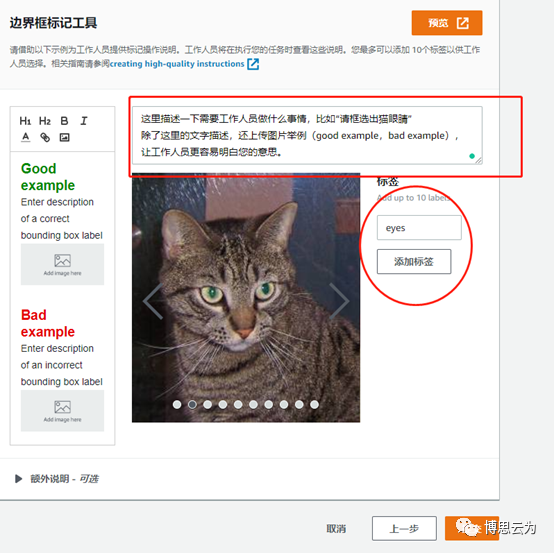
可以給圖片添加多個標籤,比如需要識別圖片中的貓眼睛,貓耳朵等。
這裏假如只希望識別眼睛,所以只添加一個eyes標籤。
提交後,看到任務狀態爲“正在進行”。這時貴公司工作人員可通過郵件提供的地址登錄Ground Truth平臺開始打標籤工作。
任務結束後,生成一份output.manifest文件,即標籤信息總文件。後續訓練模型時作爲輸入文件(train通道)。

類似的,選擇另外一批圖片,建立另外一個Ground Truth任務生成另外一個類似的manifest文件,並做爲object detection模型訓練時的另外一個輸入文件(validation通道)
(訓練模型通常需要training data和validation data)
標籤任務還生成一些其他中間文件,詳情參考
https://docs.aws.amazon.com/sagemaker/latest/dg/sms-data-output.html
標記隨需人力
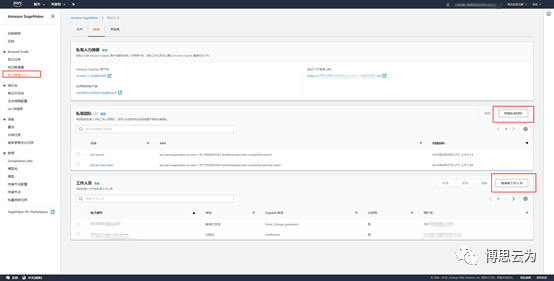
1,邀請新工作人員 輸入員工通過郵件,員工會收到郵件告知登錄Ground Truth平臺的URL、用戶名、密碼。
2,創建私人團隊 創建團隊後刷新一下頁面,再向團隊添加之前創建的工作人員。
2 筆記本
創建一臺EC2筆記本,jupyter已經搭建安裝好各種語言及機器學習框架供科學家直接使用。
熟練的科學家可以在這個平臺以編寫代碼調用sagemaker API的形式完成機器學習的整個流程,從一開始的構建自己的算法,驗證算法,訓練模型,調優,等等直到最後部署模型。
一個參考例子:
非專業人員,建議使用sagemaker圖形界面來完成這些操作。
3 訓練
算法
科學家在這創建自己的算法,後續通過“訓練任務”生成算法模型。
訓練任務

訓練任務將算法訓練出一個實用的模型。
算法源:sagemaker內置了衆多著名、經典成熟的算法,包括對象檢測(object detection),當然也可以選擇科學家自己設計的算法。
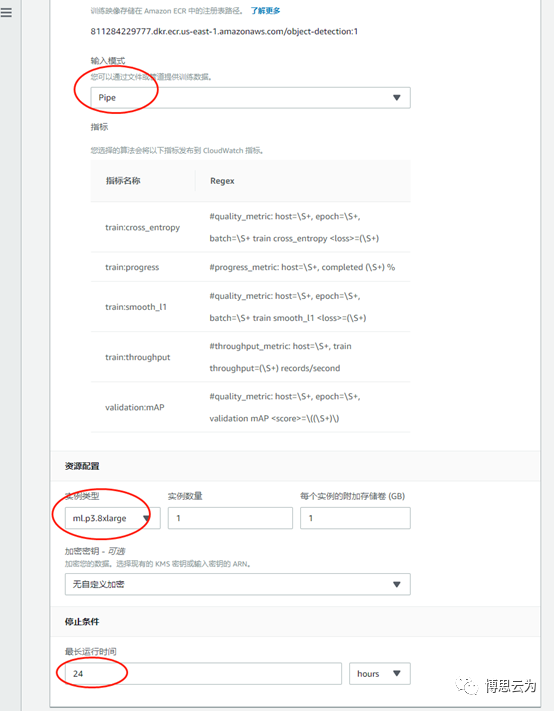
輸入模型:Pipe
資源配置:訓練時建議選擇P系列EC2,生產部署建議C系列。
運行時間:根據實際情況設置訓練任務時長。

超參:非專業人員建議使用默認值,科學家可自定義。
超參詳情
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/object-detection-api-config.html
之前Ground Truth生成的manifest文件內容如下:

source-ref欄位是圖片路徑
lzd-eye是自定義的標籤名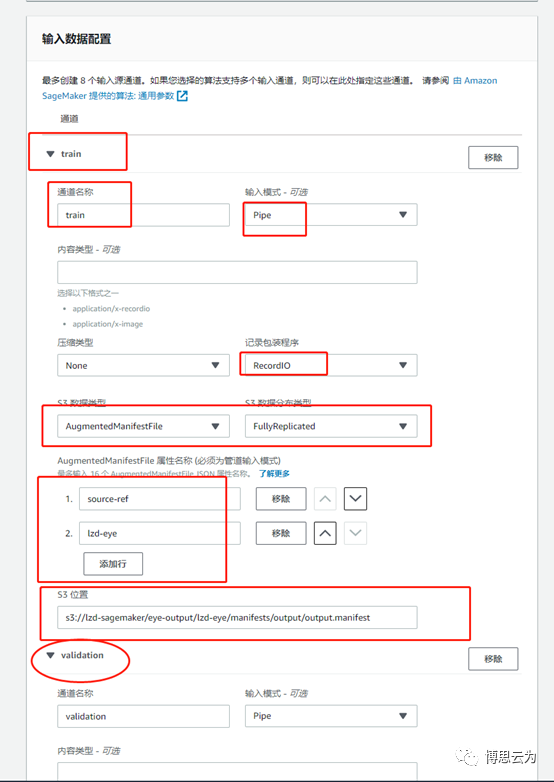
輸入數據配置:
1,默認只有一個“train”通道接收training data。
按上圖填好manifest路徑及source-ref、lzd-eye(根據實際標籤名填寫)等信息

2,添加validation通道接收validation data,除通道名稱爲validation外,其他信息與train通道類似。
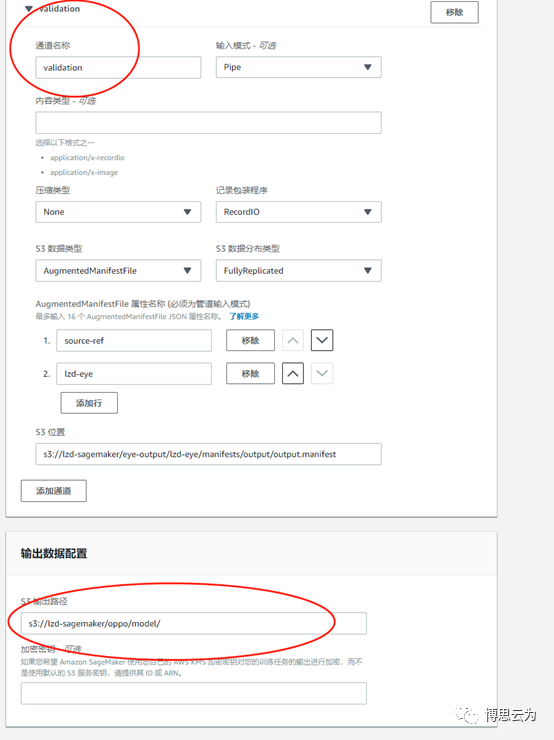
輸出數據配置:即輸出模型路徑
最後創建訓練任務並生成模型。
超級參數優化作業
與“訓練任務”類似,科學家也可以在這裏從零開始訓練模型或在現有的模型基礎上優化訓練,這裏可以更加自由地設定超參範圍,讓sagemaker通過併發訓練任務等方式在指定範圍內找到最佳超參。
4 推理
模型訓練好之後,部署在AWS上,部署分爲實時和批量。
實時:模型實時在線,用戶隨時可以調sagemaker API對圖片進行實時的對象檢測,並實時返回結果。
批量:模型按需啓動,對用戶提供的批量圖片進行對象檢測,並返回批量結果。
training job==>create model
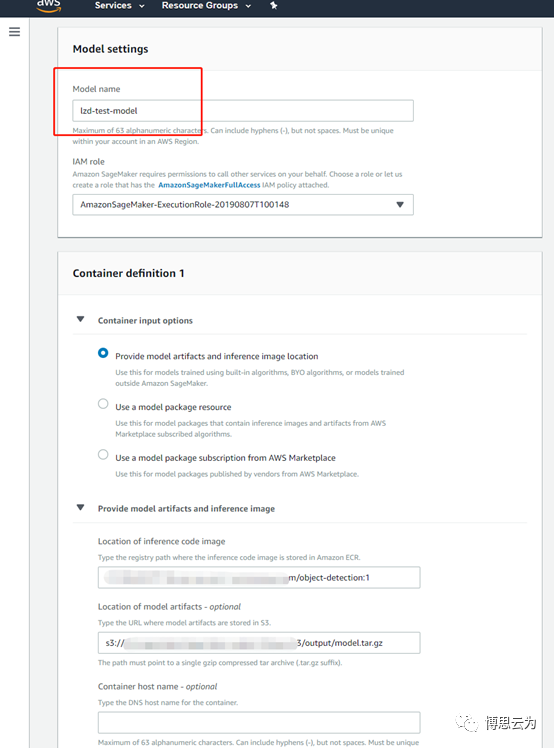
輸入model名稱,其他保持默認。
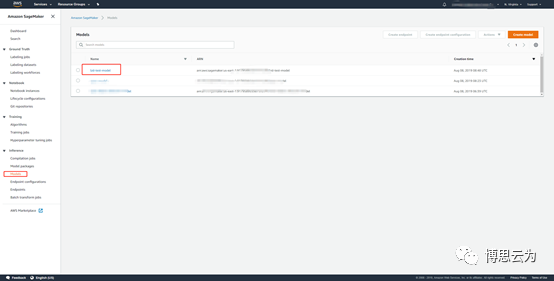
點擊model名稱
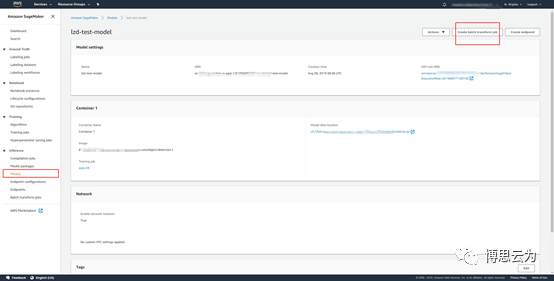
這裏才批量推斷爲例:create batch inference job

按實際情況選擇實例類型及數量。

按實際情況填寫待檢測圖片所在路徑及檢測結果輸出路徑。
batch job結束後在輸出路徑下爲每個圖片生成一個json文件,描述圖片中檢測到多少個物體,每個物體所在座標及類別。
詳情請參考:
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/object-detection-in-formats.html