




注:本文轉自的V8 之旅:對象表示
在前一篇文章中,我們觀察了V8的簡單編譯器——Full Compiler。在我們繼續觀察Crankshaft之前,爲更好地理解它,我們首先來看看V8在內存中如何表達對象。
本文來自Jay Conrod的A tour of V8: object representation,其中的術語、代碼請以原文爲準。
概覽
簡易的圖表或許是瞭解對象表示的最爲快速直觀的方法。
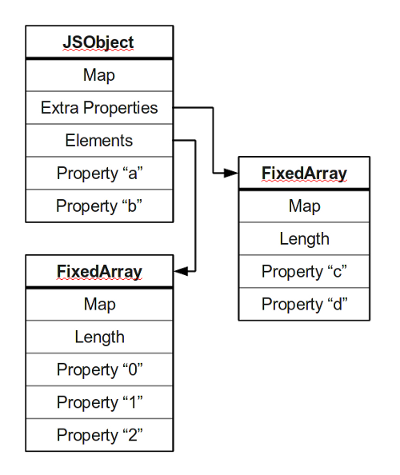
所有的對象內存區都會有一個Map指針,用以描述該對象的結構。絕大多數對象將其自身的屬性存放在一塊內存中(“a”和“b”);附加的命名屬性通常會存放在一個單獨的數組中(“c”和“d”);而數字式的屬性則單獨存放在另一個地方,通常是一個連續的數組。
這張圖僅僅表示已被優化的JS對象的通常狀態,另有一些狀態來處理其他情況。如果你對此抱有興趣,繼續讀下文吧。
屬性的怪異屬性
V8有它的難處:JavaScript標準中允許開發者以非常靈活的方式定義對象,因此很難用一種形式來高效地表示對象。一個對象基本上就是一堆屬性的集合:也就是一羣鍵值對。你可以以兩種方式來訪問對象的屬性:
obj.prop obj["prop"]
根據標準,屬性的名稱永遠是字符串。如果你用不是字符串的東西來作爲屬性的名稱,那它將會被隱式轉換爲字符串。所以一個怪異的情況就是,如果用數字作爲屬性名,則數字也會被轉換爲字符串(至少根據標準就是這樣)。因此,你可以以小數或者負數來作爲下標。
obj[1]; //
obj["1"]; // 這些都是同一個屬性哦
obj[1.0]; //
var o = {toString: function () { return "-1.5"; } };
obj[-1.5]; // 這倆也是同一個屬性
obj[o]; // 因爲o轉換成了字符串
數組在JS中也只是帶有神奇length屬性的對象。大多數數組的屬性名都是非負整數,而length的值則來計算於這些屬性名中最大的那個加一,比如:
var a = new Array(); a[100] = "foo"; a.length; // 返回101
除此之外數組和普通的對象沒什麼區別。函數也是對象,只不過它們的length屬性返回的是其定義的參數個數。
字典模式
譯註,也即哈希表模式
既然JavaScript中的對象就是鍵值對映射,爲何不直接以哈希表來表示對象呢?這種方式沒什麼問題,V8內部實際上也用了這樣的方式來表達一些難以用優化形式表達的對象(後文詳述)。但訪問哈希表中的值要比訪問指定偏移的值慢多了。
我們來看看字符串和哈希表在V8中如何工作。字符串有多種表達方式,用來表示屬性名的是最常見的ASCII碼序列——所有字符挨個排列,每個字符1字節。
0: map (字符串類型) 4: length (字符數) 8: hash code (惰性計算而來) 12: characters...
譯註:左邊是偏移量,右邊是該偏移量起始內存存放的值含義;從0開始,除最後一處外每個要素佔用4字節,最後一處則是長度爲length的字符
字符串通常不可變,唯一可能變的是惰性計算而來的哈希值。用做屬性名的字符串被稱爲符號,這意味着它必須獨有(譯註:原文uniquified,意思是這個字符串對象不會因爲在其他地方也引用了,導致其它地方可以對這個對象的內部進行修改),非獨有的字符串如果被用作屬性名,都會被單獨複製一份出來,以便不受其它修改的影響。
V8中的哈希表由一個包含鍵和值的大數組組成。初始時,所有的鍵和值都被初始化爲undefined(一個特殊值),當有鍵值對插入到哈希表中時,鍵的哈希值被計算出來,其低位被用作數組的下標。如果數組的該位置已經被佔用,則哈希表嘗試(取模過後的)下一個位置,以此類推。以下是這一過程的僞代碼:
insert(table, key, value): table = ensureCapacity(table, length(table) + 1) code = hash(key) n = capacity(table) index = code (mod n) while getKey(table, index) is not undefined: index += 1 (mod n) set(table, index, key, value) lookup(table, key): code = hash(key) n = capacity(table) index = code (mod n) k = getKey(table, index) while k is not null or undefined and k != key: index += 1 (mod n) k = getKey(table, index) if k == key: return getValue(table, index) else: return undefined
由於符號字符串是獨有的,這裏的hash code至多計算一次,計算該值和對比鍵值通常都很快。然而這一算法仍然不夠簡單,導致於每次訪問對象的屬性都會慢下來。V8會儘可能地避免這種表達方式。
快速的對象內屬性
在Lars Bak(V8的締造團隊領導者)2008年的這段視頻當中,他講述了一種可以在通常情況下更快速訪問屬性的對象表達方式。考慮如下的構造函數:
function Point(x, y) {
this.x = x;
this.y = y;
}
像這樣的構造函數是最爲多見的。絕大多數時間裏,同一構造函數所產生的對象會擁有以相同順序賦值的相同屬性。既然這些對象有着如此類似的結構,我們在內存中就可以以這樣相同的結構來佈局這些對象。
V8將這種描述對象的方式稱爲Map。你可以假想Map爲一張填滿描述符的表,每一項都表示一個屬性。Map也包含其他信息,比如對象的大小以及指向構造函數和原型的指針等,但這裏我們主要關注這些描述符。同樣結構的對象,通常會共享同一個Map。一個完成初始化的Point實例可能就像這樣:
Map M2 object size: 20 (2個屬性的空間) "x": FIELD at offset 12 "y": FIELD at offset 16
現在你可能會想到,不是所有的Point實例都有相同的屬性。當Point的實例剛剛在內存中開闢空間時(在構造函數中的代碼真正執行前),它是沒有任何屬性的,Map
M2並不符合它的結構。另外,我們也可以在構造函數完成後隨時爲它增加新的其他屬性。
V8處理通過一種特殊的描述符來處理這種情形:Transition。當增加一個新的屬性時,除非迫不得已,我們不會創建新的Map,而是儘可能使用一個現存符合結構的Map。Transition描述符就是用來指向這些Map的。
Map M0 "x": TRANSITION to M1 at offset 12 this.x = x; Map M1 "x": FIELD at offset 12 "y": TRANSITION to M2 at offset 16 this.y = y; Map M2 "x": FIELD at offset 12 "y": FIELD at offset 16
在上面的例子中新的Point實例從沒有任何Field的M0開始;在第一次賦值時,對象的Map指針指向了M1,屬性x的值存放在了偏移量12的位置;在第二次賦值時,Map指針指向了M2,屬性y的值放在了偏移量16的位置。
如果在M2的基礎上再新增屬性呢?
Map M2 "x": FIELD at offset 12 "y": FIELD at offset 16 "z": TRANSITION to M3 at offset 20 this.z = z; Map M3 "x": FIELD at offset 12 "y": FIELD at offset 16 "z": FIELD at offset 20
如果新增的屬性之前沒有,則我們會通過複製M2創建一個新的Map,M3,然後將一個新的FIELD描述符增加在M3上。同時我們要在M2上增加一個TRANSITION描述符。注意,新增TRANSITION是修改Map爲數不多的情況之一,通常Map是不可變的。
如果對象的屬性並不是以相同的順序出現呢?比如:
function Point(x, y, reverse) {
if (reverse) {
this.x = x;
this.y = y;
} else {
this.y = x;
this.x = y;
}
}
在這種情況下,我們最終會得到一個Transition樹,而不是鏈。初始的Map(上面的M0)將會有兩個Transition,具體代碼中轉向哪個,會根據x和y的賦值順序來定。正因爲這樣,不是所有的Point都會有相同的Map了。
這正是事情變糟的地方。V8對於這樣的小規模分支情形可以容忍,但如果你的代碼中充斥着以同一個構造函數得出的隨機賦值對象,V8就會將其退化到字典模式,將屬性存放在哈希表中。否則就會有大量的Map涌現。
對象內的稀疏追蹤
你可能好奇V8如何確定爲一個對象保留多少內存。很明顯,我們不希望每次增加屬性都重新開闢內存,同時也不想爲一個小對象預留大片的內存。V8使用一個叫做對象內稀疏追蹤(譯註,原文:In-object slack tracking)的辦法來確定爲構造函數的新實例分配多少內存。
一開始,構造函數所產生的對象會被分配較多的內存:足夠存放32個快速屬性的內存。一旦該構造函數實例化了足夠多次(最後一次看的時候是8次),V8就會選取其中最大的實例,通過Transition指針遍歷該構造函數對應的Map。新實例分配的內存,將直接使用遍歷得來的最大內存值。而最開始實例化出來的對象,也採用了非常精明的方式來縮減內存佔用。當對象初始化時,對象所得的內存將以接近垃圾回收器可回收內存的形式出現。由於對象的Map標明瞭它的內存佔用大小,垃圾回收器不會直接回收這片內存。直到稀疏追蹤的過程完成之後,Map中的內存大小被重新修正,相應對象的內存佔用也就小了。此時垃圾回收器會回收掉這些已經是可回收的內存,而原先的對象也無需重新挪動。
現在我估計你的下一個問題是,“如果一個對象在稀疏追蹤結束之後又增加了新的屬性呢?”。這就要依靠一個單獨的數組來存放這些附加的屬性。只要有屬性加入,這個數組隨時可以重新分配爲更大的數組。
譯註:回憶一下文章開始的那張圖吧
成員函數與原型
JavaScript沒有類,因此它的成員函數調用與C++及Java不同。JavaScript中的成員函數只是普通的屬性。在下面的例子中,distance只是Point對象的一個屬性,它指向PointDistance函數。JavaScript中的任何函數都可以作爲成員函數,並且通過this來訪問其目標對象。
譯註:在C++中,obj.method(param)實際是C代碼method(this, param)的語法糖,因此this指針實際是函數的目標對象,而不是函數的發起者。
function Point(x, y) {
this.x = x;
this.y = y;
this.distance = PointDistance;
}
function PointDistance(p) {
var dx = this.x - p.x;
var dy = this.y - p.y;
return Math.sqrt(dx*dx, dy*dy);
}
如果distance像普通的對象內屬性一樣對待,那很顯然會佔用大量的內存空間,原因是每一個Point實例都會有一個Field來存放這個共同的屬性。對於有大量成員函數的對象更是如此。我們可以對此改進。
C++解決這個問題的方法是虛表(譯註:原文v-table)。虛表是一個存放各個虛函數指針的數組。帶有虛函數的類的每個實例,都會有一個指向該類虛表的指針。當你調用虛函數時,程序會讀取虛表,並按照虛表中該虛函數的地址跳轉執行。在V8中,我們已經有了這麼一個類似的表,它就是Map。
爲了讓Map有類似虛表的功能,我們需要爲其增加一種新的描述符:Constant Function。CF類型的描述符表示該對象有一個已知名稱的屬性,該屬性不存放在對象中,而是直接尾隨描述符。
Map M0 "x": TRANSITION to M1 at offset 12 this.x = x; Map M1 "x": FIELD at offset 12 "y": TRANSITION to M2 at offset 16 this.y = y; Map M2 "x": FIELD at offset 12 "y": FIELD at offset 16 "distance": TRANSITION to M3 this.distance = PointDistance; Map M3 "x": FIELD at offset 12 "y": FIELD at offset 16 "distance": CONSTENT_FUNCTION
注意,轉換到另一個Map只會在描述符的函數與實際函數一致時纔會發生。因此如果程序員對PointDistance重新賦值爲另一個值,則該Transition不再有效,Map也會重新創建。同時注意,我們並不像虛表那樣僅僅是跳轉到虛函數,而是會生成一個包含函數地址的優化代碼,以便在下次執行時,一旦發現對象使用的Map是這個Map並要調用該函數,則直接跳轉過去。
JavaScript中還有另一種方法來提供公共屬性,那就是通過構造函數所關聯的原型對象。對於一個構造函數的實例來說,原型對象所擁有的屬性,它也可以直接使用。舉例來說:
function Point(x, y) {
this.x = x;
this.y = y;
}
Point.prototype.distance = function(p) {
var dx = this.x - p.x;
var dy = this.y - p.y;
return Math.sqrt(dx*dx, dy*dy);
}
...
var u = new Point(1, 2);
var v = new Point(3, 4);
var d = u.distance(v);
這樣的代碼隨處可見,同時也是實現繼承的一種範式,因爲原型還可以有自己的原型。instanceof操作符所針對的就是原型鏈。
和普通對象一樣,V8也會將原型的成員函數以CF描述符來表示。調用原型的函數會比直接調用對象自己的函數略慢,因爲編譯器不僅需要檢查目標對象的Map,同時也要檢查原型鏈上的其他Map。但這不會產生大的性能問題,對於開發者來說也不應影響代碼書寫。
數字式屬性:Fast Element
至此,我們已經討論了普通屬性和方法,並且假設對象總是以相同順序構造相同的屬性。但這對於數字式的屬性(以下標的形式來訪問的數組元素)並不成立,同時任何對象都有可能像數組一樣使用,因此我們需要對數組一樣的對象區別對待。記住,根據標準,所有的屬性都必須是字符串,其他類型會先轉換爲字符串。
我們將屬性名爲非負整數(0、1、2……)的屬性稱爲Element。V8中,Element的存放和其他屬性是分開的。每個對象都有一個指向Element數組的指針,對象Map中的Element Field將反映出Element是如何存儲的。注意,Map中並不包含Element的描述符,但可能包含其它有着不同Element類型的同一種Map的Transition描述符(譯註:換言之,一個Map只對應一種Element數組,如果Element數組的類型不同,會形成一個Transition。)。大多數情況下,對象都會有Fast Element,也就是說這些Element以連續數組的形式存放。有三種不同的Fast Element:
- Fast small integers
- Fast doubles
- Fast values
根據標準,JS中的所有數字都理應以64位浮點數形式出現,儘管我們平時處理的都是整數。因此V8儘可能以31位帶符號整數來表達數字(最低位總是0,這有助於垃圾回收器區分數字和指針)。因此含有Fast small integers類型的對象,其Element類型只會包含這樣的數字。如果需要存儲小數、大整數或其他特殊值,如-0,則需要將數組提升爲Fast doubles。於是這引入了潛在的昂貴的複製-轉換操作,但通常不會頻繁發生。Fast doubles仍然是很快的,因爲所有的數字都是無封箱存儲的。但如果我們要存儲的是其他類型,比如字符串或者對象,則必須將其提升爲普通的Fast Element數組。
JavaScript不提供任何確定存儲元素多少的辦法。你可能會說像這樣的辦法,new Array(100),但實際上這僅僅針對Array構造函數有用。如果你將值存在一個不存在的下標上,V8會重新開闢更大的內存,將原有元素複製到新內存。V8可以處理帶空洞的數組,也就是隻有某些下標是存有元素,而期間的下標都是空的。其內部會安插特殊的哨兵值,因此試圖訪問未賦值的下標,會得到undefined。
當然,Fast Element也有其限制。如果你在遠遠超過當前數組大小的下標賦值,V8會將數組轉換爲字典模式,將值以哈希表的形式存儲。這對於稀疏數組來說很有用,但性能上肯定打了折扣,無論是從轉換這一過程來說,還是從之後的訪問來說。如果你需要複製整個數組,不要逆向複製(索引從高到低),因爲這幾乎必然觸發字典模式。
// 這會大大降低大數組的性能
function copy(a) {
var b = new Array();
for (var i = a.length - 1; i >= 0; i--)
b[i] = a[i];
return b;
}
由於普通的屬性和數字式屬性分開存放,即使數組退化爲字典模式,也不會影響到其他屬性的訪問速度(反之亦然)。
總結
這篇文章中我們觀察了V8內部是如何表示對象及其屬性的。V8爲通用接口提供了針對具體場景可切換的數據存儲模型,這作爲VM語言的一項優勢,對於編譯型語言來說是難以企及的:那些語言要麼只能小範圍優化,要麼則依賴於程序員對對象結構的控制。
在接下來的文章中,我們要觀察V8的優化編譯器——Crankshaft,以及它是如何利用本文中的這些結構優勢來生成高效代碼的。