




HDFS簡單介紹
HDFS全稱是Hadoop Distribute File System,是一個能運行在普通商用硬件上的分佈式文件系統。
與其他分佈式文件系統顯著不同的特點是:
- HDFS是一個高容錯系統且能運行在各種低成本硬件上;
- 提供高吞吐量,適合於存儲大數據集;
- HDFS提供流式數據訪問機制。
HDFS起源於Apache Nutch,現在是Apache Hadoop項目的核心子項目。
HDFS設計假設和目標
- 硬件錯誤是常態
在數據中心,硬件異常應被視作常態而非異常態。
在一個大數據環境下,hdfs集羣有大量物理機器構成,每臺機器由很多硬件組成,整個因爲某一個組件出錯而出錯的機率是很高的,
因此HDFS架構的一個核心設計目標就是能夠快速檢測硬件失效並快速從失效中恢復工作。 - 流式訪問要求
在HDFS集羣上運行的應用要求流式訪問數據,HDFS設計爲適用於批處理而非交互式處理,因此在架構設計時更加強調高吞吐量而非低延遲。
對於POSIX的標準訪問機制比如隨機訪問會嚴重降低吞吐量,HDFS將忽略此機制。 - 大數據集
假定HDFS的典型文件大小是GB甚至TB大小的,HDFS設計重點是支持大文件,支持通過機器數量擴展以支持更大的集羣,
單個集羣應提供海量文件數量支持 - 簡單一致性模型
HDFS提供的訪問模型是一次寫入多次讀取的模型。寫入後文件保持原樣不動簡化了數據一致性模型並且對應用來說,它能得到更高的吞吐量。
文件追加也支持。 - 移動計算比移動數據代價更低
HDFS利用了計算機系統的數據本地化原理,認爲數據離CPU越近,性能更高。
HDFS提供接口讓應用感知數據的物理存儲位置。 - 異構軟硬件平臺兼容
HDFS被設計成能方便的從一個平臺遷移到另外一個平臺
HDFS適用場景
綜合上述的設計假設和後面的架構分析,HDFS特別適合於以下場景:
- 順序訪問
比如提供流媒體服務等大文件存儲場景 - 大文件全量訪問
如要求對海量數據進行全量訪問,OLAP等 -
整體預算有限
想利用分佈式計算的便利,又沒有足夠的預算購買HPC、高性能小型機等場景
在如下場景其性能不盡如人意: -
低延遲數據訪問
低延遲數據訪問意味着快速數據定位,比如10ms級別響應,系統若忙於響應此類要求,
則有悖於快速返回大量數據的假設。 - 大量小文件
大量小文件將佔用大量的文件塊會造成較大的浪費以及對元數據(namenode)是個嚴峻的挑戰 - 多用戶併發寫入
併發寫入違背數據一致性模型,數據可能不一致。 - 實時更新
HDFS支持append,實時更新會降低數據吞吐以及增加維護數據一致的代價。
HDFS架構
本文將從以下幾個方面分析HDFS架構,探討HDFS架構是如何滿足設計目標的。
HDFS總體架構
下面這張HDFS架構圖來自於hadoop官方網站.

從這上面可以看出,HDFS採取主從式C/S架構,HDFS的節點分爲兩種角色:
- NameNode
NameNode提供文件元數據,訪問日誌等屬性的存儲、操作功能。
文件的基礎信息等存放在NameNode當中,採用集中式存儲方案。 -
DataNode
DataNode提供文件內容的存儲、操作功能。
文件數據塊本身存儲在不同的DataNode當中,DataNode可以分佈在不同機架。HDFS的Client會分別訪問NameNode和DataNode以獲取文件的元信息以及內容。HDFS集羣的Client將
直接訪問NameNode和DataNode,相關數據直接從NameNode或者DataNode傳送到客戶端。
HDFS數據組織機制
HDFS的數據組織分成兩部分進行理解,首先是NameNode部分,其次是DataNode數據部分,數據的組織圖如下所示:
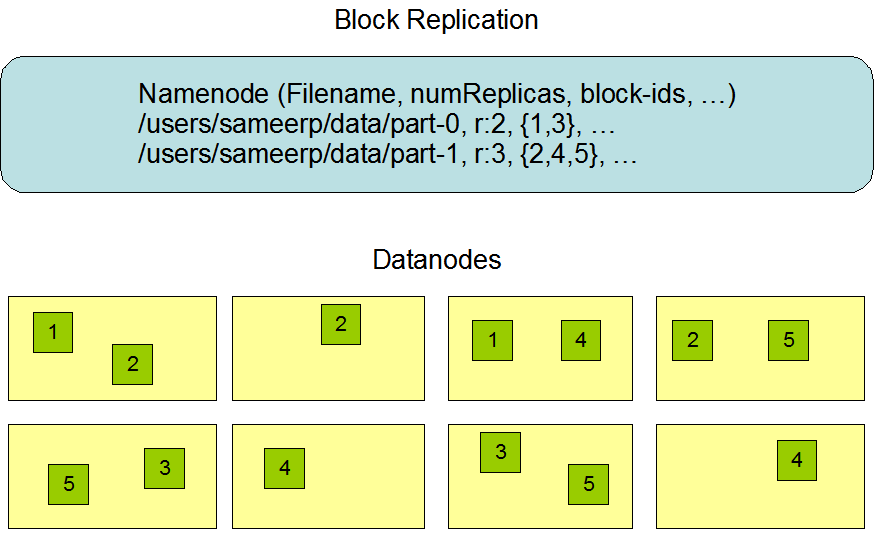
- NameNode
基於Yarn架構的HDFS中,NameNode採取主從式設計,主機主要負責客戶端訪問元數據的要求,以及存儲塊信息。
從機主要負責對主機進行實時備份,同時定期將用戶操作記錄以及文件記錄歸併到塊存儲設備,並將其回寫到主機。
當主機失效時,從機接管主機所有的工作。 主從NameNode協同工作方式如下:
- DataNode
DataNode負責存儲真正的數據。DataNode中文件以數據塊爲基礎單位,數據塊大小固定。整個集羣中,同一個數據塊
將被保存多份,分別存儲在不同的DataNode當中。其中數據塊大小,副本個數由hadoop的配置文件參數確定。數據塊大小、
副本個數在集羣啓動後可以修改,修改後的參數重啓之後生效,不影響現有的文件。
DataNode啓動之後會掃描本地文件系統中物理塊個數,並將對應的數據塊信息彙報給NameNode。
HDFS數據訪問機制
HDFS的文件訪問機制爲流式訪問機制,即通過API打開文件的某個數據塊之後,可以順序讀取或者寫入某個文件,不可以指定
讀取文件然後進行文件操作。
由於HDFS中存在多個角色,且對應應用場景主要爲一次寫入多次讀取的場景,因此其讀和寫的方式有較大不同。讀寫操作都由
客戶端發起,並且進行整個流程的控制,服務器角色(NameNode和DataNode)都是被動式響應。
下面分別對其進行 介紹:
- 讀取流程
客戶端發起讀取請求時,首先與Namenode機進行連接,連接時同樣需要hdfs配置文件,因此其知道各服務器相關信息。連接建立
完成後,客戶端請求讀取某個文件的某一個數據塊,NameNode在內存中進行檢索,查看是否有對應的文件以及文件塊,若沒有
則通知客戶端對應文件或塊不存在。若有則通知客戶端對應的數據塊存在哪些服務器之上,客戶端確定收到信息之後,與對應的數據
接連連接,並開始進行網絡傳輸。客戶端任意選擇其中一個副本數據進行讀操作。

流程分析
?使用HDFS提供的客戶端開發庫Client,向遠程的Namenode發起RPC請求;? Namenode會視情況返回文件的部分或者全部block列表,對於每個block,Namenode都會返回有該block拷貝的DataNode地址;
?客戶端開發庫Client會選取離客戶端最接近的DataNode來讀取block;如果客戶端本身就是DataNode,那麼將從本地直接獲取數據.
?讀取完當前block的數據後,關閉與當前的DataNode連接,併爲讀取下一個block尋找最佳的DataNode;
?當讀完列表的block後,且文件讀取還沒有結束,客戶端開發庫會繼續向Namenode獲取下一批的block列表。
?讀取完一個block都會進行checksum驗證,如果讀取datanode時出現錯誤,客戶端會通知Namenode,然後再從下一個擁有該block拷貝的datanode繼續讀。
- 寫入流程
客戶端發起寫入求時,NameNode在內存中進行檢索,查看是否有對應的文件以及文件塊,若有 則通知客戶端對應文件或塊已存在,
若沒有則通知客戶端某臺服務器作爲寫入主服務器。NameNode同時通知寫入主服務器就緒,客戶端與主服務器進行通信並寫入數據時,
主寫入服務器寫入數據到物理磁盤,寫入完成之後與NameNode通信獲取其下一個副本服務器地址,確認地址之後將數據傳遞給它,這樣
進行接力棒式寫入,一直到達設置副本數目爲止,等最後一個副本寫完成,則同樣將寫入成功失敗情況以接力棒方式返回給客戶端,最後
客戶端通知NameNode數據塊寫入成功,若其中某臺失敗則整個寫入失敗。

流程分析
?使用HDFS提供的客戶端開發庫Client,向遠程的Namenode發起RPC請求;
?Namenode會檢查要創建的文件是否已經存在,創建者是否有權限進行操作,成功則會爲文件 創建一個記錄,否則會讓客戶端拋出異常;
?當客戶端開始寫入文件的時候,會將文件切分成多個packets,並在內部以數據隊列"data queue"的形式管理這些packets,並向Namenode申請新的blocks,獲取用來存儲replicas的合適的datanodes列表,列表的大小根據在Namenode中對replication的設置而定。
?開始以pipeline(管道)的形式將packet寫入所有的replicas中。把packet以流的方式寫入第一個datanode,該datanode把該packet存儲之後,再將其傳遞給在此pipeline中的下一個datanode,直到最後一個datanode,這種寫數據的方式呈流水線的形式。
?最後一個datanode成功存儲之後會返回一個ack packet,在pipeline裏傳遞至客戶端,在客戶端的開發庫內部維護着"ack queue",成功收到datanode返回的ack packet後會從"ack queue"移除相應的packet。
?如果傳輸過程中,有某個datanode出現了故障,那麼當前的pipeline會被關閉,出現故障的datanode會從當前的pipeline中移除,剩餘的block會繼續剩下的datanode中繼續以pipeline的形式傳輸,同時Namenode會分配一個新的datanode,保持replicas設定的數量。
HDFS數據安全機制
HDFS文件系統的安全機制採取類linux的ACL安全訪問機制。每一個文件默認繼承其父對象即目錄的訪問權限,默認的用戶和屬組來自於
上傳客戶端的用戶。相關控制方法也與linux類似,可以通過命令或者API指定某個用戶對某個文件的讀寫權限。當用戶沒有對應的權限時,
若進行文件讀寫操作將會得到對應的錯誤提示。
HDFS高可用性機制
HDFS作爲一個高可用集羣,其可用性設計是非常用心的,主要體現在:
- NameNode主從設計
主從設計保證了元數據的可靠,解決了HDFS 1.0中單點故障的問題。具體可以參看上文描述 - 數據副本機制
數據副本機制保證了存放在某臺服務器的文件塊因爲某種原因遭到破壞的時候,整個集羣照樣可以對外提供
文件訪問服務,具體請參考上文數據訪問機制部分。 - 數據恢復機制
這兒的數據恢復指HDFS提供一定時間的反悔窗口期,默認系統中被刪除的文件被移動到trash目錄裏面,過了
一段時間之後有HDFS清理掉,此機制在雲存儲中普遍使用。若某數據塊失效,通過副本機制則可以恢復。 - 機架感知機制
大型集羣的組織是以機架形式組織的,機器以固定數量服務器以及對應的網絡設備組成一個機櫃,一般來說,跨機架的網絡IO總是比同一機架更高,當然若跨機房則代價更高。因此HDFS總是想辦法將數據保存在性能更好的服務器當中以提升性能,同時會設法將數據保存到不同機架以保證數據的容錯性。典型機架拓撲和副本如下圖所示:
在應用讀取數據時,HDFS總是選擇離應用更近的服務器。 - 快照機制
- 自動錯誤檢測恢復機制
機器失效檢測通過心跳檢測完成,若在一段時間內,DataNode或者NameNode不能返回心跳,主NameNode會將其標記爲宕機服務器,此後新的IO請求等將不會被轉發到此服務器,同時對應的文件若有相關文件因爲某臺服務器宕機導致副本數目達不到指定數目,HDFS將重新複製部分文件副本,以保證整個集羣的可靠性。 - 校驗和機制
校驗和是指對每一個數據塊產生一個校驗和,當數據被再次讀取時,客戶端對其進行計算並與服務器上的校驗和進行比較,保證了數據不會因爲網絡傳輸或者其他方式被篡改。
HDFS集羣擴展機制
集羣的動態擴展方式方便用戶以動態的方式對集羣進行擴容和縮容。若有新服務器加入,則後續的IO會有更多的機會被
發送到新服務器上執行,對集羣中現有文件的充分分佈,可以通過命令進行,但是數據重新分佈將只佔用少量網絡IO,這樣保證集羣上的應用不會因爲重分佈而受到重大影響。同樣機器下架也通過命令進行,此時集羣表現出與機器宕機類似情況,會不再往其上發IO請求以及重新複製以保證副本數量。