




阿里百川碼力APP監控 來了!
這個APP監控 和手淘一起成長
歷經千錘百煉 走過千BUG萬坑
如今百川起產品 爲了讓你的APP更好 用戶更爽!
在移動互聯網時代,一款應用是否成功,用戶體驗是一個關鍵的因素。APM的發展使得用戶體驗越來越完善,本文通過90年代互聯產品性能優化的發展過程到今天移動互聯網時代下的APM可用性監控體系,如何去解決日漸複雜的業務導致功能不斷迭代所突發的致命bug,以及日益增長的用戶和膨脹的數據導致流量過大所出現的一些問題。
在《***帝國》電影中較爲經典的一幕是讓Neo在紅藥丸和藍藥丸中做出選擇。紅藥丸作爲一個跟蹤程序,幫助Neo定位物理身體位置,無論在哪裏,出現任何問題都能夠第一時間定位並解決。而開發者基本都知道,想解決大部分的功能性問題的難點基本就在定位上,而電影裏面出現的一些人工智能、機器學習、虛擬現實的技術,也只能夠在科幻電影中才能看到。
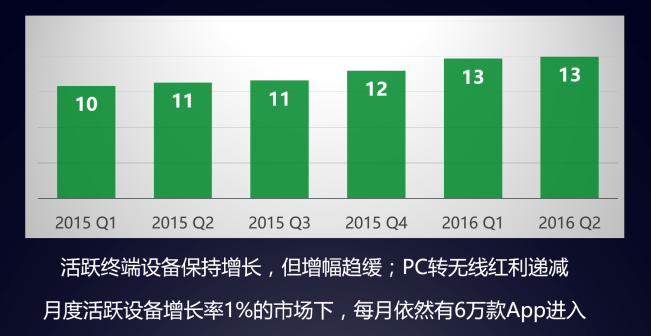
季度活躍設備增長趨勢
今天,在移動終端爆發以及用戶需求的推動下,移動應用的“數量”和“體量”急速擴大,APP性能數據在優化產品上變得越來越重要,國內大批APM廠商彷彿一夜間遍地開花,整個監控體系也從服務端到APP端再到H5端不斷的加強和改變策略來適應不同的場景需求,使得監控和優化的本質上已經發生了變化。
APM的雛形發展
在1996年時,Tivo與HP公司就從應用程序層面出發,他們認爲網絡無疑就是應用的速度。直至1998年,面向以組件爲中心基礎建設監控的APM產品出現,直到2011年,移動設備的普及和APP應用市場的爆發,讓大家對移動端的性能體驗要求也越來越苛刻。
在這個時候,國外的APM行業New Relic和AppDynamics已經在APM領域拔得頭籌,國內一些APM廠商看準移動的這個趨勢,APM彷彿一夜之間遍地開花,直至今日,作爲國內比較具有代表性的APM廠商有:聽雲、OneAPM、雲智慧、博睿等,當前BAT領域也躋身這一領域,阿里百川碼力APM(簡稱“碼力APM”)也在雲棲大會中發佈公測。開發者無需從零開始構建性能探針、數據平臺和控制檯,就可以通過可視化、可運維的方式長期監控應用性能、及時解決應用中存在的問題。
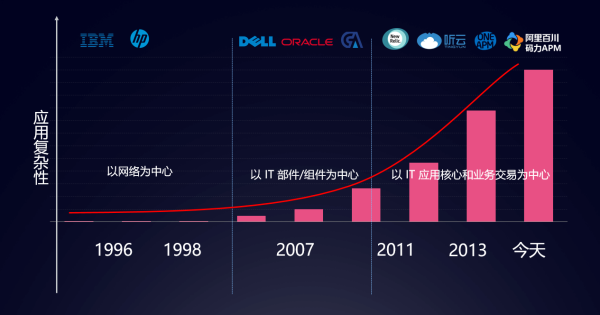
▲ APM 業務與 IT 發展關係變遷
APM可用性度量體系
如今,國內APM業務競爭越來越激烈,大家紛紛在可用性、用戶體驗上發力。比如,大家用手機淘寶,明顯感覺穩定性和流暢度比國內其他電商APP好很多,這不僅僅是因爲他們有一堆優秀的開發工程師,更關鍵是其背後那一套完善的性能監控度量體系。
通過性能監控體系,app上發生的性能指標都會被實時上報,而碼力APM服務端會基於這些指標進行聚類和分析,聚合出問題和性能瓶頸,同時完善的日誌信息也將支持開發工程師及時修復和優化。
阿里技術專家陳武認爲,在性能優化方面,以往的度量是通過APP的打開率來進行對比,很多都是非常主觀。而度量體系裏面面臨的一個很大的問題是常態化。那麼,應該如何建立起這一套可視化的性能度量的體系呢?
阿里百川將影響用戶使用的性能指標分爲可用性度量和體驗度量。
1、 可用性度量
可用性包含app可用性和服務可用性。app可用性問題中最常見的就是crash,而用戶遇到crash之後,大部分會選擇直接卸載app;服務可用性問題則包含網絡連接和服務端錯誤,這類問題往往可能造成用戶購買、訂閱等關鍵操作不可用,從而導致資損,而這類問題若長期未能解決,也會導致用戶流失。
這類問題需要第一時間被修復,越早修復,止損的效果就越好。
這需要客戶端探針具有強大的採集能力。探針SDK將負責採集用戶由於線程異常、內存溢出、手機殺進程等各種原因導致的崩潰,並捕獲到儘量全面的環境信息,和用戶操作軌跡來幫助開發者還原用戶操作,定位問題。同時,對網絡請求部分也是同樣,探針SDK需要支持自動採集網絡性能指標,並捕獲錯誤網絡請求的日誌,來輔助開發工程師解決問題。
但是探針在用戶app端採集的均是單一的事件,若有1000個用戶出現可用性問題,那麼服務端接收到的可能就是1000份日誌。讓開發工程師在海量的日誌中排查問題,顯然可行性不高。這就需要APM服務端實時對這些日誌進行語義分析以及高效的聚類,比如,將1000條用戶日誌聚合爲3個問題,通過控制檯反饋給開發者。這將大大提升開發工程師排查和解決問題的效率。
2、 APP體驗度量
APP體驗是影響用戶留存和活躍的關鍵,大家對APP使用過程中“如絲般順滑”都具有天然的好感。但是目前市場大部分APP的體驗依舊非常差,用戶常會面對卡頓、圖片加載失敗、頁面長時間等待等各種不良體驗。這個時候,非常需要有一個系統體系化的去陳列和度量這些體驗類問題。
APM控制檯對卡頓的處理方式和崩潰類似,同類型的卡頓將被聚類在一起,發生該卡頓的用戶詳細日誌也聚合在一起可以翻頁查閱。而對圖片加載失敗等,頁面元素無法正常顯示的問題,則可以關注該圖片所在靜態資源的服務主機是否異常(單分鐘請求量過多、圖片過大等)。若該靜態資源服務正常,則可以關注請求該圖片的URL的錯誤率,可以反推是否爲圖片本身的問題。
在性能優化的量化方面,如何幫助企業去做定製?陳武認爲,應該串聯關鍵路徑所需要的全部URL,從關鍵路徑整體來看服務的健康度指標,而非關注全部的URL。比如通過網絡性能監控,開發者無需對所有的URL進行關注,不同的開發者關注的核心業務不同,大家關注的URL也不一樣。比如,在電商的場景,一個關鍵的路徑是用戶通過登錄,打開商品,進入詳情,然後下單到支付,通過把對應的關鍵路徑所有的URL整合在一起,保障這條關鍵鏈路的性能,才能夠強化核心業務的服務以及穩定性。
APM的可用性檢測方式
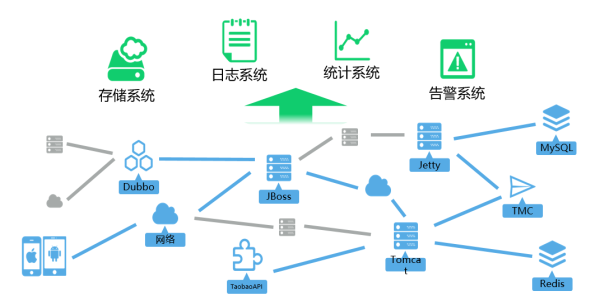
▲ 阿里百川碼力APM的監控體系
對於加強應用的可用性,APM一般都採取應用監控結合服務監控的形式,使得開發者實現端到端的全鏈路性能管理。在碼力APM監控體系中,阿里巴巴技術專家熊奇介紹了碼力APM在監控體系裏面的應用監控、服務監控、數據庫以及消息推送等性能監控,主要通過以下方式來完成:
★ 在應用監控上,採集了iOS、Android應用的內存、CPU、崩潰、網絡等方面的性能數據;
★ 在服務監控上,支持Tomcat、Jetty、JBoss容器和Spring、Struts等框架的性能檢測;
★ 支持MySQL等SQL數據庫和Redis、Mem cache等NoSQL數據庫的性能檢測;
★ 碼力APM還提供了支持淘寶消息服務TMC、分佈式框架Dubbo、淘寶API調用的性能檢測。
對於數據採集之後會統一進入可以承載海量數據的存儲系統和日誌系統,統計系統會利用落地的數據完成數據的計算處理、生成報表,幫助開發者長期跟蹤應用和服務的性能,而告警系統則會根據規則在問題發生時發出短信、郵件等即時告警,從而幫助開發者及時解決問題,降低損失。
可用性的度量檢測方式-性能
在應用開發時,程序錯誤、主線程卡頓和資源使用超過系統限制導致的崩潰,是最嚴重、也是需要首先解決的問題。
通常開發者會藉助模擬器、Instrument或者自動化測試發現一部分問題,但是測試往往難以覆蓋用戶使用場景下的設備、網絡等環境。如果藉助於社交媒體或者郵件反饋渠道,雖然可以有限地拿到真實的用戶反饋,但是用戶往往不能清楚的描述出復現問題所需的信息,往復溝通成本極高。所以,在客戶端上,碼力APM通過以下檢測方式來收集應用崩潰信息。
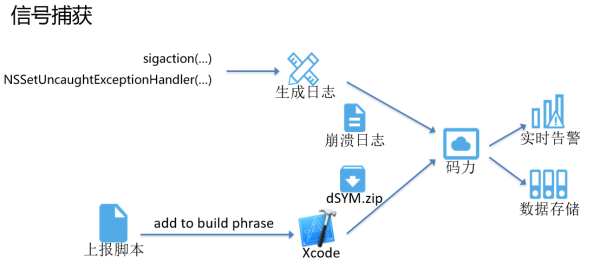
碼力APM在信號捕獲方式中,通過sigaction設置信號中斷時的回調,這樣,就可以在回調中根據程序運行狀態生成對應的崩潰日誌。此外,對於SIGARBT(abnormal termination),我們還需要通過NSSetUncaughtExceptionHandler來獲取未捕獲異常的堆棧,來補全崩潰信息。
而後,把崩潰日誌上報到碼力APM,會依據崩潰日誌的堆棧信息,聚合同一類型的崩潰後寫入數據存儲。同時,告警系統可以依據崩潰次數、崩潰率等規則,即時發出告警。
此外,碼力Apm提供了dSYM上報腳本,在Xcode的build phrase中添加腳本,就可以在編譯成功後自動上報dSYM文件。通過對dSYM文件的解析,重新聚合後寫入數據存儲,聚合可以減少高達90%數據庫行數;同時,也實現了崩潰日誌符號化。不依賴mac環境符號化,更好地利用雲計算平臺服務更多開發者。
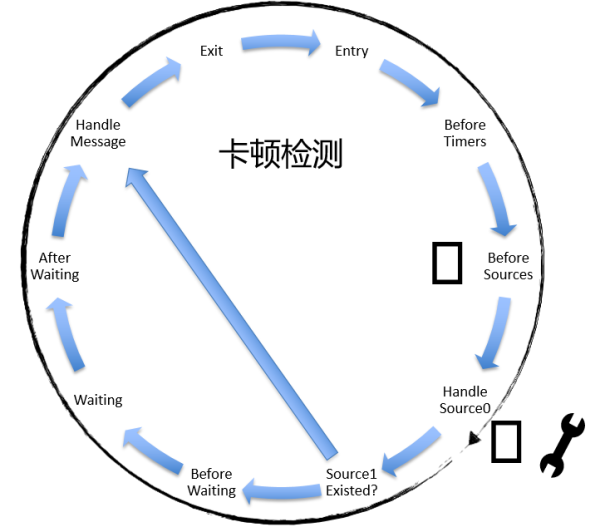
第二種技術是卡頓檢測,卡頓檢測的基礎是RunLoop,通過RunLoop Observer監聽主線程RunLoop狀態的變更。在這裏,把RunLoop當作在操場上跑圈的運動員,把Before Sources當做每圈的起點,同時另外開啓一條線程作爲計時員,每5秒判斷一次RunLoop是否跑過一圈。如果5秒內RunLoop沒有完成一次RunLoop,則視爲主線程卡頓。在發現主線程卡頓後,會生成卡頓日誌,如果是復現的卡頓,可以選擇不重複上報。
此外,針對設備不同的運行時期,如啓動階段、後臺階段、空閒階段,我們會動態調整閾值,降低檢測的開銷。
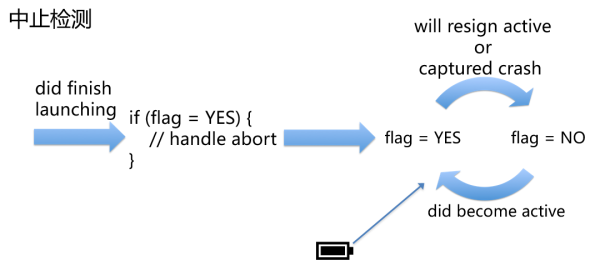
對於無法通過信號捕獲、卡頓檢測的崩潰,碼力APM引入了應用中止檢測,中止檢測雖然不能還原崩潰現場,但是可以揭示問題的存在。在應用進入active狀態時,碼力APM在持久存儲上設立一個標誌位,表示程序在正常運行。在應用退出active狀態或檢測到崩潰時,碼力APM就清除持久存儲上的標誌位,表示程序在已知的情況下退出。這樣,在下一次應用啓動時,如果持久存儲上的標誌位爲真,則說明應用上一次運行在未知情況下退出,這種情況碼力APM就計爲應用非正常中止上報。
同時,爲了過濾因爲電量耗盡導致的關機,碼力APM還增加了電量檢測,在低電量時,清除標誌位,避免中止誤報。
可用性的度量檢測方式-網絡

請求錯誤、流量開銷高、被運營商劫持等網絡問題是應用開發時另一類棘手的問題。當然我們也可以藉助模擬器、Instrument或者自動化測試發現簡單的網絡問題,但是測試難以覆蓋複雜的用戶網絡環境,也難以導出網絡性能數據進行長期比對監控。如果使用手工埋點的方式記錄網絡性能,一方面,我們需要應對多種系統網絡接口,另一方面,我們需要同步應用網絡代碼和埋點代碼,維護成本將會居高不下。
爲了監控應用在真實網絡環境中的性能,碼力APM中引入了無痕埋點的網絡性能監控,在網絡檢測中引入三種注入技術,幫助開發者長期監控應用的網絡性能,優化產品用戶體驗。
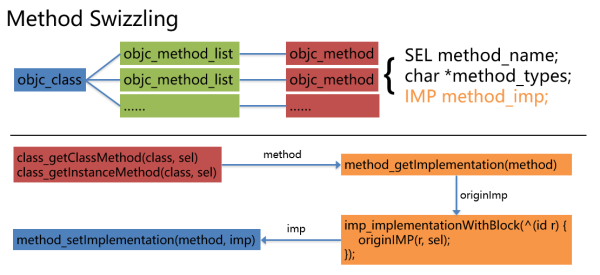
第一種是Method Swizzling。每一個NSObject類都包含一個isa指針,指向objc_class結構體,而每一個objc_class結構體又包含一個methodLists指針,指向objc_method_list結構體數組,在objc_method_list裏又包含一個objc_method結構體成員,且每一個objc_method包含一個method_imp指針,指向方法實現。
因此,只要能修改method_imp的值,我們就能替換原有的實現。在<objc/runtime>中,通過class_getClassMethod和class_getInstanceMethod取得objc_method結構體指針,而後通過method_getImplementation取得方法的原始實現地址originIMP,之後在imp_implementationWithBlock生成新實現imp的參數block裏,調用原始實現,就可以原有行爲前後加入網絡性能埋點行爲。最後調用method_setImplementation替換方法實現。這樣,任何調用都將使用新的實現。
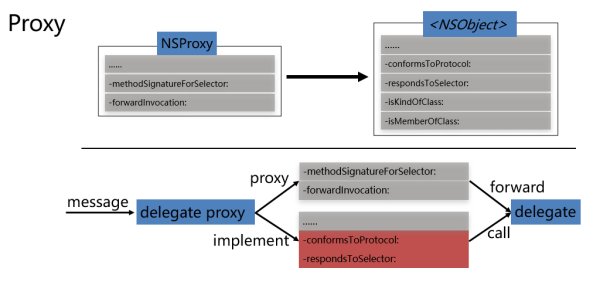
第二種技術是Proxy。在Objective-C裏,NSProxy是除NSObject外唯一的根類。NSProxy是一個實現了NSObject協議的抽象類,它的正常運作需要子類override -methodSignatureForSelector:方法爲sel提供方法簽名,以及-forwardInvocation:方法來完成調用的轉發。
使用Proxy來注入NSURLConnection、NSURLSession等對delegate的回調。具體來說,在delegate proxy收到消息時,如果不是目標協議方法,則通過消息轉發機制,轉發給原delegate;如果是目標協議方法,則直接調用proxy實現,在proxy實現中委託調用原delegate;此外,多數協議和協議方法都是可選的,因此,在proxy的實現中需要實現-conformsToProtocol:和-respondsToSelector:方法來聲明proxy額外加入的協議和方法。這樣,我們就能在不影響原有回調的同時,增加網絡性能埋點邏輯。
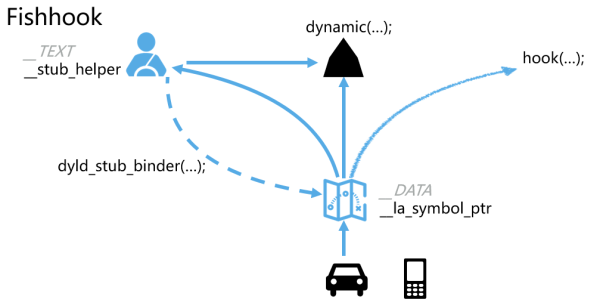
第三種技術是fishhook。使用fishhook來替換動態鏈接庫中的C函數實現,具體來說是CFNetwork和CoreFoundation中的相關函數。這裏,以開車的模型來解釋動態鏈接。設想一名新手司機開車從巴黎到羅馬,因爲他不知道路線,於是他先去諮詢老司機;老司機告訴他正確的線路,這一次他可能還會繞點路,但下一次,他就會按照老司機的建議直接開到羅馬。
相應的,在程序運行時,動態鏈接的C函數dynamic(...)地址記錄在__DATA segment下的__la_symbol_ptr中;初始時,程序只知道dynamic函數的符號名而不知道函數的實現地址;首次調用時,程序通過__TEXT segment中的__stub_helper取得綁定信息,通過dyld_stub_binder來更新__la_symbol_ptr中的符號實現地址;這樣,再次調用時,就可以通過__la_symbol_ptr直接找到dynamic函數的實現;如果我們需要替換dynamic函數的實現,只需要修改__la_symbol_ptr即可。具體的實現方式,可以參閱Facebook的開源框架fishhook。
加強可用性的優化手段
通過以上兩種檢測方式,基本能夠大部分的性能和網絡需求,使得開發者能夠滿足如今移動互聯網下用戶的苛刻的需求,那麼,建立起來的度量體系後,瞭解的具體的問題後,我們應該如何去解決這些問題來提升可用性呢?
1、網絡安全
運營商、DNS被劫持問題是應用開發時一類棘手的問題, 解決方案也比較多。51信用卡技術總監汪睿認爲,51信用卡作爲金融屬性的產品,基於安全考慮會放在第一位。解決方案主要是基於全棧HTTPS的方案來處理,但會帶來一些成本和性能上的損耗。甚至可以像FaceBook、google等一些解決方案,使用HTTP2.0方式,這取決於公司和開發者自身去評估實現的成本。汪睿還介紹了早起的一個過渡方案,那就是HTTP的DNS方式,通過獲取一個IP表通過IP來直接連接,可以避免HTTP劫持的問題。
而網絡是一個端到端的技術,阿里高級技術專家陳武認爲,從電商的場景看,首先要保證服務端的穩定性,服務端可以有反刷,限流,單元化,異地容災,服務降級等策略保證連接的穩定性。另外,客戶端的角度主要看連接鏈路和數據量。鏈路裏面資源可以做多CDN的備份,通過HTTP DNS或者HTTPS,HTTP2.0來反劫持。在鏈路穩定的基礎上,接着去保證傳輸的效率,這裏面可以通過就近接入,連接複用,提升壓縮率,使用二進制協議等技術來減少包大小。當然,這裏面最重要的是端到端的網絡監控體系,這樣在網絡服務治理上會更有抓手。
2、系統降級
降級的解決方案,是系統性能保障的最後一道防線,從性能優化的角度上說,沒有100%完善的設計,總會有一些意料突發的情況導致性能惡化。所以,在系統設計時,必須做好降級設計。
餓了麼移動首席架構師王朝成認爲,在餓了麼517大促活動上,服務器端承受非常大的壓力,這個時候會通過降級部分服務的方式,來確保大促秒殺這種場景得以正常運行。但是,在用戶端上,以及APP,還在不斷積極的發送用戶請求和數據,反而增加服務器集羣的壓力。這個時候,王朝成表示,他們會考慮把一部分的SDK或者APP上的服務也進行降級,來減少服務端在分析數據上的壓力。
降級分爲手動降級和智能降級,在策略上分爲流量降級、效果降級、功能性降級。流量降級主要表現在通過主動拒絕處理部分流量早餐部分用戶服務不可用。而效果降級和功能性降級都表現爲服務質量的降級,一個是通過在流量高峯時期用相對低質量、低延時的服務來保障所有用戶的服務可用性,另外一個是通過減少功能的方式來提高用戶的服務可用性。
3、網絡性能
從數據結構上,需要根據不同的業務場景來選擇合適的數據結構,在數據流量較少的情況可能客戶端上表現不出什麼區別,當在數據流量過大,且數據結構複雜的時候很可能就是直接影響到APP的性能。
類似餐飲領域“餓了麼”這樣的應用,數據發送的頻率使得據量會非常大,對用戶來說可能沒有什麼感知,但是商家接收大量的訂單,數據量影響很大,感知比較明顯。王朝成認爲,可以考慮一些新的協議(Protobuf, Flatbuf)來優化數據量,比如HTTP2.0可以壓縮http協議的header,使用encoder來減少需要傳輸的header大小,通過通訊雙方各自cache一份header fields表,對於相同的數據不再通過每次請求和響應發送,又減少了需要傳輸的大小。再一個是採取二進制的協議,只認0和1的組合,通過把原來http1.x的header和body部分用frame重新封裝,實現方便且健壯。通過內容壓縮與併發傳輸機制,在低速、不穩定的無線條件下,較少其http body的發送大小,改善用戶體驗和資源效率。
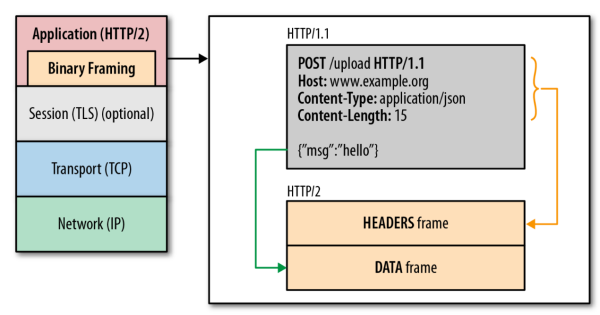
▲ http1.x和http2.0協議關係
同時,阿里高級技術專家陳武也表示,如果在鏈路沒有問題的情況下,那麼必須在整個網絡傳輸層要儘量快,不然很容易出現timeout。所以,第一要從協議層,在協議層裏面通過http2.0來減少包頭的壓縮,同時支持服務端push消息,且通過雙通通道,對通道複用更快。第二是從數據層,數據可以通過二進制壓縮。在整個網絡連通率較低的時候,將打包拆成小包,達到很好的傳輸效果。
4、動態熱修復
所謂熱修復,就是使用熱補丁動態修復技術,通過向用戶發送Patch,在用戶無感知的情況下完成一些致命bug的修復。51信用卡客戶端負責人汪睿認爲,在移動客戶端上最大的一個問題是發版,對於iOS的用戶來說,整個修復流程比較漫長。需要提交審覈,但是在這段時間有可能已經錯過很多用戶。他認爲,熱修復技術能夠很快並及時的在線進行修復,通常在使用的過程中就完成的修復過程。
在熱修復技術上,Android常用的是基於Android dex分包方案,而iOS可以利用JSPatch,它可以使得你用JavaScript書寫原生iOS APP,只需要在項目中引入極小的引擎,就可以用JavaScript調用任何的Objective-C的原生接口。
總結
以上所談到的性能優化手段基本是爲了解決三種情況所造成的問題:1. 日漸複雜的業務導致功能不斷迭代所突發的致命bug修復方式,2. 日益增長的用戶和膨脹的數據導致流量過大,3.網絡安全和內存開銷的問題。
本文通過不同的場景來分析移動性能優化的模式,可以通過確定場景下解決某一類型的問題。當然,我們不能僅僅通過了解性能優化所解決的問題以及手段,更重要的是需要清楚該問題所發生的場景、原因需要的成本。
作者 51CTO 林師授