




一、Spark Streaming的介紹
(1)爲什麼要有Spark Streaming?
Hadoop 的 MapReduce 及 Spark SQL 等只能進行離線計算,無法滿足實時性要求較高的業務 需求,例如實時推薦、實時網站性能分析等,流式計算可以解決這些問題。目前有三種比較 常用的流式計算框架,它們分別是 Storm,Spark Streaming 和 fink。
(2)Spark Streaming是什麼?

Spark Streaming,其實就是一種Spark提供的,對於大數據,進行實時計算的一種框架。它的底層,其實,也是基於我們之前講解的Spark Core的。基本的計算模型,還是基於內存的大數據實時計算模型。而且,它的底層的核心組件還是我們在Spark Core中經常用到的RDD。針對實時計算的特點,在RDD之上,進行了一層封裝,叫做DStream。其底層還是基於RDD的。所以,RDD是整個Spark技術生態中的核心。
Spark streaming支持的數據輸入源很多,如:Kafka、Flume、Twitter、ZeroMQ 和簡單的 TCP 套接字等等。數據輸入後可以用spark的高度抽象語:map、reduce、join、window 等進行運算。而結果也能保存在很多地方。如HDFS, 數據庫等。另外,spark streaming也能和MLlib(機器學習)以及 Graphx 完美融合。
(3)Spark Streaming的優勢
易用
容錯:
與spark體系無縫整合
二、Spark Streaming的核心概念

接收實時輸入數據流,然後將數據拆分成多個batch,比如每收集1秒的數據封裝爲一個batch,然後將每個batch交給Spark的計算引擎進行處理,最後會生產出一個結果數據流,其中的數據,也是由一個一個的batch所組成的。
(1)相關術語介紹:
離散流DStream:這是spark streaming對內部持續的實時數據流的抽象描述,即我們處理的一個實時數據,在sparkstreaming中對應一個DStream實例。
批數據:這是化整爲零的第一步,將實時數據抽象,以時間片爲單位進行分批,將流處理轉化爲時間片,數據的批處理,隨着持續時間的推移,這些處理結果就形成了對應的結果數據流。
時間片或批處理時間間隔:人爲地對流數據進行定量的標準,以時 間片作爲我們拆分流數據的依據。一個時間片的數據對應一個 RDD 實例。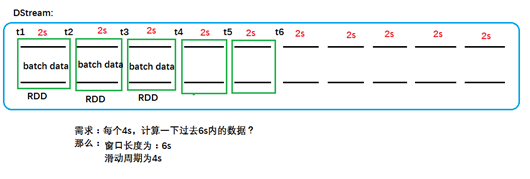
窗口長度:一個窗口覆蓋的數據流的時間長度,必須是批處理時間間隔的倍數。
滑動週期:前一個窗口到後一個窗口所經過的時間長度,必須是批處理時間間隔的倍數。
InputDStream:一個 InputDStream 是一個特殊的 DStream,表示第一次被加載到實時數據流中的原始數據。
(2)DStream的相關介紹:
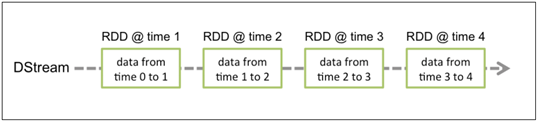
Discretized Stream 是 Spark Streaming 的基礎抽象,代表持續性的數據流和經過各種 Spark 原 語操作後的結果數據流。在內部實現上,DStream 是一系列連續的 RDD 來表示。DStream 是 連續數據的離散化表示,DStream 中每個離散片段都是一個 RDD,DStream 可以變換成另一 個 DStream。
DStream對數據的操作也是按照RDD爲單位來進行的: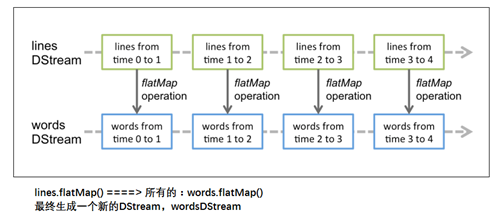
1)DStream的相關操作:
DStream上的原語與RDD類似,分爲:Transformations(轉換)和Output Operations(輸出,類似於action)。
由於DStream的操作與RDD極爲類似,而且DStream底層就是封裝的RDD,所以這裏簡單的介紹一下Transformations。
注意:Transformations操作中有幾個極爲重要的操作:updateStateByKey()、transform()、window()、foreachRDD()。以後的博文中爲詳細介紹。