最近主攻go的學習,在學完了基礎語法,看完了無聞翻譯的《The way to go》和ccmouse大神的慕課網課程後,感覺基礎差不多了,繼續深入挖掘ccmouse大神的爬蟲項目,收穫頗豐,感覺還是有一定的難度的,會繼續啃下去,學習之餘感覺自己實在是井底之蛙,無數光陰盡數浪費,無所建樹,思維停留在最原始的層面,無法向前邁進;慶幸現在有所覺悟,人生匆匆幾十載,時間是最寶貴的,不論哪個領域,選擇一個自己認定的,低下頭向前衝刺,豐富自己的頭腦,提升自己的認知。好像扯得有點遠了,下面是項目的總結。
- 項目有一個main.go的入口文件,然後是各個子目錄功能文件夾;如圖:
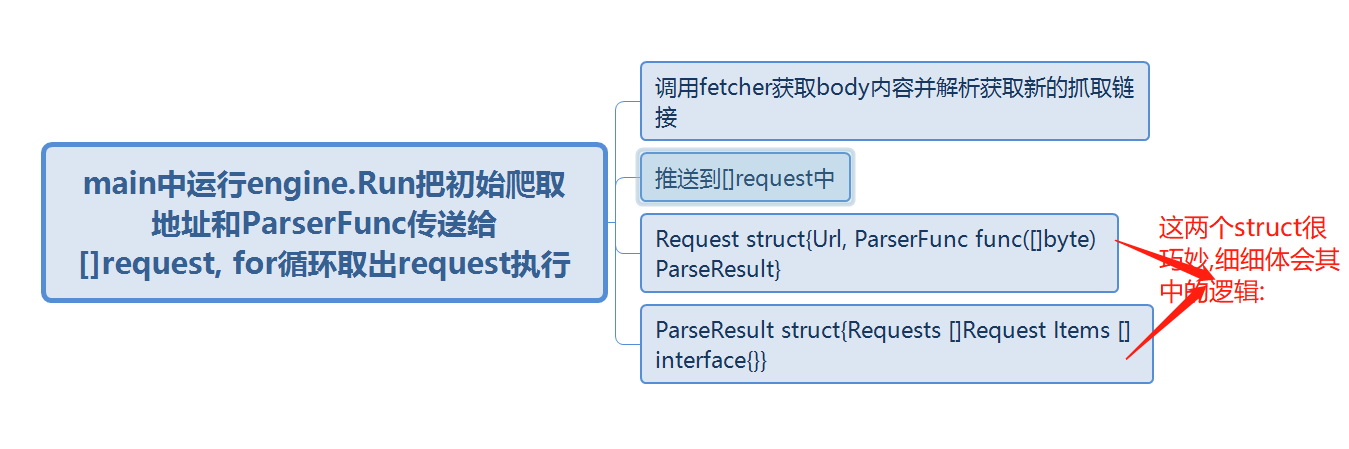
![go語言學習爬蟲框架總結]() engine是總的控制文件,把請求和正則解析push到總的slice []request中,fetcher主要是通過http庫去獲取頁面body信息,model是要保存的人的信息struct
engine是總的控制文件,把請求和正則解析push到總的slice []request中,fetcher主要是通過http庫去獲取頁面body信息,model是要保存的人的信息struct - 說完了目錄結構,接下來介紹下流程:
![go語言學習爬蟲框架總結]()
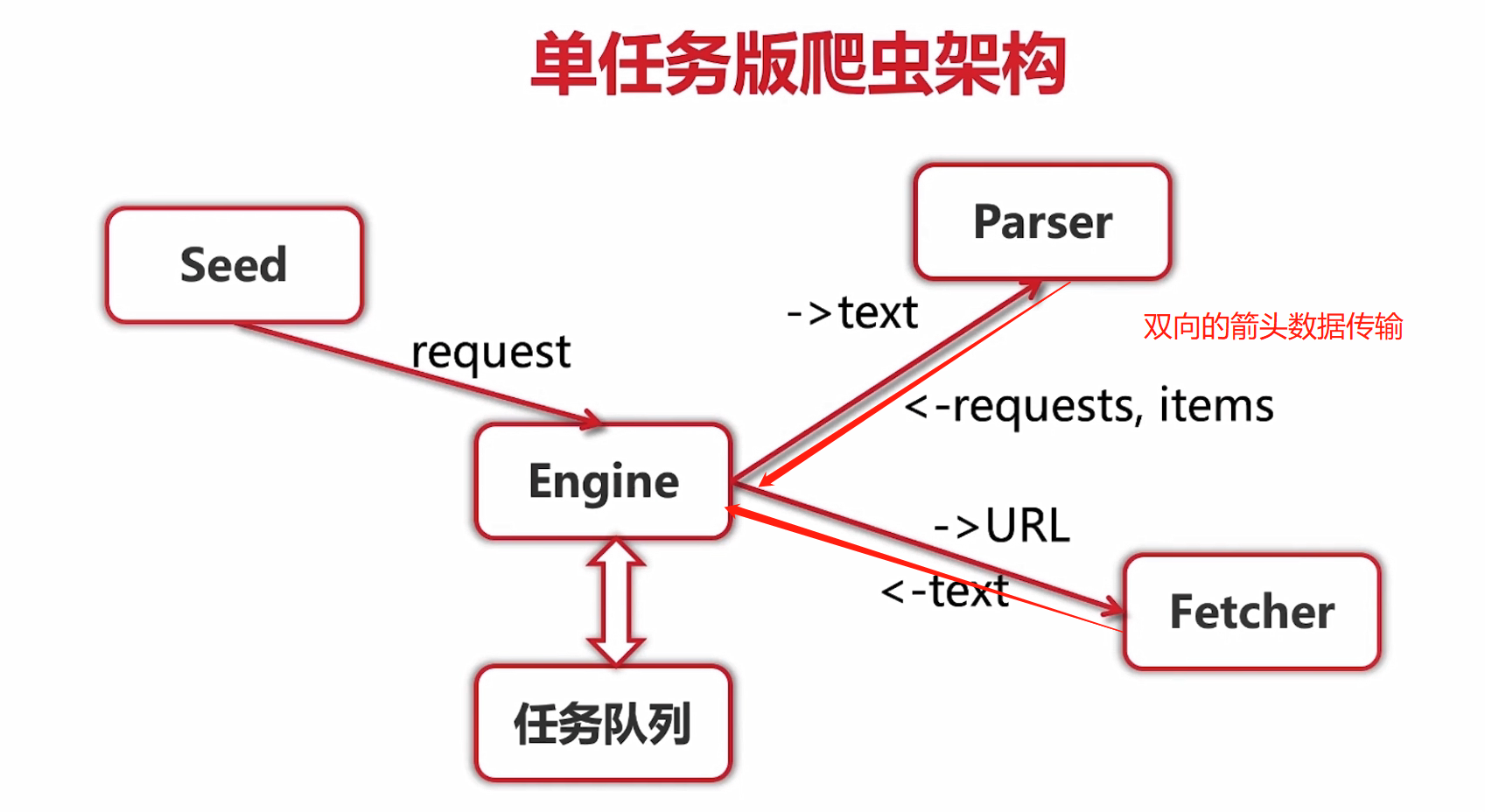
- 整個單機版爬蟲項目比較簡單,但對我來說收貨還是比較大的,其中涉及到一些技術細節,如接口定義,結構方法的使用,
- 後面還有併發版本和分佈式版本,就比較複雜了,併發版是充分使用go的goroutine和chan,要在大的方向上理清楚思路,抽象出一些公用的方法和結構,重要的正則解析要做test工作,然後在此指引下一步步構建,不可盲目前進。首先併發版需要兩個chan,一個in :=chan Request和另一個out:=chan ParseResult,併發版啓動WorkerCount個goroutine去併發獲取in chan url內容並解析出新url推送到out chan,同時併發版有一個scheduler調度器, 將初始的爬取Request(包括url和對應的parser,因爲每個網址的parser規則不同所以要成組傳輸)放進scheduler裏的workerChan即前面定義的in chan, 他倆是一個chan, 程序開始併發執行,由於執行的比較快會被爬取網站斷掉, 可以用time.Tike(time)來限制速度,另爬取時可能要設置相應的header頭,否則會被屏蔽掉.
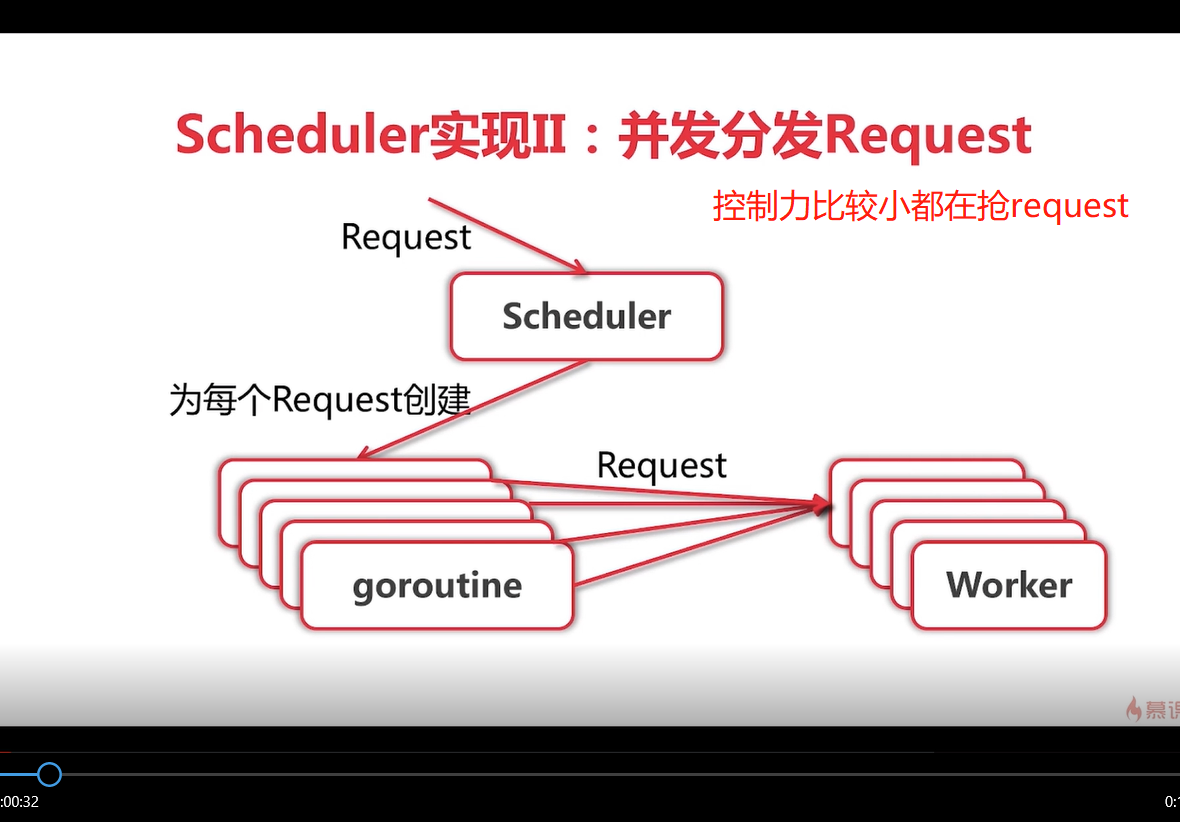
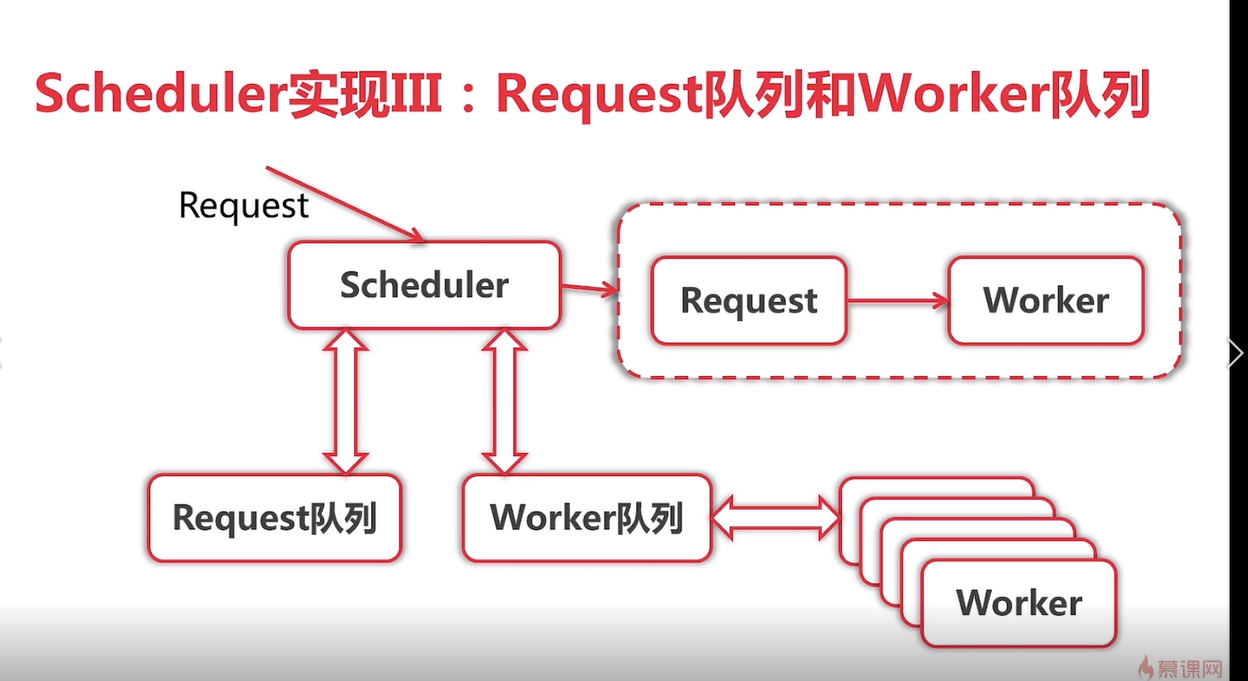
- 由於併發版多個worker都在爭搶Request去執行,控制力度比較小,只適用於單機,不適合多機器分佈式部署,故演化出第三個版本:隊列實現.隊列執行效率和併發版執行效率差不多. scheduler調度器中有rqquestChan chan Request 和 workerChan chan chan Request(
注意這裏是兩個chan), 在run方法中定義一個out chan ParseResult,和併發版相比而言,隊列版多了workerChan 這個chan,主要用來實現隊列的調度。試着描述下整個過程不一定清晰:![go語言學習爬蟲框架總結]()
- 下面附上幾張ccmouse大神的講課ppt供大家理解,如有不清楚的歡迎下方留言討論。
![go語言學習爬蟲框架總結]()
![go語言學習爬蟲框架總結]()
![go語言學習爬蟲框架總結]()
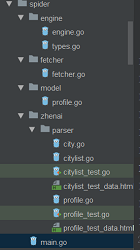 engine是總的控制文件,把請求和正則解析push到總的slice []request中,fetcher主要是通過http庫去獲取頁面body信息,model是要保存的人的信息struct
engine是總的控制文件,把請求和正則解析push到總的slice []request中,fetcher主要是通過http庫去獲取頁面body信息,model是要保存的人的信息struct