




-
深入理解 RDD 的內在邏輯
-
能夠使用 RDD 的算子
-
理解 RDD 算子的 Shuffle 和緩存
-
理解 RDD 整體的使用流程
-
理解 RDD 的調度原理
-
理解 Spark 中常見的分佈式變量共享方式
1. 深入 RDD
-
深入理解 RDD 的內在邏輯, 以及 RDD 的內部屬性(RDD 由什麼組成)
1.1. 案例
-
給定一個網站的訪問記錄, 俗稱 Access log
-
計算其中出現的獨立 IP, 以及其訪問的次數
val config = new SparkConf().setAppName("ip_ana").setMaster("local[6]")
val sc = new SparkContext(config)
val result = sc.textFile(“dataset/access_log_sample.txt”)
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
.sortBy(item => item._2, false)
.take(10)
result.foreach(item => println(item))
針對這個小案例, 我們問出互相關聯但是又方向不同的五個問題
-
假設要針對整個網站的歷史數據進行處理, 量有 1T, 如何處理?
-
如何放在集羣中運行?
![6088be299490adbaaeece8717ae985e8]()
- 簡單來講, 並行計算就是同時使用多個計算資源解決一個問題, 有如下四個要點
-
-
要解決的問題必須可以分解爲多個可以併發計算的部分
-
每個部分要可以在不同處理器上被同時執行
-
需要一個共享內存的機制
-
需要一個總體上的協作機制來進行調度
-
-
如果放在集羣中的話, 可能要對整個計算任務進行分解, 如何分解?
![f738dbe3df690bc0ba8f580a3e2d1112]()
- 概述
-
-
對於 HDFS 中的文件, 是分爲不同的 Block 的
-
在進行計算的時候, 就可以按照 Block 來劃分, 每一個 Block 對應一個不同的計算單元
-
- 擴展
-
-
RDD並沒有真實的存放數據, 數據是從 HDFS 中讀取的, 在計算的過程中讀取即可 -
RDD至少是需要可以 分片 的, 因爲HDFS中的文件就是分片的,RDD分片的意義在於表示對源數據集每個分片的計算,RDD可以分片也意味着 可以並行計算
-
-
移動數據不如移動計算是一個基礎的優化, 如何做到?
![1d344ab200bd12866c26ca2ea6ab1e37]()
每一個計算單元需要記錄其存儲單元的位置, 儘量調度過去
-
在集羣中運行, 需要很多節點之間配合, 出錯的概率也更高, 出錯了怎麼辦?
![5c7bef41f177a96e99c7ad8a500b7310]()
- RDD1 → RDD2 → RDD3 這個過程中, RDD2 出錯了, 有兩種辦法可以解決
-
-
緩存 RDD2 的數據, 直接恢復 RDD2, 類似 HDFS 的備份機制
-
記錄 RDD2 的依賴關係, 通過其父級的 RDD 來恢復 RDD2, 這種方式會少很多數據的交互和保存
-
- 如何通過父級 RDD 來恢復?
-
-
記錄 RDD2 的父親是 RDD1
-
記錄 RDD2 的計算函數, 例如記錄
RDD2 = RDD1.map(…),map(…)就是計算函數 -
當 RDD2 計算出錯的時候, 可以通過父級 RDD 和計算函數來恢復 RDD2
-
-
假如任務特別複雜, 流程特別長, 有很多 RDD 之間有依賴關係, 如何優化?
![dc87ed7f9b653bccb43d099bbb4f537f]()
上面提到了可以使用依賴關係來進行容錯, 但是如果依賴關係特別長的時候, 這種方式其實也比較低效, 這個時候就應該使用另外一種方式, 也就是記錄數據集的狀態
- 在 Spark 中有兩個手段可以做到
-
-
緩存
-
Checkpoint
-





1.2. 再談 RDD
-
理解 RDD 爲什麼會出現
-
理解 RDD 的主要特點
-
理解 RDD 的五大屬性
1.2.1. RDD 爲什麼會出現?
- 在 RDD 出現之前, 當時 MapReduce 是比較主流的, 而 MapReduce 如何執行迭代計算的任務呢?
-
![306061ee343d8515ecafbce43bc54bc6]()
多個 MapReduce 任務之間沒有基於內存的數據共享方式, 只能通過磁盤來進行共享
這種方式明顯比較低效
- RDD 如何解決迭代計算非常低效的問題呢?
-
![4fc644616fb13ef896eb3a8cea5d3bd7]()
在 Spark 中, 其實最終 Job3 從邏輯上的計算過程是:
Job3 = (Job1.map).filter, 整個過程是共享內存的, 而不需要將中間結果存放在可靠的分佈式文件系統中這種方式可以在保證容錯的前提下, 提供更多的靈活, 更快的執行速度, RDD 在執行迭代型任務時候的表現可以通過下面代碼體現
// 線性迴歸 val points = sc.textFile(...) .map(...) .persist(...) val w = randomValue for (i <- 1 to 10000) { val gradient = points.map(p => p.x * (1 / (1 + exp(-p.y * (w dot p.x))) - 1) * p.y) .reduce(_ + _) w -= gradient }在這個例子中, 進行了大致 10000 次迭代, 如果在 MapReduce 中實現, 可能需要運行很多 Job, 每個 Job 之間都要通過 HDFS 共享結果, 熟快熟慢一窺便知


1.2.2. RDD 的特點
- RDD 不僅是數據集, 也是編程模型
-
RDD 即是一種數據結構, 同時也提供了上層 API, 同時 RDD 的 API 和 Scala 中對集合運算的 API 非常類似, 同樣也都是各種算子
![02adfc1bcd91e70c1619fc6a67b13f92]()
RDD 的算子大致分爲兩類:
-
Transformation 轉換操作, 例如
mapflatMapfilter等 -
Action 動作操作, 例如
reducecollectshow等
執行 RDD 的時候, 在執行到轉換操作的時候, 並不會立刻執行, 直到遇見了 Action 操作, 纔會觸發真正的執行, 這個特點叫做 惰性求值
-
- RDD 可以分區
-
![2ba2cc9ad8e745c26df482b4e968c802]()
RDD 是一個分佈式計算框架, 所以, 一定是要能夠進行分區計算的, 只有分區了, 才能利用集羣的並行計算能力
同時, RDD 不需要始終被具體化, 也就是說: RDD 中可以沒有數據, 只要有足夠的信息知道自己是從誰計算得來的就可以, 這是一種非常高效的容錯方式
- RDD 是隻讀的
-
![ed6a534cfe0a56de3c34ac6e1e8d504e]()
RDD 是隻讀的, 不允許任何形式的修改. 雖說不能因爲 RDD 和 HDFS 是隻讀的, 就認爲分佈式存儲系統必須設計爲只讀的. 但是設計爲只讀的, 會顯著降低問題的複雜度, 因爲 RDD 需要可以容錯, 可以惰性求值, 可以移動計算, 所以很難支持修改.
-
RDD2 中可能沒有數據, 只是保留了依賴關係和計算函數, 那修改啥?
-
如果因爲支持修改, 而必須保存數據的話, 怎麼容錯?
-
如果允許修改, 如何定位要修改的那一行? RDD 的轉換是粗粒度的, 也就是說, RDD 並不感知具體每一行在哪.
-
- RDD 是可以容錯的
-
![5c7bef41f177a96e99c7ad8a500b7310]()
- RDD 的容錯有兩種方式
-
-
保存 RDD 之間的依賴關係, 以及計算函數, 出現錯誤重新計算
-
直接將 RDD 的數據存放在外部存儲系統, 出現錯誤直接讀取, Checkpoint
-



1.2.3. 什麼叫做彈性分佈式數據集
- 分佈式
-
RDD 支持分區, 可以運行在集羣中
- 彈性
-
-
RDD 支持高效的容錯
-
RDD 中的數據即可以緩存在內存中, 也可以緩存在磁盤中, 也可以緩存在外部存儲中
-
- 數據集
-
-
RDD 可以不保存具體數據, 只保留創建自己的必備信息, 例如依賴和計算函數
-
RDD 也可以緩存起來, 相當於存儲具體數據
-
2. RDD 的算子
-
理解 RDD 的算子分類, 以及其特性
-
理解常見算子的使用
- 分類
- 特點
2.1. Transformations 算子
Transformation function |
解釋 |
|---|---|
|

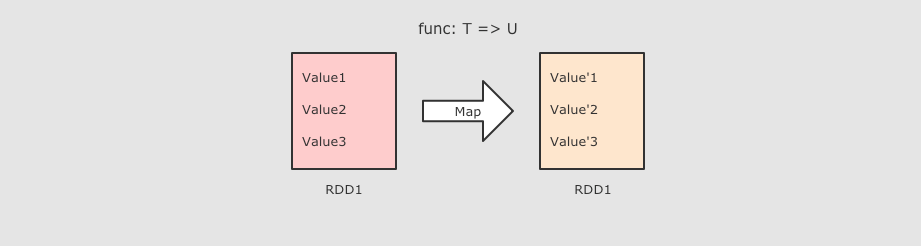
|
|

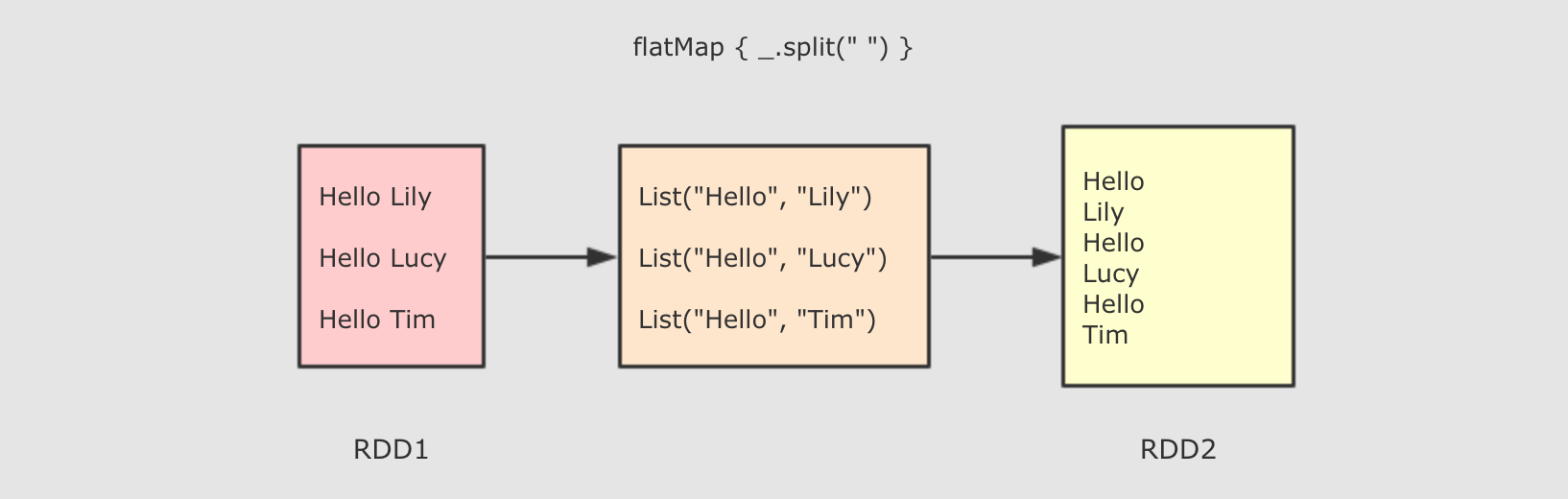
|
|

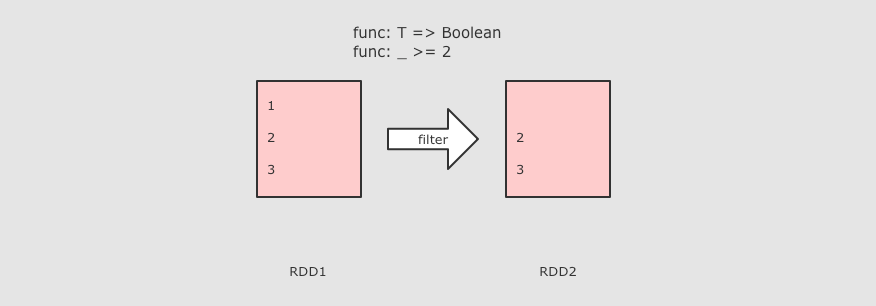
|
|
RDD[T] ⇒ RDD[U] 和 map 類似, 但是針對整個分區的數據轉換 |
|
和 mapPartitions 類似, 只是在函數中增加了分區的 Index |
|

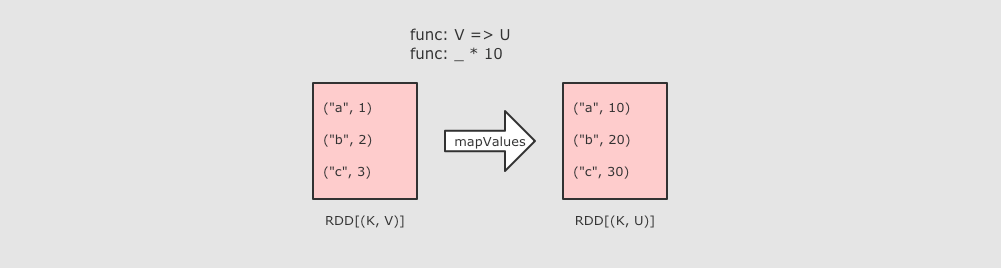
|
|

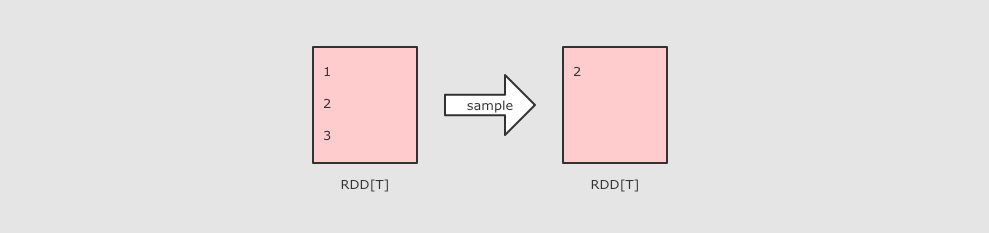
|
|

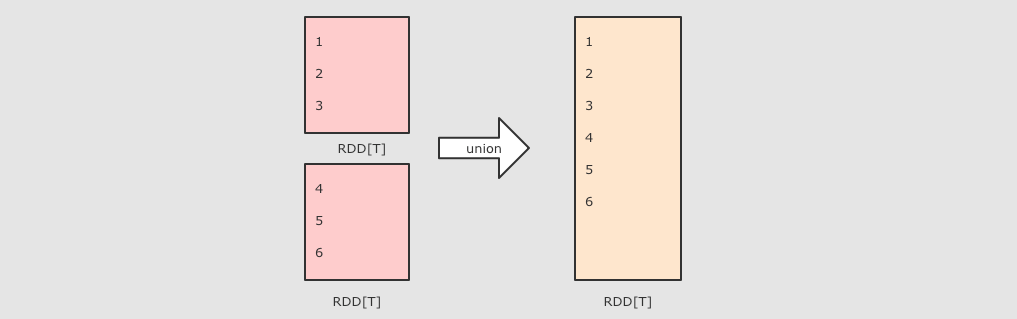
|
|
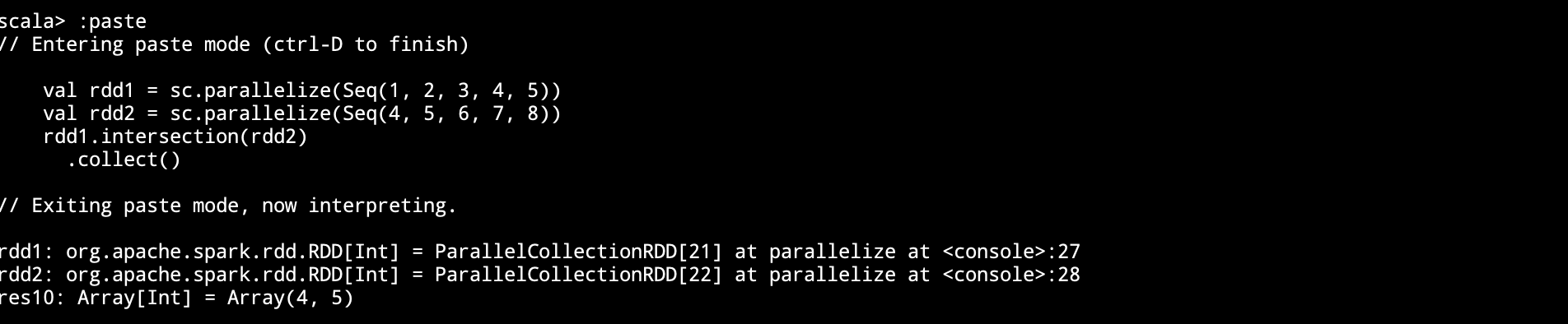
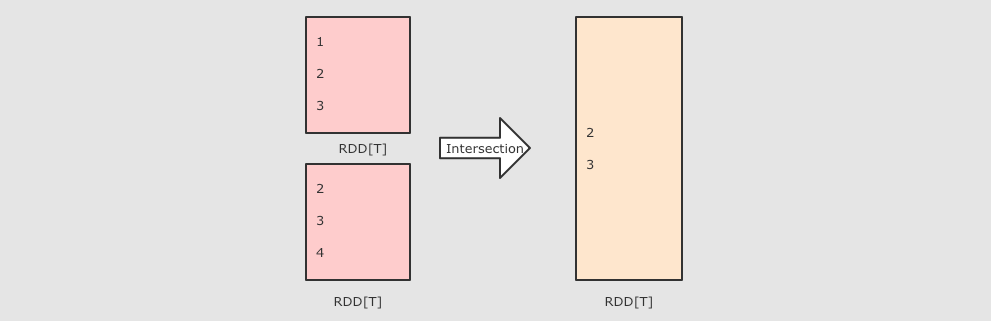
|
|
(RDD[T], RDD[T]) ⇒ RDD[T] 差集, 可以設置分區數 |
|


|
|

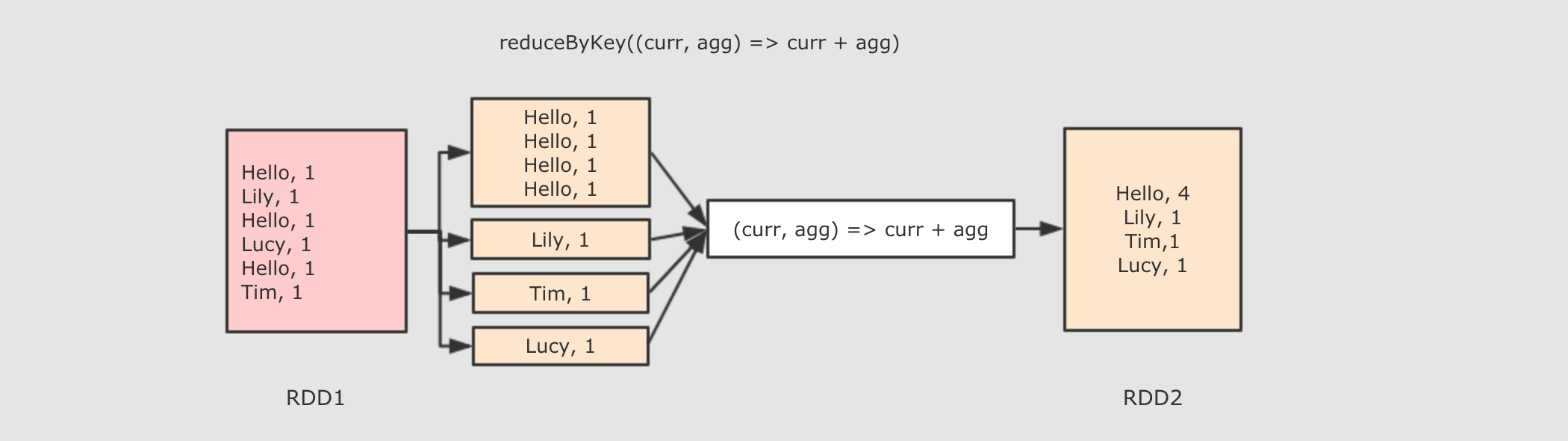
|
|

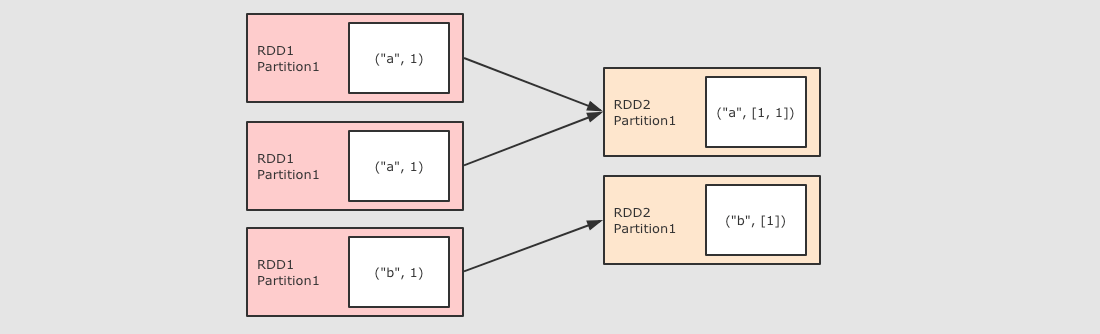
|
|
|
val combineRdd = rdd.combineByKey(
score => (score, 1),
(scoreCount: (Double, Int),newScore) => (scoreCount._1 + newScore, scoreCount._2 + 1),
(scoreCount1: (Double, Int), scoreCount2: (Double, Int)) =>
(scoreCount1._1 + scoreCount2._1, scoreCount1._2 + scoreCount2._2)
)
val meanRdd = combineRdd.map(score => (score._1, score._2._1 / score._2._2))
meanRdd.collect()
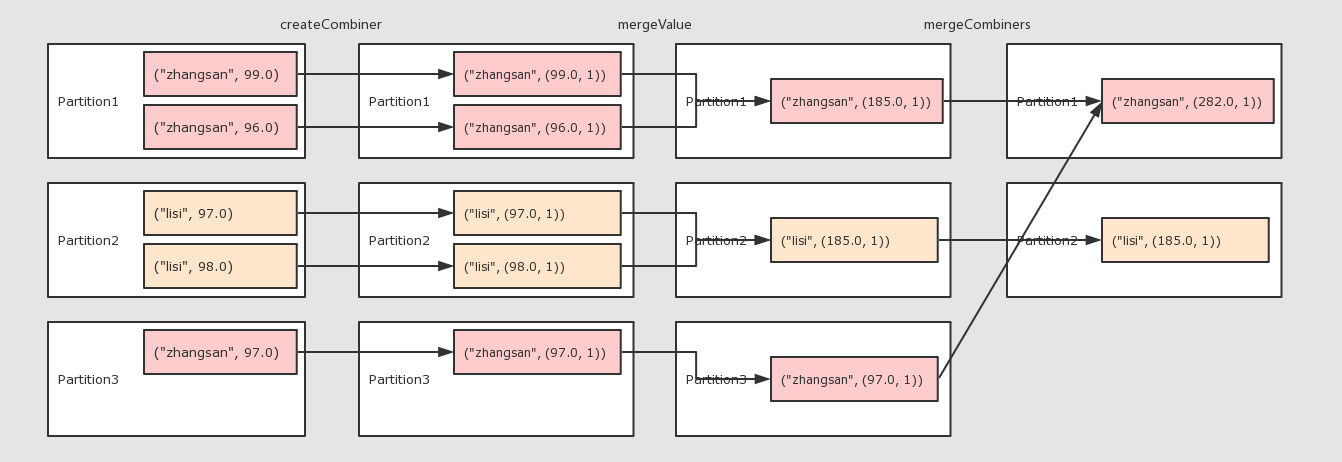
- 作用
-
-
對數據集按照 Key 進行聚合
-
- 調用
-
-
combineByKey(createCombiner, mergeValue, mergeCombiners, [partitioner], [mapSideCombiner], [serializer])
-
- 參數
-
-
createCombiner將 Value 進行初步轉換 -
mergeValue在每個分區把上一步轉換的結果聚合 -
mergeCombiners在所有分區上把每個分區的聚合結果聚合 -
partitioner可選, 分區函數 -
mapSideCombiner可選, 是否在 Map 端 Combine -
serializer序列化器
-
- 注意點
-
-
combineByKey的要點就是三個函數的意義要理解 -
groupByKey,reduceByKey的底層都是combineByKey
-
aggregateByKey()
val rdd = sc.parallelize(Seq(("手機", 10.0), ("手機", 15.0), ("電腦", 20.0)))
val result = rdd.aggregateByKey(0.8)(
seqOp = (zero, price) => price * zero,
combOp = (curr, agg) => curr + agg
).collect()
println(result)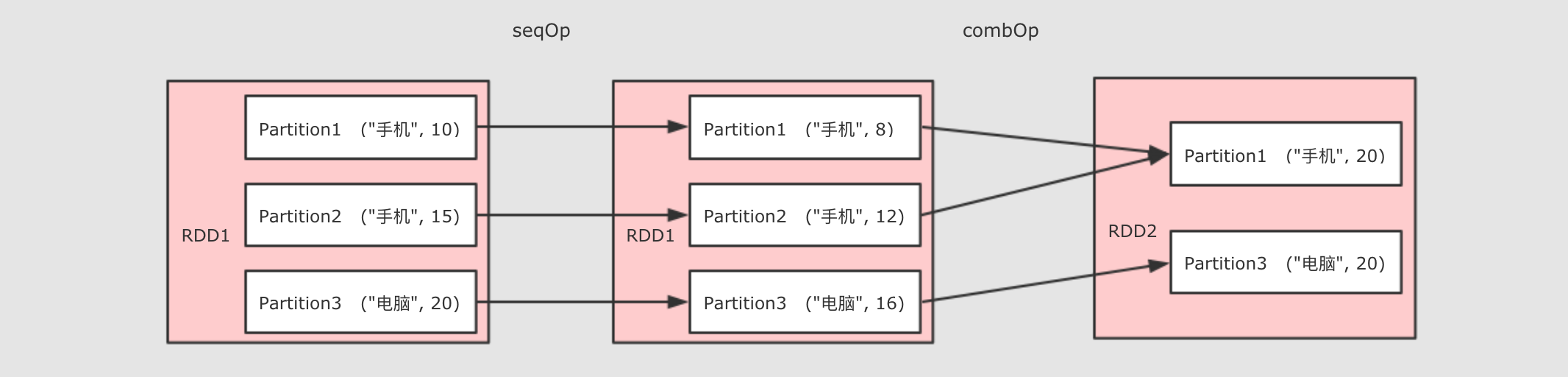
- 作用
-
-
聚合所有 Key 相同的 Value, 換句話說, 按照 Key 聚合 Value
-
- 調用
-
-
rdd.aggregateByKey(zeroValue)(seqOp, combOp)
-
- 參數
-
-
zeroValue初始值 -
seqOp轉換每一個值的函數 -
comboOp將轉換過的值聚合的函數
-
注意點
* 爲什麼需要兩個函數?
aggregateByKey 運行將一個`RDD[(K, V)]聚合爲`RDD[(K, U)], 如果要做到這件事的話, 就需要先對數據做一次轉換, 將每條數據從`V`轉爲`U`, `seqOp`就是幹這件事的
** 當`seqOp`的事情結束以後, `comboOp`把其結果聚合
-
和 reduceByKey 的區別::
-
aggregateByKey 最終聚合結果的類型和傳入的初始值類型保持一致
-
reduceByKey 在集合中選取第一個值作爲初始值, 並且聚合過的數據類型不能改變
-
foldByKey(zeroValue)((V, V) ⇒ V)
sc.parallelize(Seq(("a", 1), ("a", 1), ("b", 1)))
.foldByKey(zeroValue = 10)( (curr, agg) => curr + agg )
.collect()
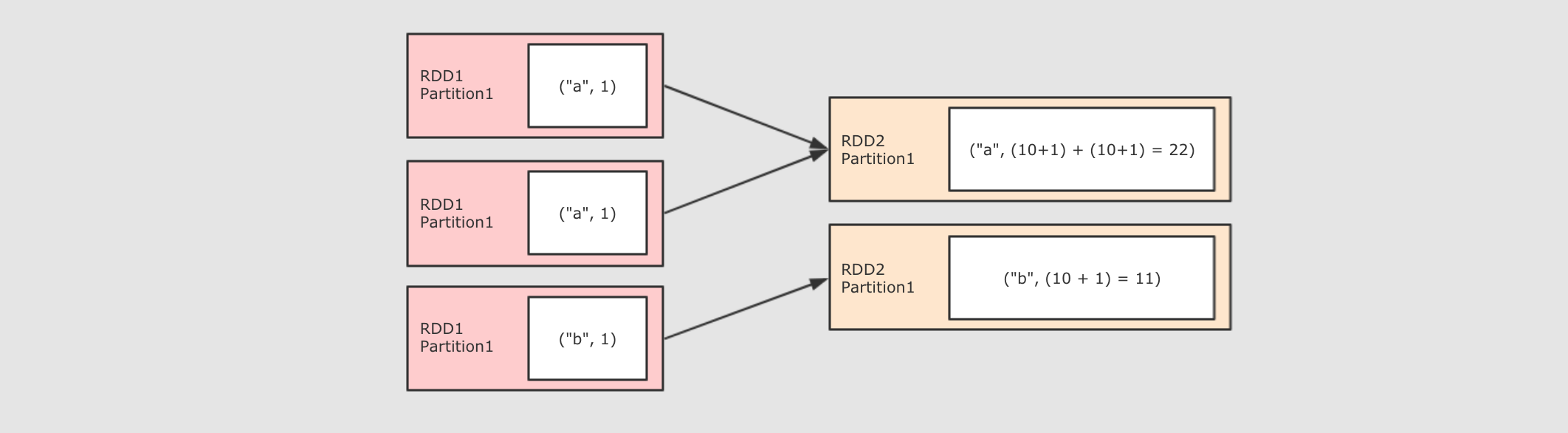
- 作用
-
-
和 ReduceByKey 是一樣的, 都是按照 Key 做分組去求聚合, 但是 FoldByKey 的不同點在於可以指定初始值
-
- 調用
-
foldByKey(zeroValue)(func) - 參數
-
-
zeroValue初始值 -
funcseqOp 和 combOp 相同, 都是這個參數
-
- 注意點
-
-
FoldByKey 是 AggregateByKey 的簡化版本, seqOp 和 combOp 是同一個函數
-
FoldByKey 指定的初始值作用於每一個 Value
-
join(other, numPartitions)
val rdd1 = sc.parallelize(Seq(("a", 1), ("a", 2), ("b", 1)))
val rdd2 = sc.parallelize(Seq(("a", 10), ("a", 11), ("a", 12)))
rdd1.join(rdd2).collect()
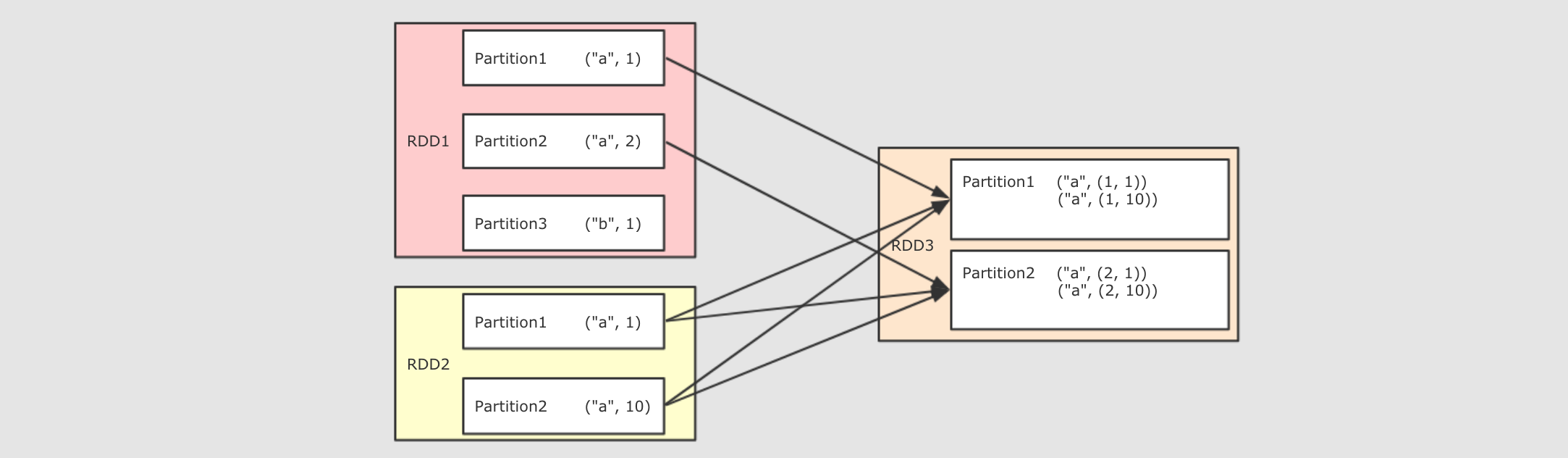
- 作用
-
-
將兩個 RDD 按照相同的 Key 進行連接
-
- 調用
-
join(other, [partitioner or numPartitions]) - 參數
-
-
other其它 RDD -
partitioner or numPartitions可選, 可以通過傳遞分區函數或者分區數量來改變分區
-
- 注意點
-
-
Join 有點類似於 SQL 中的內連接, 只會再結果中包含能夠連接到的 Key
-
Join 的結果是一個笛卡爾積形式, 例如`"a", 1), ("a", 2
和"a", 10), ("a", 11的 Join 結果集是 `"a", 1, 10), ("a", 1, 11), ("a", 2, 10), ("a", 2, 11
-
cogroup(other, numPartitions)
val rdd1 = sc.parallelize(Seq(("a", 1), ("a", 2), ("a", 5), ("b", 2), ("b", 6), ("c", 3), ("d", 2)))
val rdd2 = sc.parallelize(Seq(("a", 10), ("b", 1), ("d", 3)))
val rdd3 = sc.parallelize(Seq(("b", 10), ("a", 1)))
val result1 = rdd1.cogroup(rdd2).collect()
val result2 = rdd1.cogroup(rdd2, rdd3).collect()
/*
執行結果:
Array(
(d,(CompactBuffer(2),CompactBuffer(3))),
(a,(CompactBuffer(1, 2, 5),CompactBuffer(10))),
(b,(CompactBuffer(2, 6),CompactBuffer(1))),
(c,(CompactBuffer(3),CompactBuffer()))
)
*/
println(result1)
/*
執行結果:
Array(
(d,(CompactBuffer(2),CompactBuffer(3),CompactBuffer())),
(a,(CompactBuffer(1, 2, 5),CompactBuffer(10),CompactBuffer(1))),
(b,(CompactBuffer(2, 6),CompactBuffer(1),Co…
*/
println(result2)
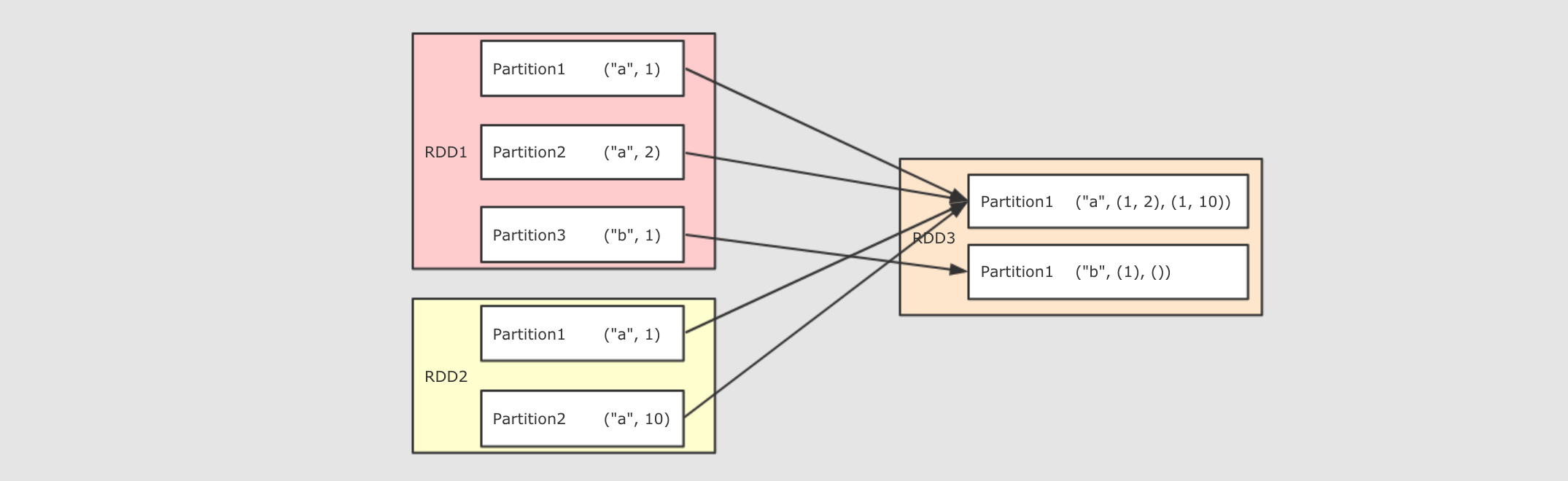
- 作用
-
-
多個 RDD 協同分組, 將多個 RDD 中 Key 相同的 Value 分組
-
- 調用
-
-
cogroup(rdd1, rdd2, rdd3, [partitioner or numPartitions])
-
- 參數
-
-
rdd…最多可以傳三個 RDD 進去, 加上調用者, 可以爲四個 RDD 協同分組 -
partitioner or numPartitions可選, 可以通過傳遞分區函數或者分區數來改變分區
-
- 注意點
-
-
對 RDD1, RDD2, RDD3 進行 cogroup, 結果中就一定會有三個 List, 如果沒有 Value 則是空 List, 這一點類似於 SQL 的全連接, 返回所有結果, 即使沒有關聯上
-
CoGroup 是一個需要 Shuffled 的操作
-
cartesian(other)
(RDD[T], RDD[U]) ⇒ RDD[(T, U)] 生成兩個 RDD 的笛卡爾積
sortBy(ascending, numPartitions)
val rdd1 = sc.parallelize(Seq(("a", 3), ("b", 2), ("c", 1)))
val sortByResult = rdd1.sortBy( item => item._2 ).collect()
val sortByKeyResult = rdd1.sortByKey().collect()
println(sortByResult)
println(sortByKeyResult)
- 作用
-
-
排序相關相關的算子有兩個, 一個是`sortBy`, 另外一個是`sortByKey`
-
- 調用
-
sortBy(func, ascending, numPartitions) - 參數
-
-
`func`通過這個函數返回要排序的字段
-
`ascending`是否升序
-
`numPartitions`分區數
-
- 注意點
-
-
普通的 RDD 沒有`sortByKey`, 只有 Key-Value 的 RDD 纔有
-
`sortBy`可以指定按照哪個字段來排序, `sortByKey`直接按照 Key 來排序
-
partitionBy(partitioner)
使用用傳入的 partitioner 重新分區, 如果和當前分區函數相同, 則忽略操作
coalesce(numPartitions)
減少分區數
val rdd = sc.parallelize(Seq(("a", 3), ("b", 2), ("c", 1)))
val oldNum = rdd.partitions.length
val coalesceRdd = rdd.coalesce(4, shuffle = true)
val coalesceNum = coalesceRdd.partitions.length
val repartitionRdd = rdd.repartition(4)
val repartitionNum = repartitionRdd.partitions.length
print(oldNum, coalesceNum, repartitionNum)
- 作用
-
-
一般涉及到分區操作的算子常見的有兩個,
repartitioin和coalesce, 兩個算子都可以調大或者調小分區數量
-
- 調用
-
-
repartitioin(numPartitions) -
coalesce(numPartitions, shuffle)
-
- 參數
-
-
numPartitions新的分區數 -
shuffle是否 shuffle, 如果新的分區數量比原分區數大, 必須 Shuffled, 否則重分區無效
-
- 注意點
-
-
repartition和coalesce的不同就在於coalesce可以控制是否 Shuffle -
repartition是一個 Shuffled 操作
-
repartition(numPartitions)
重新分區
repartitionAndSortWithinPartitions
重新分區的同時升序排序, 在partitioner中排序, 比先重分區再排序要效率高, 建議使用在需要分區後再排序的場景使用
2.2. Action 算子
| Action function | 解釋 |
|---|---|
|
|
|
以數組的形式返回數據集中所有元素 |
|
返回元素個數 |
|
返回第一個元素 |
|
返回前 N 個元素 |
|
類似於 sample, 區別在這是一個Action, 直接返回結果 |
|
指定初始值和計算函數, 摺疊聚合整個數據集 |
|
將結果存入 path 對應的文件中 |
|
將結果存入 path 對應的 Sequence 文件中 |
|
|
|
遍歷每一個元素 |
- 應用
-
```scala val rdd = sc.parallelize(Seq(("手機", 10.0), ("手機", 15.0), ("電腦", 20.0))) // 結果: Array((手機,10.0), (手機,15.0), (電腦,20.0)) println(rdd.collect()) // 結果: Array((手機,10.0), (手機,15.0)) println(rdd.take(2)) // 結果: (手機,10.0) println(rdd.first()) ```
- RDD 的算子大部分都會生成一些專用的 RDD
-
-
map,flatMap,filter等算子會生成MapPartitionsRDD -
coalesce,repartition等算子會生成CoalescedRDD
-
- 常見的 RDD 有兩種類型
-
-
轉換型的 RDD, Transformation
-
動作型的 RDD, Action
-
- 常見的 Transformation 類型的 RDD
-
-
map
-
flatMap
-
filter
-
groupBy
-
reduceByKey
-
- 常見的 Action 類型的 RDD
-
-
collect
-
countByKey
-
reduce
-
2.3. RDD 對不同類型數據的支持
-
理解 RDD 對 Key-Value 類型的數據是有專門支持的
-
理解 RDD 對數字類型也有專門的支持
- 一般情況下 RDD 要處理的數據有三類
- RDD 的算子設計對這三類不同的數據分別都有支持
- RDD 對鍵值對數據的額外支持
-
鍵值型數據本質上就是一個二元元組, 鍵值對類型的 RDD 表示爲
RDD[(K, V)]RDD 對鍵值對的額外支持是通過隱式支持來完成的, 一個
RDD[(K, V)], 可以被隱式轉換爲一個PairRDDFunctions對象, 從而調用其中的方法.![3b365c28403495cb8d07a2ee5d0a6376]()
- 既然對鍵值對的支持是通過
PairRDDFunctions提供的, 那麼從PairRDDFunctions中就可以看到這些支持有什麼
類別 算子 聚合操作
reduceByKeyfoldByKeycombineByKey分組操作
cogroupgroupByKey連接操作
joinleftOuterJoinrightOuterJoin排序操作
sortBysortByKeyAction
countByKeytakecollect - 既然對鍵值對的支持是通過
- RDD 對數字型數據的額外支持

3. RDD 的 Shuffle 和分區
-
RDD 的分區操作
-
Shuffle 的原理
- 分區的作用
-
RDD 使用分區來分佈式並行處理數據, 並且要做到儘量少的在不同的 Executor 之間使用網絡交換數據, 所以當使用 RDD 讀取數據的時候, 會盡量的在物理上靠近數據源, 比如說在讀取 Cassandra 或者 HDFS 中數據的時候, 會盡量的保持 RDD 的分區和數據源的分區數, 分區模式等一一對應
- 分區和 Shuffle 的關係
-
分區的主要作用是用來實現並行計算, 本質上和 Shuffle 沒什麼關係, 但是往往在進行數據處理的時候, 例如`reduceByKey`, `groupByKey`等聚合操作, 需要把 Key 相同的 Value 拉取到一起進行計算, 這個時候因爲這些 Key 相同的 Value 可能會坐落於不同的分區, 於是理解分區才能理解 Shuffle 的根本原理
- Spark 中的 Shuffle 操作的特點
-
-
只有
Key-Value型的 RDD 纔會有 Shuffle 操作, 例如RDD[(K, V)], 但是有一個特例, 就是repartition算子可以對任何數據類型 Shuffle -
早期版本 Spark 的 Shuffle 算法是
Hash base shuffle, 後來改爲Sort base shuffle, 更適合大吞吐量的場景
-
3.1. RDD 的分區操作
- 查看分區數
-
scala> sc.parallelize(1 to 100).count res0: Long = 100![873af6194db362a1ab5432372aa8bd21]()
之所以會有 8 個 Tasks, 是因爲在啓動的時候指定的命令是
spark-shell --master local[8], 這樣會生成 1 個 Executors, 這個 Executors 有 8 個 Cores, 所以默認會有 8 個 Tasks, 每個 Cores 對應一個分區, 每個分區對應一個 Tasks, 可以通過rdd.partitions.size來查看分區數量![a41901e5af14f37c88b3f1ea9b97fbfb]()
同時也可以通過 spark-shell 的 WebUI 來查看 Executors 的情況
![24b2646308923d7549a7758f7550e0a8]()



默認的分區數量是和 Cores 的數量有關的, 也可以通過如下三種方式修改或者重新指定分區數量
- 創建 RDD 時指定分區數
scala> rdd1.partitions.size
res1: Int = 6
scala> val rdd2 = sc.textFile(“hdfs:///dataset/wordcount.txt”, 6)
rdd2: org.apache.spark.rdd.RDD[String] = hdfs:///dataset/wordcount.txt MapPartitionsRDD[3] at textFile at <console>:24
scala> rdd2.partitions.size
res2: Int = 7
rdd1 是通過本地集合創建的, 創建的時候通過第二個參數指定了分區數量. rdd2 是通過讀取 HDFS 中文件創建的, 同樣通過第二個參數指定了分區數, 因爲是從 HDFS 中讀取文件, 所以最終的分區數是由 Hadoop 的 InputFormat 來指定的, 所以比指定的分區數大了一個.
scala> source.partitions.size
res0: Int = 6
scala> val noShuffleRdd = source.coalesce(numPartitions=8, shuffle=false)
noShuffleRdd: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[1] at coalesce at <console>:26
scala> noShuffleRdd.toDebugString (1)
res1: String =
(6) CoalescedRDD[1] at coalesce at <console>:26 []
| ParallelCollectionRDD[0] at parallelize at <console>:24 []
scala> val noShuffleRdd = source.coalesce(numPartitions=8, shuffle=false)
noShuffleRdd: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[1] at coalesce at <console>:26
scala> shuffleRdd.toDebugString (2)
res3: String =
(8) MapPartitionsRDD[5] at coalesce at <console>:26 []
| CoalescedRDD[4] at coalesce at <console>:26 []
| ShuffledRDD[3] at coalesce at <console>:26 []
±(6) MapPartitionsRDD[2] at coalesce at <console>:26 []
| ParallelCollectionRDD[0] at parallelize at <console>:24 []
scala> noShuffleRdd.partitions.size (3)
res4: Int = 6
scala> shuffleRdd.partitions.size
res5: Int = 8
| 1 | 如果 shuffle 參數指定爲 false, 運行計劃中確實沒有 ShuffledRDD, 沒有 shuffled 這個過程 |
| 2 | 如果 shuffle 參數指定爲 true, 運行計劃中有一個 ShuffledRDD, 有一個明確的顯式的 shuffled 過程 |
| 3 | 如果 shuffle 參數指定爲 false 卻增加了分區數, 分區數並不會發生改變, 這是因爲增加分區是一個寬依賴, 沒有 shuffled 過程無法做到, 後續會詳細解釋寬依賴的概念 |
repartition 算子指定repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]repartition 算子本質上就是 coalesce(numPartitions, shuffle = true)

scala> val source = sc.parallelize(1 to 100, 6)
source: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[7] at parallelize at <console>:24
scala> source.partitions.size
res7: Int = 6
scala> source.repartition(100).partitions.size (1)
res8: Int = 100
scala> source.repartition(1).partitions.size (2)
res9: Int = 1
| 1 | 增加分區有效 |
| 2 | 減少分區有效 |
repartition 算子無論是增加還是減少分區都是有效的, 因爲本質上 repartition 會通過 shuffle 操作把數據分發給新的 RDD 的不同的分區, 只有 shuffle 操作纔可能做到增大分區數,
默認情況下, 分區函數是 RoundRobin, 如果希望改變分區函數, 也就是數據分佈的方式, 可以通過自定義分區函數來實現

3.2. RDD 的 Shuffle 是什麼
val sourceRdd = sc.textFile("hdfs://node01:9020/dataset/wordcount.txt")
val flattenCountRdd = sourceRdd.flatMap(_.split(" ")).map((_, 1))
val aggCountRdd = flattenCountRdd.reduceByKey(_ + _)
val result = aggCountRdd.collect

reduceByKey 這個算子本質上就是先按照 Key 分組, 後對每一組數據進行 reduce, 所面臨的挑戰就是 Key 相同的所有數據可能分佈在不同的 Partition 分區中, 甚至可能在不同的節點中, 但是它們必須被共同計算.
爲了讓來自相同 Key 的所有數據都在 reduceByKey 的同一個 reduce 中處理, 需要執行一個 all-to-all 的操作, 需要在不同的節點(不同的分區)之間拷貝數據, 必須跨分區聚集相同 Key 的所有數據, 這個過程叫做 Shuffle.
3.3. RDD 的 Shuffle 原理
Spark 的 Shuffle 發展大致有兩個階段: Hash base shuffle 和 Sort base shuffle
- Hash base shuffle
-
![2daf43cc1750fffab62ae5e16fab54c2]()
大致的原理是分桶, 假設 Reducer 的個數爲 R, 那麼每個 Mapper 有 R 個桶, 按照 Key 的 Hash 將數據映射到不同的桶中, Reduce 找到每一個 Mapper 中對應自己的桶拉取數據.
假設 Mapper 的個數爲 M, 整個集羣的文件數量是
M * R, 如果有 1,000 個 Mapper 和 Reducer, 則會生成 1,000,000 個文件, 這個量非常大了.過多的文件會導致文件系統打開過多的文件描述符, 佔用系統資源. 所以這種方式並不適合大規模數據的處理, 只適合中等規模和小規模的數據處理, 在 Spark 1.2 版本中廢棄了這種方式.
- Sort base shuffle
-
![94f038994f8553dd32370ae78878d038]()
對於 Sort base shuffle 來說, 每個 Map 側的分區只有一個輸出文件, Reduce 側的 Task 來拉取, 大致流程如下
-
Map 側將數據全部放入一個叫做 AppendOnlyMap 的組件中, 同時可以在這個特殊的數據結構中做聚合操作
-
然後通過一個類似於 MergeSort 的排序算法 TimSort 對 AppendOnlyMap 底層的 Array 排序
-
先按照 Partition ID 排序, 後按照 Key 的 HashCode 排序
-
-
最終每個 Map Task 生成一個 輸出文件, Reduce Task 來拉取自己對應的數據
從上面可以得到結論, Sort base shuffle 確實可以大幅度減少所產生的中間文件, 從而能夠更好的應對大吞吐量的場景, 在 Spark 1.2 以後, 已經默認採用這種方式.
但是需要大家知道的是, Spark 的 Shuffle 算法並不只是這一種, 即使是在最新版本, 也有三種 Shuffle 算法, 這三種算法對每個 Map 都只產生一個臨時文件, 但是產生文件的方式不同, 一種是類似 Hash 的方式, 一種是剛纔所說的 Sort, 一種是對 Sort 的一種優化(使用 Unsafe API 直接申請堆外內存)
-


4. 緩存
-
緩存的意義
-
緩存相關的 API
-
緩存級別以及最佳實踐
4.1. 緩存的意義
- 使用緩存的原因 - 多次使用 RDD
val interimRDD = sc.textFile(“dataset/access_log_sample.txt”)
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg) (1)
val resultLess = interimRDD.sortBy(item => item._2, ascending = true).first()
val resultMore = interimRDD.sortBy(item => item._2, ascending = false).first()
println(s"出現次數最少的 IP : resultMore")
sc.stop()
| 1 | 這是一個 Shuffle 操作, Shuffle 操作會在集羣內進行數據拷貝 |
在上述代碼中, 多次使用到了 interimRDD, 導致文件讀取兩次, 計算兩次, 有沒有什麼辦法增進上述代碼的性能?

當在計算 RDD3 的時候如果出錯了, 會怎麼進行容錯?
會再次計算 RDD1 和 RDD2 的整個鏈條, 假設 RDD1 和 RDD2 是通過比較昂貴的操作得來的, 有沒有什麼辦法減少這種開銷?
上述兩個問題的解決方案其實都是 緩存, 除此之外, 使用緩存的理由還有很多, 但是總結一句, 就是緩存能夠幫助開發者在進行一些昂貴操作後, 將其結果保存下來, 以便下次使用無需再次執行, 緩存能夠顯著的提升性能.
所以, 緩存適合在一個 RDD 需要重複多次利用, 並且還不是特別大的情況下使用, 例如迭代計算等場景.
4.2. 緩存相關的 API
- 可以使用
cache方法進行緩存
val interimRDD = sc.textFile(“dataset/access_log_sample.txt”)
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
.cache() (1)
val resultLess = interimRDD.sortBy(item => item._2, ascending = true).first()
val resultMore = interimRDD.sortBy(item => item._2, ascending = false).first()
println(s"出現次數最少的 IP : resultMore")
sc.stop()
| 1 | 緩存 |
方法簽名如下
cache(): this.type = persist()cache 方法其實是 persist 方法的一個別名

val interimRDD = sc.textFile(“dataset/access_log_sample.txt”)
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
.persist(StorageLevel.MEMORY_ONLY) (1)
val resultLess = interimRDD.sortBy(item => item._2, ascending = true).first()
val resultMore = interimRDD.sortBy(item => item._2, ascending = false).first()
println(s"出現次數最少的 IP : $resultLess, 出現次數最多的 IP : $resultMore")
sc.stop()
| 1 | 緩存 |
方法簽名如下
persist(): this.type
persist(newLevel: StorageLevel): this.typepersist 方法其實有兩種形式, persist() 是 persist(newLevel: StorageLevel) 的一個別名, persist(newLevel: StorageLevel) 能夠指定緩存的級別

val interimRDD = sc.textFile(“dataset/access_log_sample.txt”)
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
.persist()
interimRDD.unpersist() (1)
val resultLess = interimRDD.sortBy(item => item._2, ascending = true).first()
val resultMore = interimRDD.sortBy(item => item._2, ascending = false).first()
println(s"出現次數最少的 IP : resultMore")
sc.stop()
| 1 | 清理緩存 |
根據緩存級別的不同, 緩存存儲的位置也不同, 但是使用 unpersist 可以指定刪除 RDD 對應的緩存信息, 並指定緩存級別爲 NONE
4.3. 緩存級別
其實如何緩存是一個技術活, 有很多細節需要思考, 如下
-
是否使用磁盤緩存?
-
是否使用內存緩存?
-
是否使用堆外內存?
-
緩存前是否先序列化?
-
是否需要有副本?
如果要回答這些信息的話, 可以先查看一下 RDD 的緩存級別對象
val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string")
val sc = new SparkContext(conf)
val interimRDD = sc.textFile(“dataset/access_log_sample.txt”)
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
.persist()
println(interimRDD.getStorageLevel)
sc.stop()
打印出來的對象是 StorageLevel, 其中有如下幾個構造參數

根據這幾個參數的不同, StorageLevel 有如下幾個枚舉對象

| 緩存級別 | userDisk 是否使用磁盤 |
useMemory 是否使用內存 |
useOffHeap 是否使用堆外內存 |
deserialized 是否以反序列化形式存儲 |
replication 副本數 |
|---|---|---|---|---|---|
|
false |
false |
false |
false |
1 |
|
true |
false |
false |
false |
1 |
|
true |
false |
false |
false |
2 |
|
false |
true |
false |
true |
1 |
|
false |
true |
false |
true |
2 |
|
false |
true |
false |
false |
1 |
|
false |
true |
false |
false |
2 |
|
true |
true |
false |
true |
1 |
|
true |
true |
false |
true |
2 |
|
true |
true |
false |
false |
1 |
|
true |
true |
false |
false |
2 |
|
true |
true |
true |
false |
1 |
5. Checkpoint
-
Checkpoint 的作用
-
Checkpoint 的使用
5.1. Checkpoint 的作用
Checkpoint 的主要作用是斬斷 RDD 的依賴鏈, 並且將數據存儲在可靠的存儲引擎中, 例如支持分佈式存儲和副本機制的 HDFS.
- Checkpoint 的方式
- 什麼是斬斷依賴鏈
- Checkpoint 和 Cache 的區別
5.2. 使用 Checkpoint
val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string")
val sc = new SparkContext(conf)
sc.setCheckpointDir("checkpoint") (1)
val interimRDD = sc.textFile(“dataset/access_log_sample.txt”)
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
interimRDD.checkpoint() (2)
interimRDD.collect().foreach(println(_))
sc.stop()
| 1 | 在使用 Checkpoint 之前需要先設置 Checkpoint 的存儲路徑, 而且如果任務在集羣中運行的話, 這個路徑必須是 HDFS 上的路徑 |
| 2 | 開啓 Checkpoint |
|
一個小細節
|
interimRDD.checkpoint()
interimRDD.collect().foreach(println(_))
| 1 | checkpoint 之前先 cache 一下, 準沒錯 |
應該在 checkpoint 之前先 cache 一下, 因爲 checkpoint 會重新計算整個 RDD 的數據然後再存入 HDFS 等地方.
所以上述代碼中如果 checkpoint 之前沒有 cache, 則整個流程會被計算兩次, 一次是 checkpoint, 另外一次是 collect
end