




Zookeeper作爲服務註冊與發現的解決方案,它有如下優點:
1. 它提供的簡單API
2. 已有互聯網公司(例如:Pinterest,Airbnb)使用它來進行服務註冊與發現
3. 支持多語言的客戶端
4. 通過Watcher機制實現Push模型,服務註冊信息的變更能夠及時通知服務消費方
缺點是:
1. 引入新的Zookeeper組件,帶來新的複雜性和運維問題
2. 需自己通過它提供的API來實現服務註冊與發現邏輯(包含Python與Java版本)
我們對上述幾個方案的優缺點權衡之後,決定採用了基於Zookeeper實現自己的服務註冊與發現。

基於Zookeeper的服務註冊與發現架構
服務提供者
服務提供者作爲服務的提供方將自身的服務信息註冊到服務註冊中心中。服務信息包含:
▪ 隸屬於哪個系統
▪ 服務的IP,端口
▪ 服務的請求URL
▪ 服務的權重等等
服務註冊中心
服務註冊中心主要提供所有服務註冊信息的中心存儲,同時負責將服務註冊信息的更新通知實時的Push給服務消費者(主要是通過Zookeeper的Watcher機制來實現的)。
服務消費者
服務消費者主要職責如下:
1. 服務消費者在啓動時從服務註冊中心獲取需要的服務註冊信息
2. 將服務註冊信息緩存在本地
3. 監聽服務註冊信息的變更,如接收到服務註冊中心的服務變更通知,則在本地緩存中更新服務的註冊信息
4. 根據本地緩存中的服務註冊信息構建服務調用請求,並根據負載均衡策略(隨機負載均衡,Round-Robin負載均衡等)來轉發請求
5. 對服務提供方的存活進行檢測,如果出現服務不可用的服務提供方,將從本地緩存中剔除
服務消費者只在自己初始化以及服務變更時會依賴服務註冊中心,在此階段的單點故障通過Zookeeper集羣來進行保障。在整個服務調用過程中,服務消費者不依賴於任何第三方服務。
實現機制介紹
Zookeeper數據模型介紹
在整個服務註冊與發現的設計中,最重要是如何來存儲服務的註冊信息。
在設計基於Zookeeper的服務註冊結構之前,我們先來看一下Zookeeper的數據模型。Zookeeper的數據模型如下圖所示:
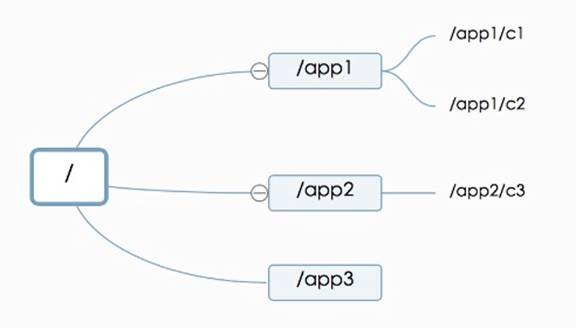
Zookeeper數據模型結構與Unix文件系統很類似,是一個樹狀層次結構。每個節點叫做Znode,節點可以擁有子節點,同時允許將少量數據存儲在該節點下。客戶端可以通過監聽節點的數據變更和子節點變更來實時獲取Znode的變更(Wather機制)。