




一、摘要
隨着互聯網的高速發展,數據量爆發式增長的同時,數據的存儲形式也開始呈現出多樣性,有結構化存儲,如 Mysql, Oracle, SQLServer 等,半結構化甚至非結構化存儲,如HBase,OSS 等。那麼從事數據分析的人員就面臨着從多種多樣的數據存儲形式中提取數據而後進行多維分析,這將是一件非常具有挑戰的事情。而Quick BI 作爲新一代智能BI服務平臺,恰好解決了這一難題,不僅支持多種結構化數據源的多維分析,也支持本地文件上傳後的查詢分析,同時還支持部分非結構化數據源的OLAP分析,甚至支持混合異構數據源的關聯分析。
Quick BI 目前支持的數據源既可以來自阿里雲數據庫,也可以來自自建數據庫,如下所示:



二、結構化數據源多維分析
對於一般的數據源,用戶在做多維分析之前需要先在Quick BI 數據源界面添加自己的數據源,比如MySQL數據源,如下:
數據源添加完成後,可以選擇一張或多張要進行分析的數據表創建一個數據集,如下:
數據集創建完成後用戶就可以在儀表板裏拖拽維度和度量進行多維分析了,比如:
結構化數據源的多維分析相對比較簡單,大致過程就是針對每次多維分析查詢,根據用戶選擇的維度,度量及過濾條件等查詢因子,生成相應結構化數據源的方言SQL,然後通過執行機下發到用戶自己的數據庫去執行該SQL,最後Quick BI接收返回的查詢結果進行可視化展現。下圖展示了多維分析的流程圖: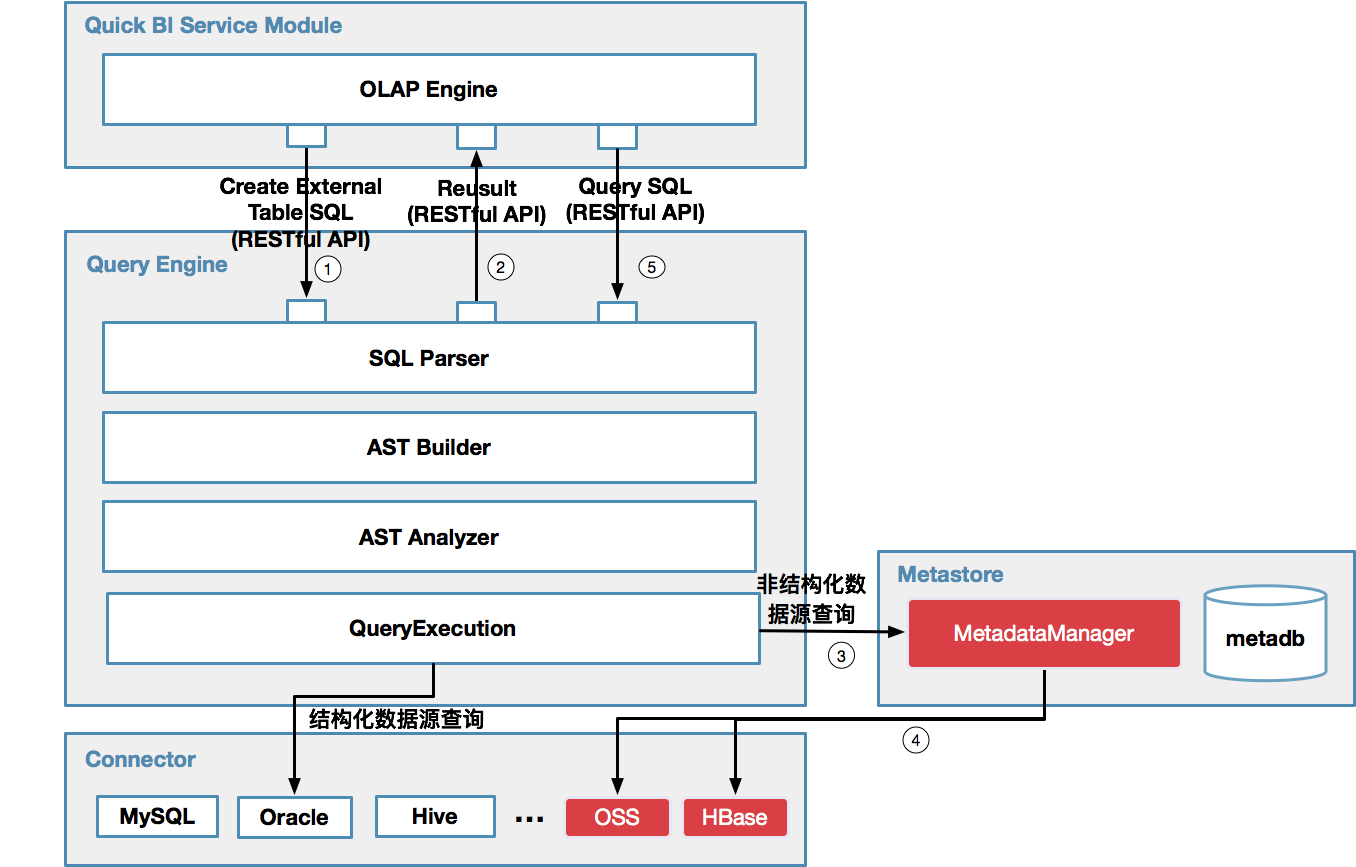
順便介紹一下,本地文件上傳支持csv 和Excel 兩種文件類型。上傳後的文件會落地到Quick BI提供的一種官方數據源:探索空間。探索空間底層依賴了一種阿里雲自研的MPP SQL引擎,提供存儲+計算服務。
接下來的篇幅將着重介紹非結構化查詢分析及混合異構數據源關聯分析的原理。
三、非結構化數據源查詢分析
3.1 背景
近年來部分大型企業更傾向於採用諸如半結構化存儲(HBase),對象存儲(OSS)等能容納較大數據規模的數據庫。如何有效地幫助企業對此類數據源進行多維數據分析是目前業界BI產品的一項挑戰。
在開源的數據庫產品當中,存在着一些潛在的解決方案。例如,針對HDFS數據的查詢,Hive設計了metastore組件,專門用於存儲元數據,解決了從結構化查詢到非結構化數據之間的映射關係,用戶通過使用創建外部表SQL的語法,可以更靈活地自定義映射的方式。另外,Apache Phoenix也採取了類似的方式讓用戶能夠使用SQL語句對HBase中的數據進行查詢。經過充分調研後,針對Quick BI產品自身的業務場景,結合開源計算引擎二次開發了一套用於非結構化查詢的分析引擎。
3.2 技術原理
對非結構化數據源進行OLAP查詢,其關鍵在於支持SQL語法形式的數據查詢。Quick BI在OLAP引擎內部採用創建外部表的SQL語法,給用戶提供了一種自定義的,從非結構化數據到結構化存儲的映射方式。對於諸如MySQL、Oracle等結構化的數據源而言,無須額外的元數據信息,而對於非結構化的數據源,需要提供額外的元數據信息。Metastore維護了所有非結構化數據源的元數據信息,元數據信息中反映了非結構化數據到結構化之間的映射方式。Metadb中包含了3張表,用於定義可以被SQL查詢所需要的元數據信息,如下圖所示: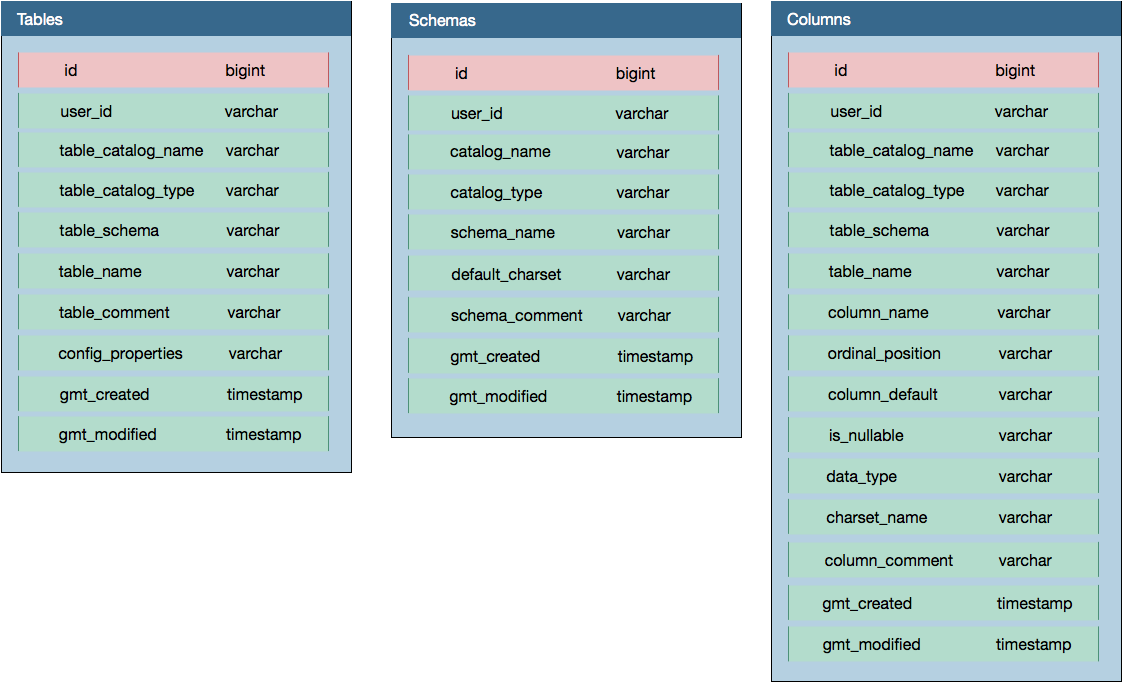
Schems、Tables和Columns分別定義了外部表的結構,通過SQL創建外部表時,在其中加入相應的記錄。查詢非結構化數據源時,再讀取相應的記錄,對數據進行解析。
下面以一個場景作爲例子,進一步地說明非結構化查詢的過程,假設用戶以CSV文件的形式將業務數據存儲在OSS上,文件的名稱爲iris.csv,其內容如下所示: 
針對這個文件,用戶期望利用Quick BI對其進行OLAP查詢,根據用戶在Quick BI數據源頁面中的配置,OLAP內部生成一條創建外部表的SQL語句:
SQL Parser對SQL進行解析,AST Builder生成對應的AST,如下圖所示: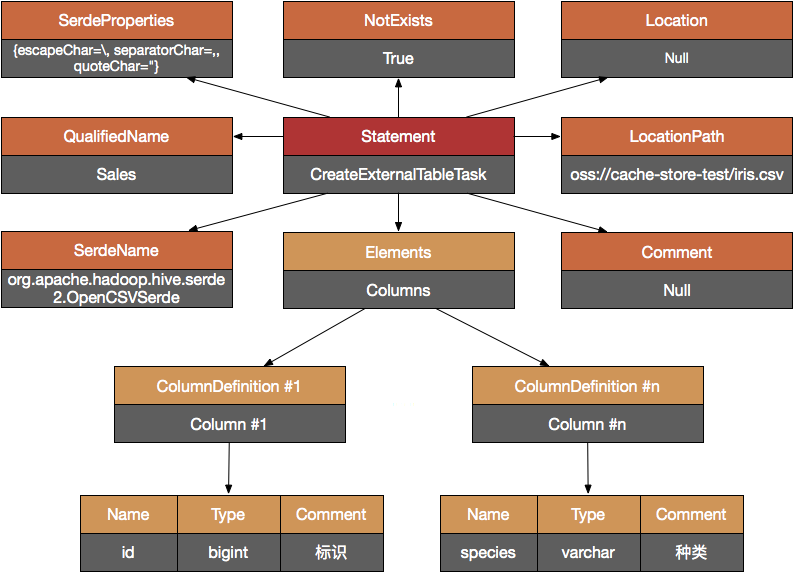
注意到該AST包含了外部表所需的全部信息,包括如何解析csv文件並映射成結構化的數據,使得數據能夠與SQL中的schema、column和table對應。Query Execution調用Metastore將信息存儲至Meatadb。此時,存儲再OSS上的CSV文件在邏輯上已經映射成了一張表,如下圖所示:

下一步便可以直接使用SQL對其進行查詢,例如,使用下面的SQL篩選出種類(species)爲setosa的數據記錄;
同理,對於HBase數據源,同樣採用外部表的方式定義映射規則: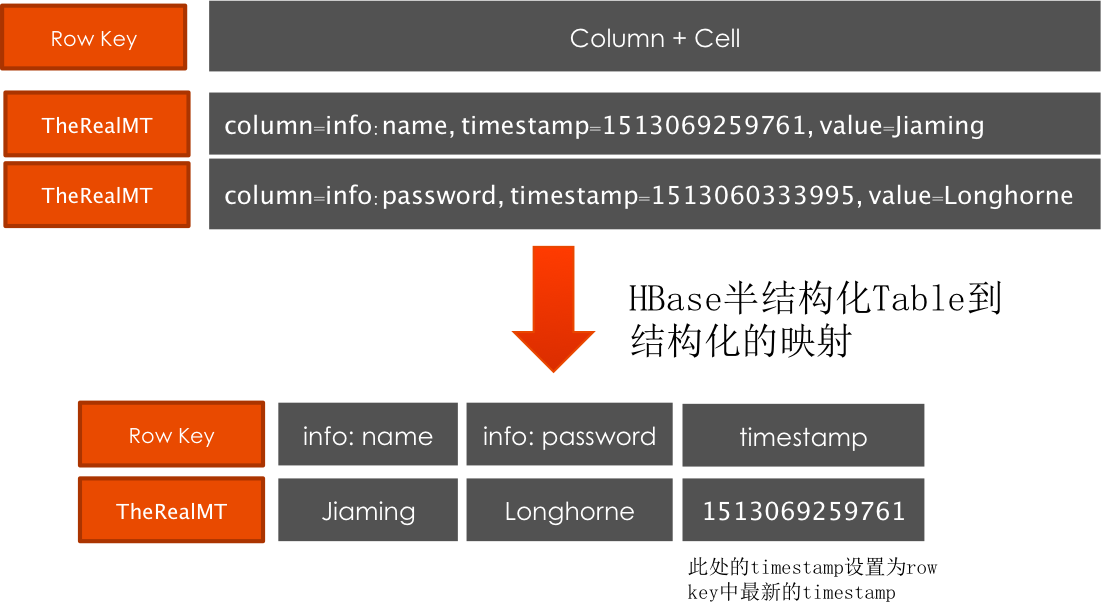
3.3 小結
Quick BI 目前支持對OSS上的csv 文件進行查詢分析,後續會增加支持OSS上更多文件類型的查詢分析,及對HBase的多維分析。
四、混合異構數據源關聯分析
4.1 背景
Quick BI用戶對異構數據源的分析需求,如:維表在MySQL,事實表在MaxCompute時,需要進行不同類型數據源間或相同類型數據源不同庫間表的關聯分析。
4.2 技術原理
要能夠支持異構數據源間的跨源關聯分析,首先需要有一款具備數據源Connector 插件機制的計算引擎,這樣就能夠方便擴展支持多種數據源類型查詢。我們從業界開源計算引擎中選擇了一款具備這樣特性的MPP內存計算引擎,經過二次開發,形成了一套適合Quick BI業務場景的跨源查詢引擎。
跨源查詢引擎在支持異構數據源查詢時,只需在查詢SQL中使用完整的catalogName.dbName.tableName表名(如:odps.quickbi_test.company_sales_record),
在Quick BI業務中用戶自己配置的每個數據源在後臺都會配一個唯一標識dsId, 所以剛好可以用來作爲catalogName, 且涉及到的Catalog在跨源查詢引擎中已經被加載即可。之後在查詢時,跨源查詢引擎會解析SQL,生成邏輯計劃、物理計劃,再通過Catalog的配置到指定數據源加載數據,在內存中進行計算並返回最終結果。
大部分多維分析都是單源查詢,那麼在什麼情況下才會啓用跨源查詢引擎呢,這就需要實現異構數據源查詢的智能路由,智能路由主要是根據查詢模型中涵蓋的數據源信息來判斷是單源查詢還是多源查詢來決定路由到單源查詢引擎還是跨源查詢引擎。跨源查詢流程如下圖所示:
注意要確保本次查詢所涉及到的catalogs 向跨源查詢引擎的CatalogServer 動態註冊成功後,才能下發本次查詢的SQLText到跨源查詢引擎。
示例:MaxCompute, MySQL 間的異構查詢SQL:
查詢結果: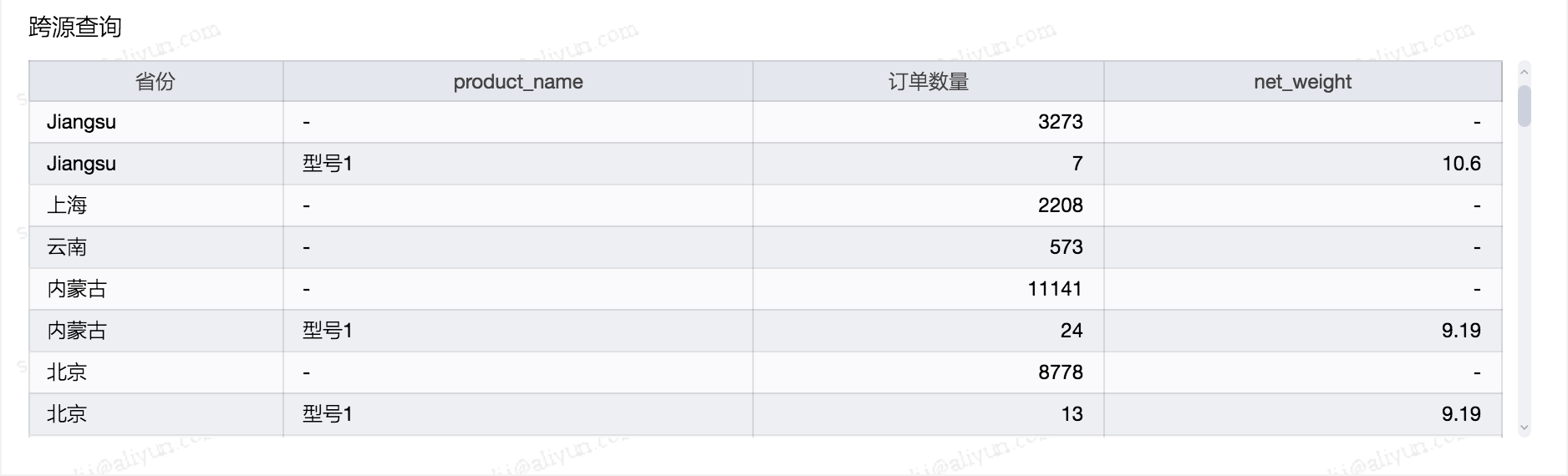
4.3 小結
異構數據源分析功能對用戶是透明無感知的,歡迎前往Quick BI體驗。用戶只需在數據集關聯時選用來源於不同庫的數據表,就可輕鬆體驗異構數據源分析功能,目前支持MaxCompute、MySQL、Oracle間的異構數據源查詢或同構數據源跨庫查詢。後續會支持更多類型數據源異構查詢,如 Hive, SQLServer, PostgresSql 等。
五、未完待續
Quick BI 後續將會迭代更新逐步支持更多類型數據源的多維分析,如API類數據源等,敬請期待…
作者:薩若 衣候