




如果要想真正的掌握sparkSQL編程,首先要對sparkSQL的整體框架以及sparkSQL到底能幫助我們解決什麼問題有一個整體的認識,然後就是對各個層級關係有一個清晰的認識後,才能真正的掌握它,對於sparkSQL整體框架這一塊,
目的是讓那些初次接觸sparkSQL框架的童鞋們,希望他們對sparkSQL整體框架有一個大致的瞭解,降低他們進入spark世界的門檻,避免他們在剛剛接觸sparkSQL時,不知所措,不知道該學習什麼,該怎麼看。這也是自己工作的一個總結,以便以後可以回頭查看。後續會對sparkSQL進行一系列詳細的介紹。慢慢來吧~~~
1、sql語句的模塊解析
當我們寫一個查詢語句時,一般包含三個部分,select部分,from數據源部分,where限制條件部分,這三部分的內容在sql中有專門的名稱:
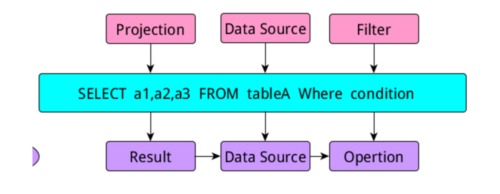
當我們寫sql時,如上圖所示,在進行邏輯解析時會把sql分成三個部分,project,DataSource,Filter模塊,當生成執行部分時又把他們稱爲:Result模塊、
DataSource模塊和Opertion模塊。
很多初學者,對大數據的概念都是模糊不清的,大數據是什麼,能做什麼,學的時候,該按照什麼線路去學習,學完往哪方面發展,想深入瞭解,想學習的同學歡迎加入大數據學習qq羣:199427210,有大量乾貨(零基礎以及進階的經典實戰)分享給大家,並且有清華大學畢業的資深大數據講師給大家免費授課,給大家分享目前國內最完整的大數據高端實戰實用學習流程體系
那麼在關係數據庫中,當我們寫完一個查詢語句進行執行時,發生的過程如下圖所示:

整個執行流程是:query -> Parse -> Bind -> Optimize -> Execute
1、寫完sql查詢語句,sql的查詢引擎首先把我們的查詢語句進行解析,也就是Parse過程,解析的過程是把我們寫的查詢語句進行分割,把project,DataSource和Filter三個部分解析出來從而形成一個邏輯解析tree,在解析的過程中還會檢查我們的sql語法是否有錯誤,比如缺少指標字段、數據庫中不包含這張數據表等。當發現有錯誤時立即停止解析,並報錯。當順利完成解析時,會進入到Bind過程。
2、Bind過程,通過單詞我們可看出,這個過程是一個綁定的過程。爲什麼需要綁定過程?這個問題需要我們從軟件實現的角度去思考,如果讓我們來實現這個sql查詢引擎,我們應該怎麼做?他們採用的策略是首先把sql查詢語句分割,分割不同的部分,再進行解析從而形成邏輯解析tree,然後需要知道我們需要取數據的數據表在哪裏,需要哪些字段,執行什麼邏輯,這些都保存在數據庫的數據字典中,因此bind過程,其實就是把Parse過程後形成的邏輯解析tree,與數據庫的數據字典綁定的過程。綁定後會形成一個執行tree,從而讓程序知道表在哪裏,需要什麼字段等等
3、完成了Bind過程後,數據庫查詢引擎會提供幾個查詢執行計劃,並且給出了查詢執行計劃的一些統計信息,既然提供了幾個執行計劃,那麼有比較就有優劣,數據庫會根據這些執行計劃的統計信息選擇一個最優的執行計劃,因此這個過程是Optimize(優化)過程。
4、選擇了一個最優的執行計劃,那麼就剩下最後一步執行Execute,最後執行的過程和我們解析的過程是不一樣的,當我們知道執行的順序,對我們以後寫sql以及優化都是有很大的幫助的.執行查詢後,他是先執行where部分,然後找到數據源之數據表,最後生成select的部分,我們的最終結果。執行的順序是:operation->DataSource->Result
雖然以上部分對sparkSQL沒有什麼聯繫,但是知道這些,對我們理解sparkSQL還是很有幫助的。
2、sparkSQL框架的架構
要想對這個框架有一個清晰的認識,首先我們要弄清楚,我們爲什麼需要sparkSQL呢?個人建議一般情況下在寫sql能夠直接解決的問題就不要使用sparkSQL,如果想刻意使用sparkSQL,也不一定能夠加快開發的進程。使用sparkSQL是爲了解決一般用sql不能解決的複雜邏輯,使用編程語言的優勢來解決問題。我們使用sparkSQL一般的流程如下圖:
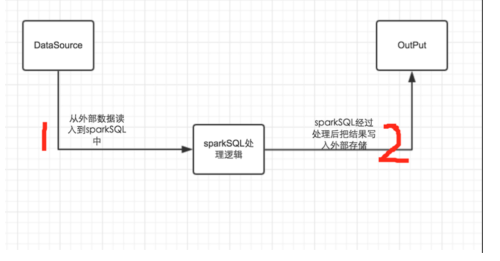
如上圖所示,一般情況下分爲兩個部分:a、把數據讀入到sparkSQL中,sparkSQL進行數據處理或者算法實現,然後再把處理後的數據輸出到相應的輸出源中。
1、同樣我們也是從如果讓我們開發,我們應該怎麼做,需要考慮什麼問題來思考這個問題。
a、第一個問題是,數據源有幾個,我們可能從哪些數據源讀取數據?現在sparkSQL支持很多的數據源,比如:hive數據倉庫、json文件,.txt,以及orc文件,同時現在還支持jdbc從關係數據庫中取數據。功能很強大。
b、還一個需要思考的問題是數據類型怎麼映射啊?我們知道當我們從一個數據庫表中讀入數據時,我們定義的表結構的字段的類型和編程語言比如scala中的數據類型映射關係是怎 樣的一種映射關係?在sparkSQL中有一種來解決這個問題的方法,來實現數據表中的字段類型到編程語言數據類型的映射關係。這個以後詳細介紹,先了解有這個問題就行。
c、數據有了,那麼在sparkSQL中我們應該怎麼組織這些數據,需要什麼樣的數據結構呢,同時我們對這些數據都可以進行什麼樣的操作?sparkSQL採用的是DataFrame數據結構來組織讀入到sparkSQL中的數據,DataFrame數據結構其實和數據庫的表結構差不多,數據是按照行來進行存儲,同是還有一個schema,就相當於數據庫的表結構,記錄着每一行數據屬於哪個字段。
d、當數據處理完以後,我們需要把數據放入到什麼地方,並切以什麼樣的格式進行對應,這個a和b要解決的問題是相同的。
2、sparkSQL對於以上問題,的實現邏輯也很明確,從上圖,已經很清楚,主要分爲兩個階段,每個階段都對應一個具體的類來實現。
a、 對於第一個階段,sparkSQL中存在兩個類來解決這些問題:HiveContext,SQLContext,同事hiveContext繼承了SQLContext的所有方法,同事又對其進行了擴展。因爲我們知道, hive和mysql的查詢還是有一定的差別的。HiveContext只是用來處理從hive數據倉庫中讀入數據的操作,SQLContext可以處理sparkSQL能夠支持的剩下的所有的數據源。這兩個類處理的粒度是限制在對數據的讀寫上,同事對錶級別的操作上,比如,讀入數據、緩存表、釋放緩存表表、註冊表、刪除註冊的表、返回表的結構等的操作。
b、sparkSQL處理讀入的數據,採用的是DataFrame中提供的方法。因爲當我們把數據讀入到sparkSQL中,這個數據就是DataFrame類型的。同時數據都是按照Row進行存儲的。其中 DataFrame中提供了很多有用的方法。以後會細說。
c、在spark1.6版本以後,又增加了一個類似於DataFrame的數據結構DataSet,增加此數據結構的目的DataFrame有軟肋,他只能處理按照Row進行存儲的數據,並且只能使用DataFrame中提供的方法,我們只能使用一部分RDD提供的操作。實現DataSet的目的就是讓我們能夠像操作RDD一樣來操作sparkSQL中的數據。
d、其中還有一些其他的類,但是現在在sparkSQL中最主要的就是上面的三個類,其他類以後碰到了會慢慢想清楚。
3、sparkSQL的hiveContext和SQLContext的運行原理
hiveContext和SQLContext與我第一部分講到的sql語句的模塊解析實現的原理其實是一樣的,採用了同樣的邏輯過程,並且網上有好多講這一塊的,就直接粘貼複製啦!!
sqlContext總的一個過程如下圖所示:
1.SQL語句經過SqlParse解析成UnresolvedLogicalPlan;
2.使用analyzer結合數據數據字典(catalog)進行綁定,生成resolvedLogicalPlan;
3.使用optimizer對resolvedLogicalPlan進行優化,生成optimizedLogicalPlan;
4.使用SparkPlan將LogicalPlan轉換成PhysicalPlan;
5.使用prepareForExecution()將PhysicalPlan轉換成可執行物理計劃;
6.使用execute()執行可執行物理計劃;
7.生成SchemaRDD。
在整個運行過程中涉及到多個SparkSQL的組件,如SqlParse、analyzer、optimizer、SparkPlan等等
hiveContext總的一個過程如下圖所示:
1.SQL語句經過HiveQl.parseSql解析成Unresolved LogicalPlan,在這個解析過程中對hiveql語句使用getAst()獲取AST樹,然後再進行解析;
2.使用analyzer結合數據hive源數據Metastore(新的catalog)進行綁定,生成resolved LogicalPlan;
3.使用optimizer對resolved LogicalPlan進行優化,生成optimized LogicalPlan,優化前使用了ExtractPythonUdfs(catalog.PreInsertionCasts(catalog.CreateTables(analyzed)))進行預處理;
4.使用hivePlanner將LogicalPlan轉換成PhysicalPlan;
5.使用prepareForExecution()將PhysicalPlan轉換成可執行物理計劃;
6.使用execute()執行可執行物理計劃;
7.執行後,使用map(_.copy)將結果導入SchemaRDD。
再多說一點,對於初學者,本人堅持的觀點是不要一上來就看源碼,這樣的效果不是很大,還浪費時間,對這個東西還沒有大致掌握,還不知道它是幹什麼的,上來就看源碼,門檻太高,而且看源碼對個人的提升也不是很高。我們做軟件開發的,我們開發的順序也是,首先是需求,對需求有了詳細的認識,需要解決什麼問題,然後纔是軟件的設計,代碼的編寫。同樣,學習框架也是,我們只有對這個框架的需求,它需要解決什麼問題,它需要幹什麼工作,都非常瞭解了,然後再看源碼,這樣效果才能得到很大的提升。對於閱讀源代碼這一塊,是本人的一點看法,說的對與錯,歡迎吐槽 ......!
......!
1、sparkSQL層級
當我們想用sparkSQL來解決我們的需求時,其實說簡單也簡單,就經歷了三步:讀入數據 -> 對數據進行處理 -> 寫入最後結果,那麼這三個步驟用的主要類其實就三個:讀入數據和寫入最後結果用到兩個類HiveContext和SQLContext,對數據進行處理用到的是DataFrame類,此類是你把數據從外部讀入到內存後,數據在內存中進行存儲的基本數據結構,在對數據進行處理時還會用到一些中間類,用到時在進行講解。如下圖所示:
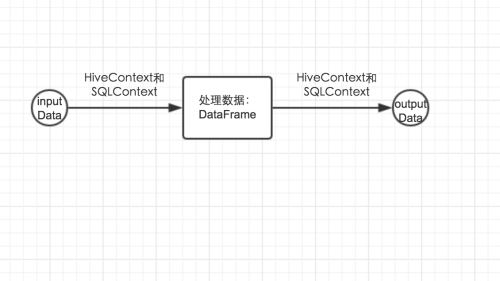
2、HiveContext和SQLContext
把HiveContext和SQLContext放在一起講解是因爲他們是差不多的,因爲HiveContext繼承自SQLContext,爲什麼會有兩個這樣的類,其實與hive和sql有關係的,雖然hive擁有HQL語言,但是它是一個類sql語言,和sql語言還是有差別的,有些sql語法,HQL是不支持的。所以他們還是有差別的。選擇不同的類,最後執行的查詢引擎的驅動是不一樣的。但是對於底層是怎麼區別的這裏不做詳細的介紹,你就知道一點,使用不同的讀數據的類,底層會進行標記,自動識別是使用哪個類進行數據操作,然後採用不同的執行計劃執行操作,這點在上一篇sparkSQL整體框架中進行了介紹,這裏不做介紹。當從hive庫中讀數據的時候,必須使用HiveContext來進行讀取數據,不然在進行查詢的時候會出一些奇怪的錯。其他的數據源兩者都可以選擇,但是最好使用SQLContext來完成。因爲其支持的sql語法更多。由於HiveContext是繼承自SQLContext,這裏只對SQLContext進行詳細的介紹,但是以下這些方法是完全可以用在HiveContext中的。其實HiveContext類就擴展了SQLContext的兩個我們可以使用的方法(在看源碼時以protected和private開頭的方法都是我們不能使用的,這個是scala的控制邏輯,相反,不是以這兩個關鍵字標記的方法是我們可以直接使用的方法):analyze(tableName:String)和refreshTable(tableName:String)。
| 方法 | 用途 |
| analyze方法 | 這個我們一般使用不到,它是來對我們寫的sql查詢語句進行分析用的,一般用不到。 |
| refreshTable方法 | 當我們在sparkSQL中處理的某個表的存儲位置發生了變換,但是我們在內存的metaData中緩存(cache)了這張表,則需要調用這個方法來使這個緩存無效,需要重新加載。
|
2.1 讀數據
我們在解決我們的需求時,首先是讀入數據,需要把數據讀入到內存中去,讀數據SQLContext提供了兩個方法,我們提供兩個數據表,爲了便於演示,我採用的是用JSON格式進行存儲的,寫成這樣的格式,但是可以保存爲.txt格式的文件。

1、第一種數據讀入:這種是對數據源文件進行操作。
import org.apache.spark.sql.SQLContext
val sql = new SQLContext(sc) //聲明一個SQLContext的對象,以便對數據進行操作
val peopleInfo = sql.read.json("文件路徑")
//其中peopleInfo返回的結果是:org.apache.spark.sql.DataFrame =
// [age: bigint, id: bigint, name: string],這樣就把數據讀入到內存中了寫了這幾行代碼後面總共發生了什麼,首先sparkSQL先找到文件,以解析json的形式進行解析,同時通過json的key形成schema,scheam的字段的順序不是按照我們讀入數據時期默認的順序,如上,其字段的順序是通過字符串的順序進行重新組織的。默認情況下,會把整數解析成bigint類型的,把字符串解析成string類型的,通過這個方法讀入數據時,返回值得結果是一個DataFrame數據類型。
DataFrame是什麼?其實它是sparkSQL處理大數據的基本並且是核心的數據結構,是來存儲sparkSQL把數據讀入到內存中,數據在內存中進行存儲的基本數據結構。它採用的存儲是類似於數據庫的表的形式進行存儲的。我們想一想,一個數據表有幾部分組成:1、數據,這個數據是一行一行進行存儲的,一條記錄就是一行,2、數據表的數據字典,包括表的名稱,表的字段和字段的類型等元數據信息。那麼DataFrame也是按照行進行存儲的,這個類是Row,一行一行的進行數據存儲。一般情況下處理粒度是行粒度的,不需要對其行內數據進行操作,如果想單獨操作行內數據也是可以的,只是在處理的時候要小心,因爲處理行內的數據容易出錯,比如選錯數據,數組越界等。數據的存儲的形式有了,數據表的字段和字段的類型都存放在哪裏呢,就是schema中。我們可以調用schema來看其存儲的是什麼。
peopleInfo.schema
//返回的結果是:org.apache.spark.sql.types.StructType =
//StructType(StructField(age,LongType,true), StructField(id,LongType,true),
// StructField(name,StringType,true))可以看出peopleInfo存儲的是數據,schema中存儲的是這些字段的信息。需要注意的是表的字段的類型與scala數據類型的對應關係:bigint->Long,int -> Int,Float -> Float,double -> Double,string -> String等。一個DataFrame是有兩部分組成的:以行進行存儲的數據和scheam,schema是StructType類型的。當我們有數據而沒有schema時,我們可以通過這個形式進行構造從而形成一個DataFrame。
read函數還提供了其他讀入數據的接口:
| 函數 | 用途 |
| json(path:String) |
讀取json文件用此方法 |
| table(tableName:String) | 讀取數據庫中的表 |
| jdbc(url: String,table: String,predicates:Array[String],connectionProperties:Properties)
|
通過jdbc讀取數據庫中的表 |
| orc(path:String) | 讀取以orc格式進行存儲的文件 |
| parquet(path:String) | 讀取以parquet格式進行存儲的文件 |
| schema(schema:StructType) | 這個是一個優化,當我們讀入數據的時候指定了其schema,底層就不會再次解析schema從而進行了優化,一般不需要這樣的優化,不進行此優化,時間效率還是可以接受 |
2、第二種讀入數據:這個讀入數據的方法,主要是處理從一個數據表中選擇部分字段,而不是選擇表中的所有字段。那麼這種需求,採用這個數據讀入方式比較有優勢。這種方式是直接寫sql的查詢語句。把上述json格式的數據保存爲數據庫中表的格式。需要注意的是這種只能處理數據庫表數據。
val peopleInfo = sql.sql("""
|select
| id,
| name,
| age
|from peopleInfo
""".stripMargin)//其中stripMargin方法是來解析我們寫的sql語句的。
//返回的結果是和read讀取返回的結果是一樣的:
//org.apache.spark.sql.DataFrame =
// [age: bigint, id: bigint, name: string]需要注意的是其返回的schmea中字段的順序和我們查詢的順序還是不一致的。
2.2 寫入數據
寫入數據就比較的簡單,因爲其擁有一定的模式,按照這個模式進行數據的寫入。一般情況下,我們需要寫入的數據是一個DataFrame類型的,如果其不是DataFrame類型的我們需要把其轉換爲
DataFrame類型,有些人可能會有疑問,數據讀入到內存中,其類型是DataFrame類型,我們在處理數據時用到的是DataFrame類中的方法,但是DataFrame中的方法不一定返回值仍然是DataFrame類型的,同時有時我們需要構建自己的類型,所以我們需要爲我們的數據構建成DataFrame的類型。把沒有schema的數據,構建schema類型,我所知道的就有兩種方法。
1、通過類構建schema,還以上面的peopleInfo爲例子。
val sql = new SQLContext(sc) //創建一個SQLContext對象
import sql.implicits._ //這個sql是上面我們定義的sql,而不是某一個jar包,網上有很多
//是import sqlContext.implicits._,那是他們定義的是
//sqlContext = SQLContext(sc),這個是scala的一個特性
val people = sc.textFile("people.txt")//我們採用spark的類型讀入數據,因爲如果用
//SQLContext進行讀入,他們自動有了schema
case clase People(id:Int,name:String,age:Int)//定義一個類
val peopleInfo = people.map(lines => lines.split(","))
.map(p => People(p(0).toInt,p(1),p(2).toInt)).toDF
//這樣的一個toDF就創建了一個DataFrame,如果不導入
//sql.implicits._,這個toDF方法是不可以用的。上面的例子是利用了scala的反射技術,生成了一個DataFrame類型。可以看出我們是把RDD給轉換爲DataFrame的。
2、直接構造schema,以peopelInfo爲例子。直接構造,我們需要把我們的數據類型進行轉化成Row類型,不然會報錯。
val sql = new SQLContext(sc) //創建一個SQLContext對象
val people = sc.textFile("people.txt").map(lines => lines.split(","))
val peopleRow = sc.map(p => Row(p(0),p(1),(2)))//把RDD轉化成RDD(Row)類型
val schema = StructType(StructFile("id",IntegerType,true)::
StructFile("name",StringType,true)::
StructFile("age",IntegerType,true)::Nil)
val peopleInfo = sql.createDataFrame(peopleRow,schema)//peopleRow的每一行的數據
//類型一定要與schema的一致
//否則會報錯,說類型無法匹配
//同時peopleRow每一行的長度
//也要和schema一致,否則
//也會報錯構造schema用到了兩個類StructType和StructFile,其中StructFile類的三個參數分別是(字段名稱,類型,數據是否可以用null填充)
採用直接構造有很大的制約性,字段少了還可以,如果有幾十個甚至一百多個字段,這種方法就比較耗時,不僅要保證Row中數據的類型要和我們定義的schema類型一致,長度也要一樣,不然都會報錯,所以要想直接構造schema,一定要細心細心再細心,本人就被自己的不細心虐慘了,處理的字段將近一百,由於定義的schema和我的數據類型不一致,我就需要每一個字段每一個字段的去確認,字段一多在對的時候就容易疲勞,就這樣的一個錯誤,由於本人比較笨,就花費了一個下午的時間,所以字段多了,在直接構造schema的時候,一定要細心、細心、細心,重要的事情說三遍,不然會死的很慘。
好了,現在我們已經把我們的數據轉化成DataFrame類型的,下面就要往數據庫中寫我們的數據了
寫數據操作:
val sql = new SQLContext(sc)
val people = sc.textFile("people.txt").map(lines => lines.split(","))
val peopleRow = sc.map(p => Row(p(0),p(1),(2)))
val schema = StructType(StructFile("id",IntegerType,true)::
StructFile("name",StringType,true)::
StructFile("age",IntegerType,true)::Nil)
val peopleInfo = sql.createDataFrame(peopleRow,schema)
peopleInfo.registerTempTable("tempTable")//只有有了這個註冊的表tempTable,我們
//才能通過sql.sql(“”“ ”“”)進行查詢
//這個是在內存中註冊一個臨時表用戶查詢
sql.sql.sql("""
|insert overwrite table tagetTable
|select
| id,
| name,
| age
|from tempTable
""".stripMargin)//這樣就把數據寫入到了數據庫目標表tagetTable中有上面可以看到,sparkSQL的sql()其實就是用來執行我們寫的sql語句的。
好了,上面介紹了讀和寫的操作,現在需要對最重要的地方來進行操作了啊。
2.3 通過DataFrame中的方法對數據進行操作
在介紹DataFrame之前,我們還是要先明確一下,sparkSQL是用來幹什麼的,它主要爲我們提供了怎樣的便捷,我們爲什麼要用它。它是爲了讓我們能用寫代碼的形式來處理sql,這樣說可能有點不準確,如果就這麼簡單,只是對sql進行簡單的替換,要是我,我也不學習它,因爲我已經會sql了,會通過sql進行處理數據倉庫的etl,我還學習sparkSQL幹嘛,而且學習的成本又那麼高。sparkSQL肯定有好處了,不然也不會有這篇博客啦。我們都知道通過寫sql來進行數據邏輯的處理時有限的,寫程序來進行數據邏輯的處理是非常靈活的,所以sparkSQL是用來處理那些不能夠用sql來進行處理的數據邏輯或者用sql處理起來比較複雜的數據邏輯。一般的原則是能用sql來處理的,儘量用sql來處理,畢竟開發起來簡單,sql處理不了的,再選擇用sparkSQL通過寫代碼的方式來處理。好了廢話不多說了,開始DataFrame之旅。
sparkSQL非常強大,它提供了我們sql中的正刪改查所有的功能,每一個功能都對應了一個實現此功能的方法。
對schema的操作
val sql = new SQLContext(sc)
val people = sql.read.json("people.txt")//people是一個DataFrame類型的對象
//數據讀進來了,那我們查看一下其schema吧
people.schema
//返回的類型
//org.apache.spark.sql.types.StructType =
//StructType(StructField(age,LongType,true),
// StructField(id,LongType,true),
// StructField(name,StringType,true))
//以數組的形式分會schema
people.dtypes
//返回的結果:
//Array[(String, String)] =
// Array((age,LongType), (id,LongType), (name,StringType))
//返回schema中的字段
people.columns
//返回的結果:
//Array[String] = Array(age, id, name)
//以tree的形式打印輸出schema
people.printSchema
//返回的結果:
//root
// |-- age: long (nullable = true)
// |-- id: long (nullable = true)
// |-- name: string (nullable = true)對錶的操作,對錶的操作語句一般情況下是不常用的,因爲雖然sparkSQL把sql查的每一個功能都封裝到了一個方法中,但是處理起來還是不怎麼靈活一般情況下我們採用的是用sql()方法直接來寫sql,這樣比較實用,還更靈活,而且代碼的可讀性也是很高的。那下面就把能用到的方法做一個簡要的說明。
| 方法(sql使我們定義的sql = new SQLContext(sc)) df是一個DataFrame對象 | 實例說明 |
| sql.read.table(tableName) | 讀取一張表的數據 |
| df.where(), df.filter() | 過濾條件,相當於sql的where部分; 用法:選擇出年齡字段中年齡大於20的字段。 返回值類型:DataFrame
df.where("age >= 20"),df.filter("age >= 20") |
| df.limit() | 限制輸出的行數,對應於sql的limit 用法:限制輸出一百行 返回值類型:DataFrame
df.limit(100) |
| df.join() | 鏈接操作,相當於sql的join 對於join操作,下面會單獨進行介紹 |
| df.groupBy() | 聚合操作,相當於sql的groupBy 用法:對於某幾行進行聚合 返回值類型:DataFrame
df.groupBy("id") |
| df.agg() | 求聚合用的相關函數,下面會詳細介紹 |
| df.intersect(other:DataFrame)
|
求兩個DataFrame的交集 |
| df.except(other:DataFrame) | 求在df中而不在other中的行 |
| df.withColumn(colName:String,col:Column) | 增加一列 |
| df.withColumnRenamed(exName,newName) | 對某一列的名字進行重新命名 |
| df.map(), df.flatMap, df.mapPartitions(), df.foreach() df.foreachPartition() df.collect() df.collectAsList() df.repartition() df.distinct() df.count() |
這些方法都是spark的RDD的基本操作,其中在DataFrame類中也封裝了這些方法,需要注意的是這些方法的返回值是RDD類型的,不是DataFrame類型的,在這些方法的使用上,一定要記清楚返回值類型,不然就容易出現錯誤 |
| df.select() | 選取某幾列元素,這個方法相當於sql的select的功能 用法:返回選擇的某幾列數據 返回值類型:DataFrame
df.select("id","name") |
以上是兩個都是一寫基本的方法,下面就詳細介紹一下join和agg,na,udf操作
2.4 sparkSQL的join操作
spark的join操作就沒有直接寫sql的join操作來的靈活,在進行鏈接的時候,不能對兩個表中的字段進行重新命名,這樣就會出現同一張表中出現兩個相同的字段。下面就一點一點的進行展開用到的兩個表,一個是用戶信息表,一個是用戶的收入薪資表:
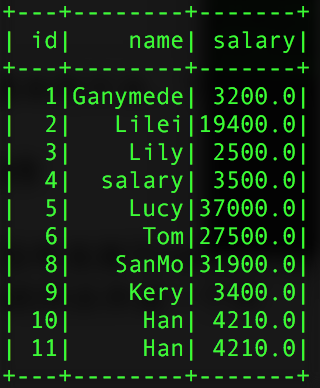
1、內連接,等值鏈接,會把鏈接的列合併成一個列
val sql = new SQLContext(sc)
val pInfo = sql.read.json("people.txt")
val pSalar = sql.read.json("salary.txt")
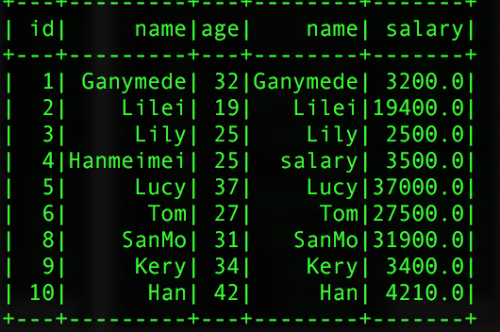
val info_salary = pInfo.join(pSalar,"id")//單個字段進行內連接
val info_salary1 = pInfo.join(pSalar,Seq("id","name"))//多字段鏈接返回的結果如下圖:
單個id進行鏈接 (一張表出現兩個name字段) 兩個字段進行鏈接

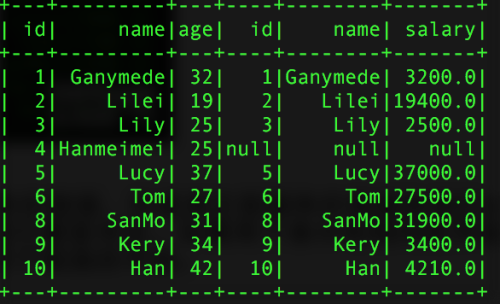
2、join還支持左聯接和右鏈接,但是其左聯接和右鏈接和我們sql的鏈接的意思是一樣的,同樣也是在鏈接的時候不能對字段進行重新命名,如果兩個表中有相同的字段,則就會出現在同一個join的表中,同事左右鏈接,不會合並用於鏈接的字段。鏈接用的關鍵詞:outer,inner,left_outer,right_outer
//單字段鏈接
val left = pInfo.join(pSalar,pInfo("id") === pSalar("id"),"left_outer")
//多字段鏈接
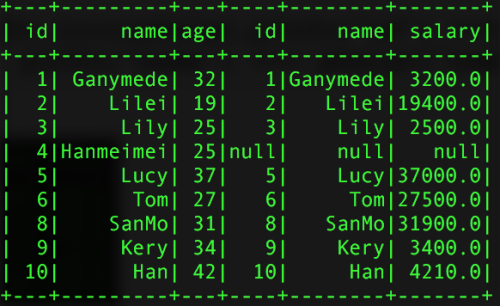
val left2 = pInfo.join(pSalar,pInfo("id") === pSalar("id") and
pInfo("name") === pSalar("name"),"left_outer")返回的結果:
單字段鏈接 多字段鏈接
由上可以發現,sparkSQL的join操作還是沒有sql的join靈活,容易出現重複的字段在同一張表中,一般我們進行鏈接操作時,我們都是先利用registerTempTable()函數把此DataFrame註冊成一個內部表,然後通過sql.sql("")寫sql的方法進行鏈接,這樣可以更好的解決了重複字段的問題。
2.5 sparkSQL的agg操作
其中sparkSQL的agg是sparkSQL聚合操作的一種表達式,當我們調用agg時,其一般情況下都是和groupBy()的一起使用的,選擇操作的數據表爲:
val pSalar = new SQLContext(sc).read.json("salary.txt")
val group = pSalar.groupBy("name").agg("salary" -> "avg")
val group2 = pSalar.groupBy("id","name").agg("salary" -> "avg")
val group3 = pSalar.groupBy("name").agg(Map("id" -> "avg","salary"->"max"))得到的結過如下:
group的結果 group2 group3
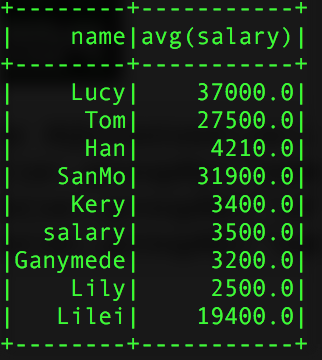
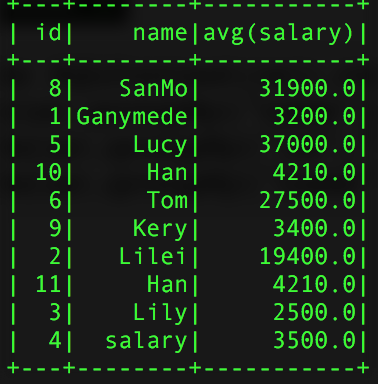
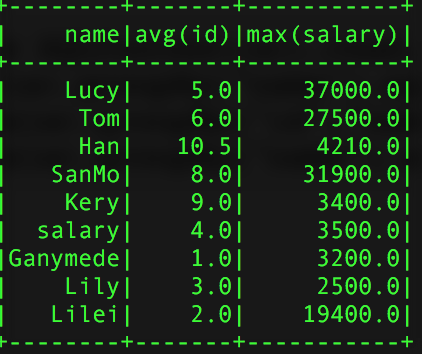
使用agg時需要注意的是,同一個字段不能進行兩次操作比如:agg(Map("salary" -> "avg","salary" -> "max"),他只會計算max的操作,原因很簡單,agg接入的參數是Map類型的key-value對,當key相同時,會覆蓋掉之前的value。同時還可以直接使用agg,這樣是對所有的行而言的。聚合所用的計算參數有:avg,max,min,sum,count,而不是隻有例子中用到的avg
2.6 sparkSQL的na操作
sparkSQL的na方法,返回的是一個DataFrameFuctions對象,此類主要是對DataFrame中值爲null的行的操作,只提供三個方法,drop()刪除行,fill()填充行,replace()代替行的操作。很簡單不做過多的介紹。
3、總結
我們使用sparkSQL的目的就是爲了解決用寫sql不能解決的或者解決起來比較困難的問題,在平時的開發過程中,我們不能爲了高逼格什麼樣的sql問題都是用sparkSQL,這樣不是最高效的。使用sparkSQL,主要是利用了寫代碼處理數據邏輯的靈活性,但是我們也不能完全的只使用sparkSQL提供的sql方法,這樣同樣是走向了另外一個極端,有上面的討論可知,在使用join操作時,如果使用sparkSQL的join操作,有很多的弊端。爲了能結合sql語句的優越性,我們可以先把要進行鏈接的DataFrame對象,註冊成內部的一箇中間表,然後在通過寫sql語句,用SQLContext提供的sql()方法來執行我們寫的sql,這樣處理起來更加的合理而且高效。在工作的開發過程中,我們要結合寫代碼和寫sql的各自的所長來處理我們的問題,這樣會更加的高效。
寫這篇博客,花費了我兩週的時間,由於工作比較忙,只有在業餘時間進行思考和總結。也算對自己學習的一個交代。關於sparkSQL的兩個類HiveContext和SQLContext提供的udf方法,如果用好了udf方法,可以使我們代碼的開發更加的簡潔和高效,可讀性也是很強的。
在這裏還是要推薦下我自己建的大數據學習羣:199427210,羣裏都是學大數據開發的,如果你正在學習大數據 ,小編歡迎你加入,大家都是軟件開發黨,不定期分享乾貨(只有大數據軟件開發相關的),包括我自己整理的一份2018最新的大數據進階資料和高級開發教程,歡迎進階中和進想深入大數據的小夥伴加入。