




BR-MLP是基於大數據BR-ODP的分佈式數據挖掘平臺,構建於分佈式平臺之上,封裝了Spark內成熟算法和其他領域算法,以機器學習算法和深度學習算法爲核心,提供海量大數據的接入、清洗、管理、建模、挖掘、可視化等功能。挖掘數據的潛在價值,助力互聯網企業更好、更快的發展!
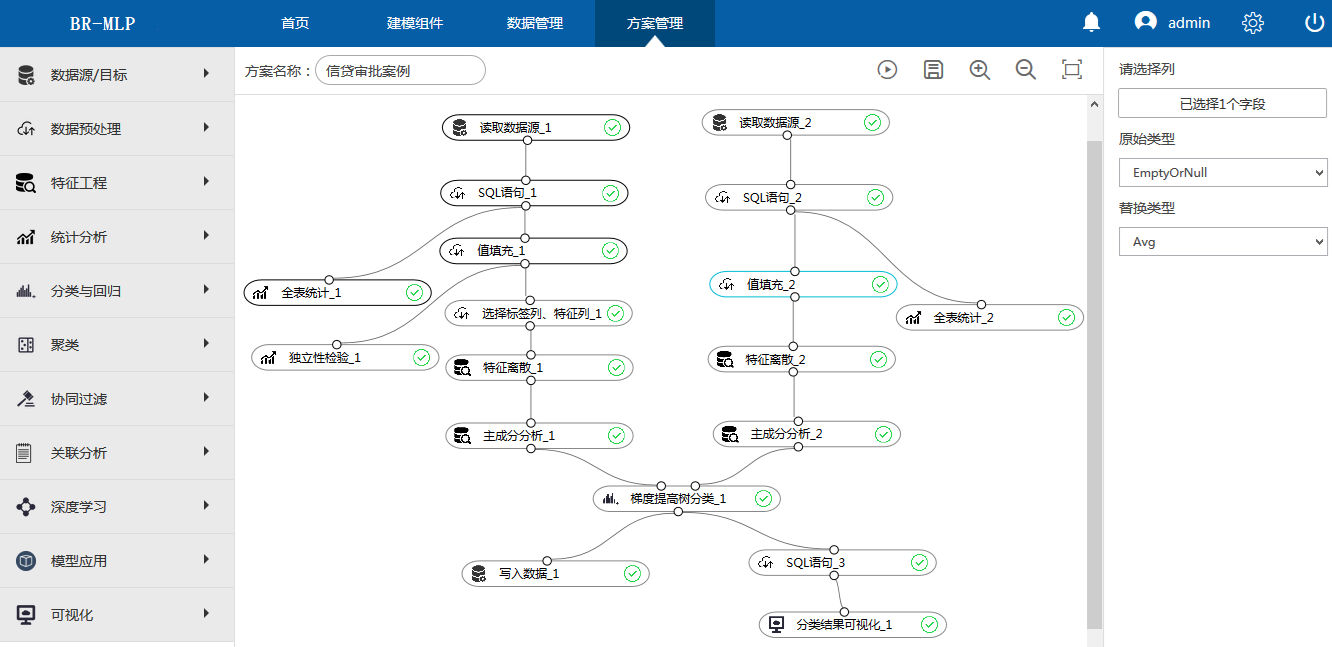
下面,小編具體講解一下BR-MLP數據挖掘平臺關於分類或迴歸模型12個算法
(1)決策樹分類:在信息增益和已知各種情況發生概率的基礎上,通過構成決策樹來實現分類,支持二分類和多分類。
(2)決策樹迴歸:決策樹是在信息增益和已知各種情況發生概率的基礎上,通過構成決策樹來實現迴歸。
(3)樸素貝葉斯:基於貝葉斯定理與特徵條件獨立假設的分類方法,支持多分類和二分類。
(4)隨機森林分類:是利用多棵決策樹對樣本進行訓練並預測的一種分類器。
(5)隨機森林迴歸:是利用多棵決策樹對樣本進行訓練並預測的一種迴歸算法。
(6)梯度提高樹分類:是一種組合算法,它的分類器是決策樹,可以用作分類。
(7)梯度提高樹迴歸:是一種組合算法,它的基分類器是決策樹,可以用迴歸。
(8)邏輯迴歸:邏輯迴歸的模型是一個非線性模型,在線性函數的基礎上添加了映射函數關係,是常用的分類算法。
(9)支持向量機:一個支持向量機構造一個超平面,其可用於分類。
(10)線性迴歸:利用數理統計中的迴歸分析,來確定兩種或兩種以上變量間相互依賴的定量關係的一種迴歸方法。
(11)保序迴歸:是在約束條件下的一種迴歸,該平臺採用平行化的PAVA算法,最終用於擬合原始數據最佳的單調函數。
(12)時間序列:採用自迴歸積分滑動平均模型的時間序列預測方法,針對一列按照時間順序排列的數據進行建模預測。