閒暇之時瀏覽技術站點時,看到了對事物寫的很好的一篇文章,看完之後感覺講的實在是太好了。
原文地址:http://my.oschina.net/huangyong/blog/160012
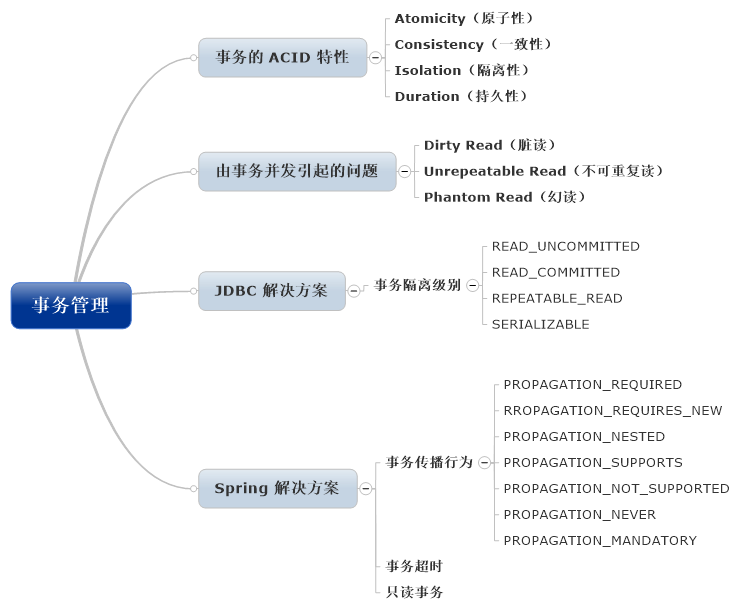
Transaction 也就是所謂的事務了,通俗理解就是一件事情。從小,父母就教育我們,做事情要有始有終,不能半途而廢。 事務也是這樣,不能做一般就不做了,要麼做完,要麼就不做。也就是說,事務必須是一個不可分割的整體,就像我們在化學課裏學到的原子,原子是構成物質的最小單位。於是,人們就歸納出事務的第一個特性:原子性(Atomicity)。我靠,一點都不神祕嘛。
特別是在數據庫領域,事務是一個非常重要的概念,除了原子性以外,它還有一個極其重要的特性,那就是:一致性(Consistency)。也就是說,執行完數據庫操作後,數據不會被破壞。打個比方,如果從 A 賬戶轉賬到 B 賬戶,不可能因爲 A 賬戶扣了錢,而 B 賬戶沒有加錢吧。如果出現了這類事情,您一定會非常氣憤,什麼 diao 銀行啊!
當我們編寫了一條 update 語句,提交到數據庫的一剎那間,有可能別人也提交了一條 delete 語句到數據庫中。也許我們都是對同一條記錄進行操作,可以想象,如果不稍加控制,就會出大麻煩來。我們必須保證數據庫操作之間是“隔離”的(線程之間有時也要做到隔離),彼此之間沒有任何干擾。這就是:隔離性(Isolation)。要想真正的做到操作之間完全沒有任何干擾是很難的,於是乎,每天上班打醬油的數據庫專家們,開始動腦筋了,“我們要制定一個規範,讓各個數據庫廠商都支持我們的規範!”,這個規範就是:事務隔離級別(Transaction Isolation Level)。能定義出這樣牛逼的規範真的挺不容易的,其實說白了就四個級別:
- READ_UNCOMMITTED
- READ_COMMITTED
- REPEATABLE_READ
- SERIALIZABLE
千萬不要去翻譯,那只是一個代號而已。從上往下,級別越來越高,併發性越來越差,安全性越來越高,反之則反。
當我們執行一條 insert 語句後,數據庫必須要保證有一條數據永久地存放在磁盤中,這個也算事務的一條特性, 它就是:持久性(Durability)。
歸納一下,以上一共提到了事務的 4 條特性,把它們的英文單詞首字母合起來就是:ACID,這個就是傳說中的“事務 ACID 特性”!
真的是非常牛逼的特性啊!這 4 條特性,是事務管理的基石,一定要透徹理解。此外還要明確,這四個傢伙當中,誰纔是老大?
其實想想也就清楚了:原子性是基礎,隔離性是手段,持久性是目的,真正的老大就是一致性。數據不一致了,就相當於“江湖亂套了,流氓戴胸罩”。所以說,這三個小弟都是跟着“一致性”這個老大混,爲他全心全意服務。
這四個傢伙當中,其實最難理解的反倒不是一致性,而是隔離性。因爲它是保證一致性的重要手段,是工具,使用它不能有半點差池,否則後果自負!怪不得數據庫行業專家們都要來研究所謂的事務隔離級別了。其實,定義這四個級別就是爲了解決數據在高併發下所產生的問題,那又有哪些問題呢?
- Dirty Read(髒讀)
- Unrepeatable Read(不可重複讀)
- Phantom Read(幻讀)
首先看看“髒讀”,看到“髒”這個字,我就想到了噁心、骯髒。數據怎麼可能髒呢?其實也就是我們經常說的“垃圾數據”了。比如說,有兩個事務,它們在併發執行(也就是競爭)。看看以下這個表格,您一定會明白我在說什麼:
|
時間 |
事務 A(存款) |
事務 B(取款) |
|
T1 |
開始事務 |
|
|
T2 |
|
開始事務 |
|
T3 |
|
查詢餘額(1000 元) |
|
T4 |
|
取出 1000 元(餘額 0 元) |
|
T5 |
查詢餘額(0 元) |
|
|
T6 |
|
撤銷事務(餘額恢復爲 1000 元) |
|
T7 |
存入 500 元(餘額 500 元) |
|
|
T8 |
提交事務 |
|
餘額應該爲 1500 元纔對!請看 T5 時間點,事務 A 此時查詢餘額爲 0 元,這個數據就是髒數據,它是事務 B 造成的,明顯事務沒有進行隔離,滲過來了,亂套了。
所以髒讀這件事情是非常要不得的,一定要解決掉!讓事務之間隔離起來纔是硬道理。
那第 2 條,不可重複讀又怎麼解釋呢?還是用類似的例子來說明:
|
時間 |
事務 A(存款) |
事務 B(取款) |
|
T1 |
開始事務 |
|
|
T2 |
|
開始事務 |
|
T3 |
|
查詢餘額(1000 元) |
|
T4 |
查詢餘額(1000 元) |
|
|
T5 |
|
取出 1000 元(餘額 0 元) |
|
T6 |
|
提交事務 |
|
T7 |
查詢餘額(0 元) |
|
事務 A 其實除了查詢了兩次以外,其他什麼事情都沒有做,結果錢就從 1000 變成 0 了,這就是重複讀了。可想而知,這是別人乾的,不是我乾的。其實這樣也是合理的,畢竟事務 B 提交了事務,數據庫將結果進行了持久化,所以事務 A 再次讀取自然就發生了變化。
這種現象基本上是可以理解的,但在有些變態的場景下卻是不允許的。畢竟這種現象也是事務之間沒有隔離所造成的,但我們對於這種問題,似乎可以忽略。
最後一條,幻讀。我去!Phantom 這個單詞不就是“幽靈、鬼魂”嗎?剛看到這個單詞時,真的把我的小弟弟都給驚呆了。怪不得這裏要翻譯成“幻讀”了,總不能翻譯成“幽靈讀”、“鬼魂讀”吧。其實意義就是鬼在讀,不是人在讀,或者說搞不清楚爲什麼,它就變了,很暈,真的很暈。還是用一個示例來說話吧:
|
時間 |
事務 A(統計總存款) |
事務 B(存款) |
|
T1 |
開始事務 |
|
|
T2 |
|
開始事務 |
|
T3 |
統計總存款(10000 元) |
|
|
T4 |
|
存入 100 元 |
|
T5 |
|
提交事務 |
|
T6 |
統計總存款(10100 元) |
|
銀行工作人員,每次統計總存款,都看到不一樣的結果。不過這也確實也挺正常的,總存款增多了,肯定是這個時候有人在存錢。但是如果銀行系統真的這樣設計,那算是玩完了。這同樣也是事務沒有隔離所造成的,但對於大多數應用系統而言,這似乎也是正常的,可以理解,也是允許的。銀行裏那些噁心的那些系統,要求非常嚴密,統計的時候,甚至會將所有的其他操作給隔離開,這種隔離級別就算非常高了(估計要到 SERIALIZABLE 級別了)。
歸納一下,以上提到了事務併發所引起的跟讀取數據有關的問題,各用一句話來描述一下:
- 髒讀:事務 A 讀取了事務 B 未提交的數據,並在這個基礎上又做了其他操作。
- 不可重複讀:事務 A 讀取了事務 B 已提交的更改數據。
- 幻讀:事務 A 讀取了事務 B 已提交的新增數據。
第一條是堅決抵制的,後兩條在大多數情況下可不作考慮。
這就是爲什麼必須要有事務隔離級別這個東西了,它就像一面牆一樣,隔離不同的事務。看下面這個表格,您就清楚了不同的事務隔離級別能處理怎樣的事務併發問題:
| 事務隔離級別 | 髒讀 | 不可重複讀 | 幻讀 |
|
READ_UNCOMMITTED |
允許 | 允許 | 允許 |
|
READ_COMMITTED |
禁止 | 允許 | 允許 |
|
REPEATABLE_READ |
禁止 | 禁止 | 允許 |
|
SERIALIZABLE |
禁止 | 禁止 | 禁止 |
根據您的實際需求,再參考這張表,最後確定事務隔離級別,應該不再是一件難事了。
JDBC 也提供了這四類事務隔離級別,但默認事務隔離級別對不同數據庫產品而言,卻是不一樣的。我們熟知的 MySQL 數據庫的默認事務隔離級別就是 READ_COMMITTED,Oracle、SQL Server、DB2等都有有自己的默認值。我認爲 READ_COMMITTED 已經可以解決絕大多數問題了,其他的就具體情況具體分析吧。
若對其他數據庫的默認事務隔離級別不太清楚,可以使用以下代碼來獲取:
1 |
DatabaseMetaData
meta = DBUtil.getDataSource().getConnection().getMetaData(); |
2 |
int defaultIsolation
= meta.getDefaultTransactionIsolation(); |
提示:在 java.sql.Connection 類中可查看所有的隔離級別。
我們知道 JDBC 只是連接 Java 程序與數據庫的橋樑而已,那麼數據庫又是怎樣隔離事務的呢?其實它就是“鎖”這個東西。當插入數據時,就鎖定表,這叫“鎖表”;當更新數據時,就鎖定行,這叫“鎖行”。當然這個已經超出了我們今天討論的範圍,所以還是留點空間給我們的 DBA 同學吧,免得他沒啥好寫的了。
除了 JDBC 給我們提供的事務隔離級別這種解決方案以外,還有哪些解決方案可以完善事務管理功能呢?
不妨看看 Spring 的解決方案吧,其實它是對 JDBC 的一個補充或擴展。它提供了一個非常重要的功能,就是:事務傳播行爲(Transaction Propagation Behavior)。
確實夠牛逼的,Spring 一下子就提供了 7 種事務傳播行爲,這 7 種行爲一出現,真的是亮瞎了我的狗眼!
- PROPAGATION_REQUIRED
- RROPAGATION_REQUIRES_NEW
- PROPAGATION_NESTED
- PROPAGATION_SUPPORTS
- PROPAGATION_NOT_SUPPORTED
- PROPAGATION_NEVER
- PROPAGATION_MANDATORY
看了 Spring 參考手冊之後,更是暈了,這到底是在幹嘛?
首先要明確的是,事務是從哪裏來?傳播到哪裏去?答案是,從方法 A 傳播到方法 B。Spring 解決的只是方法之間的事務傳播,那情況就多了,比如:
- 方法 A 有事務,方法 B 也有事務。
- 方法 A 有事務,方法 B 沒有事務。
- 方法 A 沒有事務,方法 B 有事務。
- 方法 A 沒有事務,方法 B 也沒有事務。
這樣就是 4 種了,還有 3 種特殊情況。還是用我的 Style 給大家做一個分析吧:
假設事務從方法 A 傳播到方法 B,您需要面對方法 B,問自己一個問題:
方法 A 有事務嗎?
- 如果沒有,就新建一個事務;如果有,就加入當前事務。這就是 PROPAGATION_REQUIRED,它也是 Spring 提供的默認事務傳播行爲,適合絕大多數情況。
- 如果沒有,就新建一個事務;如果有,就將當前事務掛起。這就是 RROPAGATION_REQUIRES_NEW,意思就是創建了一個新事務,它和原來的事務沒有任何關係了。
- 如果沒有,就新建一個事務;如果有,就在當前事務中嵌套其他事務。這就是 PROPAGATION_NESTED,也就是傳說中的“嵌套事務”了,所嵌套的子事務與主事務之間是有關聯的(當主事務提交或回滾,子事務也會提交或回滾)。
- 如果沒有,就以非事務方式執行;如果有,就使用當前事務。這就是 PROPAGATION_SUPPORTS,這種方式非常隨意,沒有就沒有,有就有,有點無所謂的態度,反正我是支持你的。
- 如果沒有,就以非事務方式執行;如果有,就將當前事務掛起。這就是 PROPAGATION_NOT_SUPPORTED,這種方式非常強硬,沒有就沒有,有我也不支持你,把你掛起來,不鳥你。
- 如果沒有,就以非事務方式執行;如果有,就拋出異常。這就是 PROPAGATION_NEVER,這種方式更猛,沒有就沒有,有了反而報錯,確實夠牛的,它說:我從不支持事務!
- 如果沒有,就拋出異常;如果有,就使用當前事務。這就是 PROPAGATION_MANDATORY,這種方式可以說是牛逼中的牛逼了,沒有事務直接就報錯,確實夠狠的,它說:我必須要有事務!
看到我上面這段解釋,小夥伴們是否已經感受到,被打通任督二脈的感覺?多讀幾遍,體會一下,就是您自己的東西了。
需要注意的是 PROPAGATION_NESTED,不要被它的名字所欺騙,Nested(嵌套),所以凡是在類似方法 A 調用方法 B 的時候,在方法 B 上使用了這種事務傳播行爲,如果您真的那樣做了,那您就錯了。因爲您錯誤地以爲 PROPAGATION_NESTED 就是爲方法嵌套調用而準備的,其實默認的 PROPAGATION_REQUIRED 就可以幫助您,做您想要做的事情了。
Spring 給我們帶來了事務傳播行爲,這確實是一個非常強大而又實用的功能。除此以外,也提供了一些小的附加功能,比如:
- 事務超時(Transaction Timeout):爲了解決事務時間太長,消耗太多的資源,所以故意給事務設置一個最大時常,如果超過了,就回滾事務。
- 只讀事務(Readonly Transaction):爲了忽略那些不需要事務的方法,比如讀取數據,這樣可以有效地提高一些性能。
最後,推薦大家使用 Spring 的註解式事務配置,而放棄 XML 式事務配置。因爲註解實在是太優雅了,當然這一切都取決於您自身的情況了。
在 Spring 配置文件中使用:
1 |
... |
2 |
<tx:annotation-driven /> |
3 |
... |
1 |
@Transactional |
2 |
public void xxx()
{ |
3 |
... |
4 |
} |
可在 @Transactional 註解中設置:事務隔離級別、事務傳播行爲、事務超時時間、是否只讀事務。
簡直是太完美了,太優雅了!
最後,有必要對本文的內容做一個總結,免費贈送一張高清無碼思維導圖: