




原文:https://blog.csdn.net/weixin_41362649/article/details/82848132
http://www.cnblogs.com/pinard/p/9128682.html
矩陣分解
矩陣分解確實可以解決一些近鄰模型無法解決的問題,近鄰模型存在的問題:1、物品之間存在相關性,信息量並不是隨着向量維度增加而線性增加 2、矩陣元素稀疏,計算結果不穩定,增減一個向量維度,導致緊鄰結果差異很大的情況出現。
矩陣分解就是把原來的大矩陣,近似的分解成小矩陣的乘積,在實際推薦計算時不再使用大矩陣,而是使用分解得到的兩個小矩陣。
具體來說就是,假設用戶物品的評分矩陣A是m乘n維,即一共有m個用戶,n個物品.通過一套算法轉化爲兩個矩陣U和V,矩陣U的維度是m乘k,矩陣V的維度是n乘k。
這兩個矩陣的要求就是通過下面這個公式可以復原矩陣A: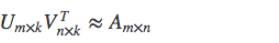
類似這樣的計算過程就是矩陣分解,還有一個更常見的名字SVD,但是SVD和矩陣分解不能劃等號,因爲除了SVD還有一些別的矩陣分解方法。
矩陣分解的不足
矩陣分解本質上都是在預測用戶對一個物品的偏好程度,哪怕不是預測評分,只是預測隱式反饋,也難逃這一個事實。
得到這樣的矩陣分解結果後,常常在實際使用時,又是用這個預測結果來排序。所以,從業者們稱想要模型的預測誤差最小化,結果繞了一大圈最後還是隻想要一個好點的排序。
這種針對單個用戶對單個物品的偏好程度進行預測,得到結果後再排序的問題,在排序學習中的行話叫做point-wise,其中point意思就是:只單獨考慮每個物品,每個物品像是空間中孤立的點一樣,與之相對的,還有直接預測物品兩兩之間相對順序的問題,就叫做pair-wise。
之前說的矩陣分解都屬於point-wise模型。這類模型存在的問題是隻能收集到正樣本,沒有負樣本,於是認爲缺失值就是負樣本,再以預測誤差爲評判標準去使勁逼近這些樣本。逼近正樣本沒問題,但是同時逼近的負樣本只是缺失值而已,還不知道真正呈現在用戶面前,到底是不喜歡還是喜歡呢?雖然這些模型採取了一些措施來規避這個問題,比如負樣本採樣,但是尷尬還是存在的,爲了排序而繞路也是事實。
更直接的推薦模型應該是:能夠較好地爲用戶排列出更好的物品相對順序,而非更精確的評分。
針對以上問題提出的方法是:貝葉斯個性化排序,簡稱BPR模型。
貝葉斯個性化排序(BRP模型)
參考http://www.cnblogs.com/pinard/p/9128682.html