




分佈變換 #
通常我們會拿VAE跟GAN比較,的確,它們兩個的目標基本是一致的——希望構建一個從隱變量ZZ生成目標數據XX的模型,但是實現上有所不同。更準確地講,它們是假設了ZZ服從某些常見的分佈(比如正態分佈或均勻分佈),然後希望訓練一個模型X=g(Z)X=g(Z),這個模型能夠將原來的概率分佈映射到訓練集的概率分佈,也就是說,它們的目的都是進行分佈之間的變換。
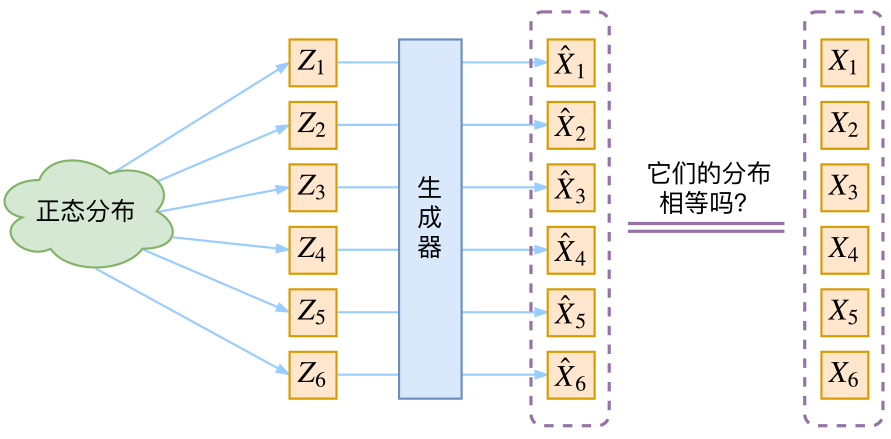
生成模型的難題就是判斷生成分佈與真實分佈的相似度,因爲我們只知道兩者的採樣結果,不知道它們的分佈表達式
那現在假設ZZ服從標準的正態分佈,那麼我就可以從中採樣得到若干個Z1,Z2,…,ZnZ1,Z2,…,Zn,然後對它做變換得到X̂1=g(Z1),X̂2=g(Z2),…,X̂n=g(Zn)X^1=g(Z1),X^2=g(Z2),…,X^n=g(Zn),我們怎麼判斷這個通過gg構造出來的數據集,它的分佈跟我們目標的數據集分佈是不是一樣的呢?有讀者說不是有KL散度嗎?當然不行,因爲KL散度是根據兩個概率分佈的表達式來算它們的相似度的,然而目前我們並不知道它們的概率分佈的表達式,我們只有一批從構造的分佈採樣而來的數據{X̂1,X̂2,…,X̂n}{X^1,X^2,…,X^n},還有一批從真實的分佈採樣而來的數據{X1,X2,…,Xn}{X1,X2,…,Xn}(也就是我們希望生成的訓練集)。我們只有樣本本身,沒有分佈表達式,當然也就沒有方法算KL散度。
雖然遇到困難,但還是要想辦法解決的。GAN的思路很直接粗獷:既然沒有合適的度量,那我乾脆把這個度量也用神經網絡訓練出來吧。就這樣,WGAN就誕生了,詳細過程請參考《互懟的藝術:從零直達WGAN-GP》。而VAE則使用了一個精緻迂迴的技巧。
VAE慢談 #
這一部分我們先回顧一般教程是怎麼介紹VAE的,然後再探究有什麼問題,接着就自然地發現了VAE真正的面目。
經典回顧 #
首先我們有一批數據樣本{X1,…,Xn}{X1,…,Xn},其整體用XX來描述,我們本想根據{X1,…,Xn}{X1,…,Xn}得到XX的分佈p(X)p(X),如果能得到的話,那我直接根據p(X)p(X)來採樣,就可以得到所有可能的XX了(包括{X1,…,Xn}{X1,…,Xn}以外的),這是一個終極理想的生成模型了。當然,這個理想很難實現,於是我們將分佈改一改
這裏我們就不區分求和還是求積分了,意思對了就行。此時p(X|Z)p(X|Z)就描述了一個由ZZ來生成XX的模型,而我們假設ZZ服從標準正態分佈,也就是p(Z)=(0,I)p(Z)=N(0,I)。如果這個理想能實現,那麼我們就可以先從標準正態分佈中採樣一個ZZ,然後根據ZZ來算一個XX,也是一個很棒的生成模型。接下來就是結合自編碼器來實現重構,保證有效信息沒有丟失,再加上一系列的推導,最後把模型實現。框架的示意圖如下:
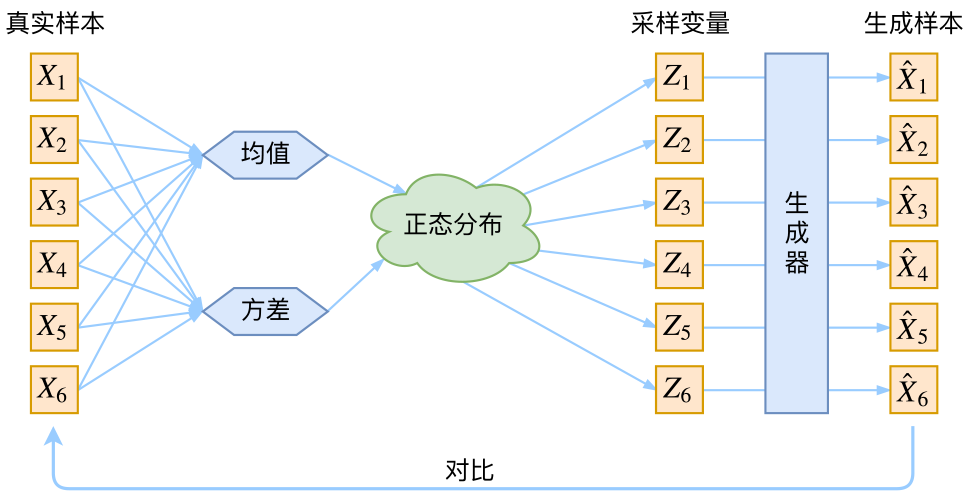
vae的傳統理解
看出了什麼問題了嗎?如果像這個圖的話,我們其實完全不清楚:究竟經過重新採樣出來的ZkZk,是不是還對應着原來的XkXk,所以我們如果直接最小化(X̂k,Xk)2D(X^k,Xk)2(這裏D代表某種距離函數)是很不科學的,而事實上你看代碼也會發現根本不是這樣實現的。也就是說,很多教程說了一大通頭頭是道的話,然後寫代碼時卻不是按照所寫的文字來寫,可是他們也不覺得這樣會有矛盾~
VAE初現 #
其實,在整個VAE模型中,我們並沒有去使用p(Z)p(Z)(隱變量空間的分佈)是正態分佈的假設,我們用的是假設p(Z|X)p(Z|X)(後驗分佈)是正態分佈!!
具體來說,給定一個真實樣本XkXk,我們假設存在一個專屬於XkXk的分佈p(Z|Xk)p(Z|Xk)(學名叫後驗分佈),並進一步假設這個分佈是(獨立的、多元的)正態分佈。爲什麼要強調“專屬”呢?因爲我們後面要訓練一個生成器X=g(Z)X=g(Z),希望能夠把從分佈p(Z|Xk)p(Z|Xk)採樣出來的一個ZkZk還原爲XkXk。如果假設p(Z)p(Z)是正態分佈,然後從p(Z)p(Z)中採樣一個ZZ,那麼我們怎麼知道這個ZZ對應於哪個真實的XX呢?現在p(Z|Xk)p(Z|Xk)專屬於XkXk,我們有理由說從這個分佈採樣出來的ZZ應該要還原到XkXk中去。
事實上,在論文《Auto-Encoding Variational Bayes》的應用部分,也特別強調了這一點:
In this case, we can let the
variational approximate posterior be a multivariate Gaussian with a diagonal covariance structure:logqϕ(z|x(i))=log(z;μ(i),σ2(i)I)(9)(9)logqϕ(z|x(i))=logN(z;μ(i),σ2(i)I)(注:這裏是直接摘錄原論文,本文所用的符號跟原論文不盡一致,望讀者不會混淆。)
論文中的式(9)(9)是實現整個模型的關鍵,不知道爲什麼很多教程在介紹VAE時都沒有把它凸顯出來。儘管論文也提到p(Z)p(Z)是標準正態分佈,然而那其實並不是本質重要的。
回到本文,這時候每一個XkXk都配上了一個專屬的正態分佈,才方便後面的生成器做還原。但這樣有多少個XX就有多少個正態分佈了。我們知道正態分佈有兩組參數:均值μμ和方差σ2σ2(多元的話,它們都是向量),那我怎麼找出專屬於XkXk的正態分佈p(Z|Xk)p(Z|Xk)的均值和方差呢?好像並沒有什麼直接的思路。那好吧,那我就用神經網絡來擬合出來吧!這就是神經網絡時代的哲學:難算的我們都用神經網絡來擬合,在WGAN那裏我們已經體驗過一次了,現在再次體驗到了。
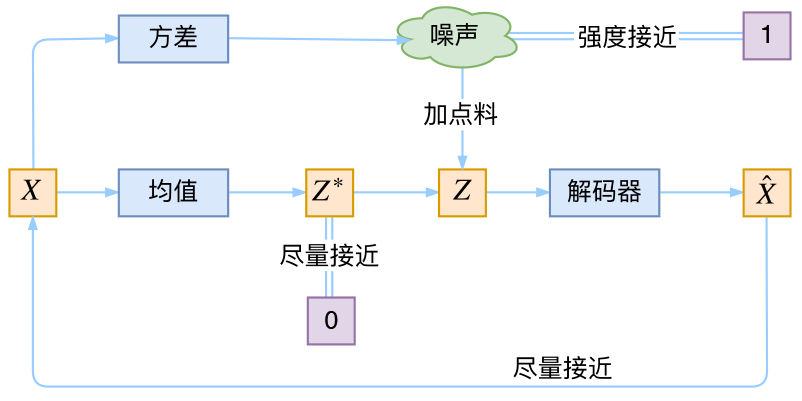
於是我們構建兩個神經網絡μk=f1(Xk),logσ2k=f2(Xk)μk=f1(Xk),logσk2=f2(Xk)來算它們了。我們選擇擬合logσ2klogσk2而不是直接擬合σ2kσk2,是因爲σ2kσk2總是非負的,需要加激活函數處理,而擬合logσ2klogσk2不需要加激活函數,因爲它可正可負。到這裏,我能知道專屬於XkXk的均值和方差了,也就知道它的正態分佈長什麼樣了,然後從這個專屬分佈中採樣一個ZkZk出來,然後經過一個生成器得到X̂k=g(Zk)X^k=g(Zk),現在我們可以放心地最小化(X̂k,Xk)2D(X^k,Xk)2,因爲ZkZk是從專屬XkXk的分佈中採樣出來的,這個生成器應該要把開始的XkXk還原回來。於是可以畫出VAE的示意圖
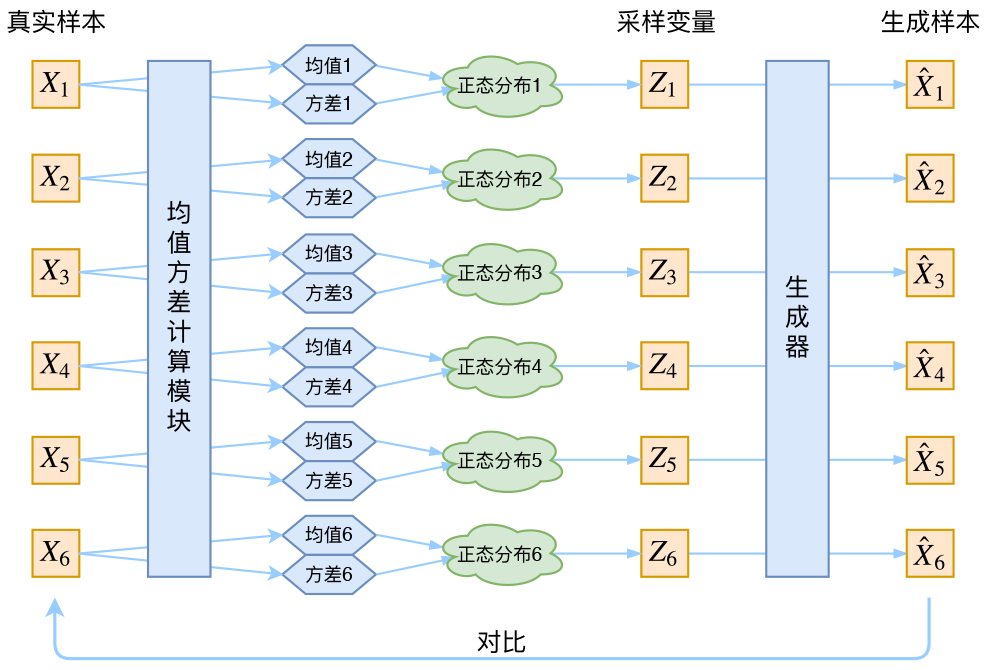
事實上,vae是爲每個樣本構造專屬的正態分佈,然後採樣來重構
分佈標準化 #
讓我們來思考一下,根據上圖的訓練過程,最終會得到什麼結果。
首先,我們希望重構XX,也就是最小化(X̂k,Xk)2D(X^k,Xk)2,但是這個重構過程受到噪聲的影響,因爲ZkZk是通過重新採樣過的,不是直接由encoder算出來的。顯然噪聲會增加重構的難度,不過好在這個噪聲強度(也就是方差)通過一個神經網絡算出來的,所以最終模型爲了重構得更好,肯定會想盡辦法讓方差爲0。而方差爲0的話,也就沒有隨機性了,所以不管怎麼採樣其實都只是得到確定的結果(也就是均值),只擬合一個當然比擬合多個要容易,而均值是通過另外一個神經網絡算出來的。
說白了,模型會慢慢退化成普通的AutoEncoder,噪聲不再起作用。
這樣不就白費力氣了嗎?說好的生成模型呢?
別急別急,其實VAE還讓所有的p(Z|X)p(Z|X)都向標準正態分佈看齊,這樣就防止了噪聲爲零,同時保證了模型具有生成能力。怎麼理解“保證了生成能力”呢?如果所有的p(Z|X)p(Z|X)都很接近標準正態分佈(0,I)N(0,I),那麼根據定義
這樣我們就能達到我們的先驗假設:p(Z)p(Z)是標準正態分佈。然後我們就可以放心地從(0,I)N(0,I)中採樣來生成圖像了。
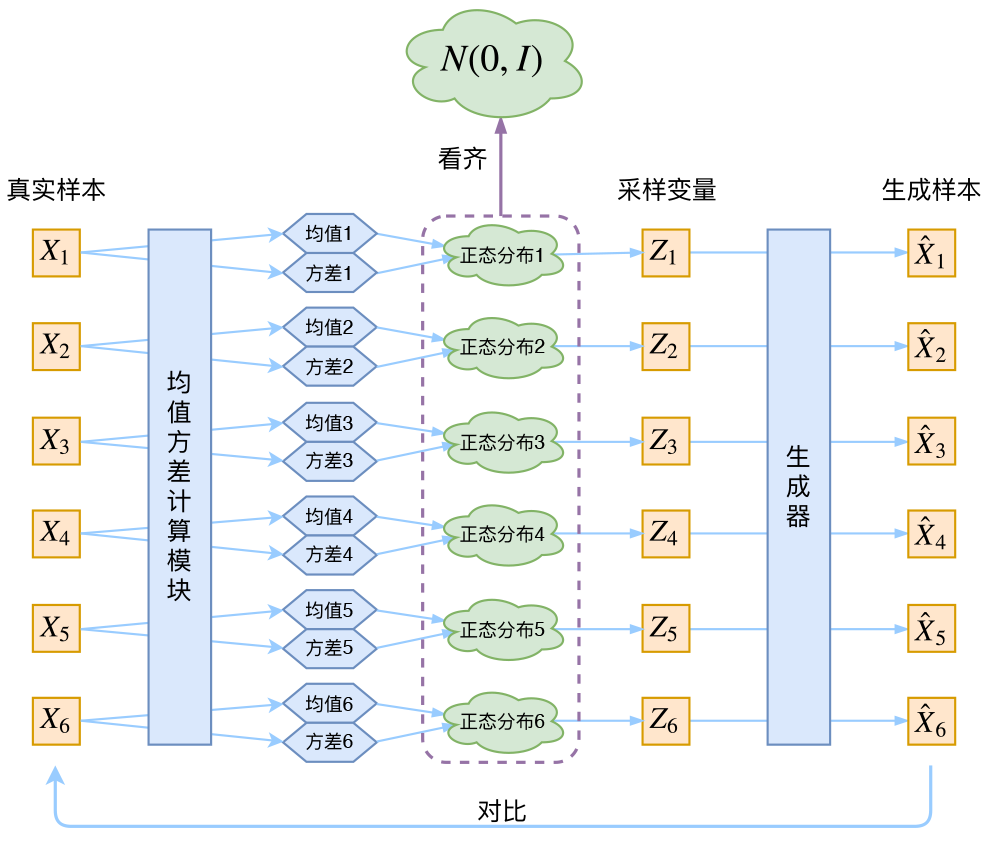
爲了使模型具有生成能力,vae要求每個p(Z_X)都向正態分佈看齊
那怎麼讓所有的p(Z|X)p(Z|X)都向(0,I)N(0,I)看齊呢?如果沒有外部知識的話,其實最直接的方法應該是在重構誤差的基礎上中加入額外的loss:
μ=‖f1(Xk)‖2和σ2=‖f2(Xk)‖2(3)(3)Lμ=‖f1(Xk)‖2和Lσ2=‖f2(Xk)‖2
因爲它們分別代表了均值μkμk和方差的對數logσ2klogσk2,達到(0,I)N(0,I)就是希望二者儘量接近於0了。不過,這又會面臨着這兩個損失的比例要怎麼選取的問題,選取得不好,生成的圖像會比較模糊。所以,原論文直接算了一般(各分量獨立的)正態分佈與標準正態分佈的KL散度KL(N(μ,σ2)‖‖‖N(0,I))KL(N(μ,σ2)‖N(0,I))作爲這個額外的loss,計算結果爲
μ,σ2=12∑i=1d(μ2(i)+σ2(i)−logσ2(i)−1)(4)(4)Lμ,σ2=12∑i=1d(μ(i)2+σ(i)2−logσ(i)2−1)
這裏的dd是隱變量ZZ的維度,而μ(i)μ(i)和σ2(i)σ(i)2分別代表一般正態分佈的均值向量和方差向量的第ii個分量。直接用這個式子做補充loss,就不用考慮均值損失和方差損失的相對比例問題了。顯然,這個loss也可以分兩部分理解:
μ,σ2=μ+σ2μ=12∑i=1dμ2(i)=12‖f1(X)‖2σ2=12∑i=1d(σ2(i)−logσ2(i)−1)(5)(5)Lμ,σ2=Lμ+Lσ2Lμ=12∑i=1dμ(i)2=12‖f1(X)‖2Lσ2=12∑i=1d(σ(i)2−logσ(i)2−1)
推導
由於我們考慮的是各分量獨立的多元正態分佈,因此只需要推導一元正態分佈的情形即可,根據定義我們可以寫出===KL(N(μ,σ2)‖‖‖N(0,1))∫12πσ2‾‾‾‾‾√e−(x−μ)2/2σ2(loge−(x−μ)2/2σ2/2πσ2‾‾‾‾‾√e−x2/2/2π‾‾‾√)dx∫12πσ2‾‾‾‾‾√e−(x−μ)2/2σ2log{1σ2‾‾‾√exp{12[x2−(x−μ)2/σ2]}}dx12∫12πσ2‾‾‾‾‾√e−(x−μ)2/2σ2[−logσ2+x2−(x−μ)2/σ2]dxKL(N(μ,σ2)‖N(0,1))=∫12πσ2e−(x−μ)2/2σ2(loge−(x−μ)2/2σ2/2πσ2e−x2/2/2π)dx=∫12πσ2e−(x−μ)2/2σ2log{1σ2exp{12[x2−(x−μ)2/σ2]}}dx=12∫12πσ2e−(x−μ)2/2σ2[−logσ2+x2−(x−μ)2/σ2]dx
整個結果分爲三項積分,第一項實際上就是−logσ2−logσ2乘以概率密度的積分(也就是1),所以結果是−logσ2−logσ2;第二項實際是正態分佈的二階矩,熟悉正態分佈的朋友應該都清楚正態分佈的二階矩爲μ2+σ2μ2+σ2;而根據定義,第三項實際上就是“-方差除以方差=-1”。所以總結果就是
KL(N(μ,σ2)‖‖‖N(0,1))=12(−logσ2+μ2+σ2−1)KL(N(μ,σ2)‖N(0,1))=12(−logσ2+μ2+σ2−1)
.
重參數技巧 #
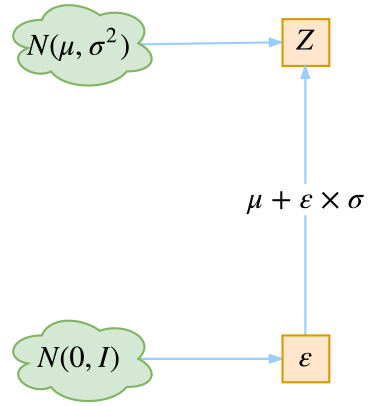
重參數技巧
最後是實現模型的一個技巧,英文名是reparameterization trick,我這裏叫它做重參數吧。其實很簡單,就是我們要從p(Z|Xk)p(Z|Xk)中採樣一個ZkZk出來,儘管我們知道了p(Z|Xk)p(Z|Xk)是正態分佈,但是均值方差都是靠模型算出來的,我們要靠這個過程反過來優化均值方差的模型,但是“採樣”這個操作是不可導的,而採樣的結果是可導的。我們利用
=12πσ2‾‾‾‾‾√exp(−(z−μ)22σ2)dz12π‾‾‾√exp[−12(z−μσ)2]d(z−μσ)(6)(6)12πσ2exp(−(z−μ)22σ2)dz=12πexp[−12(z−μσ)2]d(z−μσ)
這說明(z−μ)/σ=ε(z−μ)/σ=ε是服從均值爲0、方差爲1的標準正態分佈的,要同時把dzdz考慮進去,是因爲乘上dzdz纔算是概率,去掉dzdz是概率密度而不是概率。這時候我們得到:
從(μ,σ2)N(μ,σ2)中採樣一個ZZ,相當於從(0,I)N(0,I)中採樣一個εε,然後讓Z=μ+ε×σZ=μ+ε×σ。
於是,我們將從(μ,σ2)N(μ,σ2)採樣變成了從(0,I)N(0,I)中採樣,然後通過參數變換得到從(μ,σ2)N(μ,σ2)中採樣的結果。這樣一來,“採樣”這個操作就不用參與梯度下降了,改爲採樣的結果參與,使得整個模型可訓練了。
具體怎麼實現,大家把上述文字對照着代碼看一下,一下子就明白了~
後續分析 #
即便把上面的所有內容都搞清楚了,面對VAE,我們可能還存有很多疑問。
本質是什麼 #
VAE的本質是什麼?VAE雖然也稱是AE(AutoEncoder)的一種,但它的做法(或者說它對網絡的詮釋)是別具一格的。在VAE中,它的Encoder有兩個,一個用來計算均值,一個用來計算方差,這已經讓人意外了:Encoder不是用來Encode的,是用來算均值和方差的,這真是大新聞了,還有均值和方差不都是統計量嗎,怎麼是用神經網絡來算的?
事實上,我覺得VAE從讓普通人望而生畏的變分和貝葉斯理論出發,最後落地到一個具體的模型中,雖然走了比較長的一段路,但最終的模型其實是很接地氣的:它本質上就是在我們常規的自編碼器的基礎上,對encoder的結果(在VAE中對應着計算均值的網絡)加上了“高斯噪聲”,使得結果decoder能夠對噪聲有魯棒性;而那個額外的KL loss(目的是讓均值爲0,方差爲1),事實上就是相當於對encoder的一個正則項,希望encoder出來的東西均有零均值。
那另外一個encoder(對應着計算方差的網絡)的作用呢?它是用來動態調節噪聲的強度的。直覺上來想,當decoder還沒有訓練好時(重構誤差遠大於KL loss),就會適當降低噪聲(KL loss增加),使得擬合起來容易一些(重構誤差開始下降);反之,如果decoder訓練得還不錯時(重構誤差小於KL loss),這時候噪聲就會增加(KL loss減少),使得擬合更加困難了(重構誤差又開始增加),這時候decoder就要想辦法提高它的生成能力了。
vae的本質結構
說白了,重構的過程是希望沒噪聲的,而KL loss則希望有高斯噪聲的,兩者是對立的。所以,VAE跟GAN一樣,內部其實是包含了一個對抗的過程,只不過它們兩者是混合起來,共同進化的。從這個角度看,VAE的思想似乎還高明一些,因爲在GAN中,造假者在進化時,鑑別者是安然不動的,反之亦然。當然,這只是一個側面,不能說明VAE就比GAN好。GAN真正高明的地方是:它連度量都直接訓練出來了,而且這個度量往往比我們人工想的要好(然而GAN本身也有各種問題,這就不展開了)。
正態分佈? #
對於p(Z|X)p(Z|X)的分佈,讀者可能會有疑惑:是不是必須選擇正態分佈?可以選擇均勻分佈嗎?
估計不大可行,這還是因爲KL散度的計算公式:
要是在某個區域中p(x)≠0p(x)≠0而q(x)=0q(x)=0的話,那麼KL散度就無窮大了。對於正態分佈來說,所有點的概率密度都是非負的,因此不存在這個問題。但對於均勻分佈來說,只要兩個分佈不一致,那麼就必然存在p(x)≠0p(x)≠0而q(x)=0q(x)=0的區間,因此KL散度會無窮大。當然,寫代碼時我們會防止這種除零錯誤,但依然避免不了KL loss佔比很大,因此模型會迅速降低KL loss,也就是後驗分佈p(Z|X)p(Z|X)迅速趨於先驗分佈p(Z)p(Z),而噪聲和重構無法起到對抗作用。這又回到我們開始說的,無法區分哪個zz對應哪個xx了。
當然,非得要用均勻分佈也不是不可能,就是算好兩個均勻分佈的KL散度,然後做好初零錯誤處理,加大重構loss的權重,等等~但這樣就顯得太醜陋了。
變分在哪裏 #
還有一個有意思(但不大重要)的問題是:VAE叫做“變分自編碼器”,它跟變分法有什麼聯繫?在VAE的論文和相關解讀中,好像也沒看到變分法的存在呀?
呃~其實如果讀者已經承認了KL散度的話,那VAE好像真的跟變分沒多大關係了~因爲理論上對於KL散度(7)(7)我們要證明:
固定概率分佈p(x)p(x)(或q(x)q(x))的情況下,對於任意的概率分佈q(x)q(x)(或p(x)p(x)),都有KL(p(x)‖‖‖q(x))≥0KL(p(x)‖q(x))≥0,而且只有當p(x)=q(x)p(x)=q(x)時纔等於零。
因爲KL(p(x)‖‖‖q(x))KL(p(x)‖q(x))實際上是一個泛函,要對泛函求極值就要用到變分法,當然,這裏的變分法只是普通微積分的平行推廣,還沒涉及到真正複雜的變分法。而VAE的變分下界,是直接基於KL散度就得到的。所以直接承認了KL散度的話,就沒有變分的什麼事了。
一句話,VAE的名字中“變分”,是因爲它的推導過程用到了KL散度及其性質。
條件VAE #
最後,因爲目前的VAE是無監督訓練的,因此很自然想到:如果有標籤數據,那麼能不能把標籤信息加進去輔助生成樣本呢?這個問題的意圖,往往是希望能夠實現控制某個變量來實現生成某一類圖像。當然,這是肯定可以的,我們把這種情況叫做Conditional VAE,或者叫CVAE。(相應地,在GAN中我們也有個CGAN。)
但是,CVAE不是一個特定的模型,而是一類模型,總之就是把標籤信息融入到VAE中的方式有很多,目的也不一樣。這裏基於前面的討論,給出一種非常簡單的VAE。
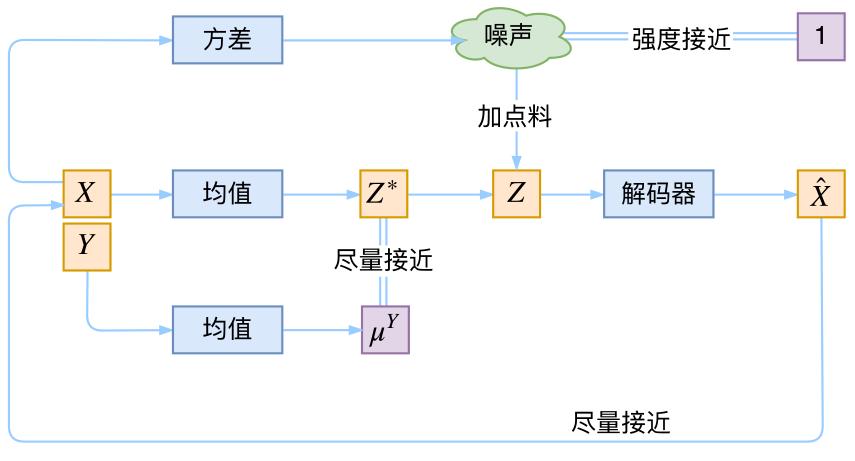
一個簡單的cvae結構
在前面的討論中,我們希望XX經過編碼後,ZZ的分佈都具有零均值和單位方差,這個“希望”是通過加入了KL loss來實現的。如果現在多了類別信息YY,我們可以希望同一個類的樣本都有一個專屬的均值μYμY(方差不變,還是單位方差),這個μYμY讓模型自己訓練出來。這樣的話,有多少個類就有多少個正態分佈,而在生成的時候,我們就可以通過控制均值來控制生成圖像的類別。事實上,這樣可能也是在VAE的基礎上加入最少的代碼來實現CVAE的方案了,因爲這個“新希望”也只需通過修改KL loss實現:
下圖顯示這個簡單的CVAE是有一定的效果的,不過因爲encoder和decoder都比較簡單(純MLP),所以控制生成的效果不盡完美。更完備的CVAE請讀者自行學習了,最近還出來了CVAE與GAN結合的工作CVAE-GAN,模型套路千變萬化啊。

用這個cvae控制生成數字9,可以發現生成了多種樣式的9,並且慢慢向7過渡,所以初步觀察這種cvae是有效的
代碼 #
我把Keras官方的VAE代碼複製了一份,然後微調並根據前文內容添加了中文註釋,也把最後說到的簡單的CVAE實現了一下,供讀者參考~
代碼:https://github.com/bojone/vae
終點站 #
磕磕碰碰,又到了文章的終點了。不知道講清楚了沒,希望大家多提點意見~
總的來說,VAE的思路還是很漂亮的。倒不是說它提供了一個多麼好的生成模型(因爲事實上它生成的圖像並不算好,偏模糊),而是它提供了一個將概率圖跟深度學習結合起來的一個非常棒的案例,這個案例有諸多值得思考回味的地方。
轉載到請包括本文地址:https://spaces.ac.cn/archives/5253
更詳細的轉載事宜請參考:《科學空間FAQ》