




此次的博文是轉載而來,寫得感覺不錯,詳細而易理解。
首先,我們需要知道TCP在網絡OSI的七層模型中的第四層——Transport層,IP在第三層——Network層,ARP在第二層——Data Link層,在第二層上的數據,我們叫Frame,在第三層上的數據叫Packet,第四層的數據叫Segment。
首先,我們需要知道,我們程序的數據首先會打到TCP的Segment中,然後TCP的Segment會打到IP的Packet中,然後再打到以太網Ethernet的Frame中,傳到對端後,各個層解析自己的協議,然後把數據交給更高層的協議處理。
TCP頭格式
接下來,我們來看一下TCP頭的格式
 TCP頭格式(圖片來源)
TCP頭格式(圖片來源)
你需要注意這麼幾點:
TCP的包是沒有IP地址的,那是IP層上的事。但是有源端口和目標端口。
一個TCP連接需要四個元組來表示是同一個連接(src_ip, src_port, dst_ip, dst_port)準確說是五元組,還有一個是協議。但因爲這裏只是說TCP協議,所以,這裏我只說四元組。
注意上圖中的四個非常重要的東西:
Sequence Number是包的序號,用來解決網絡包亂序(reordering)問題。
Acknowledgement Number就是ACK——用於確認收到,用來解決不丟包的問題。
Window又叫Advertised-Window,也就是著名的滑動窗口(Sliding Window),用於解決流控的。
TCP Flag ,也就是包的類型,主要是用於操控TCP的狀態機的。
關於其它的東西,可以參看下面的圖示

(圖片來源)
TCP的狀態機
其實,網絡上的傳輸是沒有連接的,包括TCP也是一樣的。而TCP所謂的“連接”,其實只不過是在通訊的雙方維護一個“連接狀態”,讓它看上去好像有連接一樣。所以,TCP的狀態變換是非常重要的。
下面是:“TCP協議的狀態機”(圖片來源) 和 “TCP建鏈接”、“TCP斷鏈接”、“傳數據” 的對照圖,我把兩個圖並排放在一起,這樣方便在你對照着看。另外,下面這兩個圖非常非常的重要,你一定要記牢。(吐個槽:看到這樣複雜的狀態機,就知道這個協議有多複雜,複雜的東西總是有很多坑爹的事情,所以TCP協議其實也挺坑爹的)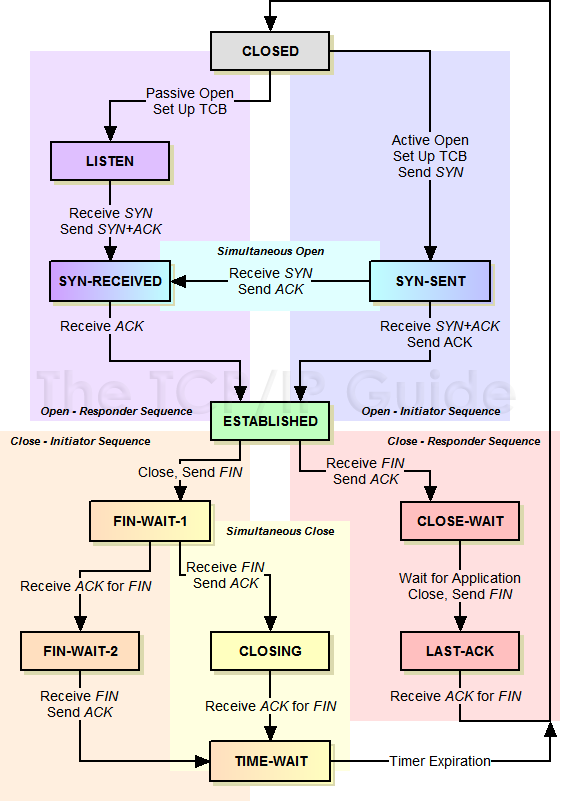

很多人會問,爲什麼建鏈接要3次握手,斷鏈接需要4次揮手?
對於建鏈接的3次握手,主要是要初始化Sequence Number 的初始值。通信的雙方要互相通知對方自己的初始化的Sequence Number(縮寫爲ISN:Inital Sequence Number)——所以叫SYN,全稱Synchronize Sequence Numbers。也就上圖中的 x 和 y。這個號要作爲以後的數據通信的序號,以保證應用層接收到的數據不會因爲網絡上的傳輸的問題而亂序(TCP會用這個序號來拼接數據)。
對於4次揮手,其實你仔細看是2次,因爲TCP是全雙工的,所以,發送方和接收方都需要Fin和Ack。只不 過,有一方是被動的,所以看上去就成了所謂的4次揮手。如果兩邊同時斷連接,那就會就進入到CLOSING狀態,然後到達TIME_WAIT狀態。下圖是 雙方同時斷連接的示意圖(你同樣可以對照着TCP狀態機看):

兩端同時斷連接(圖片來源)
另外,有幾個事情需要注意一下:
關於建連接時SYN超時。試想一下,如果server端接到了clien發的SYN後回了SYN-ACK後 client掉線了,server端沒有收到client回來的ACK,那麼,這個連接處於一箇中間狀態,即沒成功,也沒失敗。於是,server端如果 在一定時間內沒有收到的TCP會重發SYN-ACK。在Linux下,默認重試次數爲5次,重試的間隔時間從1s開始每次都翻售,5次的重試時間間隔爲 1s, 2s, 4s, 8s, 16s,總共31s,第5次發出後還要等32s都知道第5次也超時了,所以,總共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 2^6 -1 = 63s,TCP纔會把斷開這個連接。
關於SYN Flood***。一些惡意的人就爲此製造了SYN Flood***——給服務器發了一個SYN後,就下線了,於是服務器需要默認等63s纔會斷開連接,這樣,***者就可以把服務器的syn連接的隊列耗盡,讓正常的連接請求不能處理。於是,Linux下給了一個叫tcp_syncookies的 參數來應對這個事——當SYN隊列滿了後,TCP會通過源地址端口、目標地址端口和時間戳打造出一個特別的Sequence Number發回去(又叫cookie),如果是***者則不會有響應,如果是正常連接,則會把這個 SYN Cookie發回來,然後服務端可以通過cookie建連接(即使你不在SYN隊列中)。請注意,請先千萬別用tcp_syncookies來處理正常的大負載的連接的情況。 因爲,synccookies是妥協版的TCP協議,並不嚴謹。對於正常的請求,你應該調整三個TCP參數可供你選擇,第一個 是:tcp_synack_retries 可以用他來減少重試次數;第二個是:tcp_max_syn_backlog,可以增大SYN連接數;第三個 是:tcp_abort_on_overflow 處理不過來乾脆就直接拒絕連接了。
關於ISN的初始化。ISN是不能hard code的,不然會出問題的——比如:如果連接建好後始終用1來做ISN,如果client發了30個segment過去,但是網絡斷了,於是 client重連,又用了1做ISN,但是之前連接的那些包到了,於是就被當成了新連接的包,此時,client的Sequence Number 可能是3,而Server端認爲client端的這個號是30了。全亂了。RFC793中 說,ISN會和一個假的時鐘綁在一起,這個時鐘會在每4微秒對ISN做加一操作,直到超過2^32,又從0開始。這樣,一個ISN的週期大約是4.55個 小時。因爲,我們假設我們的TCP Segment在網絡上的存活時間不會超過Maximum Segment Lifetime(縮寫爲MSL - Wikipedia語條),所以,只要MSL的值小於4.55小時,那麼,我們就不會重用到ISN。
關於 MSL 和 TIME_WAIT。通過上面的ISN的描述,相信你也知道MSL是怎麼來的了。我們注意到,在TCP的狀態圖中,從TIME_WAIT狀態到CLOSED狀態,有一個超時設置,這個超時設置是 2*MSL(RFC793定 義了MSL爲2分鐘,Linux設置成了30s)爲什麼要這有TIME_WAIT?爲什麼不直接給轉成CLOSED狀態呢?主要有兩個原 因:1)TIME_WAIT確保有足夠的時間讓對端收到了ACK,如果被動關閉的那方沒有收到Ack,就會觸發被動端重發Fin,一來一去正好2個 MSL,2)有足夠的時間讓這個連接不會跟後面的連接混在一起(你要知道,有些自做主張的路由器會緩存IP數據包,如果連接被重用了,那麼這些延遲收到的 包就有可能會跟新連接混在一起)。你可以看看這篇文章《TIME_WAIT and its design implications for protocols and scalable client server systems》
關於TIME_WAIT數量太多。從上面的描述我們可以知道,TIME_WAIT是個很重要的狀態,但是如果在大併發的短鏈接下,TIME_WAIT 就會太多,這也會消耗很多系統資源。只要搜一下,你就會發現,十有八九的處理方式都是教你設置兩個參數,一個叫tcp_tw_reuse,另一個叫tcp_tw_recycle的參數,這兩個參數默認值都是被關閉的,後者recyle比前者resue更爲激進,resue要溫柔一些。另外,如果使用tcp_tw_reuse,必需設置tcp_timestamps=1,否則無效。這裏,你一定要注意,打開這兩個參數會有比較大的坑——可能會讓TCP連接出一些詭異的問題(因爲如上述一樣,如果不等待超時重用連接的話,新的連接可能會建不上。正如官方文檔上說的一樣“It should not be changed without advice/request of technical experts”)。
關於tcp_tw_reuse。官方文檔上說tcp_tw_reuse 加上tcp_timestamps(又叫PAWS, for Protection Against Wrapped Sequence Numbers)可以保證協議的角度上的安全,但是你需要tcp_timestamps在兩邊都被打開(你可以讀一下tcp_twsk_unique的源碼 )。我個人估計還是有一些場景會有問題。
關於tcp_tw_recycle。如果是tcp_tw_recycle被打開了話,會假設對端開啓了 tcp_timestamps,然後會去比較時間戳,如果時間戳變大了,就可以重用。但是,如果對端是一個NAT網絡的話(如:一個公司只用一個IP出公 網)或是對端的IP被另一臺重用了,這個事就複雜了。建鏈接的SYN可能就被直接丟掉了(你可能會看到connection time out的錯誤)(如果你想觀摩一下Linux的內核代碼,請參看源碼 tcp_timewait_state_process)。
關於tcp_max_tw_buckets。這個是控制併發的TIME_WAIT的數量,默認值是 180000,如果超限,那麼,系統會把多的給destory掉,然後在日誌裏打一個警告(如:time wait bucket table overflow),官網文檔說這個參數是用來對抗DDoS***的。也說的默認值180000並不小。這個還是需要根據實際情況考慮。
Again,使用tcp_tw_reuse和tcp_tw_recycle來解決TIME_WAIT的問題是非常非常危險的,因爲這兩個參數違反了TCP協議(RFC 1122)
其實,TIME_WAIT表示的是你主動斷連接,所以,這就是所謂的“不作死不會死”。試想,如果讓對端斷連接,那麼這個破問題就是對方的了,呵呵。另外,如果你的服務器是於HTTP服務器,那麼設置一個HTTP的KeepAlive有多重要(瀏覽器會重用一個TCP連接來處理多個HTTP請求),然後讓客戶端去斷鏈接(你要小心,瀏覽器可能會非常貪婪,他們不到萬不得已不會主動斷連接)。
數據傳輸中的Sequence Number
下圖是我從Wireshark中截了個我在訪問coolshell.cn時的有數據傳輸的圖給你看一下,SeqNum是怎麼變的。(使用Wireshark菜單中的Statistics ->Flow Graph… )

你可以看到,SeqNum的增加是和傳輸的字節數相關的。上圖中,三次握手後,來了兩個Len:1440的包,而第二個包的SeqNum就成了1441。然後第一個ACK回的是1441,表示第一個1440收到了。
注意:如果你用Wireshark抓包程序看3次握手,你會發現SeqNum總是爲0,不是這樣 的,Wireshark爲了顯示更友好,使用了Relative SeqNum——相對序號,你只要在右鍵菜單中的protocol preference 中取消掉就可以看到“Absolute SeqNum”了
TCP重傳機制
TCP要保證所有的數據包都可以到達,所以,必需要有重傳機制。
注意,接收端給發送端的Ack確認只會確認最後一個連續的包,比如,發送端發了1,2,3,4,5一共五份數據,接收端收到了1,2,於是回ack 3,然後收到了4(注意此時3沒收到),此時的TCP會怎麼辦?我們要知道,因爲正如前面所說的,SeqNum和Ack是以字節數爲單位,所以ack的時候,不能跳着確認,只能確認最大的連續收到的包,不然,發送端就以爲之前的都收到了。
超時重傳機制
一種是不回ack,死等3,當發送方發現收不到3的ack超時後,會重傳3。一旦接收方收到3後,會ack 回 4——意味着3和4都收到了。
但是,這種方式會有比較嚴重的問題,那就是因爲要死等3,所以會導致4和5即便已經收到了,而發送方也完全不知道發生了什麼事,因爲沒有收到Ack,所以,發送方可能會悲觀地認爲也丟了,所以有可能也會導致4和5的重傳。
對此有兩種選擇:
一種是僅重傳timeout的包。也就是第3份數據。
另一種是重傳timeout後所有的數據,也就是第3,4,5這三份數據。
這兩種方式有好也有不好。第一種會節省帶寬,但是慢,第二種會快一點,但是會浪費帶寬,也可能會有無用功。但總體來說都不好。因爲都在等timeout,timeout可能會很長(在下篇會說TCP是怎麼動態地計算出timeout的)
快速重傳機制
於是,TCP引入了一種叫Fast Retransmit 的算法,不以時間驅動,而以數據驅動重傳。也就是說,如果,包沒有連續到達,就ack最後那個可能被丟了的包,如果發送方連續收到3次相同的ack,就重傳。Fast Retransmit的好處是不用等timeout了再重傳。
比如:如果發送方發出了1,2,3,4,5份數據,第一份先到送了,於是就ack回2,結果2因爲某些原因沒收到,3到達了,於是還是ack回 2,後面的4和5都到了,但是還是ack回2,因爲2還是沒有收到,於是發送端收到了三個ack=2的確認,知道了2還沒有到,於是就馬上重轉2。然後, 接收端收到了2,此時因爲3,4,5都收到了,於是ack回6。示意圖如下:

Fast Retransmit只解決了一個問題,就是timeout的問題,它依然面臨一個艱難的選擇,就是重轉之前的一個還是重裝所有的問 題。對於上面的示例來說,是重傳#2呢還是重傳#2,#3,#4,#5呢?因爲發送端並不清楚這連續的3個ack(2)是誰傳回來的?也許發送端發了20 份數據,是#6,#10,#20傳來的呢。這樣,發送端很有可能要重傳從2到20的這堆數據(這就是某些TCP的實際的實現)。可見,這是一把雙刃劍。
SACK 方法
另外一種更好的方式叫:Selective Acknowledgment (SACK)(參看RFC 2018),這種方式需要在TCP頭裏加一個SACK的東西,ACK還是Fast Retransmit的ACK,SACK則是彙報收到的數據碎版。參看下圖:

這樣,在發送端就可以根據回傳的SACK來知道哪些數據到了,哪些沒有到。於是就優化了Fast Retransmit的算法。當然,這個協議需要兩邊都支持。在 Linux下,可以通過tcp_sack參數打開這個功能(Linux 2.4後默認打開)。
這裏還需要注意一個問題——接收方Reneging,所謂Reneging的意思就是接收方有權把已經報給發送端SACK裏的數據給丟了。這樣幹是不被鼓勵的,因爲這個事會把問題複雜化了,但是,接收方這麼做可能會有些極端情況,比如要把內存給別的更重要的東西。所以,發送方也不能完全依賴SACK,還是要依賴ACK,並維護Time-Out,如果後續的ACK沒有增長,那麼還是要把SACK的東西重傳,另外,接收端這邊永遠不能把SACK的包標記爲Ack。
注意:SACK會消費發送方的資源,試想,如果一個***者給數據發送方發一堆SACK的選項,這會導致發送方開始要重傳甚至遍歷已經發出的數據,這會消耗很多發送端的資源。詳細的東西請參看《TCP SACK的性能權衡》
Duplicate SACK – 重複收到數據的問題
Duplicate SACK又稱D-SACK,其主要使用了SACK來告訴發送方有哪些數據被重複接收了。RFC-2833裏有詳細描述和示例。下面舉幾個例子(來源於RFC-2833)
D-SACK使用了SACK的第一個段來做標誌,
如果SACK的第一個段的範圍被ACK所覆蓋,那麼就是D-SACK
如果SACK的第一個段的範圍被SACK的第二個段覆蓋,那麼就是D-SACK
示例一:ACK丟包
下面的示例中,丟了兩個ACK,所以,發送端重傳了第一個數據包(3000-3499),於是接收端發現重複收到,於是回了一個 SACK=3000-3500,因爲ACK都到了4000意味着收到了4000之前的所有數據,所以這個SACK就是D-SACK——旨在告訴發送端我收 到了重複的數據,而且我們的發送端還知道,數據包沒有丟,丟的是ACK包。
Transmitted Received ACK Sent Segment Segment (Including SACK Blocks)3000-3499 3000-3499 3500 (ACK dropped)3500-3999 3500-3999 4000 (ACK dropped)3000-3499 3000-3499 4000, SACK=3000-3500 ---------
示例二,網絡延誤
下面的示例中,網絡包(1000-1499)被網絡給延誤了,導致發送方沒有收到ACK,而後面到達的三個包觸發了“Fast Retransmit算法”,所以重傳,但重傳時,被延誤的包又到了,所以,回了一個SACK=1000-1500,因爲ACK已到了3000,所以,這 個SACK是D-SACK——標識收到了重複的包。
這個案例下,發送端知道之前因爲“Fast Retransmit算法”觸發的重傳不是因爲發出去的包丟了,也不是因爲迴應的ACK包丟了,而是因爲網絡延時了。
Transmitted Received ACK Sent Segment Segment (Including SACK Blocks)500-999 500-999 10001000-1499 (delayed)1500-1999 1500-1999 1000, SACK=1500-20002000-2499 2000-2499 1000, SACK=1500-25002500-2999 2500-2999 1000, SACK=1500-30001000-1499 1000-1499 3000 1000-1499 3000, SACK=1000-1500 ---------
可見,引入了D-SACK,有這麼幾個好處:
1)可以讓發送方知道,是發出去的包丟了,還是回來的ACK包丟了。
2)是不是自己的timeout太小了,導致重傳。
3)網絡上出現了先發的包後到的情況(又稱reordering)
4)網絡上是不是把我的數據包給複製了。
知道這些東西可以很好得幫助TCP瞭解網絡情況,從而可以更好的做網絡上的流控。
轉自:http://kb.cnblogs.com/page/209100/