




KNN分類算法原理及實現,sklearn中的使用方法
簡介
右下圖中,綠色圓要被決定賦予哪個類,是紅色三角形還是藍色四方形?如果K=3,由於紅色三角形所佔比例爲2/3,綠色圓將被賦予紅色三角形那個類,如果K=5,由於藍色四方形比例爲3/5,因此綠色圓被賦予藍色四方形類。
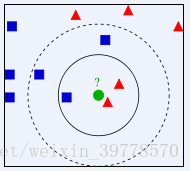
K最近鄰(k-Nearest Neighbor,KNN)分類算法,是一個理論上比較成熟的方法,也是最簡單的機器學習算法之一。該方法的思路是:如果一個樣本在特徵空間中的k個最相似(即特徵空間中最鄰近)的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別。
實現及使用方法
下面的KNNClassifier是模仿sklearn中的api實現的一個簡單類
- init構造器傳入的是一個k值,即要統一分析的最近的k個點
- fit函數需要在對象創建後使用,傳入訓練數據集,X_train,y_train
- predict方法傳入的是一個測試數據集,返回的是一個測試結果集(這裏統一返回np.array)
- (在sklearn該方法在metrics模塊中所以設置爲私有方法)_accuracy_score是用來計算準確率的,傳入的連個參數分別爲 真實結果集 和 測試結果集
- score方法用來計算該模型的準確率,傳入的是 測試數據集 和 測試數據的真是結果集,返回該模型的準確度
import numpy as np
from math import sqrt
from collections import Counter
# k近鄰算法可以認爲是一個沒有訓練過程的算法
# 對於knn來說,訓練集就是模型
# 參數k,X_train訓練集, y_train分類標籤集, x新的點
class KNNClassifier:
def __init__(self, k):
"""初始化kNN分類器"""
assert k>=1, "k must be valid"
self.k = k
# 私有成員變量_
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train):
"""根據訓練數據集X_train和y_train訓練kNN分類器"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train."
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k."
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict):
"""給定待測預測數據集X_predict,返回表示X_predict的結果向量集"""
assert self._X_train is not None and self._y_train is not None, \
"must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1], \
"the feature number of X_predict must be similar to X_train."
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""給定單個待測數據x,返回x的預測結果集"""
assert x.shape[0] == self._X_train.shape[1], \
"the feature number of x must be equal to X_train"
# 歐拉距離
distances = [sqrt(np.sum((x_train-x)**2))
for x_train in self._X_train]
# 求出距離最小的索引
nearest = np.argsort(distances)
# 前k個距離最小的標籤的點集
topK_y = [self._y_train[i] for i in nearest[:self.k]]
# 投票統計
votes = Counter(topK_y)
# 返回票數最多的標籤
return votes.most_common(1)[0][0]
def _accuracy_score(self, y_true, y_predict):
"""計算 y_true 和 y_predict 之間的準確率"""
assert y_true.shape[0] == y_predict.shape[0], \
"the size of y_true must be equal to the size of y_predict"
return sum(y_true == y_predict) / len(y_true)
def score(self, X_test, y_test):
"""根據測算數據集 X_test 和 y_test 確定當前模型的準確度"""
y_predict = self.predict(X_test)
return self._accuracy_score(y_test, y_predict)
def __repr__(self):
return "KNN(k=%d)" % self.kmodel_selection模塊下面train_test_split方法
- 該方法的功能是實現把數據分爲訓練數據集和測試數據集兩部分
- 該方法傳入一個特徵集X和一個分類集y,test_ratio是測試數據集所佔比例,seed是隨機種子,默認爲空
import numpy as np
def train_test_split(X, y, test_ratio=0.2, seed=None):
"""將數據 X 和 y 按照test_ration分割成X_train, X_test, y_train, y_test"""
assert X.shape[0] == y.shape[0], \
"the size of X must be equal to the size of y"
assert 0.0 <= test_ratio <= 1.0, \
"test_ration must be valid"
if seed:
np.random.seed(seed)
# 隨機打亂X
shuffled_indexes = np.random.permutation(len(X))
# 根據test_ration對打亂的索引進行切分
test_size = int(len(X) * test_ratio)
test_indexes = shuffled_indexes[:test_size]
train_indexes = shuffled_indexes[test_size:]
# funcyIndexing挑選數據
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
return X_train, X_test, y_train, y_test簡單使用一下自己實現的類,對鳶尾花數據集進行預測分類
- 使用環境:Anaconda3,Jupyter
導入庫
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn import datasets使用鳶尾花數據集
iris = datasets.load_iris()
iris.keys()
# 結果:data是數據特徵集,target是分類集
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names'])
iris.data.shape
(150, 4)
# 使用兩個特徵
X = iris.data[:, :2]
X.shape
(150, 2)
y = iris.target
# 繪製散點圖
plt.scatter(X[y==0, 0], X[y==0, 1], color="red", marker='o')
plt.scatter(X[y==1, 0], X[y==1, 1], color="blue", marker='x')
plt.scatter(X[y==2, 0], X[y==2, 1], color="green", marker='+')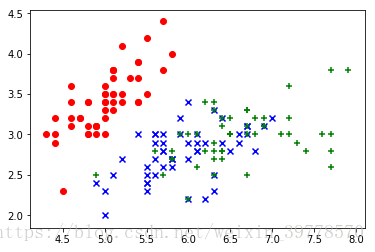
可以看到該數據集具有明顯的按照特徵集羣分佈的特點,故可以使用KNN算法
#使用自己實現的模塊
%run D:\機械學習\MySkl\model_selection.py
# 分類
X_train, X_test, y_train, y_test = train_test_split(x,y)
# 打印結果
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
(120, 4)
(120,)
(30, 4)
(30,)
%run D:\機械學習\MySki\KNN_classify.py
# 使用k值爲3,用最近的3個點進行分析
knn_clf = KNNClassifier(k=3)
KNN(k=3)
# 傳入訓練數據
my_knn_clf.fit(X_train, y_train)
# 進行預測
y_predict = my_knn_clf.predict(X_test)
y_predict
# 預測結果:
array([0, 0, 0, 2, 2, 2, 1, 1, 0, 1, 0, 0, 2, 1, 2, 1, 2, 0, 2, 1, 0, 0,
0, 0, 1, 1, 0, 1, 0, 2])
# 真實結果
y_test
array([0, 0, 0, 2, 2, 2, 1, 1, 0, 1, 0, 0, 2, 1, 2, 1, 2, 0, 2, 1, 0, 0,
0, 0, 1, 1, 0, 1, 0, 2])
# 這次的結果正確率爲100%(每次預測的結果可能不一樣,受到隨機分類的隨機種子的影響)
sum(y_predict == y_test)/len(y_test)
1.0
# 數據一樣,結果一樣
my_knn_clf.score(X_test, y_test)
1.0使用scikit-learn,對手寫數字進行預測分類
- 自己實現的類只是用來更好的理解sklearn,真實使用的畫一般還是使用sklearn封裝的api
# 導入相應的庫
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn import datasets# 加載手寫數字的數據集
digits = datasets.load_digits()
# 查看內容
digits.keys()
dict_keys(['data', 'target', 'target_names', 'images', 'DESCR'])
# 顯示部分結果,這是一個8*8的圖片
print(digits['DESCR'])
Notes
-----
Data Set Characteristics:
:Number of Instances: 5620
:Number of Attributes: 64
:Attribute Information: 8x8 image of integer pixels in the range 0..16.
:Missing Attribute Values: None
:Creator: E. Alpaydin (alpaydin '@' boun.edu.tr)
:Date: July; 1998
# 該數據集有部分數據
# 特徵集
x = digits.data
x.shape
(1797, 64)
# 特徵集對應分類集
y = digits.target
y.shape
(1797,)
# 分類標籤
digits.target_names
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 查看顯示第666個數據,爲0
some_digit = x[666]
y[666]
0
# 繪製該數字
some_digit_image = some_digit.reshape(8,8)
plt.imshow(some_digit_image, cmap = matplotlib.cm.binary)
plt.show()
# 導入分類模塊
from sklearn.model_selection import train_test_split
# 進行訓練數據和測試數據的分類,隨機種子爲666可以復現結果
X_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=666)
# 導入knn的模塊KNeighborsClassifier模塊
from sklearn.neighbors import KNeighborsClassifier
# n_neighbors參數即k值
knn_clf = KNeighborsClassifier(n_neighbors=3)
# 模型擬合,傳入訓練數據
knn_clf.fit(X_train, y_train)
# 返回結果
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=3, p=2,
weights='uniform')
# 對測試數據進行預測,返回預測結果集
y_predict = knn_clf.predict(x_test)
# 導入計算正確率的模塊
from sklearn.metrics import accuracy_score
# 傳入真實結果和測試結果,返回正確率
accuracy_score(y_test, y_predict)
0.9888888888888889
# 直接傳入測試數據進行模型評估
knn_clf.score(x_test, y_test)
0.9888888888888889
# 沒有使用隨機種子的完整代碼,算正確率
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
x = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
knn_clf.score(X_test, y_test)
# 正確率
0.9916666666666667機器學習庫使用過程中要注意的一些地方
超參數和模型參數
- 超參數: 在算法運行前需要決定的參數
- 模型參數:算法中學習的參數
- kNN算法沒有模型參數
- kNN算法中的k是典型的超參數
簡單使用循環尋找最好的k值
import numpy as np
from sklearn import datasets
digits = datasets.load_digits()
x = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
from sklearn.neighbors import KNeighborsClassifier
# 使用循環尋找最好的k值
best_score = 0.0
best_k = -1
for k in range(1,11):
knn_clf = KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
print("best_k = ", best_k)
print("best_score = ", best_score)
best_k = 5
best_score = 0.9944444444444445考慮距離? 不考慮距離?
我們默認使用的是歐拉距離
當一個點跟其他分類之間出現平票的時候,如果不考慮距離的話是會進行隨機分類的
考慮距離的話則會選擇與點之間的距離最小的那一個分類
距離計算:取每個特徵距離的大小的倒數和 sum( 1/n )
# weights參數默認值'uniform'不考慮距離,'distance'爲考慮距離
best_method = ""
best_score = 0.0
best_k = -1
for method in ['uniform', 'distance']:
for k in range(1,11):
knn_clf = KNeighborsClassifier(n_neighbors=k, weights=method)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
best_method = method
print("best_k = ", best_k)
print("best_score = ", best_score)
print("best_method = ", best_method)
best_k = 5
best_score = 0.9944444444444445
best_method = uniform使用哪種距離?
- 歐拉距離 : 兩點距離
- 曼哈頓距離 :維度距離
- 明可夫斯基距離 p=1是曼哈頓,p=2是歐拉距離, ++p…
- 默認使用明科夫斯基距離,p=2

# 尋找最好的距離參數p
%%time
best_p = -1
best_score = 0.0
best_k = -1
for k in range(1,11):
for p in range (1,6):
knn_clf = KNeighborsClassifier(n_neighbors=k,weights='distance', p=p,metric='minkowski')
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
best_p= p
print("best_k = ", best_k)
print("best_score = ", best_score)
print("best_p = ", best_p)
best_k = 3
best_score = 0.9972222222222222
best_p = 5
Wall time: 22.3 s網格搜索
- 網格搜索與k近鄰算法中更多超參數
# 該參數是一個列表,裏面的字典,是要搜索的內容,weights爲 'uniform'時不使用距離p參數
param_grid = [
{
'weights' : ['uniform'],
'n_neighbors':[i for i in range(1, 11)]
},
{
'weights':['distance'],
'n_neighbors' : [i for i in range(1,11)],
'p' : [i for i in range(1, 6)]
}
]
knn_clf = KNeighborsClassifier()
# 導入網格包搜索的模塊GridSearchCV
from sklearn.model_selection import GridSearchCV
# 傳入訓練模型,參數集
grid_search = GridSearchCV(knn_clf, param_grid)
# 執行搜索
%%time
grid_search.fit(X_train, y_train)
# 搜索時間比較長
Wall time: 3min 2s
Out[18]:
GridSearchCV(cv=None, error_score='raise',
estimator=KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform'),
fit_params=None, iid=True, n_jobs=1,
param_grid=[{'weights': ['uniform'], 'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]}, {'weights': ['distance'], 'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 'p': [1, 2, 3, 4, 5]}],
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=0)
# 結果集
# 最優參數
grid_search.best_estimator_
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='distance')
# 最優成績
grid_search.best_score_
0.988169798190675
# 最優搜索參數
grid_search.best_params_
{'n_neighbors': 5, 'p': 2, 'weights': 'distance'}
# 獲得最好的評估器
knn_clf = grid_search.best_estimator_
# 對測試數據進行預測的成績
knn_clf.score(X_test, y_test)
0.9944444444444445- 併發搜索
%%time
# n_jobs爲使用核數,-1使用所有核,verbose邊搜索邊輸出,使用一個整數,數越大輸出越詳細
grid_search = GridSearchCV(knn_clf, param_grid, n_jobs=-1, verbose=3)
grid_search.fit(X_train, y_train)
# 這次搜索使用了1.2分鐘,大大縮短了時間
Fitting 3 folds for each of 60 candidates, totalling 180 fits
[Parallel(n_jobs=-1)]: Done 24 tasks | elapsed: 2.5s
[Parallel(n_jobs=-1)]: Done 120 tasks | elapsed: 39.9s
Wall time: 1min 13s
[Parallel(n_jobs=-1)]: Done 180 out of 180 | elapsed: 1.2min finished數據歸一化
將所有的數據映射到同一尺寸
- 最值歸一化 normalization
- 把所有數據映射到0-1之間 Xscale = (X - Xmin)/ (Xmax - Xmin)
適用於分佈有明顯邊界的情況,受outlier影響較大
比如有大部分數據都比較小,然後出現了一個特別大的數據,那麼Xmax就很大,對Xscale影響很大,導致預測準確率下降均值方差歸一化standardization
- 數據分佈沒有明顯的邊界,有可能存在極端數據值
- 均值方差歸一化:把所有數據歸一到均值爲0方差爲1的分佈中
- Xscale = (X - Xmean) / std
- 一般使用均值方差歸一化
實現StandarScalar類,用於理解原理
- 功能:將數據歸一化
- fit方法傳入訓練數據,作爲均值方差歸一化的指標
- transform方法傳入要轉換的數據,返回歸一化的數據
- 這裏均使用二維數組
import numpy as np
class StandardScalar:
def __init__(self):
self.mean_ = None
self.scale_ = None
def fit(self, X):
"""根據訓練數據集X獲得數據的均值和方差"""
assert X.ndim == 2, "The dimension of X must be 2"
# 根據傳入的標準數據計算 均值mean_ 和 方差scale_
self.mean_ = np.array([np.mean(X[:, i]) for i in range(X.shape[1])])
self.scale_ = np.array([np.std(X[:, i]) for i in range(X.shape[1])])
return self
def transform(self, X):
"""將X根據這個StandarScaler進行均值方差歸一化處理"""
assert X.ndim == 2, "The dimension of X must be 2"
assert self.mean_ is not None and self.scale_ is not None, \
"must fit before transform!"
assert X.shape[1] == len(self.mean_), \
"The feature number of X must be equal to mean_ and std_"
# 先構建一個空的數組
resX = np.empty(shape=X.shape, dtype=float)
# 把根據公式歸一化的數據放入數組中
for col in range(X.shape[1]):
resX[:,col] = (X[:,col] - self.mean_[col]) / self.scale_[col]
return resXscikit-learn中的StandardScaler
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target)
# 導入歸一化模塊
from sklearn.preprocessing import StandardScaler
# 使用該類
standarScaler = StandardScaler()
# 傳入訓練數據作爲標準
standarScaler.fit(X_train)
StandardScaler(copy=True, with_mean=True, with_std=True)
# 獲取每個特徵的均值
standarScaler.mean_
array([5.80178571, 3.11517857, 3.64553571, 1.15446429])
# 獲取每個特徵的方差(數據分佈範圍)
array([0.82721371, 0.43838376, 1.78829969, 0.77100218])
# 獲得歸一化的訓練數據
X_train = standarScaler.transform(X_train)
# 獲得歸一化的測試數據
X_test_standar = standarScaler.transform(X_test)
# 查看獲得的數據的均值和方差的情況
np.mean(X_train)
1.2965818894729507e-15 # 負15次方非常接近0
np.std(X_train)
1.0
# 進行預測
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
knn_clf.score(X_test_standar, y_test)
# 成績
0.9736842105263158KNN的缺點
缺點1:效率低下,每個數據都需要O(n*m)
缺點2:高度數據相關
缺點3:預測結果不具有可解釋性
缺點4: 維數災難,隨着維度的增加,“看似相近”的兩個點之間的距離越來越大,解決方法:降維
KNN的優點
1.簡單,易於理解,易於實現,無需估計參數,無需訓練;
2. 適合對稀有事件進行分類;
3.特別適合於多分類問題(multi-modal,對象具有多個類別標籤), kNN比SVM的表現要好。
機器學習算法的一般使用步驟
- 對數據進行分類爲訓練數據和測試數據
- 再使用Scaler進行數據歸一化(可能存在數據尺度不一)
- 對數據進行訓練得到模型
- 測試數據同樣需要使用歸一化
- 然後送進模型來看分類準確度:accuracy來看模型的好壞
- 使用網格搜索尋找最好的超參數