Spark是基於內存的大數據綜合處理引擎,具有優秀的作業調度機制和快速的分佈式計算能力,使其能夠更加高效地進行迭代計算,因此Spark能夠在一定程度上實現大數據的流式處理。
隨着信息技術的迅猛發展,數據量呈現出爆炸式增長趨勢,數據的種類與變化速度也遠遠超出人們的想象,因此人們對大數據處理提出了更高的要求,越來越多的領域迫切需要大數據技術來解決領域內的關鍵問題。在一些特定的領域中(例如金融、災害預警等),時間就是金錢、時間可能就是生命!然而傳統的批處理框架卻一直難以滿足這些領域中的實時性需求。爲此,涌現出了一批如S4、Storm的流式計算框架。Spark是基於內存的大數據綜合處理引擎,具有優秀的作業調度機制和快速的分佈式計算能力,使其能夠更加高效地進行迭代計算,因此Spark能夠在一定程度上實現大數據的流式處理。
Spark Streaming是Spark上的一個流式處理框架,可以面向海量數據實現高吞吐量、高容錯的實時計算。Spark Streaming支持多種類型數據源,包括Kafka、Flume、trwitter、zeroMQ、Kinesis以及TCP sockets等,如圖1所示。Spark Streaming實時接收數據流,並按照一定的時間間隔將連續的數據流拆分成一批批離散的數據集;然後應用諸如map、reducluce、join和window等豐富的API進行復雜的數據處理;最後提交給Spark引擎進行運算,得到批量結果數據,因此其也被稱爲準實時處理系統。
圖1 Spark Streaming支持多種類型數據源
目前應用最廣泛的×××式處理框架是Storm。Spark Streaming 最低0.5~2s做一次處理(而Storm最快可達0.1s),在實時性和容錯方面不如Storm。然而Spark Streaming的集成性非常好,通過RDD不僅能夠與Spark上的所有組件無縫銜接共享數據,還能非常容易地與Kafka、Flume等分佈式日誌收集框架進行集成;同時Spark Streaming的吞吐量非常高,遠遠優於Storm的吞吐量,如圖2所示。所以雖然Spark Streaming的處理延遲高於Storm,但是在集成性與吞吐量方面的優勢使其更適用於大數據背景。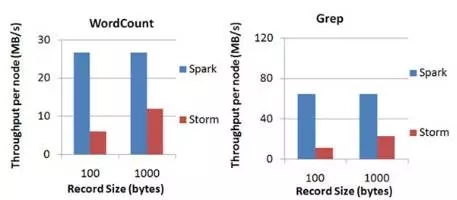
Spark Streaming基礎概念
批處理時間間隔
在Spark Streaming中,對數據的採集是實時、逐條進行的,但是對數據的處理卻是分批進行的。因此,Spark Streaming需要設定一個時間間隔,將該時間間隔內採集到的數據統一進行處理,這個間隔稱爲批處理時間間隔。
也就是說對於源源不斷的數據,Spark Streaming是通過切分的方式,先將連續的數據流進行離散化處理。數據流每被切分一次,對應生成一個RDD,每個RDD都包含了一個時間間隔內所獲取到的所有數據,因此數據流被轉換爲由若干個RDD構成的有序集合,而批處理時間間隔決定了Spark Streaming需要多久對數據流切分一次。Spark Streaming是Spark上的組件,其獲取的數據和數據上的操作最終仍以Spark作業的形式在底層的Spark內核中進行計算,因此批處理時間間隔不僅影響數據處理的吞吐量,同時也決定了Spark Streaming向Spark提交作業的頻率和數據處理的延遲。需要注意的是,批處理時間間隔的設置會伴隨Spark Streaming應用程序的整個生命週期,無法在程序運行期間動態修改,所以需要綜合考慮實際應用場景中的數據流特點和集羣的處理性能等多種因素進行設定。
窗口時間間隔
窗口時間間隔又稱爲窗口長度,它是一個抽象的時間概念,決定了Spark Streaming對RDD序列進行處理的範圍與粒度,即用戶可以通過設置窗口長度來對一定時間範圍內的數據進行統計和分析。如果設批處理時間設爲1s,窗口時間間隔爲3s,如3圖所示,其中每個實心矩形表示Spark Streaming每1秒鐘切分出的一個RDD,若干個實心矩形塊表示一個以時間爲序的RDD序列,而透明矩形框表示窗口時間間隔。易知窗口內RDD的數量最多爲3個,即Spark Streming 每次最多對3個RDD中的數據進行統計和分析。對於窗口時間間隔還需要注意以下幾點:
以圖3爲例,在系統啓動後的前3s內,因進入窗口的RDD不足3個,但是隨着時間的推移,最終窗口將被填滿。
不同窗口內所包含的RDD可能會有重疊,即當前窗口內的數據可能被其後續若干個窗口所包含,因此在一些應用場景中,對於已經處理過的數據不能立即刪除,以備後續計算使用。
窗口時間間隔必須是批處理時間間隔的整數倍。
圖3 窗口時間間隔示意圖
滑動時間間隔
滑動時間間隔決定了Spark Streaming對數據進行統計與分析的頻率,多出現在與窗口相關的操作中。滑動時間間隔是基於批處理時間間隔提出的,其必須是批處理時間間隔的整數倍。在默認的情況下滑動時間間隔設置爲與批處理時間間隔相同的值。如果批處理時間間隔爲1s,窗口間隔爲3s,滑動時間間隔爲2s,如圖4所示,其含義是每隔2s對過去3s內產生的3個RDD進行統計分析。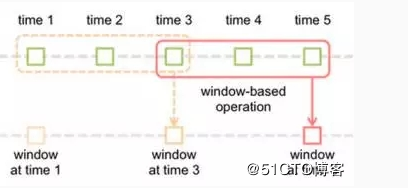
圖4 滑動時間間隔、窗口時間間隔、批處理時間間隔綜合示意圖
DStream基本概念
DStream是Spark Streaming的一個基本抽象,它以離散化的RDD序列的形式近似描述了連續的數據流。DStream本質上是一個以時間爲鍵,RDD爲值的哈希表,保存了按時間順序產生的RDD,而每個RDD封裝了批處理時間間隔內獲取到的數據。Spark Streaming每次將新產生的RDD添加到哈希表中,而對於已經不再需要的RDD則會從這個哈希表中刪除,所以DStream也可以簡單地理解爲以時間爲鍵的RDD的動態序列。設批處理時間間隔爲1s,圖5爲4s內產生的DStream示意圖。
Spark Streaming編程模式與案例分析
Spark Streaming編程模式
下面以Spark Streaming官方提供的WordCount代碼爲例來介紹Spark Streaming的使用方式。
示例1:
Spark Streaming應用程序在功能結構上通常包含以下五部分,如上述示例1所示。
導入Spark Streaming相關包:Spark Streaming作爲Spark框架上的一個組件,具有很好的集成性。在開發Spark Streaming應用程序時,只需導入Spark Streaming相關包,無需額外的參數配置。
創建StreamingContext對象:同Spark應用程序中的SparkContext對象一樣, StreamingContext對象是Spark Streaming應用程序與集羣進行交互的唯一通道,其中封裝了Spark集羣的環境信息和應用程序的一些屬性信息。在該對象中通常需要指明應用程序的運行模式(示例1中設爲local[2])、設定應用程序名稱(示例1中設爲NetworkWordCount)、設定批處理時間間隔(示例1中設爲Seconds(1)即1秒鐘),其中批處理時間間隔需要根據用戶的需求和集羣的處理能力進行適當地設置。
創建InputDStream:Spark Streaming需要根據數據源類型選擇相應的創建DStream的方法。示例1中Spark Streaming通過StreamingContext對象調用socketTextStream方法處理以socket連接類型數據源,創建出DStream即lines。Spark Streaming同時支持多種不同的數據源類型,其中包括Kafka、Flume、HDFS/S3、Kinesis和Twitter等數據源。
操作DStream:對於從數據源得到的DStream,用戶可以調用豐富的操作對其進行處理。示例1中針對lines的一系列操作就是一個典型的WordCount執行流程:對於當前批處理時間間隔內的文本數據以空格進行切分,進而得到words;再將words中每個單詞轉換爲二元組,進而得到pairs;最後利用reduceByKey方法進行統計。
啓動與停止Spark Streaming應用程序:在啓動Spark Streaming應用程序之前,DStream上所有的操作僅僅是定義了數據的處理流程,程序並沒有真正連接上數據源,也沒有對數據進行任何操作,當ssc.start()啓動後程序中定義的操作纔會真正開始執行。
文本文件數據處理案例
功能需求
實時監聽並獲取本地home/dong/Streamingtext目錄中新生成的文件(文件均爲英文文本文件,單詞之間使用空格進行間隔),並對文件中各單詞出現的次數進行統計。
代碼實現
運行演示
第1步,啓動Hadoop與Spark。
第2步,創建Streaming監控目錄。
在dong用戶主目錄下創建Streamingtext爲Spark Streaming監控的目錄,創建後如圖6所示。
圖6 dong用戶主目錄下創建Streamingtext文件夾
第3步,在IntelliJ IDEA中編輯運行Streaming程序。在IntelliJ IDEA中創建工程StreamingFileWordCount,編輯對象StreamingFileWordCount,如圖7所示。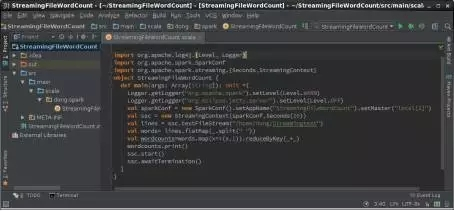
圖7 IntelliJ IDEA中StreamingFileWordCount示意圖
由於該示例沒有輸入參數,因此不需要配置參數,可直接單擊右鍵->單擊"Run‘StreamingFileWordCount’ "。
第4步,在監聽目錄下創建文本文件。在master節點上的/home/dong/Streamingtext中分別創建file1.txt與file2.txt。
file1.txt內容如下:
file2.txt內容如下:
創建後,/home/dong/Streamingtext中內容如圖8所示。
圖8 Streamingtext文件夾內容示意圖
查看結果
終端窗口輸出了每個批處理時間間隔(20秒)內,/home/dong/Streamingtext中新生成文件所包含的各單詞個數,如圖9所示。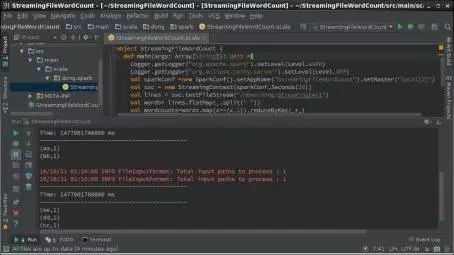
圖9 StreamingFileWordCount運行結果示意圖
網絡數據處理案例
功能需求
監聽本地節點指定端口傳輸的數據流(本案例爲master節點9999端口的英文文本數據,以逗號間隔單詞),每5秒統計一次該時間間隔內收集到的各單詞的個數。
代碼實現
本案例涉及數據流模擬器和分析器兩部分。爲了更接近真實的網絡環境,首先定義數據流模擬器,該模擬器以Socket方式監聽網絡中指定節點上的指定端口號(master節點9999端口),當外部程序通過該端口連接並請求數據時,數據流模擬器將定時地從指定文本文件中隨機選取數據發送至指定端口(每間隔1秒鐘數據流模擬器從master節點上的/home/dong/Streamingtext/file1.txt中隨機截取一行文本發送給master節點的9999端口),通過這種方式模擬網絡環境下源源不斷的數據流。針對獲取到的實時數據,再定義分析器(Spark Streaming應用程序),用以統計時間間隔(5秒)內收集到的單詞個數。
數據流模擬器代碼實現如下:
分析器代碼如下:
運行演示
第1步,在IntelliJ IDEA中編輯運行Streaming程序。master節點啓動IntelliJ IDEA,創建工程NetworkWordCount,編輯模擬器與分析器。模擬器如圖10所示,分析器如圖11所示。
圖10 IntelliJ IDEA中數據流模擬器示意圖
圖11 IntelliJ IDEA中分析器示意圖
第2步,創建模擬器數據源文件。在master節點創建/home/dong/Streamingtext目錄,在其中創建文本文件file1.txt。
file1.txt內容如下:
第3步,打包數據流模擬器。打包過程詳見本書4.3.3節。在Artifacts打包配置界面中,根據用戶實際scala安裝目錄,在Class Path中添加下述scala依賴包,如圖12所示。

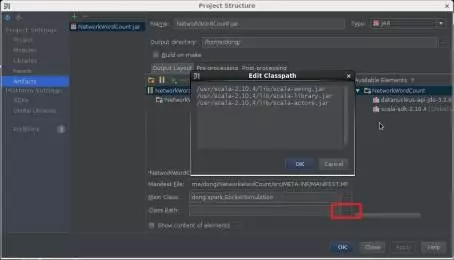
圖12 在Class Path中添加scala依賴包
打包後在主目錄下生成NetworkWordCount.jar,如圖13所示。
圖13 在dong用戶主目錄下生成NetworkWordCount.jar示意圖
第4步,啓動數據流模擬器。在master節點開啓控制終端,通過下面代碼啓動數據流模擬器。
數據流模擬器每間隔1000毫秒從/home/dong/Streamingtext/file1.txt中隨機截取一行文本發送給master節點的9999端口。在分析器未連接時,數據流模擬器處於阻塞狀態,終端不會顯示輸出的文本。
第5步,運行分析器。在master上啓動IntelliJ IDEA編寫分析器代碼,然後單擊菜單"Build->"Build Artifacts",通過Application選項配置分析器運行所需的參數,其中Socket主機名爲master、端口號爲9999,參數之間用空格間隔,如圖13所示。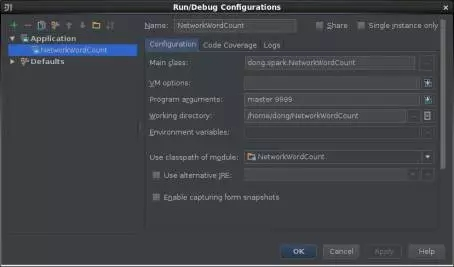
圖13 分析器參數配置示意圖
配置好參數後返回IntelliJ IDEA菜單欄,單擊"Run"->"Build Artifacts"運行分析器。
查看結果
第1步,在master上查看數據流模擬器運行情況。IntelliJ IDEA運行分析器從而與數據流模擬器建立連接。當檢測到外部連接時,數據流模擬器將每隔1000毫秒從/home/dong/Streamingtext/file1.txt中隨機截取一行文本發送給master節點上的9999端口。爲方便講解和說明,file1.txt中每一行只包含一個單詞,因此數據流模擬器每次僅發送一個單詞給端口,如圖14所示。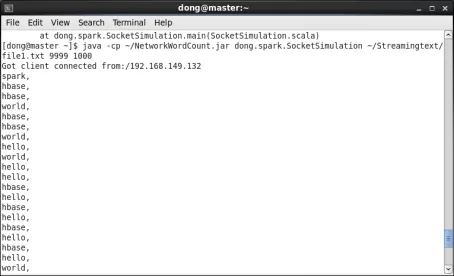
圖14 在master上模擬器運行結果
第2步,在master的IntelliJ IDEA中查看分析器運行情況。在IntelliJ IDEA的運行日誌窗口中,可以觀察到統計結果。通過分析可知Spark Streaming每個批處理時間間隔內獲取的單詞數爲5,剛好是5秒內發送單詞的總數,並對各單詞進行了統計,如圖15所示。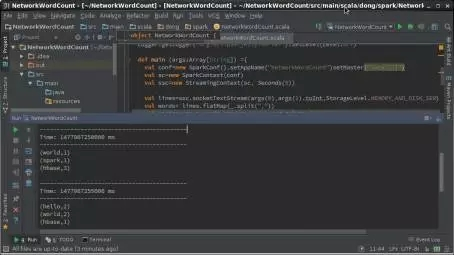
stateful應用案例
在很多數據流相關的實際應用場景中,對當前數據的統計分析需要藉助於先前的數據處理結果完成。例如電商每間隔10分鐘統計某一商品當前累計銷售總額、車站每隔3小時統計當前客流總量,等等。此類應用需求可藉助於Spark Streaming的有狀態轉換操作實現。
功能需求
監聽網絡中某節點上指定端口傳輸的數據流(slave1節點9999端口的英文文本數據,以逗號間隔單詞),每5秒分別統計各單詞的累計出現次數。
代碼實現
本案例功能的實現涉及數據流模擬器和分析器兩部分。
分析器代碼:

運行演示
第1步,slave1節點啓動數據流模擬器。
第2步,打包分析器。master節點啓動IntelliJ IDEA創建工程StatefulWordCount編輯分析器,如圖16所示,並將分析器直接打包至master節點dong用戶的主目錄下,如圖17所示。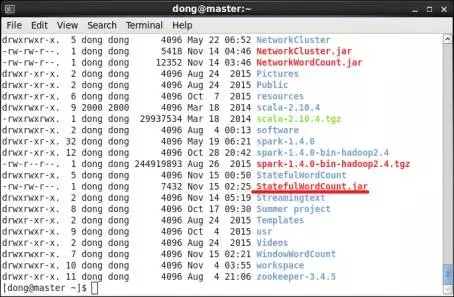
圖16 IntelliJ IDEA中StatefulWordCount示意圖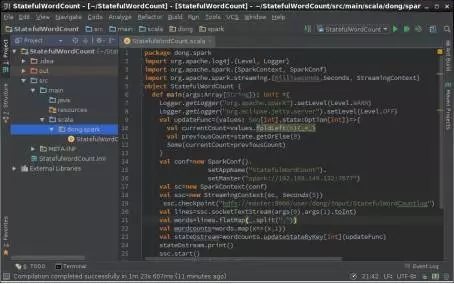
圖17 master上的StatefulWordCount.jar示意圖
第3步,運行分析器。在master節點開啓終端,通過下面代碼向Spark集羣提交應用程序。
查看結果
第1步,查看slave1上數據流模擬器運行情況。分析器在集羣上提交運行後與slave1上運行的數據流模擬器建立連接。當檢測到外部連接時,數據流模擬器將每隔1000毫秒從/home/dong/Streamingtext/file1.txt中隨機截取一行文本發送給slave1節點上的9999端口。由於該文本文件中每一行只包含一個單詞,因此每秒僅發送一個單詞給端口。如圖18所示。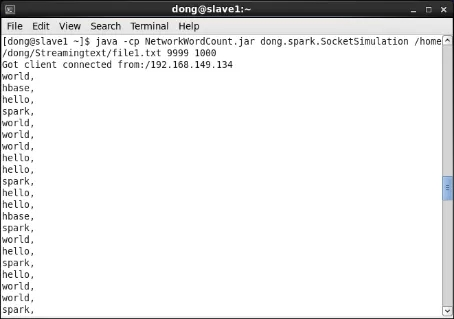
圖18 slave1上數據流模擬器運行示意圖
第2步,查看master上分析器運行情況。在master節點的提交窗口中可以查看到統計結果,如圖19所示。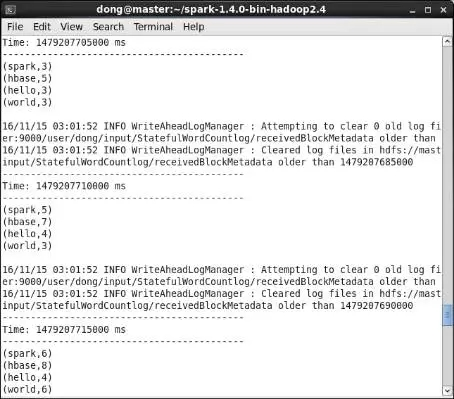
圖19 master上分析器運行示意圖
圖中表明截至147920770500ms分析器共接收到14個單詞,其中"spark"累計出現3次,"hbase"累計出現5次,"hello"累計出現3次,"world"累計出現3次。由於批處理時間間隔是5s,模擬器每1秒發送1個單詞,使得分析器在5s內共接收到5個單詞,因此截止至147920771000ms,分析器共收到19個單詞,其中"spark"累計出現5次,"hbase"累計出現7次,"hello"累計出現4次,"world"累計出現3次。
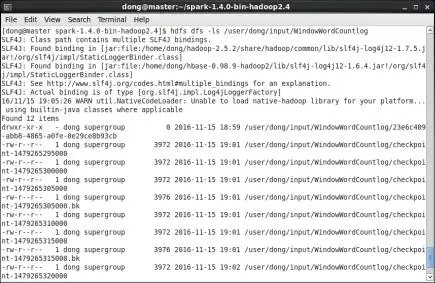
第3步,查看HDFS中持久化目錄。運行後查看HDFS上的持久化目錄/user/dong/input/StatefulWordCountlog,如圖20所示。Streaming應用程序將接收到的網絡數據持久化至該目錄下,便於容錯處理。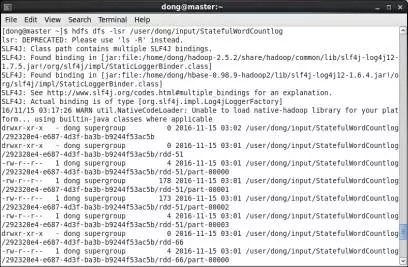
圖20 HDFS上持久化目錄示意圖
window應用案例
在實際生產環境中,與窗口相關的應用場景很常見,例如電商每間隔10分鐘小時統計某一商品前30分鐘內累計銷售總額、車站每隔1小時統計前3個小時內的客流量等,此類需求可藉助Spark Streaming中的window相關操作實現。window應用案例同時涉及批處理時間間隔、窗口時間間隔與滑動時間間隔。
功能需求
監聽網絡中某節點上指定端口傳輸的數據流(slave1節點上9999端口的英文文本數據,以逗號間隔單詞),每10秒統計前30秒各單詞累計出現的次數。
代碼實現
本例功能的實現涉及數據流模擬器和分析器兩部分。
分析器代碼:
運行演示 第1步,slave1節點啓動數據流模擬器。 第2步,打包分析器。在master節點啓動IntelliJ IDEA創建工程WindowWordCount編輯分析器,如圖21,並將分析器直接打包至master節點dong用戶的主目錄下,如圖22所示。
圖21 IntelliJ IDEA中WindowWordCount示意圖
圖22 master上WindowWordCount.jar示意圖
第3步,運行分析器。在master節點開啓終端,通過下面代碼向Spark集羣提交應用程序。
查看結果
第1步 在slave1上查看數據流模擬器運行情況。分析器在集羣上提交運行後與slave1上運行的數據流模擬器建立連接。當檢測到外部連接時,數據流模擬器將每隔1000毫秒從/home/dong/Streamingtext/file1.txt中隨機截取一行文本發送給slave1節點的9999端口。由於該文本文件中每一行只包含一個單詞和一個逗號,因此每秒僅發送一個單詞和一個逗號給端口,如圖23所示。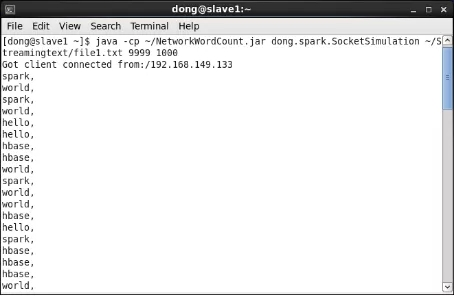
圖23 在slave1上數據流模擬器運行示意圖
第2步,在master上查看分析器運行情況。在master節點的提交窗口中可以查看到統計結果。在WindowWordCount應用程序啓動初期,窗口並沒有被接收到的單詞填滿,但隨着時間的推進,每個窗口中的單詞數目最終固定爲30個。圖7.35只是截取了運行結果中的三個批次。由於設定了窗口時間間隔是30s,滑動時間間隔是10s,且數據流模擬器每間隔1s發送一個單詞,因此WindowWordCount每間隔10s對過去30s內收到的各單詞個數進行統計。圖24中截至1479276925000ms分析器對過去30s內收到的30個單詞進行統計,其中"spark"累計出現5次,"hbase"累計出現8次,"hello"累計出現9次,"world"累計出現8次。再間隔10s,截至1479276935000ms,分析器對過去30s內收到的30個單詞進行統計,其中"spark"累計出現8次,"hbase"累計出現9次,"hello"累計出現7次,"world"累計出現6次。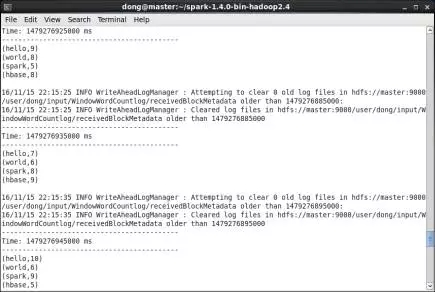
圖24 在master上分析器運行示意圖
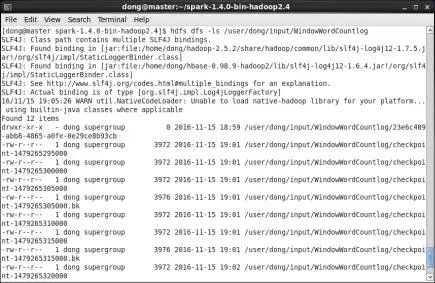
第3步,查看持久化數據。運行後查看HDFS上的持久化目錄/user/dong/input/WindowWordCountlog,如圖25所示。Streaming應用程序將接收到的網絡數據持久化至該目錄下,便於容錯處理。