




1、HDFS 是做什麼的
Hadoop實現了一個分佈式文件系統(Hadoop Distributed File System),簡稱HDFS,hdfs是分佈式計算中數據存儲管理的基礎,是基於流數據模式訪問和處理超大文件的需求而開發的,可以運行於廉價的商用服務器上。它所具有的高容錯、高可靠性、高可擴展性、高獲得性、高吞吐率等特徵爲海量數據提供了不怕故障的存儲,爲超大數據集(Large Data Set)的應用處理帶來了很多便利。
2、爲什麼選擇 HDFS 存儲數據
之所以選擇 HDFS 存儲數據,因爲 HDFS 具有以下優點:
1、高容錯性
數據自動保存多個副本。它通過增加副本的形式,提高容錯性。
某一個副本丟失以後,它可以自動恢復,這是由 HDFS 內部機制實現的,我們不必關心。
2、適合批處理
它是通過移動計算而不是移動數據。
它會把數據位置暴露給計算框架。
3、適合大數據處理
處理數據達到 GB、TB、甚至PB級別的數據。 能夠處理百萬規模以上的文件數量,數量相當之大。
能夠處理10K節點的規模。
4、流式文件訪問
一次寫入,多次讀取。文件一旦寫入不能修改,只能追加。
它能保證數據的一致性。
5、可構建在廉價機器上
它通過多副本機制,提高可靠性。
它提供了容錯和恢復機制。比如某一個副本丟失,可以通過其它副本來恢復。
當然 HDFS 也有它的劣勢,並不適合所有的場合:
1、低延時數據訪問
比如毫秒級的來存儲數據,這是不行的,它做不到。
它適合高吞吐率的場景,就是在某一時間內寫入大量的數據。但是它在低延時的情況下是不行的,比如毫秒級以內讀取數據,這樣它是很難做到的。
2、小文件存儲
存儲大量小文件(這裏的小文件是指小於HDFS系統的Block大小的文件(默認64M))的話,它會佔用 NameNode大量的內存來存儲文件、目錄和塊信息。這樣是不可取的,因爲NameNode的內存總是有限的
小文件存儲的尋道時間會超過讀取時間,它違反了HDFS的設計目標。
3、併發寫入、文件隨機修改
一個文件只能有一個寫,不允許多個線程同時寫。
僅支持數據 append(追加),不支持文件的隨機修改。
3、內部結構
HDFS 如何上傳數據
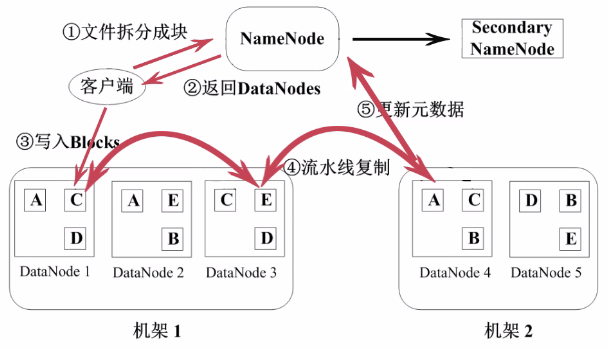
HDFS 採用Master/Slave的架構來存儲數據,這種架構主要由四個部分組成,分別爲HDFS Client、NameNode、DataNode和Secondary NameNode。下面我們分別介紹這四個組成部分
1、Client:就是客戶端。
- 文件切分。文件上傳 HDFS 的時候,Client 將文件切分成 一個一個的Block,然後進行存儲。
- 與 NameNode 交互,獲取文件的位置信息。
- 與 DataNode 交互,讀取或者寫入數據。
- Client 提供一些命令來管理 HDFS,比如啓動或者關閉HDFS。
- Client 可以通過一些命令來訪問 HDFS。
2、NameNode:就是 master,它是一個主管、管理者。
- 管理 HDFS 的名稱空間
- 管理數據塊(Block)映射信息
- 配置副本策略
- 處理客戶端讀寫請求。
3、DataNode:就是Slave。NameNode 下達命令,DataNode 執行實際的操作。
- 存儲實際的數據塊。
- 執行數據塊的讀/寫操作。
4、Secondary NameNode:並非 NameNode 的熱備。當NameNode 掛掉的時候,它並不能馬上替換 NameNode 並提供服務。
- 輔助 NameNode,分擔其工作量。
- 定期合併 fsimage和fsedits,並推送給NameNode。
- 在緊急情況下,可輔助恢復 NameNode。
5、HDFS 如何讀取文件
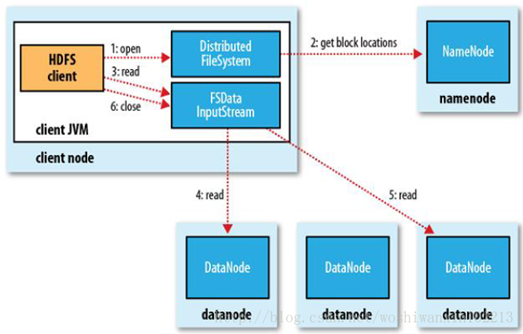
HDFS的文件讀取原理,主要包括以下幾個步驟:
- 首先調用FileSystem對象的open方法,其實獲取的是一個DistributedFileSystem的實例。
- DistributedFileSystem通過RPC(遠程過程調用)獲得文件的第一批block的locations,同一block按照重複數會返回多個locations,這些locations按照hadoop拓撲結構排序,距離客戶端近的排在前面。
- 前兩步會返回一個FSDataInputStream對象,該對象會被封裝成 DFSInputStream對象,DFSInputStream可以方便的管理datanode和namenode數據流。客戶端調用read方法,DFSInputStream就會找出離客戶端最近的datanode並連接datanode。
- 數據從datanode源源不斷的流向客戶端。
- 如果第一個block塊的數據讀完了,就會關閉指向第一個block塊的datanode連接,接着讀取下一個block塊。這些操作對客戶端來說是透明的,從客戶端的角度來看只是讀一個持續不斷的流。
- 如果第一批block都讀完了,DFSInputStream就會去namenode拿下一批blocks的location,然後繼續讀,如果所有的block塊都讀完,這時就會關閉掉所有的流。
6、HDFS 如何寫入文件
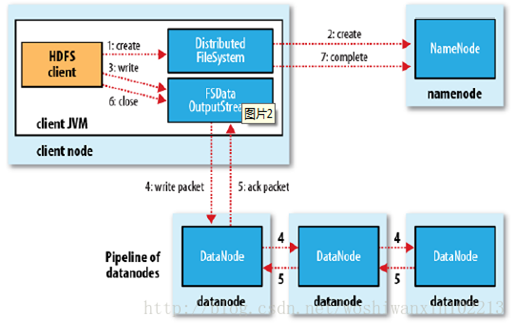
HDFS的文件寫入原理,主要包括以下幾個步驟:
- 客戶端通過調用 DistributedFileSystem 的create方法,創建一個新的文件。
- DistributedFileSystem 通過 RPC(遠程過程調用)調用 NameNode,去創建一個沒有blocks關聯的新文件。創建前,NameNode 會做各種校驗,比如文件是否存在,客戶端有無權限去創建等。如果校驗通過,NameNode 就會記錄下新文件,否則就會拋出IO異常。
- 前兩步結束後會返回 FSDataOutputStream 的對象,和讀文件的時候相似,FSDataOutputStream 被封裝成 DFSOutputStream,DFSOutputStream 可以協調 NameNode和 DataNode。客戶端開始寫數據到DFSOutputStream,DFSOutputStream會把數據切成一個個小packet,然後排成隊列 data queue。
- DataStreamer 會去處理接受 data queue,它先問詢 NameNode 這個新的 block 最適合存儲的在哪幾個DataNode裏,比如重複數是3,那麼就找到3個最適合的 DataNode,把它們排成一個 pipeline。DataStreamer 把 packet 按隊列輸出到管道的第一個 DataNode 中,第一個 DataNode又把 packet 輸出到第二個 DataNode 中,以此類推。
- DFSOutputStream 還有一個隊列叫 ack queue,也是由 packet 組成,等待DataNode的收到響應,當pipeline中的所有DataNode都表示已經收到的時候,這時akc queue纔會把對應的packet包移除掉。
- 客戶端完成寫數據後,調用close方法關閉寫入流。
- DataStreamer 把剩餘的包都刷到 pipeline 裏,然後等待 ack 信息,收到最後一個 ack 後,通知 DataNode 把文件標示爲已完成。
7、命令行接口
兩個屬性項: fs.default.name 用來設置Hadoop的默認文件系統,設置hdfs URL則是配置HDFS爲Hadoop的默認文件系統。dfs.replication 設置文件系統塊的副本個數
文件系統的基本操作:hadoop fs -help可以獲取所有的命令及其解釋
常用的有:
- hadoop fs -ls / 列出hdfs文件系統根目錄下的目錄和文件
- hadoop fs -put<local path> <hdfs path> 從本地文件系統將一個文件上傳到HDFS
- hadoop fs -get<hdfs path> <local path> 從本地文件系統將一個文件上傳到HDFS
- hadoop fs -rm -r <hdfs dir or file> 刪除文件或文件夾及文件夾下的文件
- hadoop fs -mkdir <hdfs dir>在hdfs中新建文件夾
操作路程
-
cd hadoop.2.5.2
-
cd sbin
-
./start-all.sh //啓動hdfs服務,yarn服務
-
cd ..
-
cd bin
-
./haoop dfs –ls / 解釋:./hdfs 是hdfs命令 dfs參數 表示在hadoop裏有效 –ls /顯示hdfs根目錄
-
./haoop dfs –rm /test/count/SUCCESS //刪除/test/count目錄裏的SUCCESS文件
-
./haoop dfs –rmr /test/count/output //刪除/test/count/output目錄
-
./haoop dfs –mkdir /test/count/input //創建/test/count/input目錄
-
從linux的 共享文件夾取得要分析的文件,上傳到 hdfs
./hadoop fs –put /mnt/hgfs/share/phone.txt /test/network
-
執行代碼分析,
./hadoop jar /mnt/hgfs/share/mobile.jar com.wanho.hadoopmobile.PhoneDriver
-
將產生的結果,傳回linux的共享文件夾
./hadoop fs –get /test/network/output1 /mnt/hgfs/share