




## 什麼是分佈式事務?
### 什麼是事務
**事務是關係型數據庫對數據的一系列操作的集合,他可以從以下4個特徵是否達到來描述**
* 原子性
> 原子性要求,事務是一個不可分割的執行單元,事務中的所有操作要麼全都執行,要麼全都不執行。
* 一致性
> 一致性要求,事務在開始前和結束後,數據庫的完整性約束沒有被破壞。
* 隔離性
> 事務的執行是相互獨立的,它們不會相互干擾,一個事務不會看到另一個正在運行過程中的事務的數據。
* 持久性
> 持久性要求,一個事務完成之後,事務的執行結果必須是持久化保存的。即使數據庫發生崩潰,在數據庫恢復後事務提交的結果仍然不會丟失。
### 什麼是分佈式事務
**分佈式事務,是分佈式環境下,對數據一系列操作的集合,通過以下三個特徵是否實現來表述**
* 一致性(Consistency) : 客戶端知道一系列的操作都會同時發生(生效)
* 可用性(Availability) : 每個操作都必須以可預期的響應結束
* 分區容錯性(Partition tolerance) : 即使出現單個組件無法可用,操作依然可以完成
## 分佈式環境下的兩大理論
### Cap理論 (設計中的限制)
> Cap告訴你,分佈式事務的三條性質,你的系統裏同時只能實現兩條。如在實現分區容錯性的條件下,數據A,存在分區P1和P2中,某個時間P1中的數據A發生了變化,這個時候爲了滿足分區一致,你得把數據傳輸到P2,而你又不希望客戶端看到兩個版本的數據A(一致性),那麼你選擇不讓客戶端看到數據(犧牲了可用性)。
### Base理論 (設計中的取捨)
* Basically Available(基本可用)
* Soft state(軟狀態)
* Eventually consistent(最終一致性)
> BASE理論是對CAP中的一致性和可用性進行一個權衡的結果,理論的核心思想就是:我們無法做到強一致,但每個應用都可以根據自身的業務特點,採用適當的方式來使系統達到最終一致性(Eventual consistency)。
## 分佈式事務的解決方案
* DTP模型
* 基於可靠消息服務的分佈式事務 [保證上下游兩個操作組成的事務的一致性]
* 最大努力通知 [保證上下游兩個操作組成的事務的一致性]
* TCC
* DogTCC
#### DTP模型的定義
> DTP只是一套實現分佈式事務的規範,並沒有定義具體如何實現分佈式事務,TM可以採用2PC、3PC、Paxos等協議實現分佈式事務。
##### 模型的三個角色
* AP:Application 應用系統
它就是我們開發的業務系統,在我們開發的過程中,可以使用資源管理器提供的事務接口來實現分佈式事務。
* TM:Transaction Manager 事務管理器
分佈式事務的實現由事務管理器來完成,它會提供分佈式事務的操作接口供我們的業務系統調用。這些接口稱爲TX接口。
事務管理器還管理着所有的資源管理器,通過它們提供的XA接口來同一調度這些資源管理器,以實現分佈式事務。
* RM:Resource Manager 資源管理器
能夠提供數據服務的對象都可以是資源管理器,比如:數據庫、消息中間件、緩存等。大部分場景下,數據庫即爲分佈式事務中的資源管理器。
資源管理器能夠提供單數據庫的事務能力,它們通過XA接口,將本數據庫的提交、回滾等能力提供給事務管理器調用,以幫助事務管理器實現分佈式的事務管理。XA是DTP模型定義的接口,用於向事務管理器提供該資源管理器(該數據庫)的提交、回滾等能力。DTP只是一套實現分佈式事務的規範,RM具體的實現是由數據庫廠商來完成的。
##### DTP模型接口的定義
* XA , 資源管理器實現的接口
* TM , 事務管理器實現的接口
> DTP只定義了這兩個接口,未定義這兩個接口需要實現的內容
####DTP模型的實現 (三個角色,不同的接口)
##### mysql實現的XA接口
##### JTA
##### 2PC
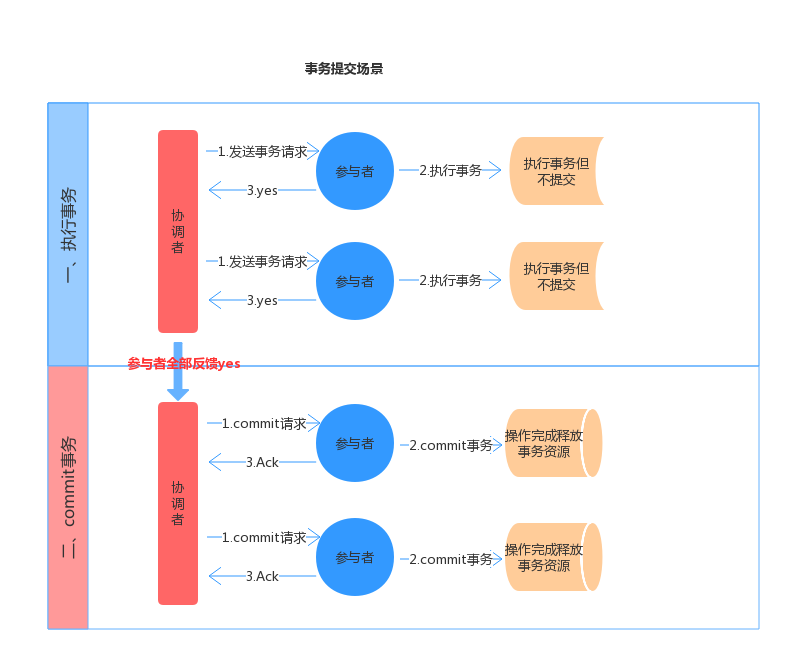
* 第一階段:
協調者會問所有的參與者結點,是否可以執行提交操作。
各個參與者開始事務執行的準備工作:如:爲資源上鎖,預留資源,寫undo/redo log……
參與者響應協調者,如果事務的準備工作成功,則迴應“可以提交”,否則迴應“拒絕提交”。
* 第二階段:
如果所有的參與者都回應“可以提交”,那麼,協調者向所有的參與者發送“正式提交”的命令。參與者完成正式提交,並釋放所有資源,然後迴應“完成”,協調者收集各結點的“完成”迴應後結束這個Global Transaction。
如果有一個參與者迴應“拒絕提交”,那麼,協調者向所有的參與者發送“回滾操作”,並釋放所有資源,然後迴應“回滾完成”,協調者收集各結點的“回滾”迴應後,取消這個Global Transaction。
> 缺點: 阻塞 腦裂 單點故障
###### 3PC
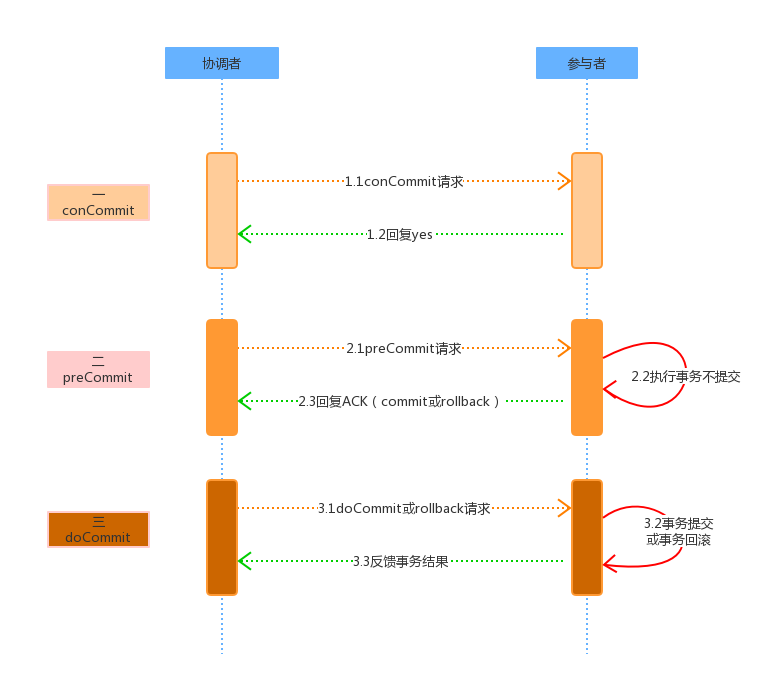
* 相對於2PC,3PC主要解決的單點故障問題,並減少阻塞,因爲一旦參與者無法及時收到來自協調者的信息之後,他會默認執行commit。而不會一直持有事務資源並處於阻塞狀態。但是這種機制也會導致數據一致性問題,因爲,由於網絡原因,協調者發送的abort響應沒有及時被參與者接收到,那麼參與者在等待超時之後執行了commit操作。這樣就和其他接到abort命令並執行回滾的參與者之間存在數據不一致的情況。
#### 基於可靠消息服務的分佈式事務
* 這種實現分佈式事務的方式需要通過消息中間件來實現。假設有A和B兩個系統,分別可以處理任務A和任務B。此時系統A中存在**一個業務流程,需要將任務A和任務B在同一個事務中處理**。

**當上遊系統執行完任務並向消息中間件提交了Commit指令後,便可以處理其他任務了,此時它可以認爲事務已經完成,接下來消息中間件一定會保證消息被下游系統成功消費掉!那麼這是怎麼做到的呢?這由消息中間件的投遞流程來保證。**
消息中間件向下遊系統投遞完消息後便進入阻塞等待狀態,下游系統便立即進行任務的處理,任務處理完成後便向消息中間件返回應答。消息中間件收到確認應答後便認爲該事務處理完畢!
如果消息在投遞過程中丟失,或消息的確認應答在返回途中丟失,那麼消息中間件在等待確認應答超時之後就會重新投遞,直到下游消費者返回消費成功響應爲止。當然,一般消息中間件可以設置消息重試的次數和時間間隔,比如:當第一次投遞失敗後,每隔五分鐘重試一次,一共重試3次。如果重試3次之後仍然投遞失敗,那麼這條消息就需要人工干預。
#### 最大努力通知

對於基於可靠消息服務的分佈式事務,是一個理想化的過程,但在實際場景中,往往會出現如下幾種意外情況:
消息中間件向下遊系統投遞消息失敗
上游系統向消息中間件發送消息失敗
對於第一種情況,消息中間件具有重試機制,我們可以在消息中間件中設置消息的重試次數和重試時間間隔,對於網絡不穩定導致的消息投遞失敗的情況,往往重試幾次後消息便可以成功投遞,如果超過了重試的上限仍然投遞失敗,那麼消息中間件不再投遞該消息,而是記錄在失敗消息表中,消息中間件需要提供失敗消息的查詢接口,下游系統會定期查詢失敗消息,並將其消費,這就是所謂的“定期校對”。
如果重複投遞和定期校對都不能解決問題,往往是因爲下游系統出現了嚴重的錯誤,此時就需要人工干預。
對於第二種情況,需要在上游系統中建立消息重發機制。可以在上游系統建立一張本地消息表,並將 任務處理過程 和 向本地消息表中插入消息 這兩個步驟放在一個本地事務中完成。如果向本地消息表插入消息失敗,那麼就會觸發回滾,之前的任務處理結果就會被取消。如果這量步都執行成功,那麼該本地事務就完成了。接下來會有一個專門的消息發送者不斷地發送本地消息表中的消息,如果發送失敗它會返回重試。當然,也要給消息發送者設置重試的上限,一般而言,達到重試上限仍然發送失敗,那就意味着消息中間件出現嚴重的問題,此時也只有人工干預才能解決問題。
對於不支持事務型消息的消息中間件,如果要實現分佈式事務的話,就可以採用這種方式。它能夠通過重試機制+定期校對實現分佈式事務,但相比於第二種方案,它達到數據一致性的週期較長,而且還需要在上游系統中實現消息重試發佈機制,以確保消息成功發佈給消息中間件,這無疑增加了業務系統的開發成本,使得業務系統不夠純粹,並且這些額外的業務邏輯無疑會佔用業務系統的硬件資源,從而影響性能。
### TCC模式

#### TCC模式系統構成
* 上圖我們可以看到以下幾個組件
事務發起方(MainService)
事務管理器(TransactionManager)
事務服務方(Server)
* 以下幾個過程
prepare -> try
commit -> confirm
rollback -> cancel
#### TCC執行流程
1. 事務發起方向事務管理器註冊服務
2. 事務發起方向服務方發起prepare命令
3. 事務服務方執行try操作
4. 事務發起方將執行結果告訴事務管理器
5. 事務管理器根據事務執行結果,向事務服務發送Confirm或者Cancel
### 現有系統存在的問題
* 2PC,3PC 的問題 : 數據不一致
* 最大努力通知的問題: 對系統侵入性太強
* 傳統TCC系統存在的問題
1. 需要自己實現事務管理器的集羣。
2. 鏈式調用延遲,可以想象,如果服務方又是事務發起方,那麼對他的調用中,又將涉及新事務產生。事務的Confirm和Cancel怎麼設計,將是對系統的挑戰。
> 假設A調用B(B調用E,F)和C。對於B來說,如果不存在鏈式調用,E,F中有一個失敗,另外一個回滾即可。而現在現在情況變了,在這個假設裏,E,F服務的Confirm或Cancel還取決於C服務。這就大大增加了系統的複雜性,如果C服務有是鏈式調用,那麼更加複雜,多級的等待將使系統變的不可用。另外鏈式調用中,事務的不斷創建也是對性能的損耗。
### DogTCC
> 一個易用的開源分佈式TCC事務框架
* DogTCC在傳統TCC的基礎上,將事務注入業務的消息流中鏈式傳輸,各個消息鏈中的服務無需和調用方保持連接,調用方可通過原有的消息返回通道獲取返回結果,去掉了發起方和被調用發try操作的確認流程,大大提升了性能。
* 因爲事務的鏈式傳輸,使得邏輯上在一個事務中的調用自然的變成了一個事務,而非傳統DogTCC會出現的多層次樹狀調用,解決了鏈式調用的問題。
* 事務發起方和事務服務方間無鏈接,並且都爲無狀態服務,更容易併發。

源碼地址: https://github.com/sunpengChina/dog