




在對GAN的學習和思考過程中,我發現我不僅學習到了一種有效的生成模型,而且它全面地促進了我對各種模型各方面的理解,比如模型的優化和理解視角、正則項的意義、損失函數與概率分佈的聯繫、概率推斷等等。GAN不單單是一個“造假的玩具”,而是具有深刻意義的概率模型和推斷方法。
作爲事後的總結,我覺得對GAN的理解可以粗糙地分爲三個階段:
1、樣本階段:在這個階段中,我們瞭解了GAN的“鑑別者-造假者”詮釋,懂得從這個原理出發來寫出基本的GAN公式(如原始GAN、LSGAN),比如判別器和生成器的loss,並且完成簡單GAN的訓練;同時,我們知道GAN有能力讓圖片更“真”,利用這個特性可以把GAN嵌入到一些綜合模型中。
2、分佈階段:在這個階段中,我們會從概率分佈及其散度的視角來分析GAN,典型的例子是WGAN和f-GAN,同時能基本理解GAN的訓練困難問題,比如梯度消失和mode collapse等,甚至能基本地瞭解變分推斷,懂得自己寫出一些概率散度,繼而構造一些新的GAN形式。
3、動力學階段:在這個階段中,我們開始結合優化器來分析GAN的收斂過程,試圖瞭解GAN是否能真的達到理論的均衡點,進而理解GAN的loss和正則項等因素如何影響的收斂過程,由此可以針對性地提出一些訓練策略,引導GAN模型到達理論均衡點,從而提高GAN的效果。
事實上,不僅僅是GAN,對於一般的模型理解,也可以大致上分爲這三個階段。當然也許有熱衷於幾何解釋或其他詮釋的讀者會不同意第二點,覺得沒必要非得概率分佈的角度來理解。但事實上幾何視角和概率視角都有一定的相通之處,而本文所寫的三個階段只是一個粗糙的總結,簡單來說就是從局部到整體,然後再到優化器。
而本文主要聚焦於GAN的第三個階段:GAN的動力學。
基本原理 #
一般情況下,GAN可以表示爲一個min-max過程,記作
其中maxDL(G,D)maxDL(G,D)這一步定義了一個概率散度而minGminG這一步則在最小化散度,相關的討論也可以參考本網站的《f-GAN簡介:GAN模型的生產車間》和《不用L約束又不會梯度消失的GAN,瞭解一下?》。
注意,從理論上講,這個min-max過程是有序的,即需要徹底地、精確地完成maxDmaxD這一步,然後纔去minGminG。但是很顯然,實際訓練GAN時我們做不到這一點,我們都是D,GD,G交替訓練的,理想情況下我們還希望D,GD,G每次只各自訓練一次,這樣訓練效率最高,而這樣的訓練方法對應於一個動力系統。
動力系統 #
在我們的“從動力學角度看優化算法”系列中,我們將梯度下降看成是在數學求解動力系統(也就是一個常微分方程組,簡稱ODEs)
其中L(θ)L(θ)是模型的loss,而θθ是模型的參數。如果考慮隨機性,那麼則需要加上一個噪聲項,變成一個隨機微分方程,但本文我們不考慮隨機性,這不影響我們對局部收斂性的分析。假定讀者已經熟悉了這種轉換,下面就來討論GAN對應的過程。
GAN是一個min-max的過程,換句話說,一邊是梯度下降,另一邊是梯度上升,假設φφ是判別器的參數,θθ是生成器的參數,那麼GAN對應的動力系統是
當然,對於更一般的GAN,有時候兩個LL會稍微不一樣:
不管是哪一種,右端兩項都是一正一負,而就是因爲這一正一負的差異,導致了GAN訓練上的困難~我們下面就逐步認識到這一點。
相關工作 #
將GAN的優化過程視爲一個(隨機)動力系統,基於這個觀點進行研究分析的文獻已有不少,我讀到的包括《The Numerics of GANs》、《GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium》、《Gradient descent GAN optimization is locally stable》、《Which Training Methods for GANs do actually Converge?》,而本文只不過是前輩大牛們的工作的一個學習總結。
在這幾篇文獻中,大家可能比較熟悉的是第二篇,因爲就是第二篇提出了TTUR的GAN訓練策略以及提出了FID作爲GAN的性能指標,而這篇論文的理論基礎也是將GAN的優化看成前述的隨機動力系統,然後引用了隨機優化中的一個定理,得出可以給生成器和判別器分別使用不同的學習率(TTUR)。而其餘幾篇,都是直接將GAN的優化看成確定性的動力系統(ODEs),然後用分析ODEs的方法來分析GAN。由於ODEs的理論分析/數值求解都說得上相當成熟,因此可以直接將很多ODEs的結論用到GAN中。
Dirac GAN #
本文的思路和結果主要參考《Which Training Methods for GANs do actually Converge?》,這篇論文的主要貢獻如下:
1、提出了Dirac GAN的概念,藉助它可以快速地對GAN的性態有個基本的認識;
2、完整地分析了帶零中心梯度懲罰的WGAN(也是WGAN-div)的局部收斂性;
3、利用零中心梯度懲罰的WGAN訓練了1024的人臉、256的LSUN生成,並且不需要像PGGAN那樣漸進式訓練。
由於實驗設備限制,第三點我們難以復現,而第二點涉及到比較複雜的理論分析,我們也不作過多討論,有興趣攻克的讀者直接讀原論文即可。本文主要關心第一點:Dirac GAN。
所謂Dirac GAN,就是考慮真樣本分佈只有一個樣本點的情況下,待研究的GAN模型的表現。假設真實樣本點是零向量00,而假樣本爲θθ,其實它也代表着生成器的參數;而判別器採用最簡單的線性模型,即(加激活函數之前)爲D(x)=x⋅φD(x)=x⋅φ,其中φφ代表着判別器的參數。Dirac GAN就是考慮這樣的一個極簡模型下,假樣本最終能否收斂到真樣本,也就是說θθ最終能否收斂到00。
然而,原論文只考慮了樣本點的維度是一維的情形,即0,θ,φ0,θ,φ都是標量,但本文後面的案例表明,對於某些例子,一維Dirac GAN不足以揭示它的收斂性態,一般情況下至少需要2維Dirac GAN才能較好地分析一個GAN的漸近收斂性。
常見GAN分析 #
上一節我們給出了Dirac GAN的基本概念,指出它可以幫助我們對GAN的收斂性態有個快速的認識。在這部分內容中,我們通過分析若干常見GAN,來更詳細地表明Dirac GAN怎麼做到這一點。
Vanilla GAN #
Vanilla GAN,或者叫做原始GAN、標準GAN,它就是指Goodfellow最早提出來的GAN,它有saturating和non-saturating兩種形式。作爲例子,我們來分析比較常用的non-saturating形式:
這裏的p(x),q(x)p(x),q(x)分別是真假樣本分佈,而q(z)q(z)是噪聲分佈,D(x)D(x)用sigmoid激活。對應到Dirac GAN下,那就簡單得多,因爲真樣本只有一個點而且爲00,所以判別器的loss只有一項,而判別器可以完全寫出爲θ⋅φθ⋅φ,其中θθ也就是假樣本,或者說生成器,最終結果是:
對應的動力系統是:
這個動力系統的均衡點(讓右端直接等於0)是φ=θ=0φ=θ=0,也就是假樣本變成了真樣本。但問題是從一個初始點出發,該初始點最終能否收斂到均衡點卻是個未知數。
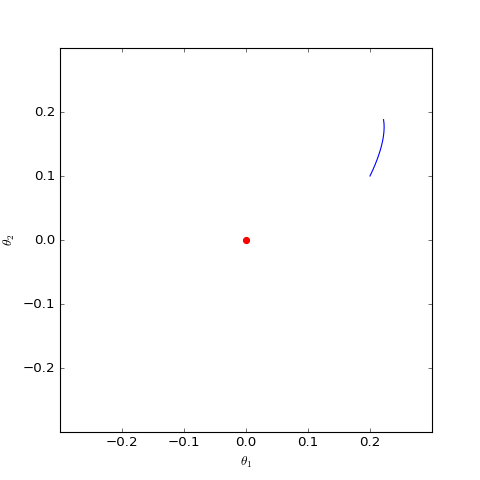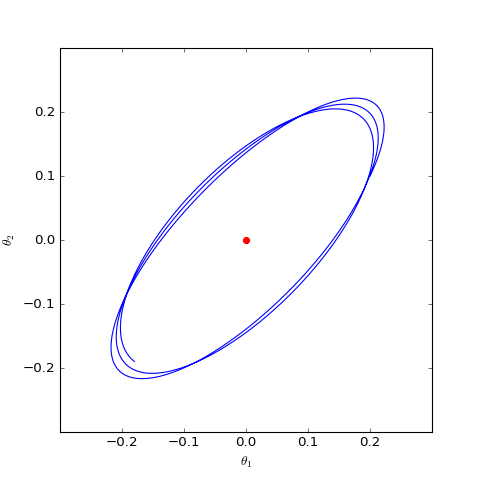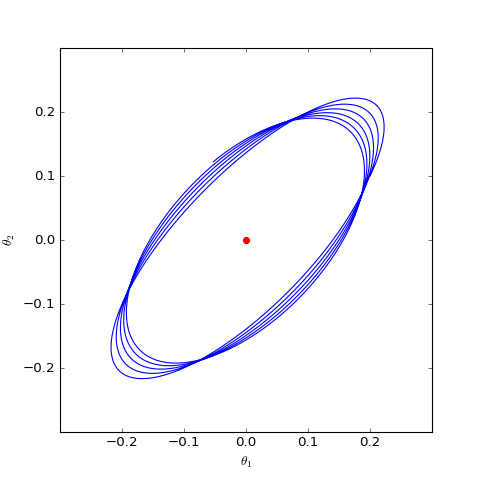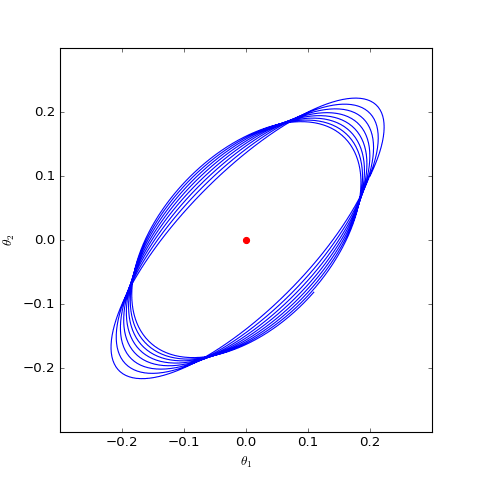
數值求解的non-saturating的Dirac GAN的優化軌跡(二維情形),可以發現它確實只是在均衡點(紅色點)周圍振盪,不收斂
爲了做出判斷,我們假設系統已經跑到了均衡點附近,即φ≈0,θ≈0φ≈0,θ≈0,那麼可以近似地線性展開:
最終近似地有
學過常微分方程的同學都知道,這是最簡單的線性常微分方程之一,只要初始值不是00,那麼它的解是一個週期解,也就是說並不會出現θ→0θ→0的特性。換句話說,對於non-saturating的Vanilla GAN,哪怕模型的初始化已經相當接近均衡點了,但是它始終不會收斂到均衡點,而是在均衡點附近振盪。數值模擬的結果則進一步證明了這一點。
事實上,類似的結果出現在任何形式的f-GAN中,即以f散度爲基礎的所有GAN都存在同樣的問題(不計正則項),即它們會慢慢收斂到均衡點附近,最終都只是在均衡點附近振盪,無法完全收斂到均衡點。
這裏再重複一下邏輯:我們知道系統的理論均衡點確實是我們想要的,但是從任意一個初值(相當於模型的初始化)出發,經過迭代後最終是否能跑到理論均衡點(相當於理想地完成GAN的訓練),這無法很顯然地得到結果,至少需要在均衡點附近做線性展開,分析它的收斂性,這就是說所謂的局部漸近收斂性態。
WGAN #
f-GAN敗下陣來了,那WGAN又如何呢?它又能否收斂到理想的均衡點呢?
WGAN的一般形式是
對應到Dirac GAN,D(x)=x⋅φD(x)=x⋅φ,而‖D‖L≤1‖D‖L≤1可以由‖φ‖=1‖φ‖=1來保證(‖⋅‖‖⋅‖是l2l2模長),換言之,D(x)D(x)加上L約束後爲D(x)=x⋅φ/‖φ‖D(x)=x⋅φ/‖φ‖,那麼WGAN對應的Dirac GAN爲
對應的動力系統是:
我們主要關心θθ是否會趨於00,可以引入類似前一節的線性展開,但是由於‖φ‖‖φ‖在分母,所以討論起來會比較困難。最乾脆的方法是直接數值求解這個方程組,結果如下圖:
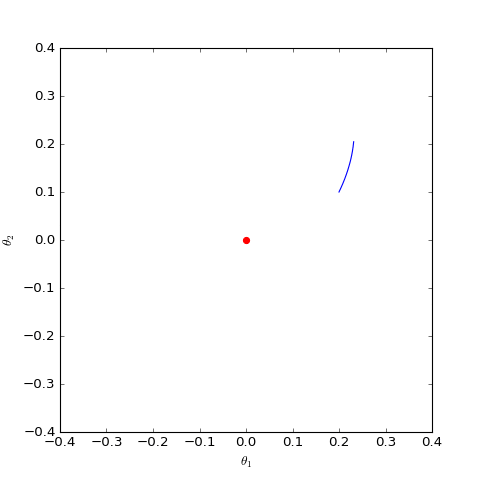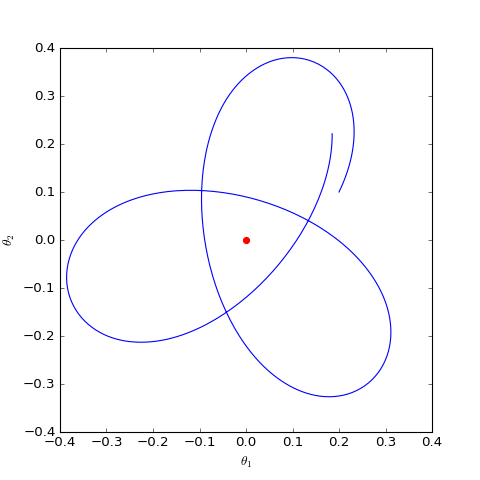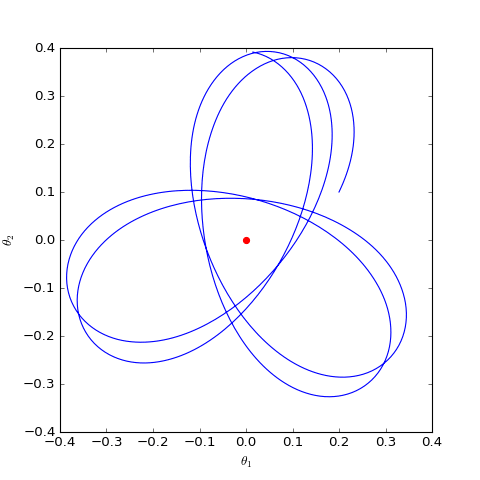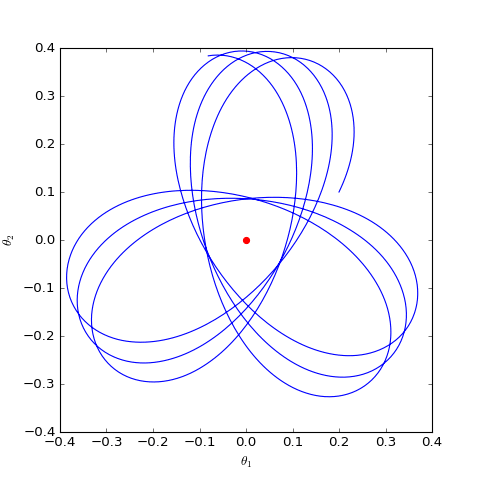
數值求解的WGAN對應的Dirac GAN的優化軌跡(二維情形),可以發現它確實只是在均衡點(紅色點)周圍振盪,不收斂
可以看到,結果依然是在均衡點附近振盪,並沒能夠達到均衡點。這個結果表明了,WGAN(同時自然也包括了譜歸一化)都沒有局部收斂性,哪怕已經跑到了均衡點附近,依然無法準確地落在均衡點上。
(注:稍加分析就能得出,如果只考慮一維的Dirac GAN,那麼將無法分析本節的WGAN和後面的GAN-QP,這就是隻考慮一維情形的侷限性。)
WGAN-GP #
大家可能會疑惑,前面不是討論了WGAN了嗎,怎麼還要討論WGAN-GP?
事實上,從優化角度看,前面所說的WGAN和WGAN-GP是兩類不一樣的模型。前面的WGAN是指事先在判別器上加上L約束(比如譜歸一化),然後進行對抗學習;這裏的WGAN-GP指的是判別器不加L約束,而是通過梯度懲罰項(Gradient Penalty)來迫使判別器具有L約束。這裏討論的梯度懲罰有兩種,第一種是《Improved Training of Wasserstein GANs》提出來的“以1爲中心的梯度懲罰”,第二種是《Wasserstein Divergence for GANs》、《Which Training Methods for GANs do actually Converge?》等文章提倡的“以0爲中心的梯度懲罰”。下面我們會對比這兩種梯度懲罰的不同表現。
梯度懲罰的一般形式是:
其中c=0c=0或c=1c=1,而r(x)r(x)是p(x)p(x)和q(x)q(x)的某個衍生分佈,一般直接取真樣本分佈、假樣本分佈或者真假樣本插值。
對於Dirac GAN來說:
也就是說它跟xx沒關係,所以r(x)r(x)怎麼取都不影響結果了。因此,WGAN-GP版本的Dirac GAN形式爲:
對應的動力系統是:
下面我們分別觀察c=0,c=1c=0,c=1時θθ是否會趨於00,當c=0c=0時其實只是一個線性常微分方程組,可以解析求解,但c=1c=1時比較複雜,因此簡單起見,我們還是直接用數值求解的方式:
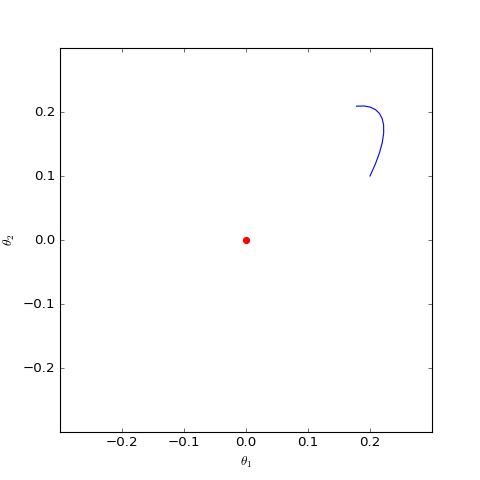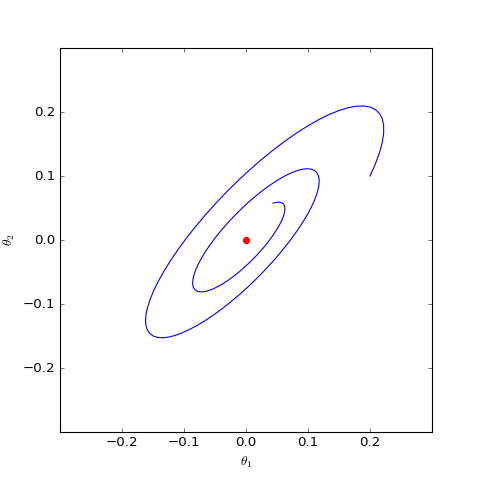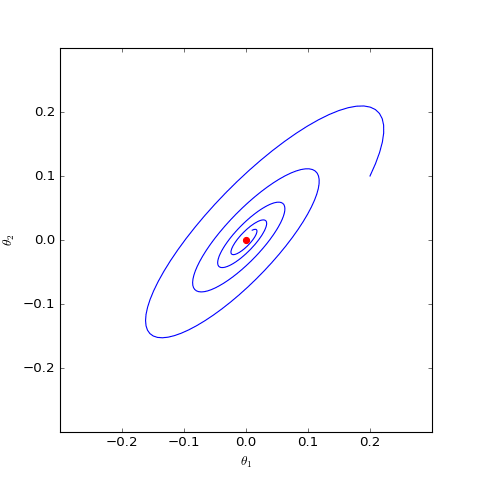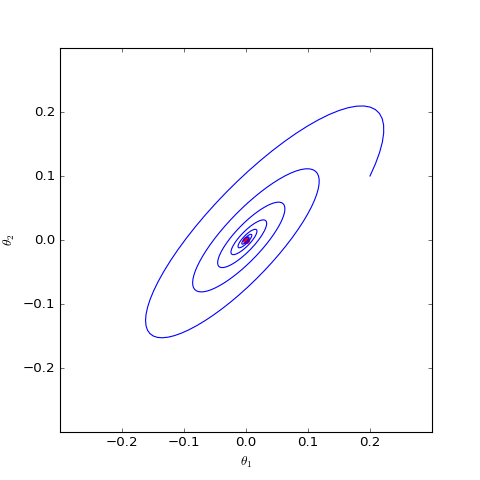
數值求解的WGAN-GP(c=0)對應的Dirac GAN的優化軌跡(二維情形),可以發現它能夠漸近收斂到均衡點(紅色點)

數值求解的WGAN-GP(c=1)對應的Dirac GAN的優化軌跡(二維情形),可以發現它確實只是在均衡點(紅色點)周圍振盪,不收斂
上圖是在同樣的初始條件(初始化)下,c=0,c=1c=0,c=1的梯度懲罰的不同表現,兩圖的其他參數都一樣。可以看到,加入“以1爲中心的梯度懲罰”後,Dirac GAN並沒有漸近收斂到原點,反而只是收斂到一個圓上;而加入“以0爲中心的梯度懲罰”則可以達到這個目的。這說明早期提出的梯度懲罰項確實是存在一些缺陷的,而“以0爲中心的梯度懲罰”在收斂性態上更好。儘管上述僅僅對Dirac GAN做了分析,但結論具有代表性,因爲關於0中心的梯度懲罰的優越性的一般證明在《Which Training Methods for GANs do actually Converge?》中已經給出,並得到實驗驗證。
GAN-QP #
最後來分析一下自己提出的GAN-QP表現如何。相比WGAN-GP,GAN-QP用二次型的差分懲罰項替換了梯度懲罰,並補充了一些證明。相比梯度懲罰,差分懲罰的最主要優勢是計算速度更快。
GAN-QP可以有多種形式,一種基本形式是:
對應的Dirac GAN爲
對應的動力系統是:
數值結果如下圖(第一個圖像):
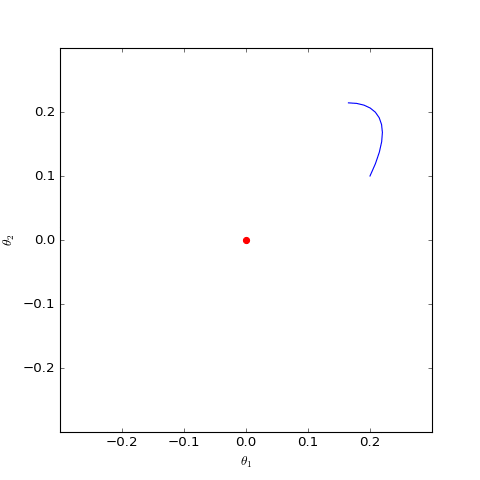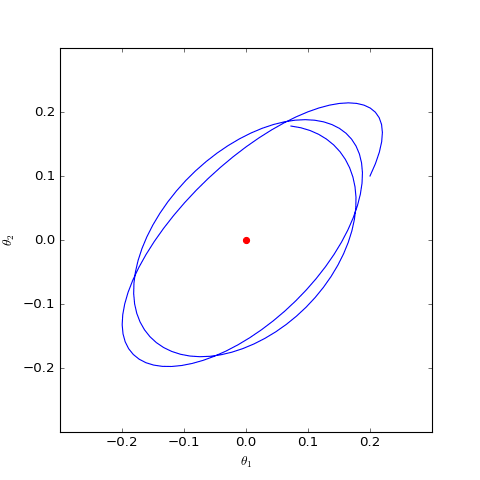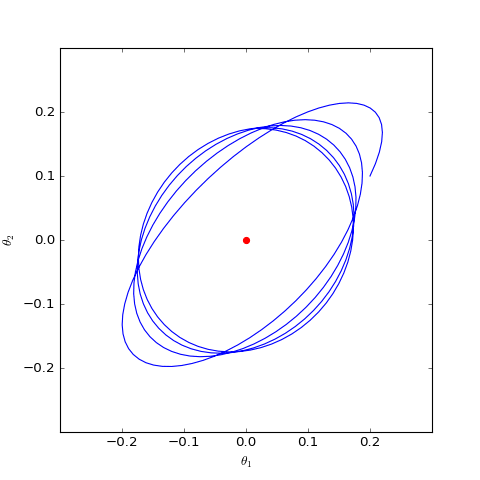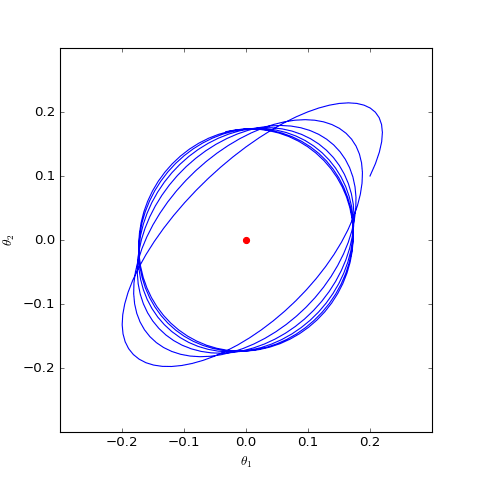
數值求解的GAN-QP對應的Dirac GAN的優化軌跡(二維情形),可以發現它確實只是在均衡點(紅色點)周圍振盪,不收斂
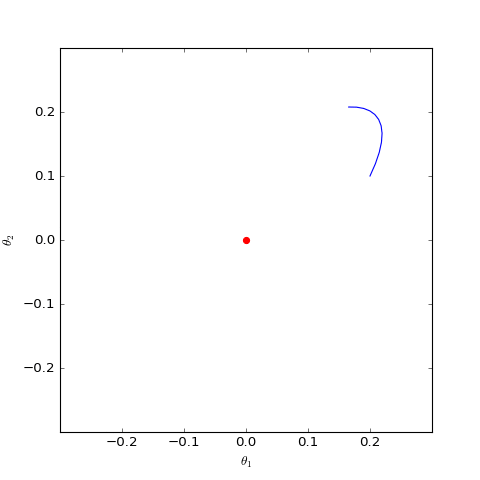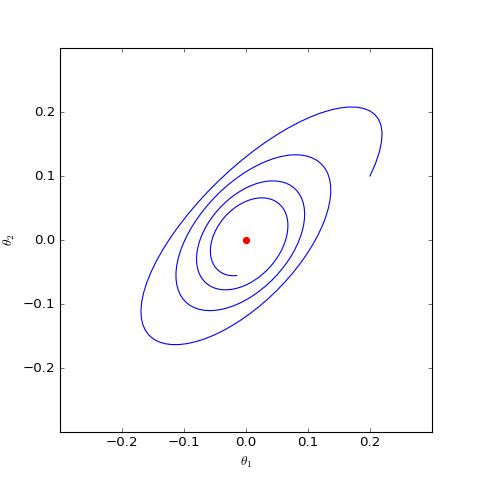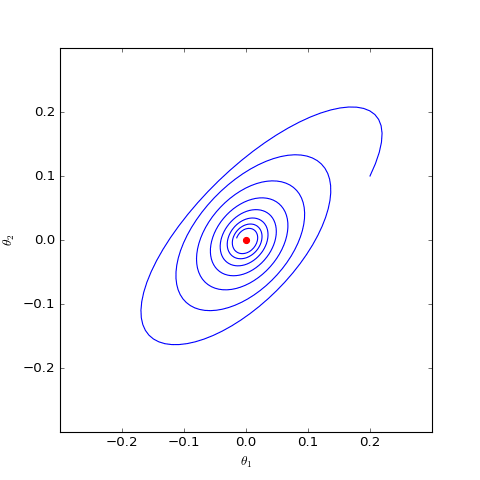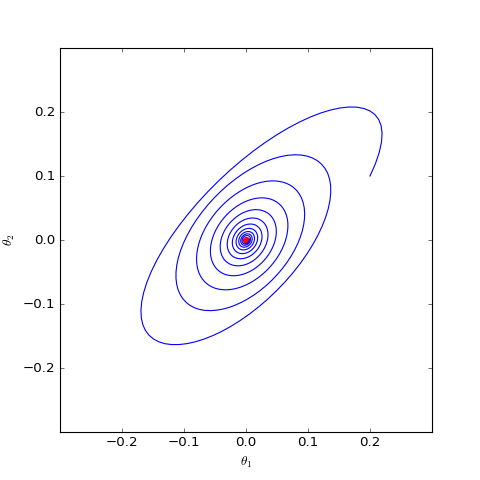
數值求解的帶有L2正則項的GAN-QP版本的Dirac GAN,其他條件一樣,僅加入了L2正則,這表明適當的L2正則項有可能誘導收斂
很遺憾,同大多數GAN一樣,GAN-QP也是振盪的。
緩解策略 #
通過上面的分析,我們得到的結論是:目前零中心的WGAN-GP(或者稱爲WGAN-div)的理論性質最好,只有它是局部收斂的,其餘的GAN變體都一定的振盪性,無法真正做到漸近收斂。當然,實際情況可能複雜得多,Dirac GAN的結論只能一定程度上說明問題,帶來一個直觀感知。
那麼,如果Dirac GAN的結論具有代表性的話(即多數GAN實際情況下都難以真正收斂,而是在均衡點附近振盪),我們應該如何緩解這個問題呢?
L2正則項 #
第一個方案是考慮往(任意GAN的)判別器的權重加入L2正則項。綜上所述,零中心的梯度懲罰確實很好,但無奈梯度懲罰太慢,如果不願意加梯度懲罰,那麼可以考慮加入L2正則項。
直觀上看,GAN在均衡點附近陷入振盪,達到一種動態平衡(週期解,而不是靜態解),而L2正則項會迫使判別器的權重向零移動,從而有可能打破這種平衡,如上圖中的第二個圖像。在我自己的GAN實驗中,往判別器加入一個輕微的L2正則項,能使得模型收斂更穩定,效果也有輕微提升。(當然,正則項的權重需要根據模型來調整好。)
權重滑動平均 #
事實上,緩解這個問題最有力的技巧,當屬權重滑動平均(EMA)。
權重滑動平均的基本概念,我們在《“讓Keras更酷一些!”:中間變量、權重滑動和安全生成器》已經介紹過。對於GAN上的應用,其實不難理解,因爲可以觀察到,儘管多數GAN最終都是在振盪,但它們振盪中心就是均衡點!所以解決方法很簡單,直接將振盪的軌跡上的點平均一下,得到近似的振盪中心,然後就得到了一個更接近均衡點(也就是更高質量)的解!
權重滑動平均帶來的提升是非常可觀的,如下圖比較了有無權重滑動平均時,O-GAN的生成效果圖:

沒有權重滑動平均時的隨機生成效果

權重滑動平均的衰減率爲0.999時的隨機生成效果

權重滑動平均的衰減率爲0.9999時的隨機生成效果
可以看到,權重滑動平均幾乎給生成效果帶來了質的提升。衰減率越大,所得到的生成結果越平滑,但同時會喪失一些細節;衰減率越小,保留的細節越多,但自然也可能保留了額外的噪聲。現在主流的GAN都使用了權重滑動平均,衰減率一般爲0.999。
順便說一下,在普通的監督訓練模型中,權重滑動平均一般也能帶來收斂速度的提升,比如下圖是有/無權重滑動平均時,ResNet20模型在cifar10上的訓練曲線,全程採用Adam優化器訓練,學習率恆爲0.001,權重滑動平均的衰減率爲0.9999:
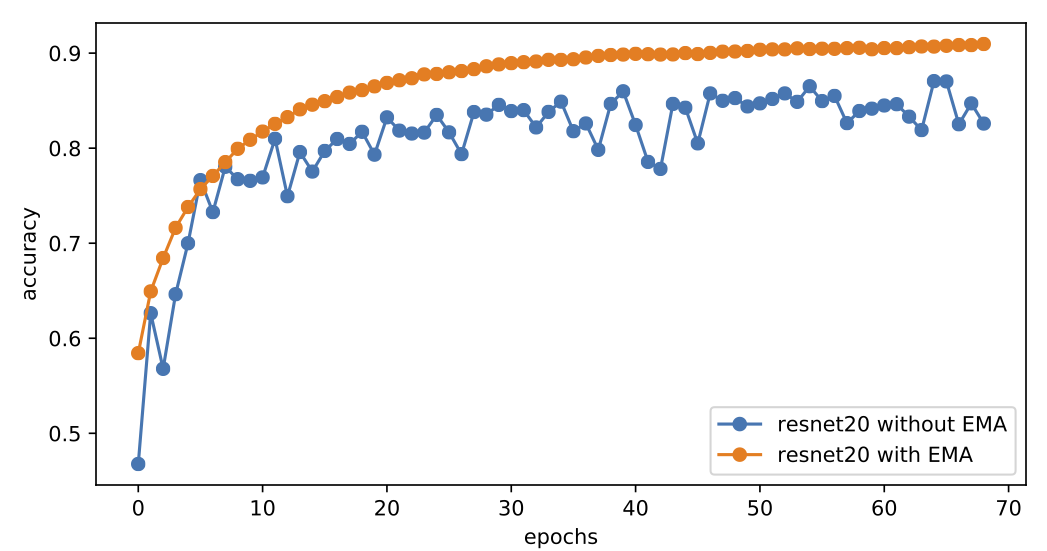
有無EMA時Adam默認學習率訓練ResNet20的表現
可以看到,加上權重滑動平均之後,模型以一種非常平穩、快速的姿態收斂到90%+的準確率,而不加的話模型準確率一直在86%左右振盪。這說明類似GAN的振盪現象在深度學習訓練時是普遍存在的,通過權重平均可以得到質量更好的模型。
文章小結 #
本文主要從動力學角度探討了GAN的優化問題。跟本系列的其他文章一樣,將優化過程視爲常微分方程組的求解,對於GAN的優化,這個常微分方程組稍微複雜一些。
分析的過程採用了Dirac GAN的思路,利用單點分佈的極簡情形對GAN的收斂過程形成快速認識,得到的結論是大多數GAN都無法真正收斂到均衡點,而只是在均衡點附近振盪。而爲了緩解這個問題,最有力的方法是權重滑動平均,它對GAN和普通模型訓練都有一定幫助。
(本文作圖代碼參考:https://github.com/bojone/gan/blob/master/gan_numeric.py)
轉載到請包括本文地址:https://spaces.ac.cn/archives/6583