




關於Hbase二級索引
HBase 是一個列存數據庫,每行數據只有一個主鍵RowKey,無法依據指定列的數據進行檢索。查詢時需要通過RowKey進行檢索,然後查看指定列的數據是什麼,效率低下。在實際應用中,我們經常需要根據指定列進行檢索,或者幾個列進行組合檢索,這就提出了建立 HBase 二級索引的需求。
二級索引構建方式:表索引、列索引、全文索引
- 表索引是將索引數據單獨存儲爲一張表,通過 HBase Coprocessor 生成並訪問索引數據。
- 列索引是將索引數據與源數據存儲在相同的 Region 裏,索引數據定義爲一個單獨的列族,也是利用 Coprocessor 來生成並訪問索引數據。對於表索引,源數據表與索引表的數據一致性很難保證,訪問兩張不同的表也會增加 IO 開銷和遠程調用的次數。對於列索引,單表的數據容量會急劇增加,對同一 Region 裏的多個列族進行 Split 或 Merge 等操作時可能會造成數據丟失或不一致。
- 全文索引:以CDH5中的Lily HBase Indexer服務實現,其使用SolrCloud存儲HBase的索引數據,Indexer索引和搜索不會影響HBase運行的穩定性和HBase數據寫入的吞吐量,因爲索引和搜索過程是完全分開並且異步的。Lily HBase Indexer在CDH5中運行必須依賴HBase、SolrCloud和Zookeeper服務。
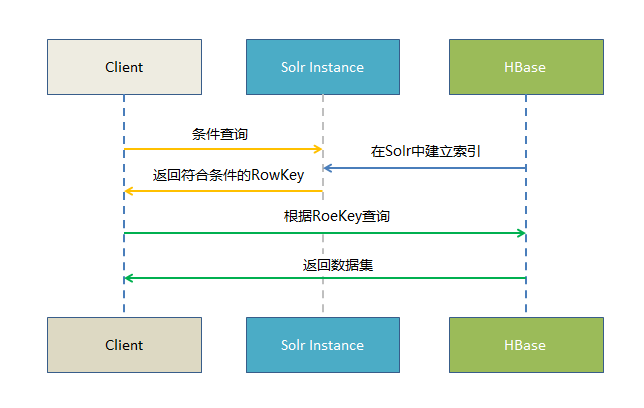
關於Key-Value Indexer組件
CDH官方文檔
hbase-indexer官方WIKI
參考博客:Email
Indexing Using Cloudera Search and HBase
參考博客: Cloudera Search Solr初探
參考博客:一種基於UDH Search的HBase二級索引構建方案
CDH5.4中的Key-Value Indexer使用的是Lily HBase NRT Indexer服務,Lily HBase Indexer是一款靈活的、可擴展的、高容錯的、事務性的,並且近實時的處理HBase列索引數據的分佈式服務軟件。它是NGDATA公司開發的Lily系統的一部分,已開放源代碼。
Lily HBase Indexer使用SolrCloud來存儲HBase的索引數據,當HBase執行寫入、更新或刪除操作時,Indexer通過HBase的replication功能來把這些操作抽象成一系列的Event事件,並用來保證寫入Solr中的HBase索引數據的一致性。並且Indexer支持用戶自定義的抽取,轉換規則來索引HBase列數據。Solr搜索結果會包含用戶自定義的columnfamily:qualifier字段結果,這樣應用程序就可以直接訪問HBase的列數據。而且Indexer索引和搜索不會影響HBase運行的穩定性和HBase數據寫入的吞吐量,因爲索引和搜索過程是完全分開並且異步的。
Lily HBase Indexer在CDH5中運行必須依賴HBase、SolrCloud和Zookeeper服務。
使用 Lily HBase Batch Indexer 進行索引
藉助 Cloudera Search,您可以利用 MapReduce 作業對 HBase 表進行批量索引。批量索引不需要以下操作:
- HBase 複製
- Lily HBase Indexer 服務
- 通過 Lily HBase Indexer 服務註冊 Lily HBase Indexer 配置
該索引器支持靈活的、自定義的、特定於應用程序的規則來將 HBase 數據提取、轉換和加載到 Solr。Solr 搜索結果可以包含到存儲在 HBase 中的數據的 columnFamily:qualifier 鏈接。這樣,應用程序可以使用搜索結果集直接訪問匹配的原始 HBase 單元格。
創建HBase集羣的表中列索引的步驟:
- 填充 HBase 表。
- 創建相應的 SolrCloud 集合
- 創建 Lily HBase Indexer 配置
- 創建 Morphline 配置文件
- 註冊 Lily HBase Indexer Configuration 和 Lily HBase Indexer Service
填充 HBase 表
在配置和啓動系統後,創建 HBase 表並向其添加行。例如:
對於每個新表,在需要通過發出格式命令進行索引的每個列系列上設置 REPLICATION_SCOPE:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
|
$ hbase shell #測試數據:列簇設置REPLICATION_SCOPE disable 'User' drop 'User' create 'User', {NAME => 'data', REPLICATION_SCOPE => 1} disable 'User' alter 'User', {NAME => 'detail', REPLICATION_SCOPE => 1} enable 'User' #新增CF disable 'User' alter 'User', {NAME => 'detail', REPLICATION_SCOPE => 1} enable 'User' #修改現有 disable 'User' alter 'User', {NAME => 'data', REPLICATION_SCOPE => 1} enable 'User' # 插入測試數據 put 'User','row1','data:name','u1' put 'User','row1','data:psd','123'
|
創建相應的 SolrCloud 集合
用於 HBase 索引的 SolrCloud 集合必須具有可容納 HBase 列系列的類型和要進行索引處理的限定符的 Solr 架構。若要開始,請考慮將包括一切 data 的字段添加到默認schema。一旦您決定採用一種schema,使用以下表單命令創建 SolrCloud 集合:
user示例配置
|
1 2
|
# 生成實體配置文件: solrctl instancedir --generate $HOME/hbase-indexer/User
|
編輯schema,需包含以下內容vim $HOME/hbase-indexer/User/conf/schema.xml
|
1 2 3 4 5 6 7
|
<!-- 綁定rowkey--> <field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="name" type="string" indexed="true" stored="true"/> <field name="psd" type="string" indexed="true" stored="true"/> <field name="address" type="string" indexed="true" stored="true"/> <field name="photo" type="string" indexed="true" stored="true"/>
|
|
1 2 3 4
|
# 創建 collection實例並將配置文件上傳到 zookeeper: solrctl instancedir --create User $HOME/hbase-indexer/User # 上傳到 zookeeper 之後,其他節點就可以從zookeeper下載配置文件。接下來創建 collection: solrctl collection --create User
|
注意
在schema.xml中uniqueKey必須爲rowkey,而rowkey默認使用’id’字段表示,中必須要有uniqueKey對應的id字段。
創建 Lily HBase Indexer 配置
Indexer-configuration官方參考
在HBase-Solr的安裝目錄/usr/lib/hbase-solr/下,創建morphline-hbase-mapper.xml文件,文件內容如下:
$ vim $HOME/hbase-indexer/morphline-hbase-mapper.xml
|
1 2 3 4 5 6 7 8 9 10 11 12
|
xml version="1.0" <!-- table:需要索引的HBase表名稱--> <!-- mapper:用來實現和讀取指定的Morphline配置文件類,固定爲MorphlineResultToSolrMapper--> <indexer table="User" mapper="com.ngdata.hbaseindexer.morphline.MorphlineResultToSolrMapper"> <!--param中的name參數用來指定當前配置爲morphlineFile文件 --> <!--value用來指定morphlines.conf文件的路徑,絕對或者相對路徑用來指定本地路徑,如果是使用Cloudera Manager來管理morphlines.conf就直接寫入值morphlines.conf"--> <param name="morphlineFile" value="morphlines.conf"/> <!-- The optional morphlineId identifies a morphline if there are multiple morphlines in morphlines.conf --> <param name="morphlineId" value="userMap"/> </indexer>
|
注意:當使用絕對或者相對路徑來指定路徑時,集羣中的其它機器也要在配置路徑上有該文件,如果是通過Cloudera Manager管理的話只需要在CM中修改後即可,CM會自動分發給集羣。當然該配置文件還有很多其它參數可以配置,擴展閱讀。
創建 Morphline 配置文件
Morphlines是一款開源的,用來減少構建hadoop ETL數據流程時間的應用程序。它可以替代傳統的通過MapReduce來抽取、轉換、加載數據的過程,提供了一系列的命令工具,
具體可以參見:http://kitesdk.org/docs/0.13.0/kite-morphlines/morphlinesReferenceGuide.html。
對於HBase的其提供了extractHBaseCells命令來讀取HBase的列數據。我們採用Cloudera Manager來管理morphlines.conf文件,使用CM來管理morphlines. conf文件除了上面提到的好處之外,還有一個好處就是當我們需要增加索引列的時候,如果採用本地路徑方式將需要重新註冊Lily HBase Indexer的配置文件,而採用CM管理的話只需要修改morphlines.conf文件後重啓Key-Value HBase Indexer服務即可。
具體操作爲:進入Key-Value Store Indexer面板->配置->服務範圍->Morphlines->Morphlines文件。在該選項加入如下配置:
注意:每個Collection對應一個morphline-hbase-mapper.xml
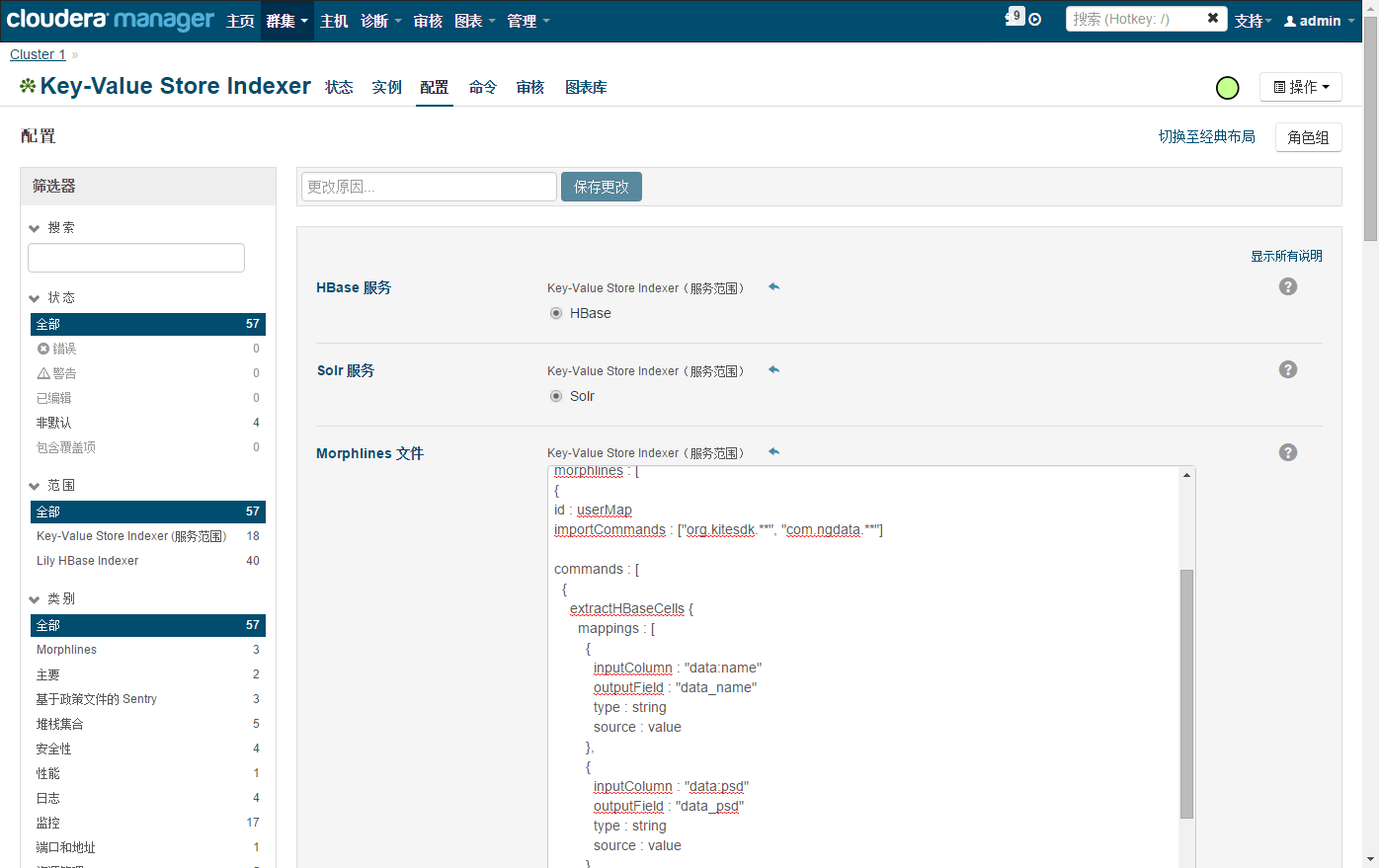
$ vim /$HOME/morphlines.conf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
|
SOLR_LOCATOR : { # Name of solr collection collection : User # ZooKeeper ensemble zkHost : "$ZK_HOST" } morphlines : [ { id : userMap importCommands : ["org.kitesdk.**", "com.ngdata.**"] commands : [ { extractHBaseCells { mappings : [ { inputColumn : "data:name" outputField : "data_name" type : string source : value }, { inputColumn : "data:psd" outputField : "data_psd" type : string source : value }, { inputColumn : "data:address" outputField : "data_address" type : string source : value }, { inputColumn : "data:photo" outputField : "data_photo" type : string source : value } ] } } { logDebug { format : "output record: {}", args : ["@{}"] } } ] } ]
|
註冊 Lily HBase Indexer Configuration 和 Lily HBase Indexer Service
當 Lily HBase Indexer 配置 XML文件的內容令人滿意,將它註冊到 Lily HBase Indexer Service。上傳 Lily HBase Indexer 配置 XML文件至 ZooKeeper,由給定的 SolrCloud 集合完成此操作。例如:
|
1 2 3 4 5 6
|
hbase-indexer add-indexer \ --name userIndexer \ --indexer-conf $HOME/hbase-indexer/User/conf/morphline-hbase-mapper.xml \ --connection-param solr.zk=server1:2181/solr \ --connection-param solr.collection=User \ --zookeeper server1:2181
|
驗證索引器是否已成功創建
執行$ hbase-indexer list-indexers驗證索引器是否已成功創建
更多幫助,請使用以下命令:
|
1 2 3 4
|
hbase-indexer add-indexer --help hbase-indexer list-indexers --help hbase-indexer update-indexer --help hbase-indexer delete-indexer --help
|
測試是solr是否已新建索引
寫入數據時,在solr-webui控制檯查看日誌是否更新
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
|
put 'User','row1','data','u1' put 'User','row1','data:name','u2' put 'User','row2','data:name','u2' put 'User','row2','data:psd','123' put 'User','row2','data:address','address2' put 'User','row2','data:photo','photo2' put 'User','row2','data:name','u2' put 'User','row2','data:psd','123' put 'User','row2','detail:address','address2' put 'User','row2','detail:photo','photo2' put 'User','row3','data:name','u2' put 'User','row3','data:psd','123' put 'User','row3','detail:address','江蘇省南京市' put 'User','row3','detail:photo','phto3'
|
折騰幾天弄好,下一步是如何以構建好的索引Hbase實現多列條件的組合查詢。
擴展命令
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
|
# solrctl solrctl instancedir --list solrctl collection --list # 更新coolection配置 solrctl instancedir --update User $HOME/hbase-indexer/User solrctl collection --reload User #刪除instancedir solrctl instancedir --delete User #刪除collection solrctl collection --delete User #刪除collection所有doc solrctl collection --deletedocs User #刪除User配置目錄 rm -rf $HOME/hbase-indexer/User # hbase-indexer # 若修改了morphline-hbase-mapper.xml,需更新索引 hbase-indexer update-indexer -n userIndexer # 刪除索引 hbase-indexer delete-indexer -n userIndexer
|
所遇問題QA
Lily HBase Indexer Service註冊錯誤
詳細日誌
|
1 2 3 4 5 6
|
[WARN ][08:56:49,677][.com:2181)] org.apache.zookeeper.ClientCnxn - Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect java.net.ConnectException: Connection refused at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739) at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:350) at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1081)
|
解決:將幫助文檔原文中的-zookeeper hbase-cluster-zookeeper:2181中hbase-cluster-zookeeper換成zoomkeeper的主機名
schema.xm和morphline.conf配置問題
|
1 2
|
ERROR org.apache.solr.common.SolrException: ERROR: [doc=row3] unknown field 'data' trueat org.apache.solr.update.DocumentBuilder.toDocument(DocumentBuilder.java:185)
|
解決方式:
Thanks for the response. In the meantime I got a solution which is fine for me using: But type=”ignored” is a good hint once I want to get rid of the fields I do not need, thanks. –
schema新增配置:
|
1 2
|
<dynamicField name="*" type="string" indexed="true" stored="true" /> <field name="data" type="string" indexed="true" stored="true" multiValued="true"/>
|
修改schema.xml後,執行以下命令更新配置:
solrctl instancedir –update hbase-collection-user $HOME/hbase-collection-user
solrctl collection –reload hbase-collection-user
修改Collection
當我們創建Collection完成後,如果需要修改schema.xml文件重新配置需要索引的字段可以按如下操作:
- 如果是修改原有schema.xml中字段值,而在solr中已經插入了索引數據,那麼我們需要清空索引數據集,清空數據集可以通過solr API來完成。
- 如果是在原有schema.xml中加入新的索引字段,那麼可以跳過1,直接執行:
|
1 2
|
solrctl instancedir --update solrtest $HOME/solrtest solrctl collection --reload solrtest
|
多個HbaseTable配置schema.xml和morphline.conf
解決方式:
email-schema示例
Q:morphline.conf和morphline-hbase-mapper.xml文件是否每個HbaseTable都要對應配置一個?
A:每一個Hbase Table對應生成一個Solr的Collection索引,每個索引對應一個Lily HBase Indexer 配置文件morphlines.conf和morphline配置文件morphline-hbase-mapper.xml,其中morphlines.conf可由CDH的Key-Value Store Indexer控制檯管理,以id區分
官方說明:
|
1 2 3 4 5
|
Creating a Lily HBase Indexer configuration Individual Lily HBase Indexers are configured using the hbase-indexer command line utility. Typically, there is one Lily HBase Indexer configuration for each HBase table, but there can be as many Lily HBase Indexer configurations as there are tables and column families and corresponding collections in the SolrCloud. Each Lily HBase Indexer configuration is defined in an XML file such as morphline-hbase-mapper.xml.
|
對HBaseTable已有數據新建索引
需要用到Lily HBase Indexer的批處理索引功能了
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
|
sudo hadoop --config /etc/hadoop/conf \ jar /usr/lib/hbase-solr/tools/hbase-indexer-mr-1.5-cdh5.4.4-job.jar \ --conf /etc/hbase/conf/hbase-site.xml \ -D 'mapred.child.java.opts=-Xmx500m' \ --hbase-indexer-zk master:2181 \ --collection hbase-collection-user \ --hbase-indexer-name userIndexer \ --hbase-indexer-file $HOME/hbase-collection-user/conf/morphline-hbase-mapper.xml \ --go-live \ ``` 錯誤日誌 ``` java Caused by: java.io.IOException Can not find resource solrconfig.xml in classpath or /root/file:/tmp/hadoop-root/mapred/local/1441858645500/6a1a458e-35e2-4f66-82df-02795ba44e2c.solr.zip/collection1/conf
|