




當前網絡與信息安全領域,正在面臨多種挑戰。一方面,企業和組織安全體系架構日趨複雜,各種類型的安全數據越來越多,隨着內控與合規的深入,傳統的分析能力明顯力不從心,越來越需要分析更多的安全信息、並且要更加快速的做出判定和響應。另一方面,新型威脅的興起,高級可持續攻擊要求有長時間的數據才能分析入侵行爲和評估遭受的損失。傳統的SIEM很難處理多樣化的非結構數據,並且傳統的應用/數據庫架構侷限了系統的性能,其能存儲的歷史數據時長、存儲事件的彙總度、查詢分析的速度均受到極大的限制。信息安全也面臨大數據帶來的挑戰。
我們需要更深層次的事件關聯處理、分析和展現,而當前分佈式計算,存儲和通信,內存計算,智能分析等技術已經逐步成熟應用,安全數據分析需要使用這些新技術在事件關聯、處理和展現能力上進行提升。
大數據安全分析將包括以下幾個應用領域:
- 安全事件管理和安全管理平臺;
- APT高級持續威脅檢測,結合全包捕獲技術;
- 0day惡意代碼分析,結合沙箱技術;
- 網絡取證分析;
- 大規模用戶行爲分析,結合機器學習技術;
- 安全情報服務;
- 業務風險安全分析等。
目前,基於Hadoop生態圈的大數據平臺已經被業界廣泛使用,部署規模從幾十臺,到幾萬臺,可以存儲和分析PB級別數據,從網頁日誌分析,搜索引擎,視頻和語音檢索都需要操作大量數據資源。而這些數據全部來由Hadoop平臺來運算。Hadoop生態圈也在不斷完善,能夠同時實現並行計算、高速計算、流式計算等計算框架。
安全牛整合了業內資深大數據專家的意見,向大家推薦一個基於Hadoop的安全大數據平臺架構,歡迎業界同仁和企業客戶與我們共同探討。近期還將邀請這方面的專家與大家進行更深入的講座和交流。
安全大數據平臺架構
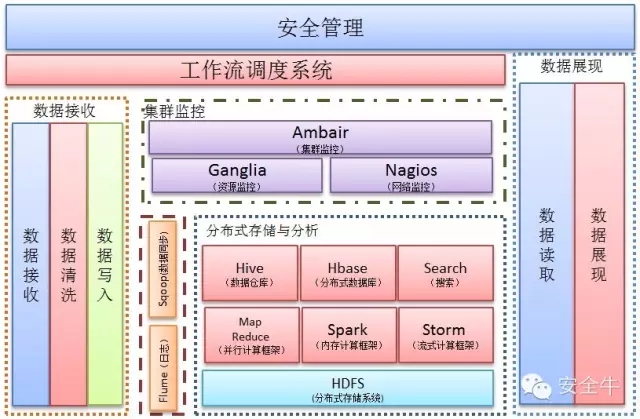
圖 1
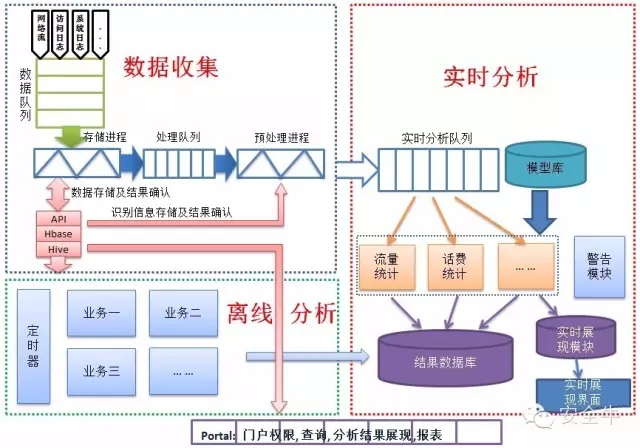
圖 2
大數據平臺總體概述
此平臺集數據採集、數據質量管理、數據存儲與分析、集羣監控、數據同步、數據展現、數據安全管理等於一身。在保證數據安全的前提下,實現從數據接收到存儲維護再到展現的數據管理功能。此平臺能夠對海量數據(包括結構化數據、半結構化數據、非結構化數據)進行存儲、維護挖掘等工作。使用目前最前沿的數據存數、分析、管理技術,以此爲基礎針對數據分析的實時性,分爲在線數據分析和離線數據分析。
在線數據分析:往往要求系統對新數據進行實時分析、實時展現,從而達到不影響用戶體驗的目的。
離線數據分析:對大多數反饋時間要求不高的應用,比如離線統計分析、機器學習等,應採用離線分析的方式。
具備以下特性:
- 先進的技術架構,基於Hadoop的先進分佈式計算及存儲框架;
- 先進的多層架構,系統維護簡單;
- 縱向、橫向擴展能力出衆,爲未來BI發展提供可能;
- 能做到5分鐘之內系統擴容,支撐更多終端。
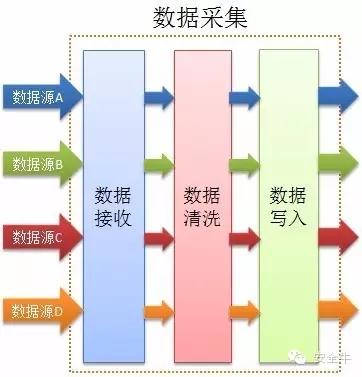
數據採集
數據採集
數據採集過程中分爲三個部分:第一部分收據接收、第二部分數據清洗校驗和第三部分數據寫入(寫入大數據平臺)。每個部分全部支持跨平臺(多種開發語言)、並行化,能夠使數據快速準確的寫入到大數據平臺中。
數據接收:能夠接收來自各種設備的所有類型的數據。
數據清洗:實現並行化數據的校驗,簡單處理等。
數據寫入:校驗好的數據通過數據寫入程序寫入大數據平臺。
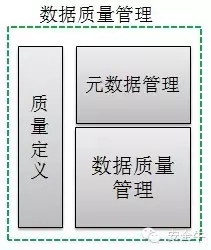
數據質量管理
數據質量管理
數據質量管理實現探查接收到的數據發現和評估數據的內容,根據企業的數據質量規則,將對數據進行質量檢測。
分佈式存儲與分析
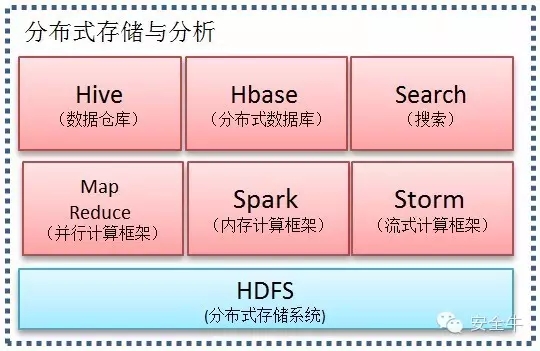
分佈式存儲與分析
A:大數據平臺使用分佈式文件系統(HDFS)作爲底層存儲。特點如下:
1. 支持多數據結構的存儲(結構化數據、半結構化數據、非結構化數據);
2. 存儲空間無限大;
3. 擴容簡易;
4. 自動化數據維護;
5. 支持大文件存儲;
6. 容錯性強。
B:MapReduce並行計算框架, 對海量數據進行分析計算。特點如下:
1. 移動計算(程序)到數據端,減少網絡使用;
2. 能夠快速並行的對海量數據進行分析計算;
3. 支持多種開發語言,程序編寫簡單。
C:Spark內存計算框架,對海量數據進行快快速計算。特點如下:
1. 支持並行計算;
2. 與MapReduce並行計算框架相比內存計算框架整合了內存計算的基元,計算速度更快。
D:Storm流數據處理框架,實現實時性數據處理。特點如下:
1. 簡單編程;
2. 多語言支持;
3. 支持水平擴展;
4. 容錯性強。
E:Hive數據倉庫,存儲結構化數據。
依賴於分佈式存儲和分佈式計算框架。主要功能爲將HQL(類SQL)轉換爲並行計算框架能夠識別的程序。
F:Hbase分佈式數據庫,主要以表格的形式存儲數據,存儲數據依賴於分佈式存儲。特點如下:
1. 實時相應讀取請求;
2. 數據表的行、列可以無限擴展;
3. 數據自動維護。
G:Elastic Search搜索,基於Lucene的搜索服務器。
它提供了一個分佈式多用戶能力的全文搜索引擎,基於RESTful web接口,可達到實時搜索的能力。
集羣監控
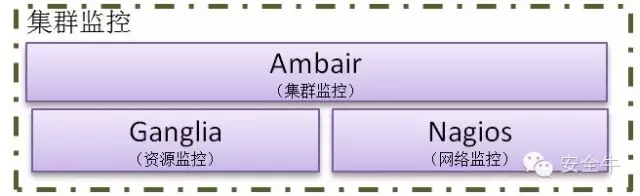
集羣監控
集羣監控管理由Ambari、Ganglia、Nagios組成。以實現對集羣的安裝部署、管理監控等功能。
Ganglia 主要對集羣的資源進行監控管理。包括CPU 資源、內存資源、網絡資源。監控資源使用百分比,高峯期等,並將此信息繪製成直觀、易於理解的統計圖。
Nagios 對於集羣的安全、資源使用值進行監控,在發生問題的情況下向有關的管理人員發送郵件給予提示。
Ambari 提供界面化的方式實現集羣安裝部署、管理維護、配置文件修改、集羣擴容等,同時與Ganglia、Nagios協同工作,實現對整個集羣的監控管理。作爲大數據平臺的核心控制系統,對大數據平臺的各個環節進行控制,且對運行過程中的各個組件的關係進行控制,同時對各個環節進行監控,通過監控異常報警來提高系統的穩定性和異常響應速度。
數據展現

數據展現
數據展現,實現將大數據平臺存儲的部分數據按着業務需求進行展示。
數據讀取,可實現根據業務需求對目標數據進行讀取,讀取後傳遞給數據展現模塊。
數據展現,或得到數據後可根據角色的不同展示不同的數據。
以上數據讀取和數據展現過程採用並行跨平臺化的處理方式實現。
數據安全
數據安全從最初的數據接入到最終的數據展現的安全問題。
中間包括數據源系統、數據收集、消息系統、實時處理、存儲、數據庫等各個模塊的數據安全以及整條線的安全。
工作流調度
工作流調度系統,主要實現對於數據接入、數據預分析、存儲、挖掘的各個環節進行可控的管理調度。
數據收集

數據採集
數據收集,主要實現各種設備的不同類型數據的收集工作。對收集到的數據初步校驗後存入大數據平臺。部分數據需要進一步預處理,可通過系統API進行再次預處理工作。同時可實現將數據存儲至Hbase數據庫或者Hive數據倉庫內。
離線處理

離線處理
離線處理,主要實現對現有已經存儲至大數據平臺的數據進行分析計算。用於對實時性要求不高的業務需求。可實現預測性分析、數據挖掘等操作。
實時分析
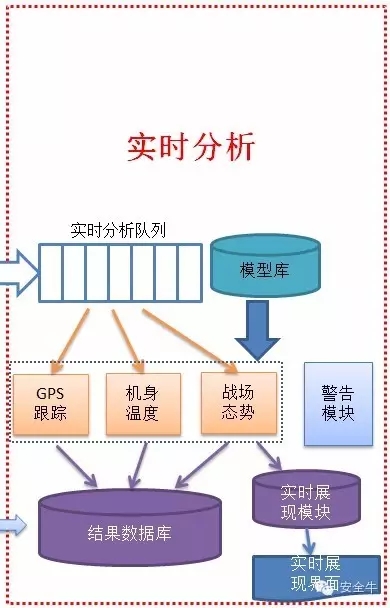
實時分析
實時分析,用於實時顯示動態數據信息,可以用於實現數據可視化業務的需求。可對接收到的數據進行實時分析,分析完成後存入結果數據庫或者直接顯示到可視化界面中。