




一、k8s架構介紹
1、k8s是什麼
Kubernetes 是谷歌開源的容器集羣管理系統,是 Google 多年大規模容器管理技術 Borg 的開源版本,主要功能包括:
- 基於Pod的應用部署、維護和滾動升級
- 負載均衡和服務發現
- 跨機器和跨地區的集羣調度
- 自動伸縮
- 無狀態服務和有狀態服務
- 廣泛的 Volume 支持
- 插件機制保證擴展性
- 資源監控
- 等等
2、架構
圖1
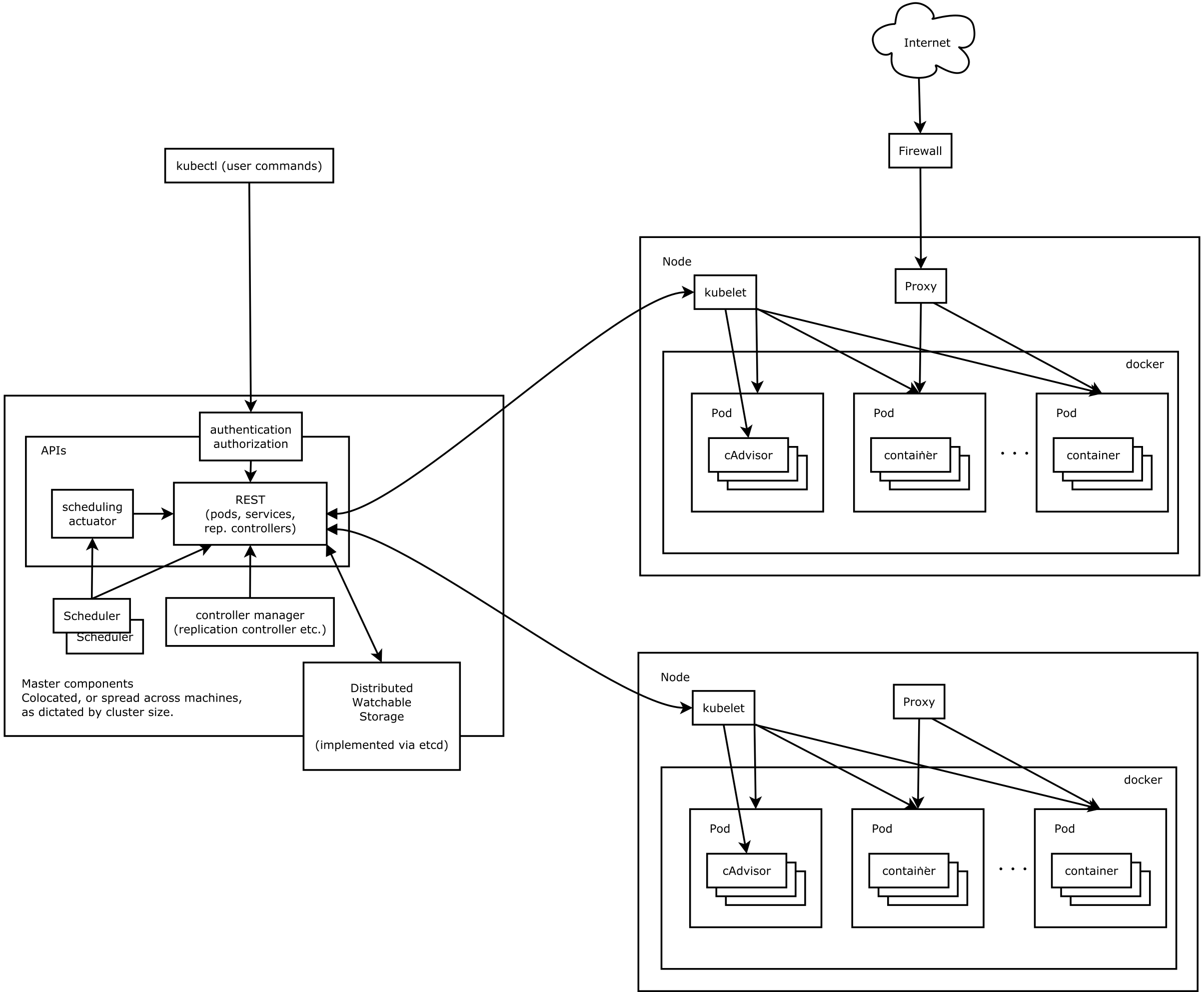
2.1 核心組件:
1)etcd保存了整個集羣的狀態;#和zk提供的功能類似,更易用
2)apiserver提供了資源操作的唯一入口(restful api),並提供認證、授權、訪問控制、API註冊和發現等機制; #其他模塊訪問etcd,必須要經過apiserver
3)controller manager負責維護集羣的狀態,比如故障檢測、自動擴展、滾動更新等; #由一些列的控制器組成node controller,replication controller,endpoint controller ...
4)scheduler負責資源的調度,按照預定的調度策略將Pod調度到相應的機器上;#監聽 kube-apiserver,查詢還未分配 Node 的 Pod,根據調度策略調度pod資源
5)kubelet負責維護容器的生命週期,同時也負責Volume(CVI)和網絡(CNI)的管理;
6)Container runtime負責鏡像管理以及Pod和容器的真正運行(CRI);
7)kube-proxy負責爲Service提供cluster內部的服務發現和負載均衡;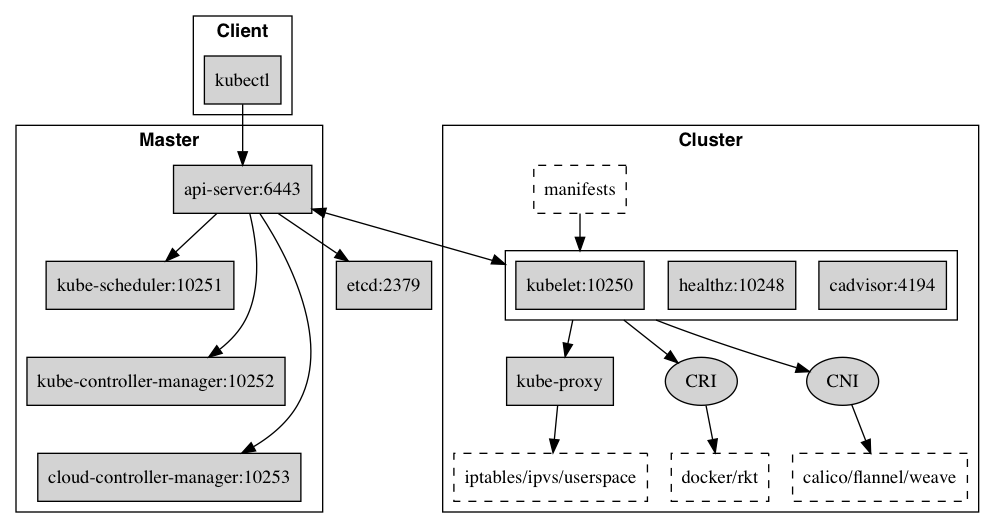
2.2 Addons:
kube-dns負責爲整個集羣提供DNS服務
Ingress Controller爲服務提供外網入口
Heapster提供資源監控
Dashboard提供GUI
Federation提供跨可用區的集羣
Fluentd-elasticsearch提供集羣日誌採集、存儲與查詢
3、分層架構
Kubernetes 設計理念和功能其實就是一個類似 Linux 的分層架構,如下圖所示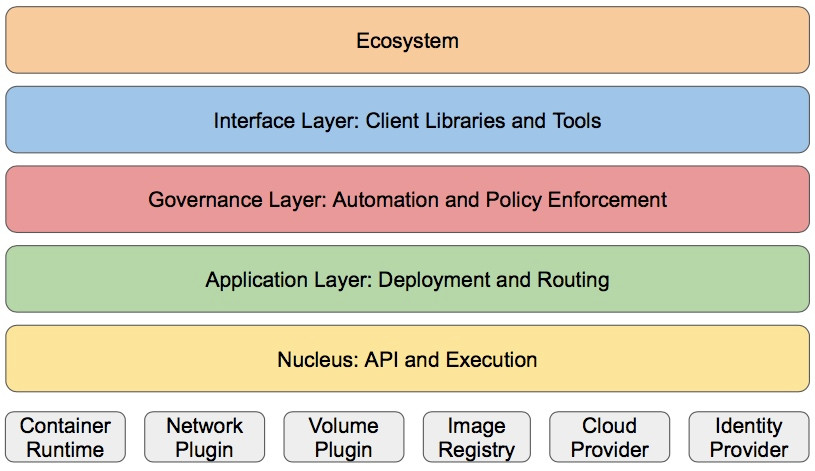
核心層:Kubernetes 最核心的功能,對外提供 API 構建高層的應用,對內提供插件式應用執行環境
應用層:部署(無狀態應用、有狀態應用、批處理任務、集羣應用等)和路由(服務發現、DNS 解析等)
管理層:系統度量(如基礎設施、容器和網絡的度量),自動化(如自動擴展、動態 Provision 等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等)
接口層:kubectl 命令行工具、客戶端 SDK 以及集羣聯邦
生態系統:在接口層之上的龐大容器集羣管理調度的生態系統,可以劃分爲兩個範疇
Kubernetes 外部:日誌、監控、配置管理、CI、CD、Workflow、FaaS、OTS 應用、ChatOps 等
Kubernetes 內部:CRI、CNI、CVI、鏡像倉庫、Cloud Provider、集羣自身的配置和管理等
4、核心組件
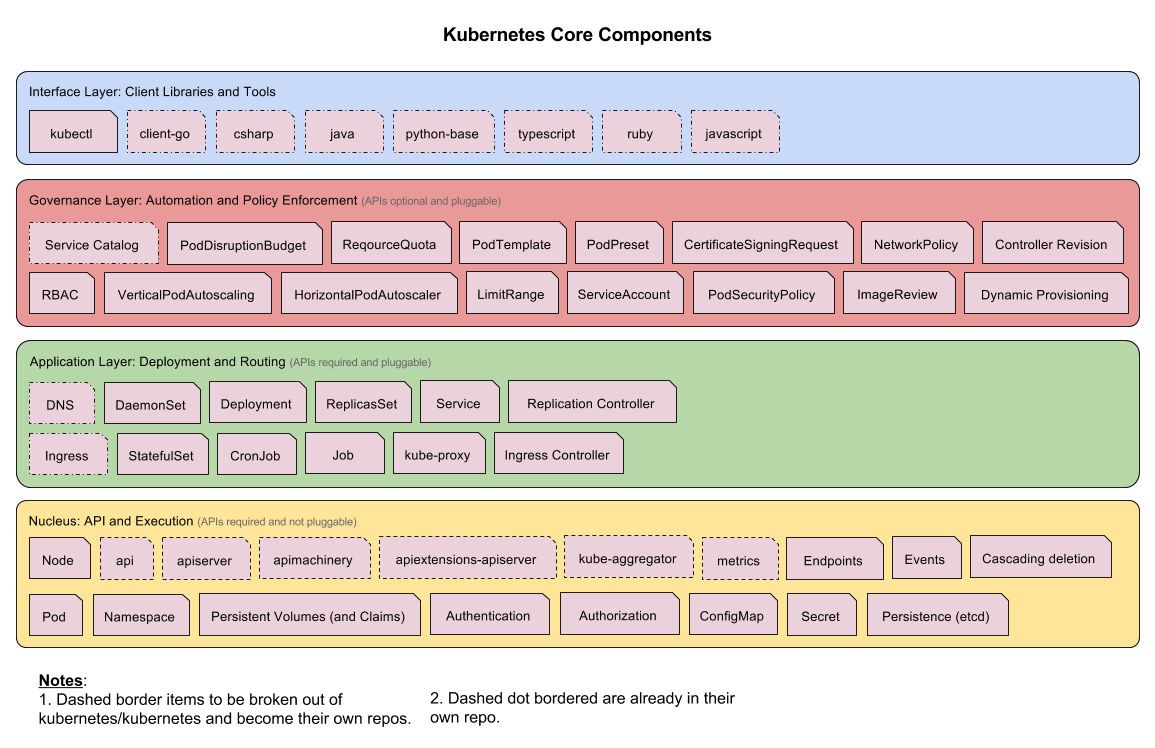
5、核心API
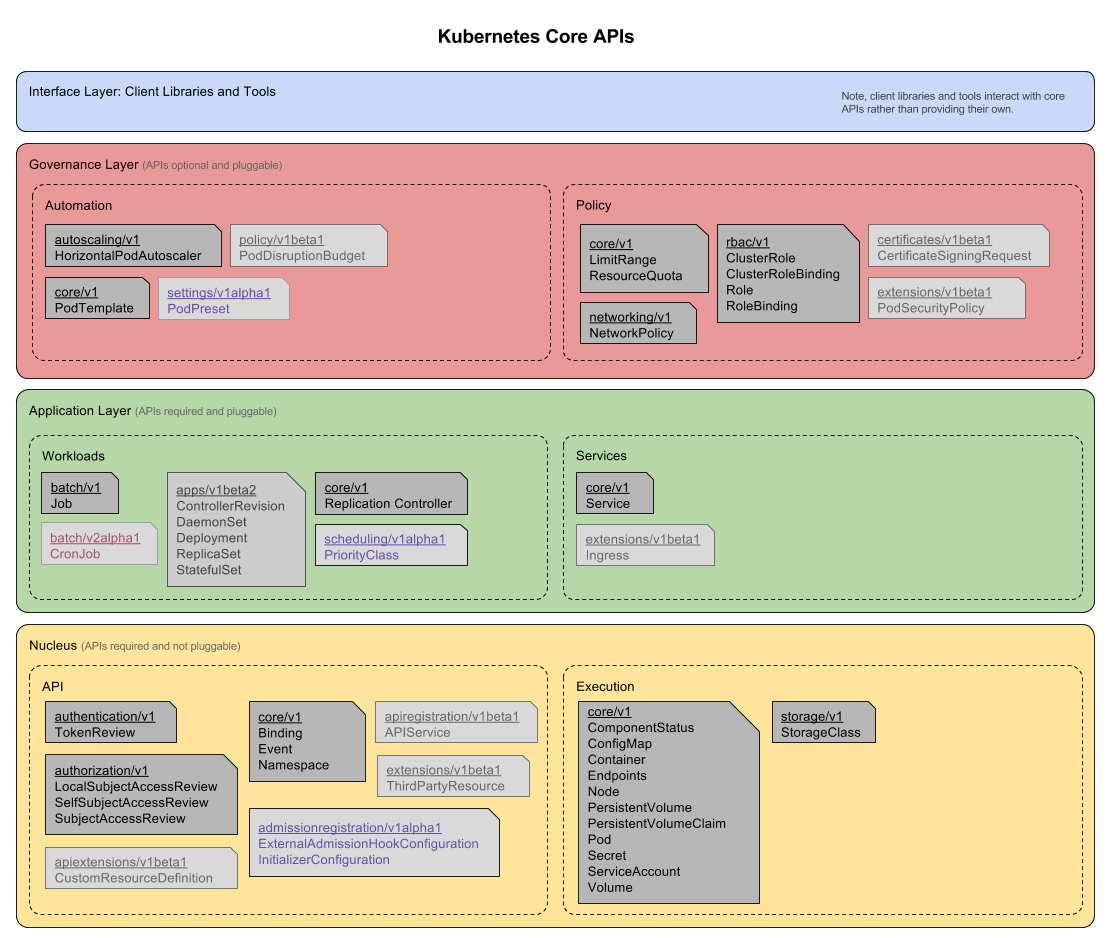
二、核心理念
1、API設計原則
K8s集羣系統每支持一項新功能,引入一項新技術,一定會新引入對應的API對象
1)所有API應該是聲明式的。
2)API對象是彼此互補而且可組合的。這裏面實際是鼓勵API對象儘量實現面向對象設計時的要求,即“高內聚,鬆耦合”,對業務相關的概念有一個合適的分解,提高分解出來的對象的可重用性。事實上,K8s這種分佈式系統管理平臺,也是一種業務系統,只不過它的業務就是調度和管理容器服務。
3)K8s的高層API設計,一定是以K8s的業務爲基礎出發,也就是以系統調度管理容器的操作意圖爲基礎設計。
4)低層API根據高層API的控制需要設計。設計實現低層API的目的,是爲了被高層API使用,考慮減少冗餘、提高重用性的目的,低層API的設計也要以需求爲基礎,要儘量抵抗受技術實現影響的誘惑。
5)儘量避免簡單封裝,不要有在外部API無法顯式知道的內部隱藏的機制。簡單的封裝,實際沒有提供新的功能,反而增加了對所封裝API的依賴性。內部隱藏的機制也是非常不利於系統維護的設計方式,例如PetSet和ReplicaSet,本來就是兩種Pod集合,那麼K8s就用不同API對象來定義它們,而不會說只用同一個ReplicaSet,內部通過特殊的算法再來區分這個ReplicaSet是有狀態的還是無狀態。
6)API操作複雜度與對象數量成正比。這一條主要是從系統性能角度考慮,要保證整個系統隨着系統規模的擴大,性能不會迅速變慢到無法使用,那麼最低的限定就是API的操作複雜度不能超過O(N),N是對象的數量,否則系統就不具備水平伸縮性了。
7)API對象狀態不能依賴於網絡連接狀態。由於衆所周知,在分佈式環境下,網絡連接斷開是經常發生的事情,因此要保證API對象狀態能應對網絡的不穩定,API對象的狀態就不能依賴於網絡連接狀態。
8)儘量避免讓操作機制依賴於全局狀態,因爲在分佈式系統中要保證全局狀態的同步是非常困難的。2、控制機制設計原則
1)控制邏輯應該只依賴於當前狀態。這是爲了保證分佈式系統的穩定可靠,對於經常出現局部錯誤的分佈式系統,如果控制邏輯只依賴當前狀態,那麼就非常容易將一個暫時出現故障的系統恢復到正常狀態,因爲你只要將該系統重置到某個穩定狀態,就可以自信的知道系統的所有控制邏輯會開始按照正常方式運行。
2)假設任何錯誤的可能,並做容錯處理。在一個分佈式系統中出現局部和臨時錯誤是大概率事件。錯誤可能來自於物理系統故障,外部系統故障也可能來自於系統自身的代碼錯誤,依靠自己實現的代碼不會出錯來保證系統穩定其實也是難以實現的,因此要設計對任何可能錯誤的容錯處理。
3)儘量避免複雜狀態機,控制邏輯不要依賴無法監控的內部狀態。因爲分佈式系統各個子系統都是不能嚴格通過程序內部保持同步的,所以如果兩個子系統的控制邏輯如果互相有影響,那麼子系統就一定要能互相訪問到影響控制邏輯的狀態,否則,就等同於系統裏存在不確定的控制邏輯。
4)假設任何操作都可能被任何操作對象拒絕,甚至被錯誤解析。由於分佈式系統的複雜性以及各子系統的相對獨立性,不同子系統經常來自不同的開發團隊,所以不能奢望任何操作被另一個子系統以正確的方式處理,要保證出現錯誤的時候,操作級別的錯誤不會影響到系統穩定性。
5)每個模塊都可以在出錯後自動恢復。由於分佈式系統中無法保證系統各個模塊是始終連接的,因此每個模塊要有自我修復的能力,保證不會因爲連接不到其他模塊而自我崩潰。
6)每個模塊都可以在必要時優雅地降級服務。所謂優雅地降級服務,是對系統魯棒性的要求,即要求在設計實現模塊時劃分清楚基本功能和高級功能,保證基本功能不會依賴高級功能,這樣同時就保證了不會因爲高級功能出現故障而導致整個模塊崩潰。根據這種理念實現的系統,也更容易快速地增加新的高級功能,以爲不必擔心引入高級功能影響原有的基本功能。3、架構設計原則
1)只有apiserver可以直接訪問etcd存儲,其他服務必須通過Kubernetes API來訪問集羣狀態
2)單節點故障不應該影響集羣的狀態
3)在沒有新請求的情況下,所有組件應該在故障恢復後繼續執行上次最後收到的請求(比如網絡分區或服務重啓等)
4)所有組件都應該在內存中保持所需要的狀態,apiserver將狀態寫入etcd存儲,而其他組件則通過apiserver更新並監聽所有的變化
5)優先使用事件監聽而不是輪詢三、核心概念和API對象
API對象是K8s集羣中的管理操作單元。K8s集羣系統每支持一項新功能,引入一項新技術,一定會新引入對應的API對象,支持對該功能的管理操作
1、對象屬性
每個API對象都有3大類屬性:元數據metadata、規範spec和狀態status
1)元數據metadata
標識API對象的,每個對象都至少有3個元數據:namespace,name和uid;除此以外還有各種各樣的標籤labels用來標識和匹配不同的對象
2)規範spec
規範描述了用戶期望K8s集羣中的分佈式系統達到的理想狀態(Desired State),比如啓動的pod副本數
3)狀態status
系統實際當前達到的狀態(Status)
2、Pod
Pod是在K8s集羣中運行部署應用或服務的最小單元,它是可以支持多容器的。Pod的設計理念是支持多個容器在一個Pod中共享網絡地址和文件系統,可以通過進程間通信和文件共享這種簡單高效的方式組合完成服務
Pod對多容器的支持是K8s最基礎的設計理念。比如你運行一個操作系統發行版的軟件倉庫,一個Nginx容器用來發布軟件,另一個容器專門用來從源倉庫做同步,這兩個容器的鏡像不太可能是一個團隊開發的,但是他們一塊兒工作才能提供一個微服務;這種情況下,不同的團隊各自開發構建自己的容器鏡像,在部署的時候組合成一個微服務對外提供服務。
Pod是K8s集羣中所有業務類型的基礎,可以看作運行在K8s集羣中的小機器人,不同類型的業務就需要不同類型的小機器人去執行。目前K8s中的業務主要可以分爲長期伺服型(long-running)、批處理型(batch)、節點後臺支撐型(node-daemon)和有狀態應用型(stateful application);分別對應的小機器人控制器爲Deployment、Job、DaemonSet和PetSet,本文後面會一一介紹。
3、副本集(Replica Set,RS)
副本控制器(Replication Controller,RC)
RC是K8s集羣中最早的保證Pod高可用的API對象。通過監控運行中的Pod來保證集羣中運行指定數目的Pod副本。指定的數目可以是多個也可以是1個;少於指定數目,RC就會啓動運行新的Pod副本;多於指定數目,RC就會殺死多餘的Pod副本
RS是新一代RC,提供同樣的高可用能力,區別主要在於RS後來居上,能支持更多種類的匹配模式。副本集對象一般不單獨使用,而是作爲Deployment的理想狀態參數使用。
4、部署(Deployment)
部署表示用戶對K8s集羣的一次更新操作。部署是一個比RS應用模式更廣的API對象,可以是創建一個新的服務,更新一個新的服務,也可以是滾動升級一個服務。滾動升級一個服務,實際是創建一個新的RS,然後逐漸將新RS中副本數增加到理想狀態,將舊RS中的副本數減小到0的複合操作;這樣一個複合操作用一個RS是不太好描述的,所以用一個更通用的Deployment來描述。以K8s的發展方向,未來對所有長期伺服型的的業務的管理,都會通過Deployment來管理。
5、服務(Service)/Ingress
RC、RS和Deployment只是保證了支撐服務的微服務Pod的數量,但是沒有解決如何訪問這些服務的問題。一個Pod只是一個運行服務的實例,隨時可能在一個節點上停止,在另一個節點以一個新的IP啓動一個新的Pod,因此不能以確定的IP和端口號提供服務。要穩定地提供服務需要服務發現和負載均衡能力。服務發現完成的工作,是針對客戶端訪問的服務,找到對應的的後端服務實例。在K8s集羣中,客戶端需要訪問的服務就是Service對象。每個Service會對應一個集羣內部有效的虛擬IP,集羣內部通過虛擬IP訪問一個服務。在K8s集羣中微服務的負載均衡是由Kube-proxy實現的。Kube-proxy是K8s集羣內部的負載均衡器。它是一個分佈式代理服務器,在K8s的每個節點上都有一個;這一設計體現了它的伸縮性優勢,需要訪問服務的節點越多,提供負載均衡能力的Kube-proxy就越多,高可用節點也隨之增多。與之相比,我們平時在服務器端做個反向代理做負載均衡,還要進一步解決反向代理的負載均衡和高可用問題。
Ingress: 可以給 service 提供集羣外部訪問的 URL、負載均衡、SSL 終止、HTTP 路由等
6、任務(Job)/CronJob
Job是K8s用來控制批處理型任務的API對象。批處理業務與長期伺服業務的主要區別是批處理業務的運行有頭有尾,而長期伺服業務在用戶不停止的情況下永遠運行。Job管理的Pod根據用戶的設置把任務成功完成就自動退出了。成功完成的標誌根據不同的spec.completions策略而不同:單Pod型任務有一個Pod成功就標誌完成;定數成功型任務保證有N個任務全部成功;工作隊列型任務根據應用確認的全局成功而標誌成功。
CronJob:CronJob 即定時任務,就類似於 Linux 系統的 crontab,在指定的時間週期運行指定的任務。
7、後臺支撐服務集(DaemonSet)
長期伺服型和批處理型服務的核心在業務應用,可能有些節點運行多個同類業務的Pod,有些節點上又沒有這類Pod運行;而後臺支撐型服務的核心關注點在K8s集羣中的節點(物理機或虛擬機),要保證每個節點上都有一個此類Pod運行。節點可能是所有集羣節點也可能是通過nodeSelector選定的一些特定節點。典型的後臺支撐型服務包括,存儲,日誌和監控等在每個節點上支持K8s集羣運行的服務。
8、StatefulSets (原名PetSets)
StatefulSets(有狀態系統服務設計)在Kubernetes 1.7中還是beta特性,同時StatefulSets是1.4 版本中PetSets的替代品。
K8s在1.3版本里發佈了Alpha版的PetSet功能。在雲原生應用的體系裏,有下面兩組近義詞;第一組是無狀態(stateless)、牲畜(cattle)、無名(nameless)、可丟棄(disposable);第二組是有狀態(stateful)、寵物(pet)、有名(having name)、不可丟棄(non-disposable)。RC和RS主要是控制提供無狀態服務的,其所控制的Pod的名字是隨機設置的,一個Pod出故障了就被丟棄掉,在另一個地方重啓一個新的Pod,名字變了、名字和啓動在哪兒都不重要,重要的只是Pod總數;而PetSet是用來控制有狀態服務,PetSet中的每個Pod的名字都是事先確定的,不能更改。PetSet中Pod的名字的作用,並不是《千與千尋》的人性原因,而是關聯與該Pod對應的狀態。
對於RC和RS中的Pod,一般不掛載存儲或者掛載共享存儲,保存的是所有Pod共享的狀態,Pod像牲畜一樣沒有分別(這似乎也確實意味着失去了人性特徵);對於PetSet中的Pod,每個Pod掛載自己獨立的存儲,如果一個Pod出現故障,從其他節點啓動一個同樣名字的Pod,要掛載上原來Pod的存儲繼續以它的狀態提供服務。
適合於PetSet的業務包括數據庫服務MySQL和PostgreSQL,集羣化管理服務Zookeeper、etcd等有狀態服務。PetSet的另一種典型應用場景是作爲一種比普通容器更穩定可靠的模擬虛擬機的機制。傳統的虛擬機正是一種有狀態的寵物,運維人員需要不斷地維護它,容器剛開始流行時,我們用容器來模擬虛擬機使用,所有狀態都保存在容器裏,而這已被證明是非常不安全、不可靠的。使用PetSet,Pod仍然可以通過漂移到不同節點提供高可用,而存儲也可以通過外掛的存儲來提供高可靠性,PetSet做的只是將確定的Pod與確定的存儲關聯起來保證狀態的連續性。PetSet還只在Alpha階段,後面的設計如何演變,我們還要繼續觀察。
9、集羣聯邦(Federation)
K8s在1.3版本里發佈了beta版的Federation功能。在雲計算環境中,服務的作用距離範圍從近到遠一般可以有:同主機(Host,Node)、跨主機同可用區(Available Zone)、跨可用區同地區(Region)、跨地區同服務商(Cloud Service Provider)、跨雲平臺。K8s的設計定位是單一集羣在同一個地域內,因爲同一個地區的網絡性能才能滿足K8s的調度和計算存儲連接要求。而聯合集羣服務就是爲提供跨Region跨服務商K8s集羣服務而設計的。
每個K8s Federation有自己的分佈式存儲、API Server和Controller Manager。用戶可以通過Federation的API Server註冊該Federation的成員K8s Cluster。當用戶通過Federation的API Server創建、更改API對象時,Federation API Server會在自己所有註冊的子K8s Cluster都創建一份對應的API對象。在提供業務請求服務時,K8s Federation會先在自己的各個子Cluster之間做負載均衡,而對於發送到某個具體K8s Cluster的業務請求,會依照這個K8s Cluster獨立提供服務時一樣的調度模式去做K8s Cluster內部的負載均衡。而Cluster之間的負載均衡是通過域名服務的負載均衡來實現的。
所有的設計都儘量不影響K8s Cluster現有的工作機制,這樣對於每個子K8s集羣來說,並不需要更外層的有一個K8s Federation,也就是意味着所有現有的K8s代碼和機制不需要因爲Federation功能有任何變化。
10、存儲卷(Volume)
K8s集羣中的存儲卷跟Docker的存儲卷有些類似,只不過Docker的存儲卷作用範圍爲一個容器,而K8s的存儲卷的生命週期和作用範圍是一個Pod。每個Pod中聲明的存儲卷由Pod中的所有容器共享。K8s支持非常多的存儲卷類型,特別的,支持多種公有云平臺的存儲,包括AWS,Google和Azure雲;支持多種分佈式存儲包括GlusterFS和Ceph;也支持較容易使用的主機本地目錄hostPath和NFS。K8s還支持使用Persistent Volume Claim即PVC這種邏輯存儲,使用這種存儲,使得存儲的使用者可以忽略後臺的實際存儲技術(例如AWS,Google或GlusterFS和Ceph),而將有關存儲實際技術的配置交給存儲管理員通過Persistent Volume來配置。
11、持久存儲卷(Persistent Volume,PV)和持久存儲卷聲明(Persistent Volume Claim,PVC)
PV和PVC使得K8s集羣具備了存儲的邏輯抽象能力,使得在配置Pod的邏輯裏可以忽略對實際後臺存儲技術的配置,而把這項配置的工作交給PV的配置者,即集羣的管理者。存儲的PV和PVC的這種關係,跟計算的Node和Pod的關係是非常類似的;PV和Node是資源的提供者,根據集羣的基礎設施變化而變化,由K8s集羣管理員配置;而PVC和Pod是資源的使用者,根據業務服務的需求變化而變化,有K8s集羣的使用者即服務的管理員來配置。
12、節點(Node)
K8s集羣中的計算能力由Node提供,最初Node稱爲服務節點Minion,後來改名爲Node。K8s集羣中的Node也就等同於Mesos集羣中的Slave節點,是所有Pod運行所在的工作主機,可以是物理機也可以是虛擬機。不論是物理機還是虛擬機,工作主機的統一特徵是上面要運行kubelet管理節點上運行的容器。
13、密鑰對象(Secret)/ConfigMap
Secret是用來保存和傳遞密碼、密鑰、認證憑證這些敏感信息的對象。使用Secret的好處是可以避免把敏感信息明文寫在配置文件裏。在K8s集羣中配置和使用服務不可避免的要用到各種敏感信息實現登錄、認證等功能,例如訪問AWS存儲的用戶名密碼。爲了避免將類似的敏感信息明文寫在所有需要使用的配置文件中,可以將這些信息存入一個Secret對象,而在配置文件中通過Secret對象引用這些敏感信息。這種方式的好處包括:意圖明確,避免重複,減少暴漏機會。
ConfigMap 用於保存配置數據的鍵值對,可以用來保存單個屬性,也可以用來保存配置文件。ConfigMap 跟 secret 很類似,但它可以更方便地處理不包含敏感信息的字符串。
14、用戶帳戶(User Account)和服務帳戶(Service Account)
顧名思義,用戶帳戶爲人提供賬戶標識,而服務賬戶爲計算機進程和K8s集羣中運行的Pod提供賬戶標識。用戶帳戶和服務帳戶的一個區別是作用範圍;用戶帳戶對應的是人的身份,人的身份與服務的namespace無關,所以用戶賬戶是跨namespace的;而服務帳戶對應的是一個運行中程序的身份,與特定namespace是相關的。
15、名字空間(Namespace)
名字空間爲K8s集羣提供虛擬的隔離作用,K8s集羣初始有兩個名字空間,分別是默認名字空間default和系統名字空間kube-system,除此以外,管理員可以創建新的名字空間滿足需要。
16、RBAC訪問授權
K8s在1.3版本中發佈了alpha版的基於角色的訪問控制(Role-based Access Control,RBAC)的授權模式。相對於基於屬性的訪問控制(Attribute-based Access Control,ABAC),RBAC主要是引入了角色(Role)和角色綁定(RoleBinding)的抽象概念。在ABAC中,K8s集羣中的訪問策略只能跟用戶直接關聯;而在RBAC中,訪問策略可以跟某個角色關聯,具體的用戶在跟一個或多個角色相關聯。顯然,RBAC像其他新功能一樣,每次引入新功能,都會引入新的API對象,從而引入新的概念抽象,而這一新的概念抽象一定會使集羣服務管理和使用更容易擴展和重用。
注:k8s當前支持的api資源類型: #kubectl api-resources 可以查看
四、kubectl命令介紹
1、kubectl命令
用於運行Kubernetes集羣命令的管理工具
kubectl命令介紹:kubectl [command] [TYPE] [NAME] [flags]
示例:kubectl get nodes master1 -o yaml
[root@master1 dashboard]# kubectl -h
kubectl controls the Kubernetes cluster manager.
Find more information at: https://kubernetes.io/docs/reference/kubectl/overview/
Basic Commands (Beginner):
create Create a resource from a file or from stdin.
expose Take a replication controller, service, deployment or pod and expose it as a new Kubernetes Service
run Run a particular image on the cluster
set Set specific features on objects
Basic Commands (Intermediate):
explain Documentation of resources
get Display one or many resources
edit Edit a resource on the server
delete Delete resources by filenames, stdin, resources and names, or by resources and label selector
Deploy Commands:
rollout Manage the rollout of a resource
scale Set a new size for a Deployment, ReplicaSet, Replication Controller, or Job
autoscale Auto-scale a Deployment, ReplicaSet, or ReplicationController
Cluster Management Commands:
certificate Modify certificate resources.
cluster-info Display cluster info
top Display Resource (CPU/Memory/Storage) usage.
cordon Mark node as unschedulable
uncordon Mark node as schedulable
drain Drain node in preparation for maintenance
taint Update the taints on one or more nodes //增加污點,比如默認創建pod不會調度到master節點上,因爲master有污點
//kubectl describe node master1 |grep -i taints
Troubleshooting and Debugging Commands:
describe Show details of a specific resource or group of resources
logs Print the logs for a container in a pod
attach Attach to a running container
exec Execute a command in a container
port-forward Forward one or more local ports to a pod
proxy Run a proxy to the Kubernetes API server
cp Copy files and directories to and from containers.
auth Inspect authorization
Advanced Commands:
diff Diff live version against would-be applied version
apply Apply a configuration to a resource by filename or stdin
patch Update field(s) of a resource using strategic merge patch
replace Replace a resource by filename or stdin
wait Experimental: Wait for a specific condition on one or many resources. //類似於觸發器
convert Convert config files between different API versions//
kustomize Build a kustomization target from a directory or a remote url.
Settings Commands:
label Update the labels on a resource
annotate Update the annotations on a resource
completion Output shell completion code for the specified shell (bash or zsh)
Other Commands:
api-resources Print the supported API resources on the server
api-versions Print the supported API versions on the server, in the form of "group/version"
config Modify kubeconfig files
plugin Provides utilities for interacting with plugins.
version Print the client and server version information //kubectl version可以顯示client和server的版本
Usage:
kubectl [flags] [options]2、選項options
[root@registry ~]# kubectl options
--alsologtostderr[=false]: 同時輸出日誌到標準錯誤控制檯和文件。
--api-version="": 和服務端交互使用的API版本。
--certificate-authority="": 用以進行認證授權的.cert文件路徑。
--client-certificate="": TLS使用的客戶端證書路徑。
--client-key="": TLS使用的客戶端密鑰路徑。
--cluster="": 指定使用的kubeconfig配置文件中的集羣名。
--context="": 指定使用的kubeconfig配置文件中的環境名。
--insecure-skip-tls-verify[=false]: 如果爲true,將不會檢查服務器憑證的有效性,這會導致你的HTTPS鏈接變得不安全。
--kubeconfig="": 命令行請求使用的配置文件路徑。
--log-backtrace-at=:0: 當日志長度超過定義的行數時,忽略堆棧信息。
--log-dir="": 如果不爲空,將日誌文件寫入此目錄。
--log-flush-frequency=5s: 刷新日誌的最大時間間隔。
--logtostderr[=true]: 輸出日誌到標準錯誤控制檯,不輸出到文件。
--match-server-version[=false]: 要求服務端和客戶端版本匹配。
--namespace="": 如果不爲空,命令將使用此namespace。
--password="": API Server進行簡單認證使用的密碼。
-s, --server="": Kubernetes API Server的地址和端口號。
--stderrthreshold=2: 高於此級別的日誌將被輸出到錯誤控制檯。
--token="": 認證到API Server使用的令牌。
--user="": 指定使用的kubeconfig配置文件中的用戶名。
--username="": API Server進行簡單認證使用的用戶名。
--v=0: 指定輸出日誌的級別。
--vmodule=: 指定輸出日誌的模塊,格式如下:pattern=N,使用逗號分隔。3、摘要
查看幫助:kubectl <command> --help
kubectl annotate – 更新資源的註解。
kubectl api-versions – 以“組/版本”的格式輸出服務端支持的API版本。
kubectl apply – 通過文件名或控制檯輸入,對資源進行配置。
kubectl attach – 連接到一個正在運行的容器。
kubectl autoscale – 對replication controller進行自動伸縮。
kubectl cluster-info – 輸出集羣信息。
kubectl config – 修改kubeconfig配置文件。
kubectl create – 通過文件名或控制檯輸入,創建資源。
kubectl delete – 通過文件名、控制檯輸入、資源名或者label selector刪除資源。
kubectl describe – 輸出指定的一個/多個資源的詳細信息。
kubectl edit – 編輯服務端的資源。
kubectl exec – 在容器內部執行命令。
kubectl expose – 輸入replication controller,service或者pod,並將其暴露爲新的kubernetes service。
kubectl get – 輸出一個/多個資源。
kubectl label – 更新資源的label。
kubectl logs – 輸出pod中一個容器的日誌。
kubectl namespace -(已停用)設置或查看當前使用的namespace。
kubectl patch – 通過控制檯輸入更新資源中的字段。
kubectl port-forward – 將本地端口轉發到Pod。
kubectl proxy – 爲Kubernetes API server啓動代理服務器。
kubectl replace – 通過文件名或控制檯輸入替換資源。
kubectl rolling-update – 對指定的replication controller執行滾動升級。
kubectl run – 在集羣中使用指定鏡像啓動容器。
kubectl scale – 爲replication controller設置新的副本數。
kubectl stop – (已停用)通過資源名或控制檯輸入安全刪除資源。
kubectl version – 輸出服務端和客戶端的版本信息。4、kubectl自動補全
[root@registry ~]# yum install bash-completion
[root@registry ~]# source /usr/share/bash-completion/bash_completion
[root@registry ~]# echo 'source <(kubectl completion bash)' >> ~/.bashrc
[root@registry ~]# source ~/.bashrc5、格式化輸出
-o=custom-columns=<spec> 使用逗號分隔的自定義列列表打印表格
-o=custom-columns-file=<filename> 使用 文件中的自定義列模板打印表格
-o=json 輸出 JSON 格式的 API 對象
-o=jsonpath=<template> 打印 jsonpath 表達式中定義的字段
-o=jsonpath-file=<filename> 打印由 文件中的 [jsonpath](/docs/user-guide/jsonpath) 表達式定義的字段
-o=name 僅打印資源名稱
-o=wide 以純文本格式輸出任何附加信息,對於 Pod ,包含節點名稱
-o=yaml 輸出 YAML 格式的 API 對象使用 -v 或 --v 標誌跟着一個整數來指定日誌級別。這裏 描述了通用的 kubernetes 日誌約定和相關的日誌級別。
--v=0 總是對操作人員可見。
--v=1 合理的默認日誌級別,如果您不需要詳細輸出。
--v=2 可能與系統的重大變化相關的,有關穩定狀態的信息和重要的日誌信息。這是對大多數系統推薦的日誌級別。
--v=3 有關更改的擴展信息。
--v=4 調試級別詳細輸出。
--v=6 顯示請求的資源。
--v=7 顯示HTTP請求的header。
--v=8 顯示HTTP請求的內容。更多kubectl用法請參考:https://kubernetes.io/docs/reference/kubectl/overview/
參考博客:
https://github.com/kubernetes/kubernetes/tree/release-1.2/docs/design
https://github.com/kubernetes/community/blob/master/contributors/design-proposals/architecture/architecture.md
https://feisky.gitbooks.io/kubernetes/content/introduction/
https://www.kubernetes.org.cn/k8s
http://docs.kubernetes.org.cn/227.html