




什麼是分佈式架構
分佈式系統(distributed system)是建立在網絡之上的軟件系統。
內聚性是指每一個數據庫分佈節點高度自治,有本地的數據庫管理系統。
透明性是指每一個數據庫分佈節點對用戶的應用來說都是透明的,看不出是本地還是遠程。
在分佈式數據庫系統中,用戶感覺不到數據是分佈的,即用戶不須知道關係是否分割、有無副本、數據存於哪個站點以及事務在哪個站點上執行等。
簡單來講:在一個分佈式系統中,一組獨立的計算機展現給用戶的是一個統一的整體,就好像是一個系統似的。

分佈式系統作爲一個整體對用戶提供服務,而整個系統的內部的協作用戶來說是透明的,用戶就像是在使用一個MySQL一樣。
如分佈式MySQL中間件-Mycat,來處理大併發大數據量的構架。
分佈式架構的應用
有 分佈式文件系統,分佈式緩存系統,分佈式數據庫,分佈式WebService,分佈式計算
我們來舉例說明:
分佈式文件系統: 出名的有 Hadoop 的HDFS ,還有 google的 GFS , 淘寶的 TFS 等
分佈式緩存系統:memcache , hbase , mongdb 等
分佈式數據庫 : MySQL , Mariadb, PostgreSQL 等
以分佈式MySQL數據庫中間件MyCat 爲例子,
MySQL 在現在電商以及互聯網公司的應用非常多,一個是因爲他的免費開源,另外一個原因是因爲分佈式系統
的水平可擴展性,隨着移動互聯網用戶的暴增,互聯網公司,像淘寶,天貓,唯品會等電商都採用分佈式系統應對
用戶的高併發量以及大數據量的存儲。
而在Mycat的商業案例中,有對中國移動的賬單結算項目中,應用實時處理高峯期每天2億的數據量,
在對物聯網的項目中,實現處理高達26億的數據量,並提供實時查詢的接口。
通過對MyCat的學習,加深分佈式系統架構的理解,
以及分佈式相關的技術,分佈式一致性ZooKeeper服務, 高可用HAProxy/keepalived等相關應用。
1> 集羣 與 分佈式
2> 負載均衡
3> 分佈式相關的高可用、容災等名詞解釋
4> Mycat 中間件學習
首先推薦4本書
大型分佈式網站架構設計與實踐
http://item.jd.com/11529266.html
大型網站技術架構:核心原理與案例分析
http://item.jd.com/11322972.html
大型網站系統與Java中間件實踐
http://item.jd.com/11449803.html
分佈式Java應用:基礎與實踐
http://item.jd.com/10144196.html
貌似都是4位阿里人寫的,一本一本的看吧,絕對會增強你的內功。
分佈式架構的演進
初始階段架構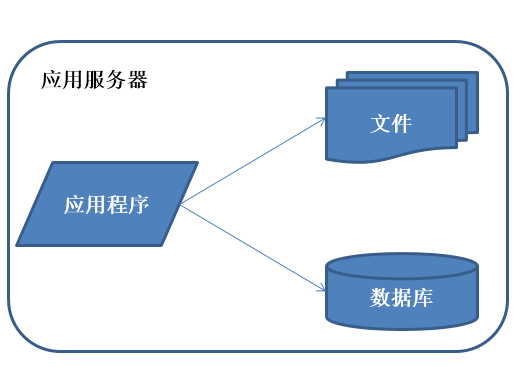
初始階段 的小型系統 應用程序、數據庫、文件等所有的資源都在一臺服務器上通俗稱爲LAMP
特徵:
應用程序、數據庫、文件等所有的資源都在一臺服務器上。
應用服務和數據服務分離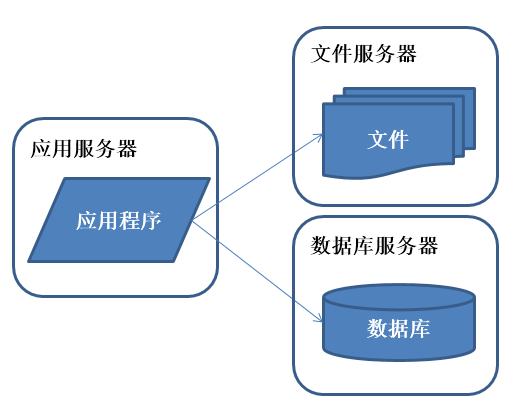
好景不長,發現隨着系統訪問量的再度增加,webserver機器的壓力在高峯期會上升到比較高,這個時候開始考慮增加一臺webserver
特徵:
應用程序、數據庫、文件分別部署在獨立的資源上。
使用緩存改善性能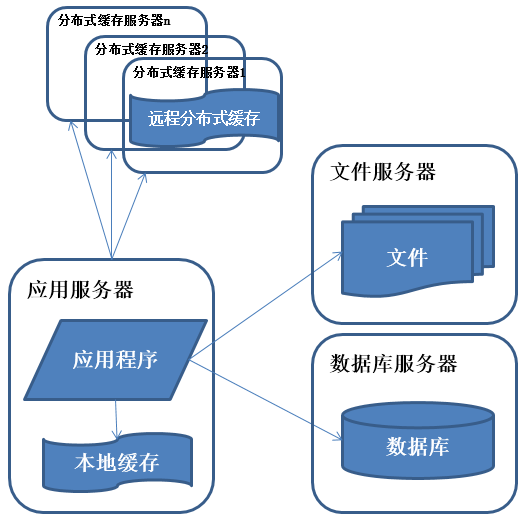
特徵:
數據庫中訪問較集中的一小部分數據存儲在緩存服務器中,減少數據庫的訪問次數,降低數據庫的訪問壓力。
描述:
系統訪問特點遵循二八定律,即80%的業務訪問集中在20%的數據上。
緩存分爲本地緩存和遠程分佈式緩存,本地緩存訪問速度更快但緩存數據量有限,同時存在與應用程序爭用內存的情況。
作者:知乎用戶
鏈接:https://www.zhihu.com/question/22764869/answer/31277656
來源:知乎
著作權歸作者所有。商業轉載請聯繫作者獲得授權,非商業轉載請註明出處。
使用應用服務器集羣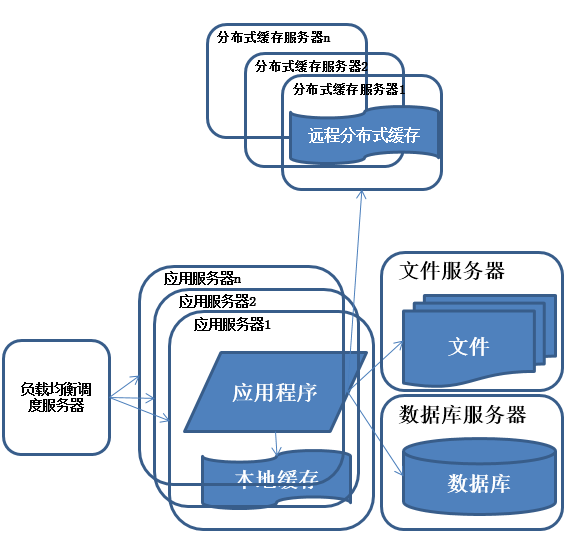
在做完分庫分表這些工作後,數據庫上的壓力已經降到比較低了,又開始過着每天看着訪問量暴增的幸福生活了,突然有一天,發現系統的訪問又開始有變慢的趨勢了,這個時候首先查看數據庫,壓力一切正常,之後查看webserver,發現apache阻塞了很多的請求,而應用服務器對每個請求也是比較快的,看來 是請求數太高導致需要排隊等待,響應速度變慢
特徵:
多臺服務器通過負載均衡同時向外部提供服務,解決單臺服務器處理能力和存儲空間上限的問題。
描述:
使用集羣是系統解決高併發、海量數據問題的常用手段。通過向集羣中追加資源,提升系統的併發處理能力,使得服務器的負載壓力不再成爲整個系統的瓶頸。
數據庫讀寫分離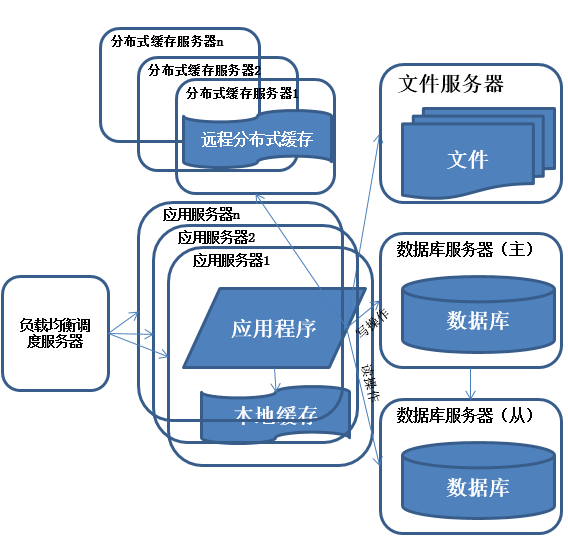
享受了一段時間的系統訪問量高速增長的幸福後,發現系統又開始變慢了,這次又是什麼狀況呢,經過查找,發現數據庫寫入、更新的這些操作的部分數據庫連接的資源競爭非常激烈,導致了系統變慢
特徵:
多臺服務器通過負載均衡同時向外部提供服務,解決單臺服務器處理能力和存儲空間上限的問題。
描述:
使用集羣是系統解決高併發、海量數據問題的常用手段。通過向集羣中追加資源,使得服務器的負載壓力不在成爲整個系統的瓶頸。
反向代理和CDN加速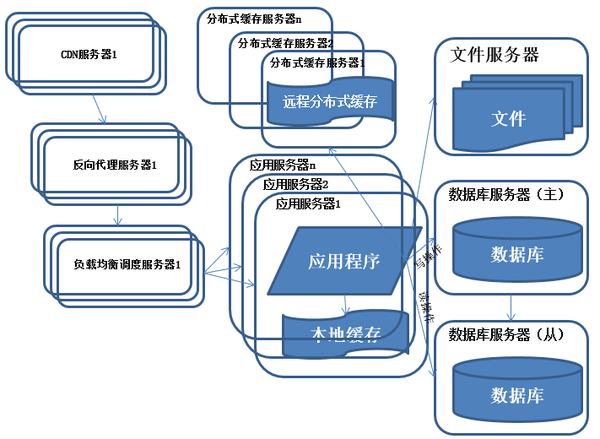
特徵:
採用CDN和反向代理加快系統的 訪問速度。
描述:
爲了應付複雜的網絡環境和不同地區用戶的訪問,通過CDN和反向代理加快用戶訪問的速度,同時減輕後端服務器的負載壓力。CDN與反向代理的基本原理都是緩存。
分佈式文件系統和分佈式數據庫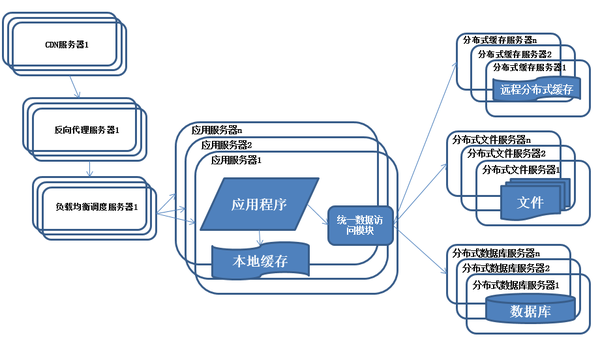
隨着系統的不斷運行,數據量開始大幅度增長,這個時候發現分庫後查詢仍然會有些慢,於是按照分庫的思想開始做分表的工作
特徵:
數據庫採用分佈式數據庫,文件系統採用分佈式文件系統。
描述:
任何強大的單一服務器都滿足不了大型系統持續增長的業務需求,數據庫讀寫分離隨着業務的發展最終也將無法滿足需求,需要使用分佈式數據庫及分佈式文件系統來支撐。
分佈式數據庫是系統數據庫拆分的最後方法,只有在單表數據規模非常龐大的時候才使用,更常用的數據庫拆分手段是業務分庫,將不同的業務數據庫部署在不同的物理服務器上。
使用NoSQL和搜索引擎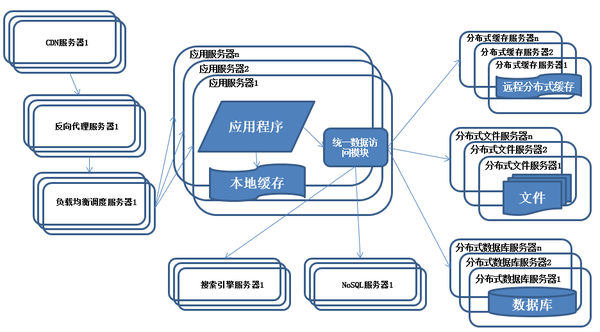
特徵:
系統引入NoSQL數據庫及搜索引擎。
描述:
隨着業務越來越複雜,對數據存儲和檢索的需求也越來越複雜,系統需要採用一些非關係型數據庫如NoSQL和分數據庫查詢技術如搜索引擎。應用服務器通過統一數據訪問模塊訪問各種數據,減輕應用程序管理諸多數據源的麻煩。