




- Cost function
對於線性迴歸模型,我們定義的代價函數是所有模型誤差的平方和。理論上來說,我們也可以對邏輯迴歸模型沿用這個定義,但是問題在於,當我們將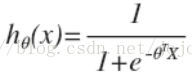

這意味着我們的代價函數有許多局部最小值,這將影響梯度下降算法尋找全局最小值。
因此,我們重新定義邏輯迴歸的代價函數爲:

其中
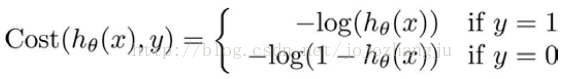


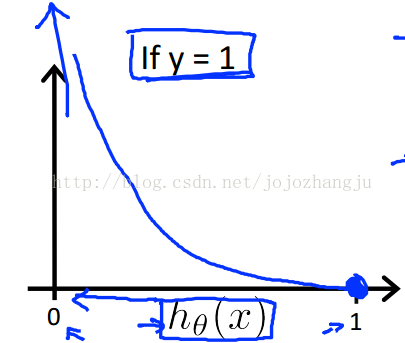
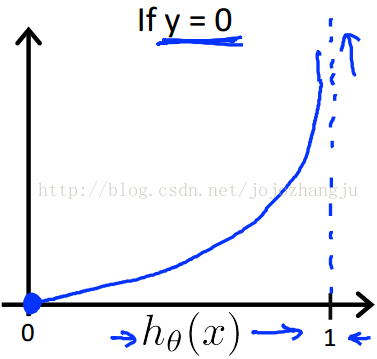
這樣構建的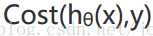
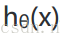

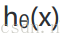
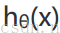
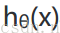
將構建的代價函數簡化如下:

帶入代價函數得到:
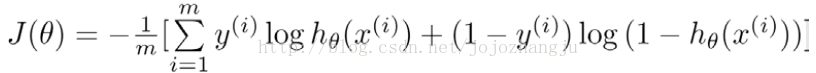
在得到這樣一個代價函數以後,我們便可以用梯度下降算法來求得能使代價函數最小的參數了。
算法爲:
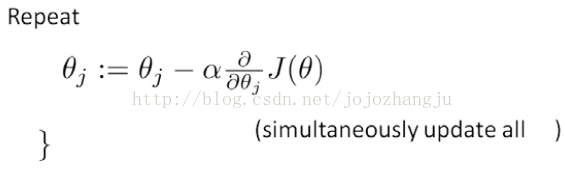
求導後得到:

注:雖然得到的梯度下降算法表面上看上去與線性迴歸的梯度下降算法一樣,但是這裏的假設函數與線性迴歸中不同,所以實際上是不一樣的。另外,在運用梯度下降算法之前,進行特徵縮放依舊是非常必要的。
另外,還有一些梯度下降算法之外的選擇:
除了梯度下降算法以外還有一些常被用來令代價函數最小的算法,這樣算法更加複雜和優越,而且通常不需要人工選擇學習率,通常比梯度下降算法更加快速。這些算法有:共軛梯度(Conjugate Gradient),局部優化法(Broyden fletcher goldfarb shann, BFGS)和有限內存局部優化法(LBFGS)
fminunc是matlab和octave中都帶的一個最小值優化函數,使用時我們需要提供代價函數和每個參數的求導,下面是octave中使用fminunc函數的代碼實例:
