




python操作excel主要用到xlrd和xlwt這兩個庫,即xlrd是讀excel,xlwt是寫excel的庫。
可從這裏下載https://pypi.python.org/pypi。下面分別記錄python讀和寫excel.
python讀excel——xlrd
這個過程有幾個比較麻煩的問題,比如讀取日期、讀合併單元格內容。下面先看看基本的操作:
首先讀一個excel文件,有兩個sheet,測試用第二個sheet,sheet2內容如下:

python 對 excel基本的操作如下:
[py] view plain copy
# -*- coding: utf-8 -*-
import xlrd
import xlwt
from datetime import date,datetime
def read_excel():
# 打開文件
workbook = xlrd.open_workbook(r'F:\demo.xlsx')
# 獲取所有sheet
print workbook.sheet_names() # [u'sheet1', u'sheet2']
sheet2_name = workbook.sheet_names()[1]
# 根據sheet索引或者名稱獲取sheet內容
sheet2 = workbook.sheet_by_index(1) # sheet索引從0開始
sheet2 = workbook.sheet_by_name('sheet2')
# sheet的名稱,行數,列數
print sheet2.name,sheet2.nrows,sheet2.ncols
# 獲取整行和整列的值(數組)
rows = sheet2.row_values(3) # 獲取第四行內容
cols = sheet2.col_values(2) # 獲取第三列內容
print rows
print cols
# 獲取單元格內容
print sheet2.cell(1,0).value.encode('utf-8')
print sheet2.cell_value(1,0).encode('utf-8')
print sheet2.row(1)[0].value.encode('utf-8')
# 獲取單元格內容的數據類型
print sheet2.cell(1,0).ctype
if __name__ == '__main__':
read_excel()
運行結果如下:
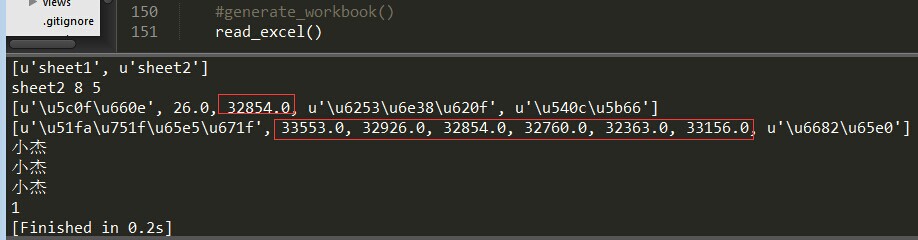
那麼問題來了,上面的運行結果中紅框框中的字段明明是出生日期,可顯示的確實浮點數。好的,來解決第一個問題:
1、python讀取excel中單元格內容爲日期的方式
python讀取excel中單元格的內容返回的有5種類型,即上面例子中的ctype:
[py] view plain copy
ctype : 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
即date的ctype=3,這時需要使用xlrd的xldate_as_tuple來處理爲date格式,先判斷表格的ctype=3時xldate才能開始操作。現在命令行看下:
[py] view plain copy
>>> sheet2.cell(2,2).ctype #1990/2/22
>>> sheet2.cell(2,1).ctype #24
>>> sheet2.cell(2,0).ctype #小胖
>>> sheet2.cell(2,4).ctype #空值(這裏是合併單元格的原因)
>>> sheet2.cell(2,2).value #1990/2/22
33656.0
>>> xlrd.xldate_as_tuple(sheet2.cell_value(2,2),workbook.datemode)
(1992, 2, 22, 0, 0, 0)
>>> date_value = xlrd.xldate_as_tuple(sheet2.cell_value(2,2),workbook.datemode)
>>> date_value
(1992, 2, 22, 0, 0, 0)
>>> date(*date_value[:3])
datetime.date(1992, 2, 22)
>>> date(*date_value[:3]).strftime('%Y/%m/%d')
'1992/02/22'
即可以做下簡單處理,判斷ctype是否等於3,如果等於3,則用時間格式處理:
[py] view plain copy
if (sheet.cell(row,col).ctype == 3):
date_value = xlrd.xldate_as_tuple(sheet.cell_value(rows,3),book.datemode)
date_tmp = date(*date_value[:3]).strftime('%Y/%m/%d')
那麼問題又來了,上面 sheet2.cell(2,4).ctype 返回的值是0,說明這個單元格的值是空值,明明是合併的單元格內容"好朋友",這個是我覺得這個包功能不完善的地方,如果是合併的單元格那麼應該合併的單元格的內容一樣,但是它只是合併的第一個單元格的有值,其它的爲空。
[py] view plain copy
>>> sheet2.col_values(4)
[u'\u5173\u7cfb', u'\u597d\u670b\u53cb', '', u'\u540c\u5b66', '', '', u'\u4e00\u4e2a\u4eba', '']
>>> for i in range(sheet2.nrows):
print sheet2.col_values(4)[i]
關係
好朋友
同學
一個人
>>> sheet2.row_values(7)
[u'\u65e0\u540d', 20.0, u'\u6682\u65e0', '', '']
>>> for i in range(sheet2.ncols):
print sheet2.row_values(7)[i]
無名
20.0
暫無
>>>
2、讀取合併單元格的內容
這個是真沒技巧,只能獲取合併單元格的第一個cell的行列索引,才能讀到值,讀錯了就是空值。
即合併行單元格讀取行的第一個索引,合併列單元格讀取列的第一個索引,如上述,讀取行合併單元格"好朋友"和讀取列合併單元格"暫無"只能如下方式:
[py] view plain copy
>>> print sheet2.col_values(4)[1]
好朋友
>>> print sheet2.row_values(7)[2]
暫無
>>> sheet2.merged_cells # 明明有合併的單元格,爲何這裏是空
[]
疑問又來了,合併單元格可能出現空值,但是表格本身的普通單元格也可能是空值,要怎麼獲取單元格所謂的"第一個行或列的索引"呢?
這就要先知道哪些是單元格是被合併的!
3、獲取合併的單元格
讀取文件的時候需要將formatting_info參數設置爲True,默認是False,所以上面獲取合併的單元格數組爲空,
[py] view plain copy
>>> workbook = xlrd.open_workbook(r'F:\demo.xlsx',formatting_info=True)
>>> sheet2 = workbook.sheet_by_name('sheet2')
>>> sheet2.merged_cells
[(7, 8, 2, 5), (1, 3, 4, 5), (3, 6, 4, 5)]
merged_cells返回的這四個參數的含義是:(row,row_range,col,col_range),
其中[row,row_range)包括row,不包括row_range,
col也是一樣,
即(1, 3, 4, 5)的含義是:第1到2行(不包括3)合併,(7, 8, 2, 5)的含義是:第2到4列合併。
利用這個,可以分別獲取合併的三個單元格的內容:
[py] view plain copy
>>> print sheet2.cell_value(1,4) #(1, 3, 4, 5)
好朋友
>>> print sheet2.cell_value(3,4) #(3, 6, 4, 5)
同學
>>> print sheet2.cell_value(7,2) #(7, 8, 2, 5)
暫無
發現規律了沒?是的,獲取merge_cells返回的row和col低位的索引即可! 於是可以這樣一勞永逸:
[py] view plain copy
>>> merge = []
>>> for (rlow,rhigh,clow,chigh) in sheet2.merged_cells:
merge.append([rlow,clow])
>>> merge
[[7, 2], [1, 4], [3, 4]]
>>> for index in merge:
print sheet2.cell_value(index[0],index[1])
暫無
好朋友
同學
>>>
python寫excel——xlwt
寫excel的難點可能不在構造一個workbook的本身,而是填充的數據,不過這不在範圍內。在寫excel的操作中也有棘手的問題,比如寫入合併的單元格就是比較麻煩的,另外寫入還有不同的樣式。這些要看源碼才能研究的透。
我"構思"瞭如下面的sheet1,即要用xlwt實現的東西:
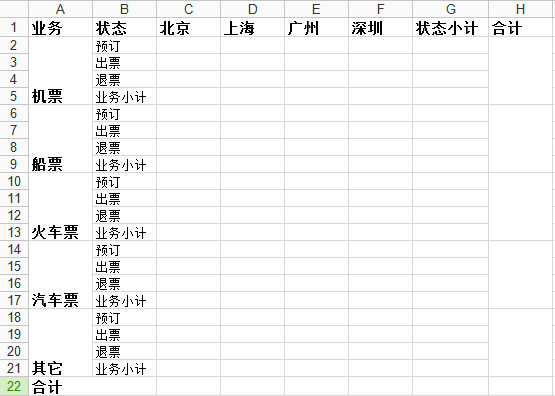
基本上看起來還算複雜,而且看起來"很正規",完全是個人杜撰。
代碼如下:
[py] view plain copy
'''''
設置單元格樣式
'''
def set_style(name,height,bold=False):
style = xlwt.XFStyle() # 初始化樣式
font = xlwt.Font() # 爲樣式創建字體
font.name = name # 'Times New Roman'
font.bold = bold
font.color_index = 4
font.height = height
# borders= xlwt.Borders()
# borders.left= 6
# borders.right= 6
# borders.top= 6
# borders.bottom= 6
style.font = font
# style.borders = borders
return style
#寫excel
def write_excel():
f = xlwt.Workbook() #創建工作簿
'''''
創建第一個sheet:
sheet1
'''
sheet1 = f.add_sheet(u'sheet1',cell_overwrite_ok=True) #創建sheet
row0 = [u'業務',u'狀態',u'北京',u'上海',u'廣州',u'深圳',u'狀態小計',u'合計']
column0 = [u'機票',u'船票',u'火車票',u'汽車票',u'其它']
status = [u'預訂',u'出票',u'退票',u'業務小計']
#生成第一行
for i in range(0,len(row0)):
sheet1.write(0,i,row0[i],set_style('Times New Roman',220,True))
#生成第一列和最後一列(合併4行)
i, j = 1, 0
while i < 4*len(column0) and j < len(column0):
sheet1.write_merge(i,i+3,0,0,column0[j],set_style('Arial',220,True)) #第一列
sheet1.write_merge(i,i+3,7,7) #最後一列"合計"
i += 4
j += 1
sheet1.write_merge(21,21,0,1,u'合計',set_style('Times New Roman',220,True))
#生成第二列
i = 0
while i < 4*len(column0):
for j in range(0,len(status)):
sheet1.write(j+i+1,1,status[j])
i += 4
f.save('demo1.xlsx') #保存文件
if __name__ == '__main__':
#generate_workbook()
#read_excel()
write_excel()
需要稍作解釋的就是write_merge方法:
write_merge(x, x + m, y, w + n, string, sytle)
x表示行,y表示列,m表示跨行個數,n表示跨列個數,string表示要寫入的單元格內容,style表示單元格樣式。其中,x,y,w,h,都是以0開始計算的。
這個和xlrd中的讀合併單元格的不太一樣。
如上述:sheet1.write_merge(21,21,0,1,u'合計',set_style('Times New Roman',220,True))
即在22行合併第1,2列,合併後的單元格內容爲"合計",並設置了style。
如果需要創建多個sheet,則只要f.add_sheet即可。
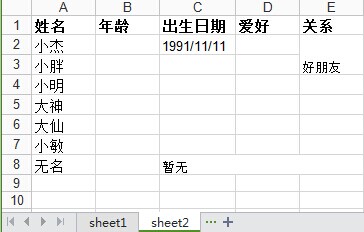
如在上述write_excel函數裏f.save('demo1.xlsx') 這句之前再創建一個sheet2,效果如下:
代碼也是真真的easy的了:
[py] view plain copy
'''''
創建第二個sheet:
sheet2
'''
sheet2 = f.add_sheet(u'sheet2',cell_overwrite_ok=True) #創建sheet2
row0 = [u'姓名',u'年齡',u'出生日期',u'愛好',u'關係']
column0 = [u'小杰',u'小胖',u'小明',u'大神',u'大仙',u'小敏',u'無名']
#生成第一行
for i in range(0,len(row0)):
sheet2.write(0,i,row0[i],set_style('Times New Roman',220,True))
#生成第一列
for i in range(0,len(column0)):
sheet2.write(i+1,0,column0[i],set_style('Times New Roman',220))
sheet2.write(1,2,'1991/11/11')
sheet2.write_merge(7,7,2,4,u'暫無') #合併列單元格
sheet2.write_merge(1,2,4,4,u'好朋友') #合併行單元格
f.save('demo1.xlsx') #保存文件
一、安裝xlrd模塊
到python官網下載http://pypi.python.org/pypi/xlrd模塊安裝,前提是已經安裝了python 環境。
二、使用介紹
1、導入模塊
複製代碼代碼如下:
import xlrd
2、打開Excel文件讀取數據
複製代碼代碼如下:
data = xlrd.open_workbook('excelFile.xls')
3、使用技巧
獲取一個工作表
複製代碼代碼如下:
table = data.sheets()[0] #通過索引順序獲取
table = data.sheet_by_index(0) #通過索引順序獲取
table = data.sheet_by_name(u'Sheet1')#通過名稱獲取
獲取整行和整列的值(數組)
複製代碼代碼如下:
table.row_values(i)
table.col_values(i)
獲取行數和列數
複製代碼代碼如下:
nrows = table.nrows
ncols = table.ncols
循環行列表數據
複製代碼代碼如下:
for i in range(nrows ):
print table.row_values(i)
單元格
複製代碼代碼如下:
cell_A1 = table.cell(0,0).value
cell_C4 = table.cell(2,3).value
使用行列索引
複製代碼代碼如下:
cell_A1 = table.row(0)[0].value
cell_A2 = table.col(1)[0].value
簡單的寫入
複製代碼代碼如下:
row = 0
col = 0
# 類型 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
ctype = 1 value = '單元格的值'
xf = 0 # 擴展的格式化
table.put_cell(row, col, ctype, value, xf)
table.cell(0,0) #單元格的值'
table.cell(0,0).value #單元格的值'
三、Demo代碼
Demo代碼其實很簡單,就是讀取Excel數據。
[py] view plain copy
# -*- coding: utf-8 -*-
import xdrlib ,sys
import xlrd
def open_excel(file= 'file.xls'):
try:
data = xlrd.open_workbook(file)
return data
except Exception,e:
print str(e)
#根據索引獲取Excel表格中的數據 參數:file:Excel文件路徑 colnameindex:表頭列名所在行的所以 ,by_index:表的索引
def excel_table_byindex(file= 'file.xls',colnameindex=0,by_index=0):
data = open_excel(file)
table = data.sheets()[by_index]
nrows = table.nrows #行數
ncols = table.ncols #列數
colnames = table.row_values(colnameindex) #某一行數據
list =[]
for rownum in range(1,nrows):
row = table.row_values(rownum)
if row:
app = {}
for i in range(len(colnames)):
app[colnames[i]] = row[i]
list.append(app)
return list
#根據名稱獲取Excel表格中的數據 參數:file:Excel文件路徑 colnameindex:表頭列名所在行的所以 ,by_name:Sheet1名稱
def excel_table_byname(file= 'file.xls',colnameindex=0,by_name=u'Sheet1'):
data = open_excel(file)
table = data.sheet_by_name(by_name)
nrows = table.nrows #行數
colnames = table.row_values(colnameindex) #某一行數據
list =[]
for rownum in range(1,nrows):
row = table.row_values(rownum)
if row:
app = {}
for i in range(len(colnames)):
app[colnames[i]] = row[i]
list.append(app)
return list
def main():
tables = excel_table_byindex()
for row in tables:
print row
tables = excel_table_byname()
for row in tables:
print row
if __name__=="__main__":
main()
基本的代碼結構
複製代碼代碼如下:
data = xlrd.open_workbook(EXCEL_PATH)
table = data.sheet_by_index(0)
lines = table.nrows
cols = table.ncols
print u'The total line is %s, cols is %s'%(lines, cols)
讀取某個單元格:
複製代碼代碼如下:
table.cell(x, y).value
x:行
y:列
行,列都是從0開始
* 時間類型的轉換,把excel中時間轉成python 時間(兩種方式)
excel某個單元格 2014/7/8
複製代碼代碼如下:
xlrd.xldate_as_tuple(table.cell(2,2).value, 0) #轉化爲元組形式
(2014, 7, 8, 0, 0, 0)
xlrd.xldate.xldate_as_datetime(table.cell(2,2).value, 1) #直接轉化爲datetime對象
datetime.datetime(2018, 7, 9, 0, 0)
table.cell(2,2).value #沒有轉化
41828.0
源碼查看:
複製代碼代碼如下:
# @param xldate The Excel number
# @param datemode 0: 1900-based, 1: 1904-based.
xldate_as_tuple(xldate, datemode)
輸入一個日期類型的單元格會返回一個時間結構組成的元組,可以根據這個元組組成時間類型
datemode 有2個選項基本我們都會使用1900爲基礎的時間戳
複製代碼代碼如下:
##
# Convert an Excel date/time number into a datetime.datetime object.
#
# @param xldate The Excel number
# @param datemode 0: 1900-based, 1: 1904-based.
#
# @return a datetime.datetime() object.
#
def xldate_as_datetime(xldate, datemode)
輸入參數和上面的相同,但是返回值是一個datetime類型,就不需要在自己轉換了
當然這兩個函數都有相應的逆函數,把python類型變成相應的excle時間類型。
腳本里先註明# -*- coding:utf-8 -*-
1. 確認源excel存在並用xlrd讀取第一個表單中每行的第一列的數值。
[py] view plain copy
import xlrd, xlwt
import os
assert os.path.isfile('source_excel.xls'),"There is no timesheet exist. Exit..."
book = xlrd.open_workbook('source_excel.xls')
sheet=book.sheet_by_index(0)
for rows in range(sheet.nrows):
value = sheet.cell(rows,0).value
2. 用xlwt準備將從源表中讀出的數據寫入新表,並設定行寬和表格的格式。合併單元格2行8列後寫入標題,並設定格式爲之前定義的tittle_style。
使用的是write_merge。
[py] view plain copy
wbk = xlwt.Workbook(encoding='utf-8')
sheet_w = wbk.add_sheet('write_after', cell_overwrite_ok=True)
sheet_w.col(3).width = 5000
tittle_style = xlwt.easyxf('font: height 300, name SimSun, colour_index red, bold on; align: wrap on, vert centre, horiz center;')
sheet_w.write_merge(0,2,0,8,u'這是標題',tittle_style)
3. 當函數中要用到全局變量時,注意加global。否則會出現UnboundLocalError:local variable'xxx' referenced before assignment.
[py] view plain copy
check_num = 0
def check_data(sheet):
global check_num
check_num=check_num+1
4. 寫入日期和帶格式的數值。原來從sheet中讀取的日期格式爲2014/4/10,處理後只保留日期並做成數組用逗號分隔後寫入新的excel。
[py] view plain copy
date_arr = []
date=sheet.cell(row,2).value.rsplit('/')[-1]
if date not in date_arr:
date_arr.append(date)
sheet_w.write_merge(row2,row2,6,6,date_num, normal_style)
sheet_w.write_merge(row2,row2,7,7,','.join(date_arr), normal_style)
5. 當從excel中讀取的日期格式爲xldate時,就需要使用xlrd的xldate_as_tuple來處理爲date格式。先判斷表格的ctype確實是xldate才能開始操作,否則會報錯。之後date格式可以使用strftime來轉化爲string。如:date.strftime("%Y-%m-%d-%H")
[py] view plain copy
from datetime import date,datetime
from xlrd import xldate_as_tuple
if (sheet.cell(rows,3).ctype == 3):
num=num+1
date_value = xldate_as_tuple(sheet.cell_value(rows,3),book.datemode)
date_tmp = date(*date_value[:3]).strftime("%d")
6. 最後保存新寫的表
[py] view plain copy
wbk.save('new_excel.xls')
https://blog.csdn.net/chengxuyuanyonghu/article/details/54951399轉載自