




https://plantegg.github.io/2021/01/01/%E7%BD%91%E7%BB%9C%E7%9B%B8%E5%85%B3%E7%9F%A5%E8%AF%86/
程序員很難有機會接觸到底層的一些東西,尤其是偏硬件部分,所以記錄下
光纖和普通網線的性能差異
以下都是在4.19內核的UOS,光纖交換機爲銳捷,服務器是華爲鯤鵬920的環境測試所得數據:
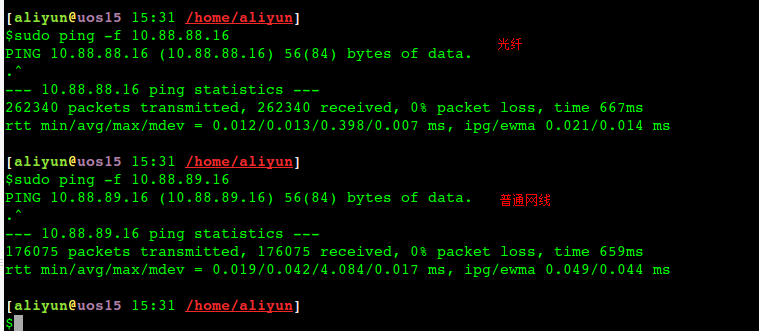
光纖穩定性好很多,平均rt是網線的三分之一,最大值則是網線的十分之一. 上述場景下光纖的帶寬大約是網線的1.5倍. 實際光纖理論帶寬一般都是萬M, 網線是千M.
光纖接口:

單模光纖和多模光纖
下圖綠色是多模光纖(Multi Mode Fiber),黃色是單模光纖(Single Mode Fiber), 因爲光纖最好能和光模塊匹配, 我們測試用的光模塊都是多模的, 單模光纖線便宜,但是對應的光模塊貴多了。
多模光模塊工作波長爲850nm,單模光模塊工作波長爲1310nm或1550nm, 從成本上來看,單模光模塊所使用的設備多出多模光模塊兩倍,總體成本遠高於多模光模塊,但單模光模塊的傳輸距離也要長於多模光模塊,單模光模塊最遠傳輸距離爲100km,多模光模塊最遠傳輸距離爲2km。因單模光纖的傳輸原理爲使光纖直射到中心,所以主要用作遠距離數據傳輸,而多模光纖則爲多通路傳播模式,所以主要用於短距離數據傳輸。單模光模塊適用於對距離和傳輸速率要求較高的大型網絡中,多模光模塊主要用於短途網路。
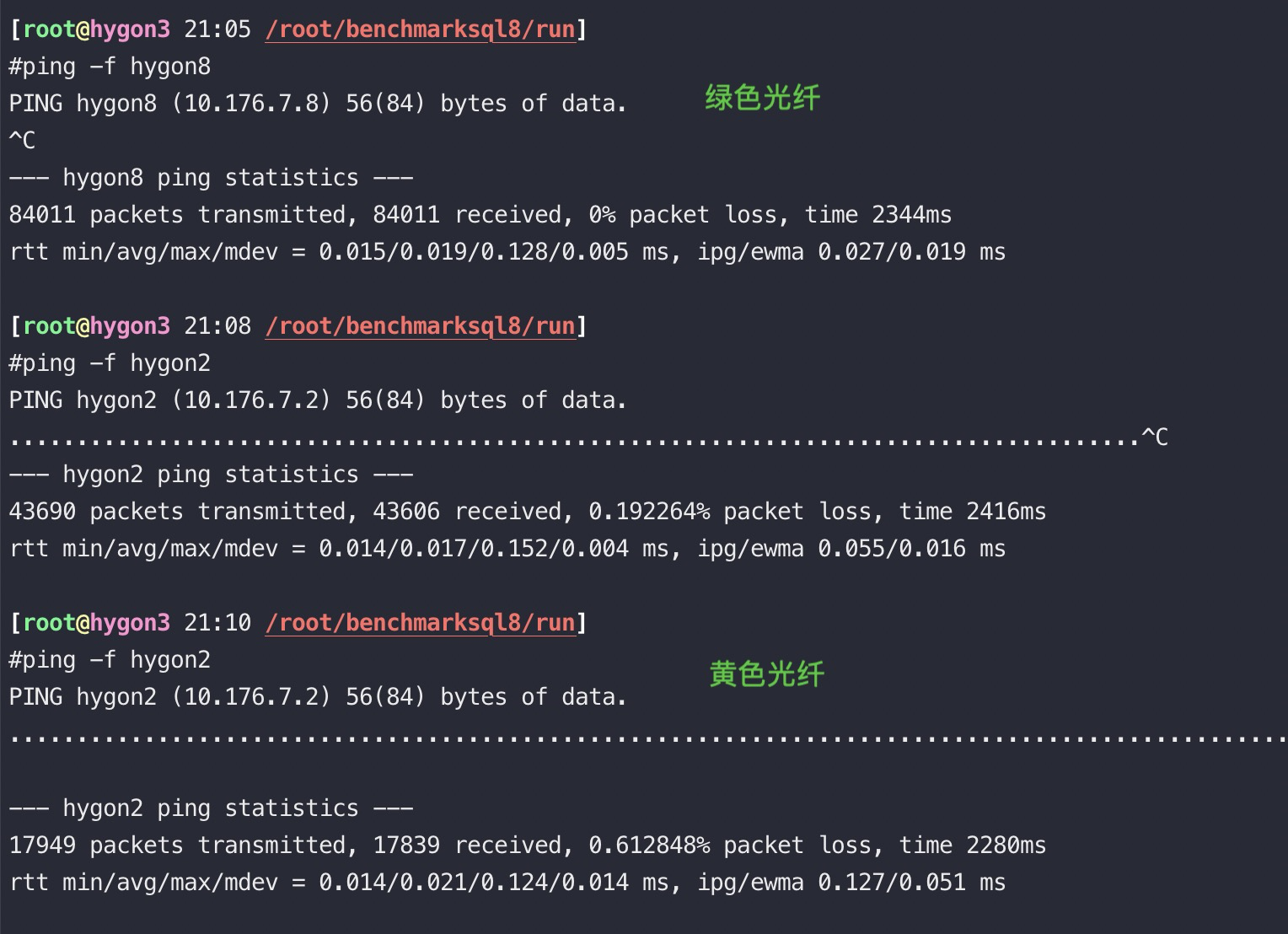
ping結果比較:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
[aliyun@uos15 11:00 /home/aliyun] 以下88都是光口、89都是電口。
PING 10.88.88.16 (10.88.88.16) 56(84) bytes of data.
64 bytes from 10.88.88.16: icmp_seq=1 ttl=64 time=0.058 ms
64 bytes from 10.88.88.16: icmp_seq=2 ttl=64 time=0.049 ms
64 bytes from 10.88.88.16: icmp_seq=3 ttl=64 time=0.053 ms
64 bytes from 10.88.88.16: icmp_seq=4 ttl=64 time=0.040 ms
64 bytes from 10.88.88.16: icmp_seq=5 ttl=64 time=0.053 ms
64 bytes from 10.88.88.16: icmp_seq=6 ttl=64 time=0.043 ms
64 bytes from 10.88.88.16: icmp_seq=7 ttl=64 time=0.038 ms
64 bytes from 10.88.88.16: icmp_seq=8 ttl=64 time=0.050 ms
64 bytes from 10.88.88.16: icmp_seq=9 ttl=64 time=0.043 ms
64 bytes from 10.88.88.16: icmp_seq=10 ttl=64 time=0.064 ms
--- 10.88.88.16 ping statistics ---
10 packets transmitted, 10 received, 0% packet loss, time 159ms
rtt min/avg/max/mdev = 0.038/0.049/0.064/0.008 ms
[aliyun@uos15 11:01 /home/aliyun]
PING 10.88.89.16 (10.88.89.16) 56(84) bytes of data.
64 bytes from 10.88.89.16: icmp_seq=1 ttl=64 time=0.087 ms
64 bytes from 10.88.89.16: icmp_seq=2 ttl=64 time=0.053 ms
64 bytes from 10.88.89.16: icmp_seq=3 ttl=64 time=0.095 ms
64 bytes from 10.88.89.16: icmp_seq=4 ttl=64 time=0.391 ms
64 bytes from 10.88.89.16: icmp_seq=5 ttl=64 time=0.051 ms
64 bytes from 10.88.89.16: icmp_seq=6 ttl=64 time=0.343 ms
64 bytes from 10.88.89.16: icmp_seq=7 ttl=64 time=0.045 ms
64 bytes from 10.88.89.16: icmp_seq=8 ttl=64 time=0.341 ms
64 bytes from 10.88.89.16: icmp_seq=9 ttl=64 time=0.054 ms
64 bytes from 10.88.89.16: icmp_seq=10 ttl=64 time=0.066 ms
--- 10.88.89.16 ping statistics ---
10 packets transmitted, 10 received, 0% packet loss, time 149ms
rtt min/avg/max/mdev = 0.045/0.152/0.391/0.136 ms
[aliyun@uos15 11:02 /u01]
uos.tar 100% 3743MB 111.8MB/s 00:33
[aliyun@uos15 11:03 /u01]
uos.tar 100% 3743MB 178.7MB/s 00:20
[aliyun@uos15 11:07 /u01]
PING 10.88.89.16 (10.88.89.16) 56(84) bytes of data.
--- 10.88.89.16 ping statistics ---
284504 packets transmitted, 284504 received, 0% packet loss, time 702ms
rtt min/avg/max/mdev = 0.019/0.040/1.014/0.013 ms, ipg/ewma 0.048/0.042 ms
[aliyun@uos15 11:07 /u01]
PING 10.88.88.16 (10.88.88.16) 56(84) bytes of data.
--- 10.88.88.16 ping statistics ---
299748 packets transmitted, 299748 received, 0% packet loss, time 242ms
rtt min/avg/max/mdev = 0.012/0.016/0.406/0.006 ms, pipe 2, ipg/ewma 0.034/0.014 ms
|
多網卡bonding
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
DEVICE=bond0
TYPE=Bond
ONBOOT=yes
BOOTPROTO=static
IPADDR=10.176.7.11
NETMASK=255.255.255.0
#cat /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=none
MASTER=bond0
SLAVE=yes
#cat /etc/sysconfig/network-scripts/ifcfg-eth1
DEVICE=eth1
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=none
MASTER=bond0
SLAVE=yes
#cat /proc/net/bonding/bond0
----加載內核bonding模塊, mode=0 是RR負載均衡模式
alias bond0 bonding
options bond0 mode=0 miimon=100 //這一行也可以放到bond0配置文件中,比如:BONDING_OPTS="miimon=100 mode=4 xmit_hash_policy=layer3+4" 用iperf 多連接測試bonding後的帶寬發現,發送端能用上兩張網卡,但是接收隊列只能使用一張物理網卡
|
網卡綁定mode共有七種(0~6) bond0、bond1、bond2、bond3、bond4、bond5、bond6
常用的有三種
-
mode=0:平衡負載模式 (balance-rr),有自動備援,兩塊物理網卡和bond網卡使用同一個mac地址,但需要”Switch”支援及設定。
-
mode=1:自動備援模式 (balance-backup),其中一條線若斷線,其他線路將會自動備援。
-
mode=6:平衡負載模式(balance-alb),有自動備援,不必”Switch”支援及設定,兩塊網卡是使用不同的MAC地址
- Mode 4 (802.3ad): This mode creates aggregation groups that share the same speed and duplex settings, and it requires a switch that supports an IEEE 802.3ad dynamic link. Mode 4 uses all interfaces in the active aggregation group. For example, you can aggregate three 1 GB per second (GBPS) ports into a 3 GBPS trunk port. This is equivalent to having one interface with 3 GBPS speed. It provides fault tolerance and load balancing.
需要說明的是如果想做成mode 0的負載均衡,僅僅設置這裏options bond0 miimon=100 mode=0是不夠的,與網卡相連的交換機必須做特殊配置(這兩個端口應該採取聚合方式),因爲做bonding的這兩塊網卡是使用同一個MAC地址.從原理分析一下(bond運行在mode 0下):
mode 0下bond所綁定的網卡的IP都被修改成相同的mac地址,如果這些網卡都被接在同一個交換機,那麼交換機的arp表裏這個mac地址對應的端口就有多 個,那麼交換機接受到發往這個mac地址的包應該往哪個端口轉發呢?正常情況下mac地址是全球唯一的,一個mac地址對應多個端口肯定使交換機迷惑了。所以 mode0下的bond如果連接到交換機,交換機這幾個端口應該採取聚合方式(cisco稱爲 ethernetchannel,foundry稱爲portgroup),因爲交換機做了聚合後,聚合下的幾個端口也被捆綁成一個mac地址.我們的解決辦法是,兩個網卡接入不同的交換機即可。
mode6模式下無需配置交換機,因爲做bonding的這兩塊網卡是使用不同的MAC地址。
mod=5,即:(balance-tlb) Adaptive transmit load balancing(適配器傳輸負載均衡)
特點:不需要任何特別的switch(交換機)支持的通道bonding。在每個slave上根據當前的負載(根據速度計算)分配外出流量。如果正在接受數據的slave出故障了,另一個slave接管失敗的slave的MAC地址。
該模式的必要條件:ethtool支持獲取每個slave的速率.
案例,兩塊萬兆bonding後帶寬翻倍
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
#ethtool bond0
Settings for bond0:
Supported ports: [ ]
Supported link modes: Not reported
Supported pause frame use: No
Supports auto-negotiation: No
Advertised link modes: Not reported
Advertised pause frame use: No
Advertised auto-negotiation: No
Speed: 20000Mb/s
Duplex: Full
Port: Other
PHYAD: 0
Transceiver: internal
Auto-negotiation: off
Link detected: yes
[root@phy 16:55 /root]
#cat /etc/sysconfig/network-scripts/ifcfg-bond0
DEVICE=bond0
BOOTPROTO=static
TYPE="ethernet"
IPADDR=100.1.1.2
NETMASK=255.255.255.192
ONBOOT=yes
USERCTL=no
PEERDNS=no
BONDING_OPTS="miimon=100 mode=4 xmit_hash_policy=layer3+4"
#cat /etc/modprobe.d/bonding.conf
alias netdev-bond0 bonding
#lsmod |grep bond
bonding 137339 0
#cat ifcfg-bond0
DEVICE=bond0
BOOTPROTO=static
TYPE="ethernet"
IPADDR=100.81.131.221
NETMASK=255.255.255.192
ONBOOT=yes
USERCTL=no
PEERDNS=no
BONDING_OPTS="miimon=100 mode=4 xmit_hash_policy=layer3+4"
#cat ifcfg-eth1
DEVICE=eth1
TYPE="Ethernet"
HWADDR=7C:D3:0A:E0:F7:81
BOOTPROTO=none
ONBOOT=yes
MASTER=bond0
SLAVE=yes
PEERDNS=no
RX_MAX=`ethtool -g "$DEVICE" | grep 'Pre-set' -A1 | awk '/RX/{print $2}'`
RX_CURRENT=`ethtool -g "$DEVICE" | grep "Current" -A1 | awk '/RX/{print $2}'`
[[ "$RX_CURRENT" -lt "$RX_MAX" ]] && ethtool -G "$DEVICE" rx "$RX_MAX"
|
網絡中斷和綁核
網絡包的描述符的內存(RingBuffer)跟着設備走(設備在哪個Die/Node上,就近分配內存), 數據緩衝區(Data Buffer–存放網絡包)內存跟着隊列(中斷)走, 如果隊列綁定到DIE0, 而設備在die1上,這樣在做DMA通信時, 會產生跨die的交織訪問。
不管設備插在哪一個die上, 只要描述符申請的內存和數據緩衝區的內存都在同一個die上(需要修改驅動源代碼–非常規),就能避免跨die內存交織, 性能能保持一致。
irqbalance服務不會將中斷進行跨node遷移,只會在同一numa node中進行優化。
ethtool
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
driver: mlx5_core
version: 5.0-0
firmware-version: 14.27.1016 (MT_2420110004)
expansion-rom-version:
bus-info: 0000:21:00.0
supports-statistics: yes
supports-test: yes
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: yes
//根據bus-info找到中斷id
//修改網卡隊列數
sudo ethtool -L eth0 combined 2 (不能超過網卡最大隊列數)
然後檢查是否生效了(不需要重啓應用和機器,實時生效):
sudo ethtool -l eth0
|
根據網卡bus-info可以找到對應的irq id
手工綁核腳本:
|
1
2
3
4
5
6
7
8
9
10
11
|
intf=$1
irq_list=(cat /proc/interrupts | grep `ethtool -i $intf |grep bus-info | awk '{ print $2 }'` | awk -F: '{print $1}')
cpunum=48 # 修改爲所在node的第一個Core
for irq in ${irq_list[@]}
do
echo $cpunum > /proc/irq/$irq/smp_affinity_list
echo `cat /proc/irq/$irq/smp_affinity_list`
(( cpunum+=1 ))
done
|
檢查綁定結果: sh irqCheck.sh enp131s0
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
intf=$1
irqID=`ethtool -i $intf |grep bus-info | awk '{ print $2 }'`
log=irqSet-`date "+%Y%m%d-%H%M%S"`.log
cpuNum=$(cat /proc/cpuinfo |grep processor -c)
irqListRx=$(cat /proc/interrupts | grep ${irqID} | awk -F':' '{print $1}')
irqListTx=$(cat /proc/interrupts | grep ${irqID} | awk -F':' '{print $1}')
for irqRX in ${irqListRx[@]}
do
cat /proc/irq/${irqRX}/smp_affinity_list
done
for irqTX in ${irqListTx[@]}
do
cat /proc/irq/${irqTX}/smp_affinity_list
done
|
中斷聯合(Coalescing)
中斷聯合可供我們推遲向內核通告新事件的操作,將多個事件彙總在一箇中斷中通知內核。該功能的當前設置可通過ethtool -c查看:
|
1
2
3
4
5
|
$ ethtool -c eth0
Coalesce parameters for eth0:
...
rx-usecs: 50
tx-usecs: 50
|
此處可以設置固定上限,對每內核每秒處理中斷數量的最大值進行硬性限制,或針對特定硬件根據吞吐率自動調整中斷速率。
啓用聯合(使用-C)會增大延遲並可能導致丟包,因此對延遲敏感的工作可能需要避免這樣做。另外,徹底禁用該功能可能導致中斷受到節流限制,進而影響性能。
多次在nginx場景下測試未發現這個值對TPS有什麼明顯的改善
How to achieve low latency with 10Gbps Ethernet 中有提到 Linux 3.11 added support for the SO_BUSY_POLL socket option. 也有類似的作用
irqbalance
irqbalance 是一個命令行工具,在處理器中分配硬件中斷以提高系統性能。默認設置下在後臺程序運行,但只可通過 --oneshot 選項運行一次。
以下參數可用於提高性能。
-
–powerthresh
CPU 進入節能模式之前,設定可空閒的 CPU 數量。如果有大於閥值數量的 CPU 是大於一個標準的偏差,該差值低於平均軟中斷工作負載,以及沒有 CPU 是大於一個標準偏差,且該偏差高出平均,並有多於一個的 irq 分配給它們,一個 CPU 將處於節能模式。在節能模式中,CPU 不是 irqbalance 的一部分,所以它在有必要時纔會被喚醒。
-
–hintpolicy
決定如何解決 irq 內核關聯提示。有效值爲
exact(總是應用 irq 關聯提示)、subset(irq 是平衡的,但分配的對象是關聯提示的子集)、或者ignore(irq 完全被忽略)。 -
–policyscript
通過設備路徑、當作參數的irq號碼以及 irqbalance 預期的零退出代碼,定義腳本位置以執行每個中斷請求。定義的腳本能指定零或多鍵值對來指導管理傳遞的 irq 中 irqbalance。下列是爲效鍵值對:ban有效值爲
true(從平衡中排除傳遞的 irq)或false(該 irq 表現平衡)。balance_level允許用戶重寫傳遞的 irq 平衡度。默認設置下,平衡度基於擁有 irq 設備的 PCI 設備種類。有效值爲none、package、cache、或core。numa_node允許用戶重寫視作爲本地傳送 irq 的 NUMA 節點。如果本地節點的信息沒有限定於 ACPI ,則設備被視作與所有節點距離相等。有效值爲識別特定 NUMA 節點的整數(從0開始)和-1,規定 irq 應被視作與所有節點距離相等。 -
–banirq
將帶有指定中斷請求號碼的中斷添加至禁止中斷的列表。
也可以使用 IRQBALANCE_BANNED_CPUS 環境變量來指定被 irqbalance 忽略的 CPU 掩碼。
|
1
2
3
4
5
|
//默認irqbalance綁定一個numa, -1指定多個numa
echo -1 >/sys/bus/pci/devices/`ethtool -i p1p1 |grep bus-info | awk '{ print $2 }'`/numa_node ;
// 目錄 /sys/class/net/p1p1/ link到了 /sys/bus/pci/devices/`ethtool -i p1p1 |grep bus-info | awk '{ print $2 }'`
執行 irqbalance --debug 進行調試
|
irqbalance指定core
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
cat /etc/sysconfig/irqbalance
# IRQBALANCE_BANNED_CPUS
# 64 bit bitmask which allows you to indicate which cpu's should
# be skipped when reblancing irqs. Cpu numbers which have their
# corresponding bits set to one in this mask will not have any
# irq's assigned to them on rebalance
#綁定軟中斷到8-15core, 每位表示4core
#IRQBALANCE_BANNED_CPUS=ffffffff,ffff00ff
#綁定軟中斷到8-15core和第65core
IRQBALANCE_BANNED_CPUS=ffffffff,fffffdff,ffffffff,ffff00ff
#96core 鯤鵬920下綁前16core
IRQBALANCE_BANNED_CPUS=ffffffff,ffffffff,ffff0000
|
irqbalance的流程
初始化的過程只是建立鏈表的過程,暫不描述,只考慮正常運行狀態時的流程
-處理間隔是10s
-清除所有中斷的負載值
-/proc/interrupts讀取中斷,並記錄中斷數
-/proc/stat讀取每個cpu的負載,並依次計算每個層次每個節點的負載以及每個中斷的負載
-通過平衡算法找出需要重新分配的中斷
-把需要重新分配的中斷加入到新的節點中
-配置smp_affinity使處理生效
irqbalance服務不會將中斷進行跨node遷移,只會在同一numa node中進行優化。
網卡軟中斷以及內存遠近的測試結論
一般網卡中斷會佔用一些CPU,如果把網卡中斷挪到其它node的core上,在鯤鵬920上測試(網卡插在node0上),業務跑在node3,網卡中斷分別在node0和node3,QPS分別是:179000 VS 175000
如果將業務跑在node0上,網卡中斷分別在node0和node1上得到的QPS分別是:204000 VS 212000
以上測試的時候業務進程分配的內存全限制在node0上
|
1
2
3
4
5
6
7
8
9
10
|
#/root/numa-maps-summary.pl </proc/123853/numa_maps
N0 : 5085548 ( 19.40 GB)
N1 : 4479 ( 0.02 GB)
N2 : 1 ( 0.00 GB)
active : 0 ( 0.00 GB)
anon : 5085455 ( 19.40 GB)
dirty : 5085455 ( 19.40 GB)
kernelpagesize_kB: 2176 ( 0.01 GB)
mapmax : 348 ( 0.00 GB)
mapped : 4626 ( 0.02 GB)
|
從以上測試數據可以看到在這個內存分佈場景下,如果就近訪問內存性能有20%以上的提升
阿里雲綁核腳本
通常情況下,Linux的網卡中斷是由一個CPU核心來處理的,當承擔高流量的場景下,會出現一些詭異的情況(網卡尚未達到瓶頸,但是卻出現丟包的情況)
這種時候,我們最好看下網卡中斷是不是缺少調優。
優化3要點:網卡多隊列+irq affinity親緣性設置+關閉irqbalance (systemctl stop irqbalance)
目前阿里雲官方提供的centos和ubuntu鏡像裏面,已經自帶了優化腳本,內容如下:
centos7的腳本路徑在 /usr/sbin/ecs_mq_rps_rfs 具體內容如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
|
function set_check_multiqueue()
{
eth=$1
log_file=$2
queue_num=$(ethtool -l $eth | grep -ia5 'pre-set' | grep -i combined | awk {'print $2'})
if [ $queue_num -gt 1 ]; then
# set multiqueue
ethtool -L $eth combined $queue_num
# check multiqueue setting
cur_q_num=$(ethtool -l $eth | grep -iA5 current | grep -i combined | awk {'print $2'})
if [ "X$queue_num" != "X$cur_q_num" ]; then
echo "Failed to set $eth queue size to $queue_num" >> $log_file
echo "after setting, pre-set queue num: $queue_num , current: $cur_q_num" >> $log_file
return 1
else
echo "OK. set $eth queue size to $queue_num" >> $log_file
fi
else
echo "only support $queue_num queue; no need to enable multiqueue on $eth" >> $log_file
fi
}
#set irq affinity
function set_irq_smpaffinity()
{
log_file=$1
node_dir=/sys/devices/system/node
for i in $(ls -d $node_dir/node*); do
i=${i/*node/}
done
echo "max node :$i" >> $log_file
node_cpumax=$(cat /sys/devices/system/node/node${i}/cpulist |awk -F- '{print $NF}')
irqs=($(cat /proc/interrupts |grep virtio |grep put | awk -F: '{print $1}'))
core=0
for irq in ${irqs[@]};do
VEC=$core
if [ $VEC -ge 32 ];then
let "IDX = $VEC / 32"
MASK_FILL=""
MASK_ZERO="00000000"
for ((i=1; i<=$IDX;i++))
do
MASK_FILL="${MASK_FILL},${MASK_ZERO}"
done
let "VEC -= 32 * $IDX"
MASK_TMP=$((1<<$VEC))
MASK=$(printf "%X%s" $MASK_TMP $MASK_FILL)
else
MASK_TMP=$((1<<$VEC))
MASK=$(printf "%X" $MASK_TMP)
fi
echo $MASK > /proc/irq/$irq/smp_affinity
echo "mask:$MASK, irq:$irq" >> $log_file
core=$(((core+1)%(node_cpumax+1)))
done
}
# stop irqbalance service
function stop_irqblance()
{
log_file=$1
ret=0
if [ "X" != "X$(ps -ef | grep irqbalance | grep -v grep)" ]; then
if which systemctl;then
systemctl stop irqbalance
else
service irqbalance stop
fi
if [ $? -ne 0 ]; then
echo "Failed to stop irqbalance" >> $log_file
ret=1
fi
else
echo "OK. irqbalance stoped." >> $log_file
fi
return $ret
}
function main()
{
ecs_network_log=/var/log/ecs_network_optimization.log
ret_value=0
echo "running $0" > $ecs_network_log
echo "======== ECS network setting starts $(date +'%Y-%m-%d %H:%M:%S') ========" >> $ecs_network_log
# we assume your NIC interface(s) is/are like eth*
eth_dirs=$(ls -d /sys/class/net/eth*)
if [ "X$eth_dirs" = "X" ]; then
echo "ERROR! can not find any ethX in /sys/class/net/ dir." >> $ecs_network_log
ret_value=1
fi
for i in $eth_dirs
do
cur_eth=$(basename $i)
echo "optimize network performance: current device $cur_eth" >> $ecs_network_log
# only optimize virtio_net device
driver=$(basename $(readlink $i/device/driver))
if ! echo $driver | grep -q virtio; then
echo "ignore device $cur_eth with driver $driver" >> $ecs_network_log
continue
fi
echo "set and check multiqueue on $cur_eth" >> $ecs_network_log
set_check_multiqueue $cur_eth $ecs_network_log
if [ $? -ne 0 ]; then
echo "Failed to set multiqueue on $cur_eth" >> $ecs_network_log
ret_value=1
fi
done
stop_irqblance $ecs_network_log
set_irq_smpaffinity $ecs_network_log
echo "======== ECS network setting END $(date +'%Y-%m-%d %H:%M:%S') ========" >> $ecs_network_log
return $ret_value
}
# program starts here
main
exit $?
|
查詢的rps綁定情況的腳本 get_rps.sh
|
1
2
3
4
5
6
|
for i in $(ls /sys/class/net/eth0/queues/rx-*/rps_cpus); do
echo $i
cat $i
done
|
查看網卡和numa的關係
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#yum install lshw -y
#lshw -C network -short
H/W path Device Class Description
=============================================================
/0/100/0/9/0 eth0 network MT27710 Family [ConnectX-4 Lx]
/0/100/0/9/0.1 eth1 network MT27710 Family [ConnectX-4 Lx]
/1 e41358fae4ee_h network Ethernet interface
/2 86b0637ef1e1_h network Ethernet interface
/3 a6706e785f53_h network Ethernet interface
/4 d351290e50a0_h network Ethernet interface
/5 1a9e5df98dd1_h network Ethernet interface
/6 766ec0dab599_h network Ethernet interface
/7 bond0.11 network Ethernet interface
/8 ea004888c217_h network Ethernet interface
|
以及:
|
1
2
3
|
lscpu | grep -i numa
numactl --hardware
cat /proc/interrupts | egrep -i "CPU|rx"
|
Check if the network interfaces are tied to Numa (if -1 means not tied, if 0, then to numa0):
|
1
|
cat /sys/class/net/eth0/device/numa_node
|
You can see which NAMA the network card belongs to, for example, using lstopo:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
|
yum install hwloc -y
lstopo
lstopo --logical
lstopo --logical --output-format png > lstopo.png
--
[root@hygon3 10:58 /root] //hygon 7280 CPU
#lstopo --logical
Machine (503GB total) //總內存大小
NUMANode L#0 (P#0 252GB) //socket0、numa0 的內存大小
Package L#0
L3 L#0 (8192KB) //L3 cache,對應4個物理core,8個HT
L2 L#0 (512KB) + L1d L#0 (32KB) + L1i L#0 (64KB) + Core L#0 // L1/L2
PU L#0 (P#0)
PU L#1 (P#64)
L2 L#1 (512KB) + L1d L#1 (32KB) + L1i L#1 (64KB) + Core L#1
PU L#2 (P#1)
PU L#3 (P#65)
L2 L#2 (512KB) + L1d L#2 (32KB) + L1i L#2 (64KB) + Core L#2
PU L#4 (P#2)
PU L#5 (P#66)
L2 L#3 (512KB) + L1d L#3 (32KB) + L1i L#3 (64KB) + Core L#3
PU L#6 (P#3)
PU L#7 (P#67)
L3 L#1 (8192KB)
L3 L#2 (8192KB)
L3 L#3 (8192KB)
L3 L#4 (8192KB)
L3 L#5 (8192KB)
L3 L#6 (8192KB)
L3 L#7 (8192KB)
HostBridge L#0
PCIBridge
PCIBridge
PCI 1a03:2000
GPU L#0 "controlD64"
GPU L#1 "card0"
PCIBridge
PCI 1d94:7901
Block(Disk) L#2 "sdm" //ssd系統盤,接在Node0上,綁核有優勢
HostBridge L#4
PCIBridge
PCI 1000:0097
PCIBridge
PCI 1c5f:000d
PCIBridge
PCI 1c5f:000d
HostBridge L#8
PCIBridge
PCI 15b3:1015
Net L#3 "p1p1" //萬兆網卡接在Node0上
PCI 15b3:1015
Net L#4 "p1p2"
HostBridge L#10
PCIBridge
PCI 8086:1521
Net L#5 "em1" //千兆網卡接在Node0上
PCI 8086:1521
Net L#6 "em2"
NUMANode L#1 (P#1 251GB) //另外一個socket
Package L#1
L3 L#8 (8192KB)
L2 L#32 (512KB) + L1d L#32 (32KB) + L1i L#32 (64KB) + Core L#32
----------- FT2500 兩路共128core
#lstopo-no-graphics --logical
Machine (503GB total)
Package L#0 + L3 L#0 (64MB)
NUMANode L#0 (P#0 31GB)
L2 L#0 (2048KB) //4個物理core共享2M
L1d L#0 (32KB) + L1i L#0 (32KB) + Core L#0 + PU L#0 (P#0)
L1d L#1 (32KB) + L1i L#1 (32KB) + Core L#1 + PU L#1 (P#1)
L1d L#2 (32KB) + L1i L#2 (32KB) + Core L#2 + PU L#2 (P#2)
L1d L#3 (32KB) + L1i L#3 (32KB) + Core L#3 + PU L#3 (P#3)
L2 L#1 (2048KB)
L1d L#4 (32KB) + L1i L#4 (32KB) + Core L#4 + PU L#4 (P#4)
L1d L#5 (32KB) + L1i L#5 (32KB) + Core L#5 + PU L#5 (P#5)
L1d L#6 (32KB) + L1i L#6 (32KB) + Core L#6 + PU L#6 (P#6)
L1d L#7 (32KB) + L1i L#7 (32KB) + Core L#7 + PU L#7 (P#7)
HostBridge L#0
PCIBridge
PCIBridge
PCIBridge
PCI 1000:00ac
Block(Disk) L#0 "sdh"
Block(Disk) L#1 "sdf" // 磁盤掛在Node0上
PCIBridge
PCI 8086:1521
Net L#13 "eth0"
PCI 8086:1521
Net L#14 "eth1" //網卡掛在node0上
PCIBridge
PCIBridge
PCI 1a03:2000
GPU L#15 "controlD64"
GPU L#16 "card0"
NUMANode L#1 (P#1 31GB)
NUMANode L#2 (P#2 31GB)
NUMANode L#3 (P#3 31GB)
NUMANode L#4 (P#4 31GB)
NUMANode L#5 (P#5 31GB)
NUMANode L#6 (P#6 31GB)
NUMANode L#7 (P#7 31GB)
L2 L#14 (2048KB)
L1d L#56 (32KB) + L1i L#56 (32KB) + Core L#56 + PU L#56 (P#56)
L1d L#57 (32KB) + L1i L#57 (32KB) + Core L#57 + PU L#57 (P#57)
L1d L#58 (32KB) + L1i L#58 (32KB) + Core L#58 + PU L#58 (P#58)
L1d L#59 (32KB) + L1i L#59 (32KB) + Core L#59 + PU L#59 (P#59)
L2 L#15 (2048KB)
L1d L#60 (32KB) + L1i L#60 (32KB) + Core L#60 + PU L#60 (P#60)
L1d L#61 (32KB) + L1i L#61 (32KB) + Core L#61 + PU L#61 (P#61)
L1d L#62 (32KB) + L1i L#62 (32KB) + Core L#62 + PU L#62 (P#62)
L1d L#63 (32KB) + L1i L#63 (32KB) + Core L#63 + PU L#63 (P#63)
Package L#1 + L3 L#1 (64MB) //socket2
NUMANode L#8 (P#8 31GB)
L2 L#16 (2048KB)
L1d L#64 (32KB) + L1i L#64 (32KB) + Core L#64 + PU L#64 (P#64)
L1d L#65 (32KB) + L1i L#65 (32KB) + Core L#65 + PU L#65 (P#65)
L1d L#66 (32KB) + L1i L#66 (32KB) + Core L#66 + PU L#66 (P#66)
L1d L#67 (32KB) + L1i L#67 (32KB) + Core L#67 + PU L#67 (P#67)
L2 L#17 (2048KB)
L1d L#68 (32KB) + L1i L#68 (32KB) + Core L#68 + PU L#68 (P#68)
L1d L#69 (32KB) + L1i L#69 (32KB) + Core L#69 + PU L#69 (P#69)
L1d L#70 (32KB) + L1i L#70 (32KB) + Core L#70 + PU L#70 (P#70)
L1d L#71 (32KB) + L1i L#71 (32KB) + Core L#71 + PU L#71 (P#71)
HostBridge L#7
PCIBridge
PCIBridge
PCIBridge
PCI 15b3:1015
Net L#17 "eth2" //node8 上的網卡,eth2、eth3做了bonding
PCI 15b3:1015
Net L#18 "eth3"
PCIBridge
PCI 144d:a808
PCIBridge
PCI 144d:a808
---鯤鵬920 每路48core 2路共4node,網卡插在node0,磁盤插在node2
#lstopo-no-graphics
Machine (755GB total)
Package L#0
NUMANode L#0 (P#0 188GB)
L3 L#0 (24MB)
L2 L#0 (512KB) + L1d L#0 (64KB) + L1i L#0 (64KB) + Core L#0 + PU L#0 (P#0)
L2 L#1 (512KB) + L1d L#1 (64KB) + L1i L#1 (64KB) + Core L#1 + PU L#1 (P#1)
L2 L#22 (512KB) + L1d L#22 (64KB) + L1i L#22 (64KB) + Core L#22 + PU L#22 (P#22)
L2 L#23 (512KB) + L1d L#23 (64KB) + L1i L#23 (64KB) + Core L#23 + PU L#23 (P#23)
HostBridge L#0
PCIBridge
PCI 15b3:1017
Net L#0 "enp2s0f0"
PCI 15b3:1017
Net L#1 "eth1"
PCIBridge
PCI 19e5:1711
GPU L#2 "controlD64"
GPU L#3 "card0"
HostBridge L#3
2 x { PCI 19e5:a230 }
PCI 19e5:a235
Block(Disk) L#4 "sda"
HostBridge L#4
PCIBridge
PCI 19e5:a222
Net L#5 "enp125s0f0"
PCI 19e5:a221
Net L#6 "enp125s0f1"
PCI 19e5:a222
Net L#7 "enp125s0f2"
PCI 19e5:a221
Net L#8 "enp125s0f3"
NUMANode L#1 (P#1 189GB) + L3 L#1 (24MB)
L2 L#24 (512KB) + L1d L#24 (64KB) + L1i L#24 (64KB) + Core L#24 + PU L#24 (P#24)
Package L#1
NUMANode L#2 (P#2 189GB)
L3 L#2 (24MB)
L2 L#48 (512KB) + L1d L#48 (64KB) + L1i L#48 (64KB) + Core L#48 + PU L#48 (P#48)
HostBridge L#6
PCIBridge
PCI 19e5:3714
PCIBridge
PCI 19e5:3714
PCIBridge
PCI 19e5:3714
PCIBridge
PCI 19e5:3714
HostBridge L#11
PCI 19e5:a230
PCI 19e5:a235
PCI 19e5:a230
NUMANode L#3 (P#3 189GB) + L3 L#3 (24MB)
L2 L#72 (512KB) + L1d L#72 (64KB) + L1i L#72 (64KB) + Core L#72 + PU L#72 (P#72)
Misc(MemoryModule)
|
如果cpu core太多, interrupts 沒法看的話,通過cut只看其中一部分core
|
1
|
cat /proc/interrupts | grep -i 'eth4\|CPU' | cut -c -8,865-995,1425-
|
lspci
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
21:00.0 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx]
Subsystem: Mellanox Technologies ConnectX-4 Lx Stand-up dual-port 10GbE MCX4121A-XCAT
Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr+ Stepping- SERR+ FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 64 bytes
Interrupt: pin A routed to IRQ 105
Region 0: Memory at 3249c000000 (64-bit, prefetchable) [size=32M]
Expansion ROM at db300000 [disabled] [size=1M]
Capabilities: [60] Express (v2) Endpoint, MSI 00
DevCap: MaxPayload 512 bytes, PhantFunc 0, Latency L0s unlimited, L1 unlimited
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+ SlotPowerLimit 0.000W
DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq-
RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop+ FLReset-
MaxPayload 512 bytes, MaxReadReq 512 bytes
DevSta: CorrErr+ NonFatalErr- FatalErr- UnsupReq+ AuxPwr- TransPend-
LnkCap: Port #0, Speed 8GT/s, Width x8, ASPM not supported
ClockPM- Surprise- LLActRep- BwNot- ASPMOptComp+
LnkCtl: ASPM Disabled; RCB 64 bytes Disabled- CommClk+
ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 8GT/s (ok), Width x8 (ok)
TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
DevCap2: Completion Timeout: Range ABC, TimeoutDis+, LTR-, OBFF Not Supported
AtomicOpsCap: 32bit- 64bit- 128bitCAS-
DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis-, LTR-, OBFF Disabled
AtomicOpsCtl: ReqEn-
LnkCtl2: Target Link Speed: 8GT/s, EnterCompliance- SpeedDis-
Transmit Margin: Normal Operating Range, EnterModifiedCompliance- ComplianceSOS-
Compliance De-emphasis: -6dB
LnkSta2: Current De-emphasis Level: -6dB, EqualizationComplete+, EqualizationPhase1+
EqualizationPhase2+, EqualizationPhase3+, LinkEqualizationRequest-
Capabilities: [48] Vital Product Data
Product Name: CX4121A - ConnectX-4 LX SFP28
Read-only fields:
[PN] Part number: MCX4121A-XCAT
[EC] Engineering changes: AJ
[SN] Serial number: MT2031J09199
[V0] Vendor specific: PCIeGen3 x8
[RV] Reserved: checksum good, 0 byte(s) reserved
End
Capabilities: [9c] MSI-X: Enable+ Count=64 Masked-
Vector table: BAR=0 offset=00002000
PBA: BAR=0 offset=00003000
Capabilities: [c0] Vendor Specific Information: Len=18 <?>
Capabilities: [40] Power Management version 3
Flags: PMEClk- DSI- D1- D2- AuxCurrent=375mA PME(D0-,D1-,D2-,D3hot-,D3cold+)
Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME-
Capabilities: [100 v1] Advanced Error Reporting
UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol-
UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol-
UESvrt: DLP+ SDES- TLP- FCP+ CmpltTO- CmpltAbrt- UnxCmplt- RxOF+ MalfTLP+ ECRC+ UnsupReq- ACSViol-
CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr-
CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr+
AERCap: First Error Pointer: 04, ECRCGenCap+ ECRCGenEn+ ECRCChkCap+ ECRCChkEn+
MultHdrRecCap- MultHdrRecEn- TLPPfxPres- HdrLogCap-
HeaderLog: 00000000 00000000 00000000 00000000
Capabilities: [150 v1] Alternative Routing-ID Interpretation (ARI)
ARICap: MFVC- ACS-, Next Function: 1
ARICtl: MFVC- ACS-, Function Group: 0
Capabilities: [180 v1] Single Root I/O Virtualization (SR-IOV)
IOVCap: Migration-, Interrupt Message Number: 000
IOVCtl: Enable- Migration- Interrupt- MSE- ARIHierarchy+
IOVSta: Migration-
Initial VFs: 8, Total VFs: 8, Number of VFs: 0, Function Dependency Link: 00
VF offset: 2, stride: 1, Device ID: 1016
Supported Page Size: 000007ff, System Page Size: 00000001
Region 0: Memory at 000003249e800000 (64-bit, prefetchable)
VF Migration: offset: 00000000, BIR: 0
Capabilities: [1c0 v1] Secondary PCI Express <?>
Capabilities: [230 v1] Access Control Services
ACSCap: SrcValid- TransBlk- ReqRedir- CmpltRedir- UpstreamFwd- EgressCtrl- DirectTrans-
ACSCtl: SrcValid- TransBlk- ReqRedir- CmpltRedir- UpstreamFwd- EgressCtrl- DirectTrans-
Kernel driver in use: mlx5_core
Kernel modules: mlx5_core
|
如果有多個高速設備爭奪帶寬(例如將高速網絡連接到高速存儲),那麼 PCIe 也可能成爲瓶頸,因此可能需要從物理上將 PCIe 設備劃分給不同 CPU,以獲得最高吞吐率。

數據來源: https://en.wikipedia.org/wiki/PCI_Express#History_and_revisions
Intel 認爲,有時候 PCIe 電源管理(ASPM)可能導致延遲提高,因進而導致丟包率增高。因此也可以爲內核命令行參數添加pcie_aspm=off將其禁用。
Default 路由持久化
通過 ip route 可以添加默認路由,但是reboot就丟失了
|
1
|
route add default dev bond0
|
如果要持久化,在centos下可以創建 /etc/sysconfig/network-scripts/route-bond0 文件,內容如下
|
1
2
3
4
5
6
7
8
|
default dev bond0 ---默認路由,後面的可以省略
10.0.0.0/8 via 11.158.239.247 dev bond0
11.0.0.0/8 via 11.158.239.247 dev bond0
30.0.0.0/8 via 11.158.239.247 dev bond0
172.16.0.0/12 via 11.158.239.247 dev bond0
192.168.0.0/16 via 11.158.239.247 dev bond0
100.64.0.0/10 via 11.158.239.247 dev bond0
33.0.0.0/8 via 11.158.239.247 dev bond0
|
或者用sed在文件第一行添加
|
1
2
|
sed -i '/default /d' /etc/sysconfig/network-scripts/route-bond0 //先刪除默認路由(如果有)
sed -i '1 i\default dev bond0' /etc/sysconfig/network-scripts/route-bond0 //添加
|
Centos 7的話需要在 /etc/sysconfig/network 中添加創建默認路由的命令
|
1
2
3
|
# cat /etc/sysconfig/network
# Created by anaconda
ip route add default dev eth0
|
內核態啓動並加載網卡的邏輯
-
運行Linux的機器在BIOS階段之後,機器的boot loader根據我們預先定義好的配置文件,將intrd和linux kernel加載到內存。這個包含initrd和linux kernel的配置文件通常在/boot分區(從grub.conf中讀取參數)
-
內核啓動,運行當前根目錄下面的init進程,init進程再運行其他必要的進程,其中跟網卡PCI設備相關的一個進程,就是udevd進程,udevd負責根據內核pci scan的pci設備,從initrd這個臨時的根文件系統中加載內核模塊,對於網卡來說,就是網卡驅動。(對應systemd-udevd 服務)
-
udevd,根據內核pci device scan出來的pci device,通過netlink消息機制通知udevd加載相應的內核驅動,其中,網卡驅動就是在這個階段加載,如果initrd臨時文件系統裏面有這個網卡的驅動文件。通常upstream到linux內核的驅動,比如ixgbe,或者和內核一起編譯的網卡驅動,會默認包含在initrd文件系統中。這些跟內核一起ship的網卡驅動會在這個階段加載
-
udevd除了負責網卡驅動加載之外,還要負責爲網卡命名。udevd在爲網卡命名的時候,會首先check “/etc/udev/rules.d/“下的rule,如果hit到相應的rule,就會通過rule裏面指定的binary爲網卡命名。如果/etc/udev/rules.d/沒有命名成功網卡,那麼udevd會使用/usr/lib/udev/rule.d下面的rule,爲網卡重命名。其中rule的文件經常以數字開頭,數字越小,表示改rule的優先級越高。intrd init不會初始化network服務,所以/etc/sysconfig/network-scripts下面的諸如bond0,route的配置都不會生效。(內核啓動先是 intrd init,然後執行一次真正的init)
-
在完成網卡driver load和name命名之後,initrd裏面的init進程,會重啓其他用戶態進程,如udevd等,並且重新mount真正的根文件系統,啓動network service。
-
重啓udevd,會觸發一次kernel的rescan device。這樣第三方安裝的網卡driver,由於其driver模塊沒有在initrd裏面,會在這個階段由udevd觸發加載。同時,也會根據“/etc/udev/rules.d/”和“/usr/lib/udev/rule.d”的rule,重命名網卡設備。–用戶態修改網卡名字的機會
12kernel: ixgbe 0000:3b:00.1 eth1: renamed from enp59s0f1kernel: i40e 0000:88:00.0 eth7: renamed from enp136s0 -
同時network service 會啓動,進而遍歷etc/sysconfig/network-scripts下面的腳本,我們配置的bond0, 默認路由,通常會在這個階段運行,創建
12345678910kernel: bond0: Enslaving eth0 as a backup interface with a down linkkernel: ixgbe 0000:3b:00.0 eth0: detected SFP+: 5kernel: power_meter ACPI000D:00: Found ACPI power meter.kernel: power_meter ACPI000D:00: Ignoring unsafe software power cap!kernel: ixgbe 0000:3b:00.1: registered PHC device on eth1kernel: ixgbe 0000:3b:00.0 eth0: NIC Link is Up 10 Gbps, Flow Control: RX/TXkernel: bond0: Enslaving eth1 as a backup interface with a down linkkernel: bond0: Warning: No 802.3ad response from the link partner for any adapters in the bondkernel: bond0: link status definitely up for interface eth0, 10000 Mbps full duplexkernel: bond0: first active interface up!
由於我們系統的初始化有兩個階段,udevd會運行兩次,所以內核態網卡driver的加載,網卡命名也有兩次機會。
第一次網卡driver的加載和命名是在initrd運行階段,這個階段由於initrd文件系統比較小,只包括和kernel一起ship的內核module,所以這個階段只能加載initrd裏面有的內核模塊。網卡的重命名也只能重命名加載了驅動的網卡。
第二個網卡driver的加載和命名,是在真正根文件系統加載後,內核再一次pci scan,這個時候,由於真的根文件系統包含了所有的driver,第一個階段無法probe的網卡會在這個階段probe,重命名也會在這個階段進行。
內核默認命名規則有一定的侷限性,往往不一定準確對應網卡接口的物理順序,而且每次啓動只根據內核發現網卡的順序進行命名,因此並不固定;所以目前一般情況下會在用戶態啓用其他的方式去更改網卡名稱,原則就是在內核命名ethx後將其在根據用戶態的規則rename爲其他的名字,這種規則往往是根據網卡的Mac地址以及其他能夠唯一代表一塊網卡的參數去命名,因此會一一對應;
內核自帶的網卡驅動在initrd中的內核模塊中。對於第三方網卡,我們通常通過rpm包的方式安裝。這種第三方安裝的rpm,通常不會在initrd裏面,只存在disk上。這樣這種內核模塊就只會在第二次udevd啓動的時候被加載。
不論第一次重命名還是第二次重命名,其都遵循一樣的邏輯,也就是先check /etc/udev/rules.d/的rule,然後check /usr/lib/udev/rule.d中的rule,其中rule的優先級etc下最高,然後是usr下面。並且,rule的文件名中的數字表示該rule在同一文件夾中的優先級,數字越低,優先級越高。
network.service 根據network-script裏面的腳本創建bond0,下發路由。這個過程和網卡重命名是同步進行,一般網卡重命名會超級快,單極端情況下重命名可能在network.service後會導致創建bond0失敗(依賴網卡名來bonding),這裏會依賴network.service retry機制來反覆嘗試確保network服務能啓動成功
要想解決網卡加載慢的問題,可以考慮把安裝後的網卡集成到initrd中。Linux系統提供的dracut可以做到這一點,我們只需要在安裝完第三方網卡驅動後,執行:
|
1
2
3
4
|
dracut --forace
查看
udevadm info -q all -a /dev/nvme0
|
就可以解決這個問題,該命令會根據最新的內存中的module,重新下刷initrd。
其實在多數第三方網卡的rpm spec或者makefile裏面通常也會加入這種強制重刷的邏輯,確保內核驅動在initrd裏面,從而加快網卡驅動的加載。
用戶態命名網卡流程
CentOS 7提供了在網絡接口中使用一致且可預期的網絡設備命名方法, 目前默認使用的是net.ifnames規則。The device name procedure in detail is as follows:
- A rule in
/usr/lib/udev/rules.d/60-net.rulesinstructs the udev helper utility, /lib/udev/rename_device, to look into all/etc/sysconfig/network-scripts/ifcfg-*suffix*files. If it finds anifcfgfile with aHWADDRentry matching the MAC address of an interface it renames the interface to the name given in theifcfgfile by theDEVICEdirective.(根據提前定義好的ifcfg-網卡名來命名網卡–依賴mac匹配,如果網卡的ifconfig文件中未加入HWADDR,則rename腳本並不會根據配置文件去重命名網卡) - A rule in
/usr/lib/udev/rules.d/71-biosdevname.rulesinstructs biosdevname to rename the interface according to its naming policy, provided that it was not renamed in a previous step, biosdevname is installed, andbiosdevname=0was not given as a kernel command on the boot command line. - A rule in
/lib/udev/rules.d/75-net-description.rulesinstructs udev to fill in the internal udev device property values ID_NET_NAME_ONBOARD, ID_NET_NAME_SLOT, ID_NET_NAME_PATH, ID_NET_NAME_MAC by examining the network interface device. Note, that some device properties might be undefined. - A rule in
/usr/lib/udev/rules.d/80-net-name-slot.rulesinstructs udev to rename the interface, provided that it was not renamed in step 1 or 2, and the kernel parameternet.ifnames=0was not given, according to the following priority: ID_NET_NAME_ONBOARD, ID_NET_NAME_SLOT, ID_NET_NAME_PATH. It falls through to the next in the list, if one is unset. If none of these are set, then the interface will not be renamed.
Steps 3 and 4 are implementing the naming schemes 1, 2, 3, and optionally 4, described in Section 11.1, “Naming Schemes Hierarchy”. Step 2 is explained in more detail in Section 11.6, “Consistent Network Device Naming Using biosdevname”.
以上重命名簡要概述就是對於CentOS系統,一般有下面幾個rule在/usr/lib/udev/rule.d來重命名網卡:
- /usr/lib/udev/rules.d/60-net.rules 文件中的規則會讓 udev 幫助工具/lib/udev/rename_device 查看所有 /etc/sysconfig/network-scripts/ifcfg-* 文件。如果發現包含 HWADDR 條目的 ifcfg 文件與某個接口的 MAC 地址匹配,它會將該接口重命名爲ifcfg 文件中由 DEVICE 指令給出的名稱。rename條件:如果網卡的ifconfig文件中未加入HWADDR,則rename腳本並不會根據配置文件去重命名網卡;
- /usr/lib/udev/rules.d/71-biosdevname.rules 中的規則讓 biosdevname 根據其命名策略重命名該接口,即在上一步中沒有重命名該接口、安裝biosdevname、且在 boot 命令行中將biosdevname=0 作爲內核命令給出。(bisodevname規則,從CentOS 7 開始默認不使用,所以該條規則在不配置的情況下失效,直接去執行3;默認在cmdline中bisodevname=0,如果需要啓用,則需要設置bisodevname=1)
- /lib/udev/rules.d/75-net-description.rules 中的規則讓 udev 通過檢查網絡接口設備,填寫內部 udev 設備屬性值 ID_NET_NAME_ONBOARD、ID_NET_NAME_SLOT、ID_NET_NAME_PATH、ID_NET_NAME_MAC。注:有些設備屬性可能處於未定義狀態。 –沒有修改網卡名,只是取到了命名需要的一些屬性值。查看:udevadm info -p /sys/class/net/enp125s0f0
- /usr/lib/udev/rules.d/80-net-name-slot.rules 中的規則讓 udev 重命名該接口,優先順序如下:ID_NET_NAME_ONBOARD、ID_NET_NAME_SLOT、ID_NET_NAME_PATH。並提供如下信息:沒有在步驟 1 或 2 中重命名該接口,同時未給出內核參數 net.ifnames=0。如果一個參數未設定,則會按列表的順序設定下一個。如果沒有設定任何參數,則不會重命名該接口 —- 目前主流CentOS流都是這個命名方式
- network service起來後會遍歷/etc/sysconfig/network-scripts下的腳本,配置bond0、默認路由、其它網卡等
其中60 rule會調用rename_device根據ifcfg-xxx腳本來命名,rule 71調用biosdevname來命名網卡。以上規則數字越小優先級越高,高優先級生效後跳過低優先級
總的來說網卡命名規則:grub啓動參數 -> /etc/udev/rules.d/的rule -> /usr/lib/udev/rule.d
參考:
The following is an excerpt from Chapter 11 of the RHEL 7 “Networking Guide”:
- Scheme 1: Names incorporating Firmware or BIOS provided index numbers for on-board devices (example: eno1), are applied if that information from the firmware or BIOS is applicable and available, else falling back to scheme 2.
- Scheme 2: Names incorporating Firmware or BIOS provided PCI Express hotplug slot index numbers (example: ens1) are applied if that information from the firmware or BIOS is applicable and available, else falling back to scheme 3.
- Scheme 3: Names incorporating physical location of the connector of the hardware (example: enp2s0), are applied if applicable, else falling directly back to scheme 5 in all other cases.
- Scheme 4: Names incorporating interface’s MAC address (example: enx78e7d1ea46da), is not used by default, but is available if the user chooses.
- Scheme 5: The traditional unpredictable kernel naming scheme, is used if all other methods fail (example: eth0).
網卡命名
默認安裝網卡所在位置來命名(enp131s0 等),按位置命名實例如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
//name example ---默認方式,按照 /usr/lib/udev/rules.d/80-net-name-slot.rules 來命名
enp4s10f1 pci 0000:04:0a.1
| | | | | | | |
| | | | domain <- 0000 | | |
| | | | | | |
en| | | --> ethernet | | |
| | | | | |
p4| | --> prefix/bus number (4) <-- 04 | |
| | | |
s10| --> slot/device number (10) <-- 10 |
| |
f1 --> function number (1) <-- 1
|
可以關掉這種按位置命名的方式,在grub參數中添加: net.ifnames=0 biosdevname=0,關閉後默認命名方式是eth**,開啓biosdevname=1後,默認網卡命名方式是p1p1/p1p2(麒麟默認開啓;alios默認關閉,然後以eth來命名)
You have two options (as described in the new RHEL 7 Networking Guide) to disable the new naming scheme:
- Run once:
ln -s /dev/null /etc/udev/rules.d/80-net-name-slot.rulesor
- Run once:
echo 'GRUB_CMDLINE_LINUX="net.ifnames=0"' >>/etc/default/grubNote that the biosdevname package is not installed by default, so unless it gets installed, you don’t need to add
biosdevname=0as a kernel argument.
也可以添加命名規則在 /etc/udev/rules.d/ 下(這種優先級挺高),比如
|
1
2
3
4
5
|
cat /etc/udev/rules.d/70-persistent-net.rules
# PCI device 21:00.0 (ixgbe)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="d4:5d:64:bb:06:32", PROGRAM="/lib/udev/rename_device", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"
# PCI device 0x8086:0x105e (e1000e)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="b8:59:9f:2d:48:2b", PROGRAM="/lib/udev/rename_device", ATTR{type}=="1", KERNEL=="eth*", NAME="eth1"
|
但是以上規則在麒麟下沒有生效
網卡重命名方式:
|
1
|
/sbin/ip link set eth1 name eth123
|
校驗
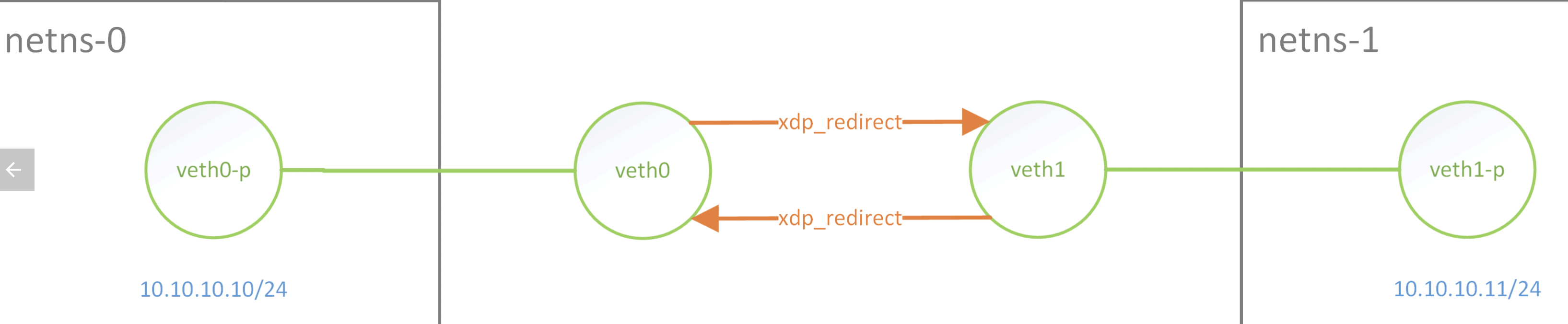
比如如下結構下因爲通過xdp redirect來聯通veth0、veth1,兩邊能ping通,但是TCP、UDP 都不通
正常走bridge ping/tcp/udp是不會有問題的, 這也是docker下常見用法
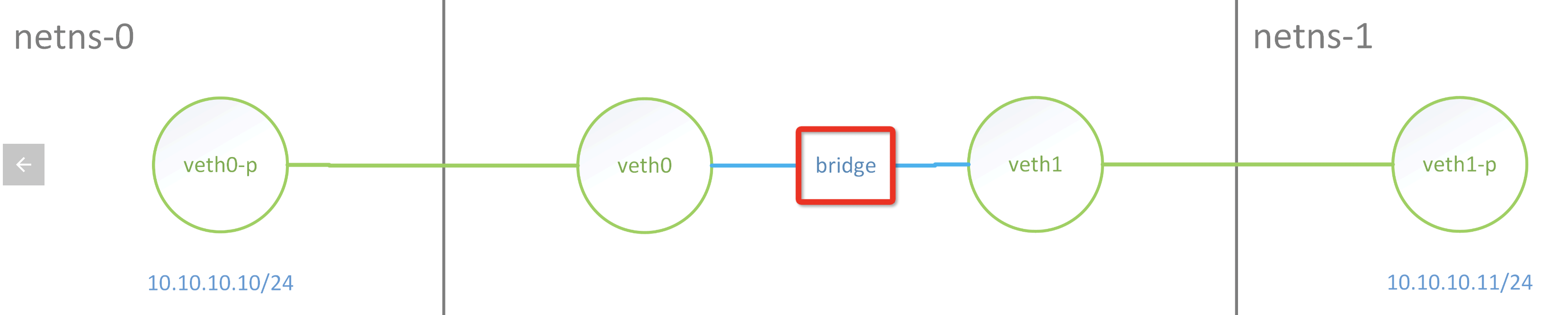
當前主流的網卡(包括虛擬網卡,如veth/tap)都支持一個叫做RX/TX Checksum Offload(RX和TX對應接收和發送兩個方向)的特性,用於將傳輸層協議的校驗和計算卸載到網卡硬件中(IP頭的檢驗和會被操作系統用軟件方式正確計算)。對於經過啓用該功能的網卡的報文,操作系統不會對該報文進行校驗和的計算,從而減少對系統CPU資源的佔用。
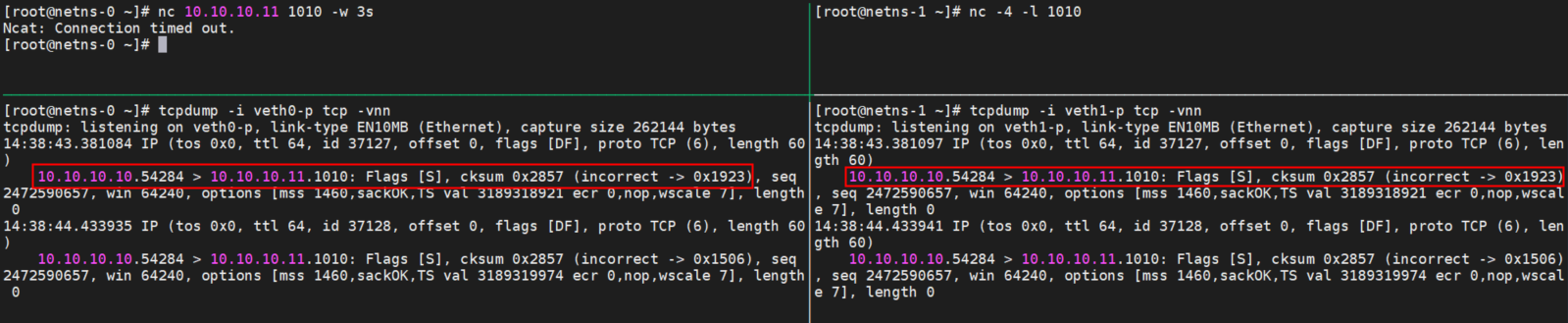
對於沒有掛載XDP程序的且開啓Checksum Offload功能的Veth設備,在接收到數據包時,會將ip_summed置爲CHECKSUM_UNNECESSARY,因此上層L4協議棧在收到該數據包的時候不會再檢查校驗和,即使是數據包的校驗和不正確也會正常被處理。但是若我們在veth設備上掛載了XDP程序,XDP程序運行時將網卡接收隊列中的數據轉換爲結構struct xdp_buff時會丟失掉ip_summed信息,這就導致數據包被L4協議棧接收後由於校驗和錯誤而被丟棄。
如上圖因爲veth掛載了XDP程序,導致包沒有校驗信息而丟掉,如果在同樣環境下ping是可以通的,因爲ping包提前計算好了正確的校驗和

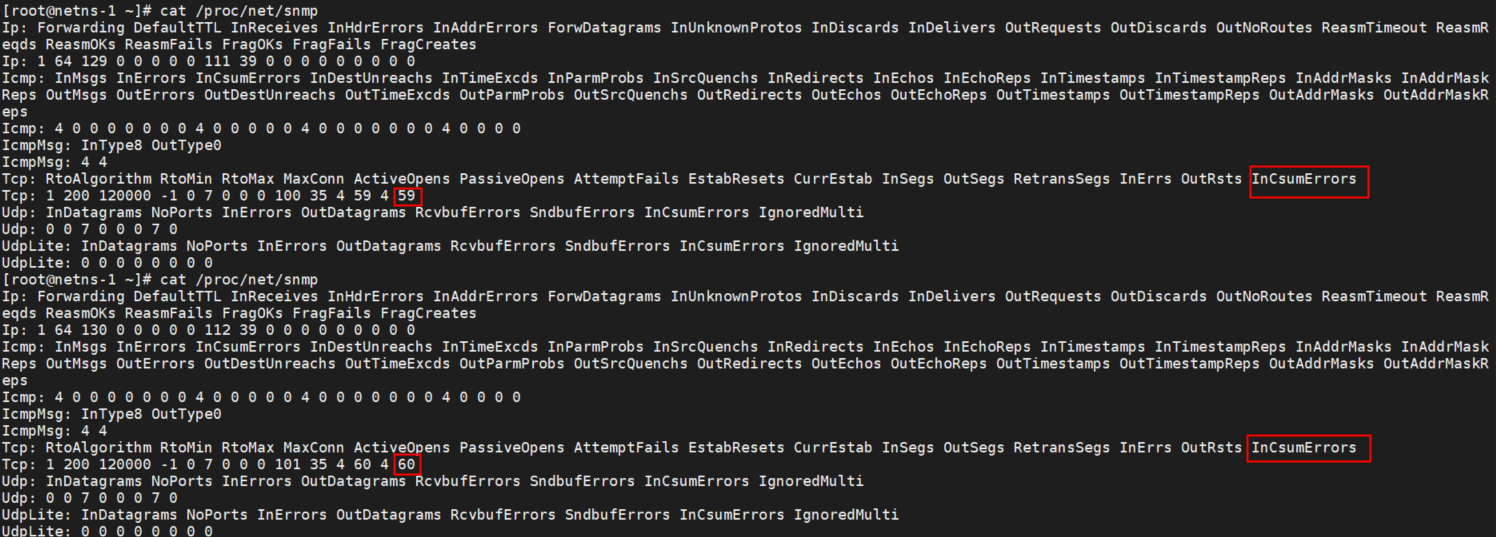
這種丟包可以通過 /proc/net/snmp 看到
通過命令ethtool -K <nic-name> tx off工具關閉Checksum Offload特性,強行讓操作系統用軟件方式計算校驗和。
日誌
|
1
2
3
4
|
sysctl -w net.ipv4.conf.all.log_martians=1 //所有網卡
sysctl -w net.ipv4.conf.p1p1.log_martians=1 //特定網卡
/proc/sys/net/ipv4/conf/eth0.9/log_martians
|
/var/log/messages中:
messages-20120101:Dec 31 09:25:45 nixcraft-router kernel: martian source 74.xx.47.yy from 10.13.106.25, on dev eth1
修改mac地址
|
1
2
3
|
sudo ip link set dev eth1 down
sudo ip link set dev eth1 address e8:61:1f:33:c5:fd
sudo ip link set dev eth1 up
|
參考資料
https://www.cyberciti.biz/faq/linux-log-suspicious-martian-packets-un-routable-source-addresses/