




Risc-V簡要概括
1.Risc-V硬件平臺術語
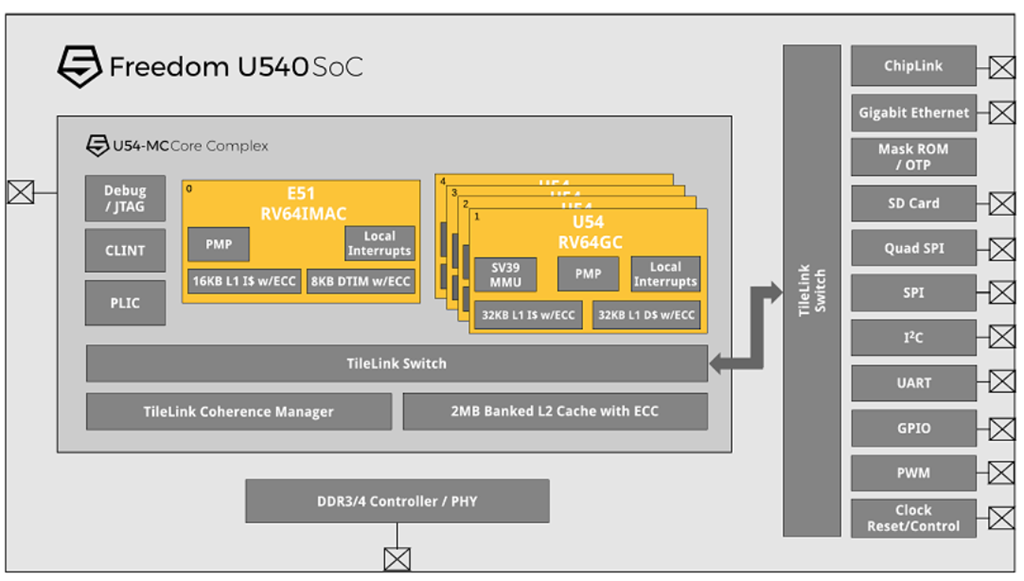
一個RiscV硬件平臺可以包含一個或多個RiscV兼容的核心、其它非RiscV兼容的核心、固定功能的加速器、各種物理存儲器結構、I/O設備以及允許這些部件相互連通的互聯結構。比如下面的SiFive Freedom U540平臺。就包括4個U54 RiscV RV64GC兼容核心,以及一個E51 RV64IMAC核心,DDR3/DDR4內存控制器接口,各種外設I/O接口,以及內部互聯的TileLink協議架構等等。
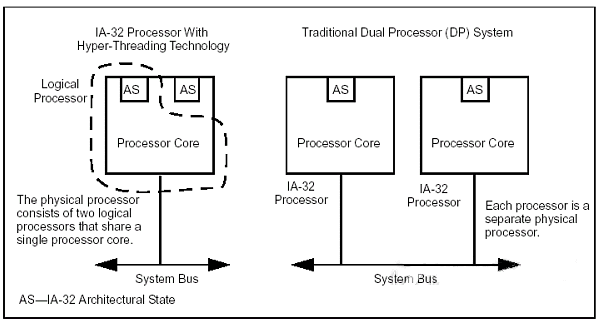
如果一個部件包含了一個獨立的取指令單元,則該部件被稱爲核心(core)。一個RiscV兼容的核心能夠通過多線程技術(或者說超線程技術)支持多個RiscV兼容硬件線程(harts),harts這兒就是指硬件線程, hardware thread的意思。所謂超線程技術,就是在一個硬件核中,實現多份硬件線程,每個硬件線程都有自己獨立的寄存器組等上下文資源,但大多數的運算資源都被所有線程複用,因此面積效率很高。超線程最早出現是在Intel的處理器中,下圖左邊是使用超線程技術的Intel處理器核,每個核心只有一個PU單元,但是有兩個AS單元,所以可以同時支持兩個物理線程,但這兩個物理線程通過調度共享PU單元。
1)Processing Unit(運算處理單元),簡稱PU
2)Architectual State(架構狀態單元),簡稱AS
PU一般就是執行運算,比如算數運算加減乘除。AS執行一些邏輯和調度方面的操作,比如控制內存訪問等。
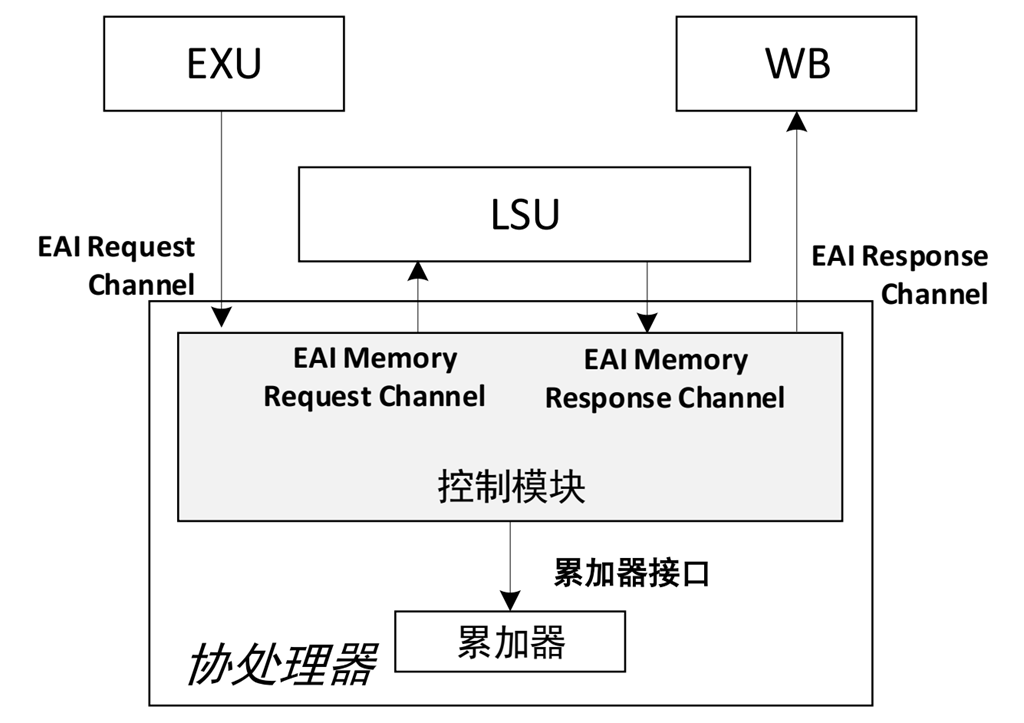
一個RiscV核心可能有額外的專有指令集擴展或者專門增加一個協處理器(coprocessor)去執行一些擴展的指令。我們使用術語協處理器,指的是一個連接到RiscV核心的單元,它執行的指令來自RiscV核心,它和RiscV核心之間通過總線相連。協處理器可能會包含一些其它的體系結構設計或者指令集擴展。相對於主控的RiscV核,協處理器通常都有一定自主處理功能。比如蜂鳥E200系列中,就有一個協處理器,主要是用RiscV的custome定製指令來做一些矩陣運算。協處理器核主控核之間通過EAI協議互連,協處理器也有自己的內存讀寫單元。
RiscV平臺中加速器(accelerator) 通常指的是一個不可編程的固定功能單元,或者是一個可以自主工作,但專門用於某項任務的核心。在RiscV中,我們預期很多可編程加速器將會是基於RiscV核心的,包括專門的指令集擴展,以及定製化的協處理器。一類重要的RiscV加速器是I/O加速器,它將I/O處理任務從主控核心轉移到I/O加速器。比如PCI I/O 加速器。
RiscV硬件平臺的系統級組織結構,可以從單個核心的微控制器,到一個擁有共享存儲器的衆核服務器作爲節點的大型集羣系統。即使小型的片上系統也可能是結構化的,包含層次化的多個計算機或者多個處理器,以便能夠模塊化設計研發或者在不同的子系統之間提供安全隔離。
2. Risc-V軟件執行環境和Hart
一個RiscV程序的行爲依賴於它運行時的執行環境。通常,RiscV的執行環境接口(EEI, execution enviorments interface)具有以下功能:定義程序的初始狀態;在特權模式和非特權模式環境中harts的數目以及類型;內存以及I/O的可訪問性以及其它特性;每個hart中所有合法執行的指令的行爲(指令集可以看作是EEI的一部分);以及程序執行過程中中斷和異常的處理等等。比如ABI(Linux application binary interface,linux應用二進制接口)以及SBI(RiscV-supervior binary interface,riscV管理二進制接口)就是典型的EEI接口例子。
RiscV EEI的實現可以是純硬件實現,也可以是純軟件實現,或者軟硬結合的實現方式。例如,程序執行時候遇到一個硬件不支持的操作碼,進入操作碼自陷處理函數或者軟件模擬都可以用來處這個理硬件不支持的功能。
EEI主要包括以下幾種實現方式:
- bare mental(裸金屬),也就是純物理硬件實施的方式,所有的harts都是純物理核線程,指令都能夠完全訪問所有的物理地址空間。在電源復位時候,硬件平臺將定義所有的執行環境。
- RiscV操作系統通過複用用戶層的harts,把它們映射到可利用的物理核線程中,通過虛擬內存機制來訪問系統內存,從而提供多個用戶層的執行環境。
- RiscV管理程序負責爲客戶操作系統提供多個監督模式下的執行環境。
- RiscV模擬器,這些都是純軟件的實現方式,比如Spike, QEMU, 以及rv8等等,它們都在x86系統中模擬了RiscV的harts實現,提供了在用戶模式和監督模式下的執行環境。
通常的EEI 都是分層實現的,比如最底層用純硬件實現EEI,而高層定義更加抽象的EEI接口 ,這樣頂層的EEI可以對應不同的硬件實施平臺。
在一個給定執行環境中,從軟件的觀點來看,一個hart就是在執行環境中自動取指以及執行指令。這樣來說,即使真實的硬件在執行環境中是分時複用的,但一個hart行爲也和硬件線程非常相像。一些EEIs支持附加的hart創建和銷燬,例如通過環境調用產生新的harts。
3. Risc-V指令集概括
Risc-V的基礎指令集是整數指令集,在任何架構方案中,必須完整實現基礎的整數指令集。在整數指令集中,用補碼錶示有符號整數。
主要有四個基礎指令集,它們主要通過整數寄存器的長度來區分,比如RV32I,在該指令集方案中,整數寄存器的長度爲32位,在RV64I指令集方案中,整數寄存器的長度爲64位。對於RV32I,由於整數寄存器是32位,所以可以提供2^32=4GB的地址訪問空間,對於RV64I,整數寄存器是64位,所以可以提供2^64=4194304TB的地址訪問空間,這是一個非常大的地址空間。我們通常用xlen表示整數寄存器位數或者說地址空間位數,所以對於RV32I, xlen=32, 對於RV64I, xlen=64。
在整數指令集的基礎上,可以選擇實現擴展模塊,比如RV32IMAFDC,表示當前實現支持這些模塊的組合,其中IMAFD是通用組合,用字母G表示,所以RV32IMAFDC,也可以寫作RV32GC。現在的Risc-V編譯工具鏈,重點會支持RV32G和RV64G。
RiscV的指令集主要包括以下模塊:
基礎模塊:
RVWMO, V2.0, 批准(Ratified): RiscV內存一致性模型。
RV32I, V2.1, 批准(Ratified): 基礎的32位整數指令集,32位地址空間,寄存器是32位。
RV64I,V2.1,批准(Ratified): 基礎的64位整數指令集,64位地址空間,寄存器是64位。
RV32E, V1.9, 草案(Draft): 嵌入式架構,僅有16個整數寄存器。
RV128I,V1.7,草案(Draft): 基礎的的128位整數指令集,支持128位地址空間。
擴展模塊:
ZiFencei,V2.0,批准(Ratified): Instruction-Fetch Fence。
Zicsr, V2.0, 批准(Ratified): 控制和狀體寄存器指令。
M, V2.0, 批准(Ratified): 支持乘法和除法指令。
A,V2.0,凍結(Freeze): 支持原子操作指令和Load-Reserved/store-Conditional指令。
F,V2.2,批准(Ratified): 單精度浮點指令。
D,V2.2,批准(Ratified): 雙精度浮點指令。
Q,V2.2,批准(Ratified): 四精度浮點指令。
C,V2.0,批准(Ratified): 支持編碼長度爲16的壓縮指令。
Ztso, V0.1, 凍結(Freeze): Total Store ordering。
Counters, V2.0, 草案(Draft): 性能統計Counters
L,V0.0, 草案(Draft): 十進制浮點數,IEEE754-2008。
B,V0.0,草案(Draft): 位操作指令。
J,V0.0, 草案(Draft): 支持動態轉化語言。
T,V0.0,草案(Draft): transactional memory operations。
P,V0.2,草案(Draft): Packed-SIMD Instructions。
V,V0.2,草案(Draft): 向量操作指令。
N,V1.1,草案(Draft): 用戶層的終端和異常指令。
Zam,V0.1,草案(Draft): 非對齊的原子指令。
4. 內存(memory)
一個字節(byte)是8bits,一個字(word)是32bits,4個字節長度。相應的,半字(halfword)是16bits,雙字(double workd)是64bits,四字(quadword)是128bits。一個RiscV hart可以訪問2^xlen字節地址空間。通常,內存地址空間是環形的,所以地址空間0和2^xlen-1是鄰接的,硬件將忽略地址溢出,而是將訪問地址模一個2^xlen,得到最終的訪問地址 。比如訪問地址2^xlen+1,實際上訪問就是地址1。
執行環境決定硬件資源如何映射到hart的地址空間。hart地址空間中不同的地址範圍對應不同硬件資源,比如主存,I/O設備,也有可能是沒有對應硬件資源的地址範圍,訪問這些範圍地址,可能會引起異常。 比如蜂鳥E200 RiscV核,是32bit的地址空間,hart可以訪問4GB的地址範圍,0x0-0xFFFF_FFFF,但實際上對應的硬件資源只使用一部分的地址空間:
ITCM 64K,地址範圍:0x8000_0000-0x8000_FFFF
DTCM 64K,地址範圍:0x9000_0000-0x9000_FFFF
PPI 地址範圍: 0x1000_0000 – 0x1FFF_FFFF
CLINT 地址範圍: 0x0200_0000 – 0x0200_FFFF
PLIC 地址範圍: 0x0C00_0000 – 0x0CFF_FFFF
FIO 地址範圍: 0xF000_FFFF – 0xFFFF_FFFF
當RiscV平臺有多個harts時候,每個hart的地址空間可能是完全相同的,也可能是完全不同的,或者部分不同,但共享一些映射到相同或不同地址的硬件。在純硬件實現的環境中,所有harts的地址空間是相同的,都是完全訪問的物理地址空間。但執行環境包括一個支持虛擬地址操作系統的時候,通常每個hart訪問的地址都是大範圍虛擬地址,但該地址最終會被地址轉化模塊轉化爲真正的物理地址,不同的虛擬地址可能會映射到相同的物理地址。
RiscV指令分爲顯式內存訪問和隱式內存訪問。在主存和RiscV核心之間,可能存在一級或者多級cache,所以有些指令,比如load和store指令讀寫內存時候,可能會cache hit,這個時候不需要內存訪問,如果cache miss的化,則需要內存訪問。有時候,即使cache hit,雖然沒有直接訪問內存,但可能隱含了虛擬地址到物理地址的轉化,則需要訪問內存中的PTE表,所以是隱式的內存訪問。
由於RiscV指令可以亂序執行,有時候爲了保證讀寫順序,比如確保store指令寫某個內存地址執行完成後,再用load指令讀該地址,則可以在兩條指令之間,增加一條fence指令來進行同步操作,確保RAW(read after write)。RiscV實施的內存模型是Weak Memory Ordering (RVWMO), 後面我們會詳細解釋這種模型的細節。
5.Risv-V的指令編碼規則:
基礎的RiscV指令集,比如RV32I,RV64I中,所有指令長度都是固定的32bits,在這些RiscV實施方案中,指令訪問必須32bit地址對齊。但是標準的RiscV指令編碼方案是支持其它指令長度的,只要指令長度是16bit的倍數,這時候,指令訪問是16bit地址對齊的。比如標準的壓縮指令RVC,指令長度就是16bit的。在嵌入式系統中,使用16bit的編碼可以提高代碼密度,減少功耗。我們用IALIGN來表示指令地址必須對齊的位數。在標準指令集中,IALIGN=32,RVC中,IALIGN=16,當然在擴展指令中,你也可以實施16倍數的其它指令編碼,比如IALIGN=64等等。
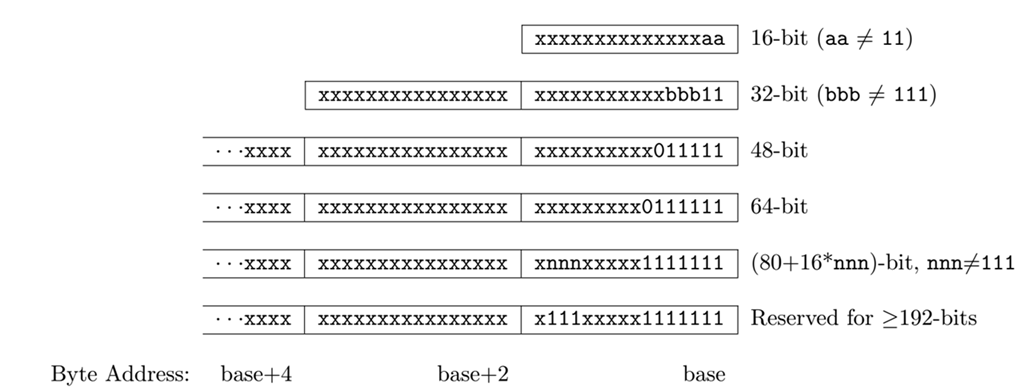
我們用術語ILEN表示RiscV實施中最大的指令長度,它總是IALIGN的倍數。如果RiscV僅實施了基礎指令集,那麼ILEN=32,如果實施了更長的指令長度方案,則ILEN有更大的值。所有的32bit指令,低兩位都是11。對於16位壓縮指令,它的低兩位不等於11,可以是00,01,10。對於RV32,它的[1:0]=11,[4:2]不等於111。對於64位指令,它的低7位爲0111111。低16位是全0或者全1的編碼都是不合法的,會導致異常。注意:RiscV中僅支持小頭格式(little-edian),就是高位存在高地址,低位存在低地址,比如32bit數0x12345678,存在地址0x0-03,則mem[0]=78,mem[1]=56,mem[2]=34,mem[3]=12。
6. 異常(Exceptions),自陷(Trap)和中斷(Interrupts)
異常:運行時出現了一個與當前RiscV線程中的一條指令相關的非正常的情況。
自陷:在一個RiscV線程中出現了一個異常或者中斷,導致將控制同步傳輸到自陷處理函數。自陷處理函數通常是在一個更高特權環境中執行的(注意,浮點異常不會自陷)。
中斷:當前RiscV線程外異步出現一個事件。
自陷如何被處理以及是否對hart上運行的軟件可見都依賴於執行環境。從執行環境中運行的軟件的觀點來看,一個hart在運行時的自陷有以下幾種類型。
Contained Trap: 自陷對執行環境中的軟件可見,並被軟件處理。比如執行環境接口給hart提供了監督程序和用戶模式,一個用戶模式的hart執行ecall指令,將會導致把控制權傳輸給相同hart上的監督模式處理程序。相似的,在相同環境中,一個hart被中斷,中斷處理程序將會運行系統hart的監督模式
Requested Trap: 自陷是外部調用產生的異步異常,它通過在執行環境中對軟件發出一個請求產生。比如系統調用,這時執行環境可能不可恢復,hart也許就被終止執行。
Invisible Trap: 自陷對執行環境是透明的,自陷服務程序執行完畢後,hart繼續執行。比如模擬執行不支持的指令;請求虛擬物理地址轉化時,頁表在外部內存中;多個程序運行機器中,處理設備中斷等等情況。在這些情況下,執行環境中運行的軟件並不知道自陷處理的存在。
Fatal Trap: 自陷表示重要的失敗,會引起終止執行環境。比如虛擬地址頁錶轉換失敗,監督的定時器過期等等。每個EEI都應該定義什麼情況下終止執行環境,並把出錯信息報告給外部環境。
下面的表格中例舉了各種自陷的特徵:

Zifencei擴展
fence 指令對外部可見的訪存請求,如設備 I / O 訪問,內存訪問等進行串行化。外部可見是指對處理器的其他核心、線程,外部設備或協處理器可見。
fence.i 指令同步指令和數據流。在執行 fence.i 指令之前,對於同一個硬件線程(hart), RISC-V 不保證用存儲指令寫到指令存儲區的數據可以被取指指令取到。
Zifencei擴展目前僅包括FENCE.I指令。該指令提供了同一個hart中寫指令內存空間和讀指令內存空間之間的顯式同步, 就是說讀取的指令的總是最新寫入的指令。該指令目前是確保指令內存存儲和讀取都對hart可見的唯一標準機制。
fence.i指令可以有各種實現方法,一種簡單的實現就是在執行fence.i指令的時候,沖刷(flush)指令緩存(Icache, instruction cache)和指令管線(instruction pipeline)。沖刷icache和管線的作用是確保指令緩存中的內容和指令內存空間中的數據一致,以及所有寫指令緩存的動作完成(icache通常是隻讀的,但自修改指令可能會需要寫的動作)。這樣確保後續的指令讀取操作正確。
更復雜的實現可能會在每個數據(指令)高速緩存未命中時窺探指令(數據)高速緩存,或者使用統一專用L2高速緩存,L2緩存是全局緩存,所有的riscv核都接在上面,當然riscv核本身有icache和dcache,也就是L1 cache, 如果L2 cache足夠大,對指令數據並沒有一致性問題。對L2的store指令,就去回看L1對應的cacheline是否有效,如果數據有效,就invalidate它。如果指令和數據高速緩存以這種方式保持一致,或者如果存儲器系統僅由未緩存的RAM組成,那麼只需要在FENCE.I處沖刷管線。
FENCE.I指令以前是基本指令集RV32I/RV64I的一部分。現在把它移到擴展指令集Zifencei, 這樣做主要有兩個原因:
首先,在某些系統上,實現FENCE.I代價將是昂貴的,RiscV基金會存儲器模型工作組中正在討論替代機制。特別是,對於具有不一致指令高速緩存和不一致數據高速緩存的設計,或者指令高速緩存不能監視(snoop)數據高速緩存一致性的時候,當遇到FENCE.I指令時,兩個高速緩存必須完全沖刷管線。當在主存和riscv系統全局統一cache的上層(更接近core),有多級的icache和dcache時候,這個問題會更加嚴重。
其次,該指令的功能不足以在類Unix操作系統環境中的用戶級別使用。 FENCE.I僅同步本地hart,操作系統可以在FENCE.I之後將用戶hart重新分配到不同的物理hart。這將要求操作系統執行額外的FENCE.I來進行每個上下文切換。出於這個原因,標準Linux ABI已經從用戶級刪除了FENCE.I,現在需要系統調用來維持指令一致性,這允許操作系統最小化在當前系統上執行FENCE.I的數量,對於將來改進的讀取指令一致性機制,也可以保持向前兼容。一些新的取指令一致性機制仍在討論中,將來會提供fence.i更多的版本。 比如在rs1中指定地址,僅fence指定的rs1地址的訪問。
fence.i 指令同步指令和數據流。在執行 fence.i 指令之前,對於同一個硬件線程(hart), RISC-V 不保證用存儲指令寫到內存指令區的數據可以被取指令取到。使用fence.i指令後,對同一hart,可以確保指令讀取是最近寫到內存指令區域的數據。但是,fence.i將不保證別的riscv hart的指令讀取也能夠滿足讀寫一致性。如果要使寫指令內存空間對所有的hart都滿足一致性要求,需要執行fence指令。
fence.i
fence.i //Fence(Store, Fetch)
同步指令流(Fence Instruction Stream). I-type, RV32I and RV64I.
使對內存指令區域的讀寫,對後續取指令可見。
| imm[11:0] | rs1 | func3 | rd | opcode | |||||||||||||||||||||||||||||
| name | type | 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| fence.i | I | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
例子:
0: 0ff0000f fence iorw,iorw
4: 0000100f fence.i
fence.i指令用於同步指令和數據流。如果程序中添加一個fence.i,則該指令能夠保證fence.i之前所有指令的訪存結果能被fence.i之後的所有指令訪問到。通常說來,處理器的微架構硬件實現時,一旦遇到一條fence.i指令,便會先等到之前的所有訪存指令執行完,然後沖刷流水線,包括Icache,使其後的所有指令,能夠重新取指,從而得到最新的值。
注意:fence.i只能保證同一個hart(硬件線程)執行的指令流和數據流順序,不能保證多個hart之間的指令流和數據流訪問。