




目錄
線上 swap 報警信息
NUMA 架構中 MySQL 的 “swap insanity” 問題
NUMA swap 解決方案
線上 swap 報警信息
近期支付這邊線上核心業務發生MySQL的swap報警:
mem.swap.used.percent>30
線上機器配置爲128G內存,innodb_buffer_pool_size 配置爲100G,當時內存使用情況: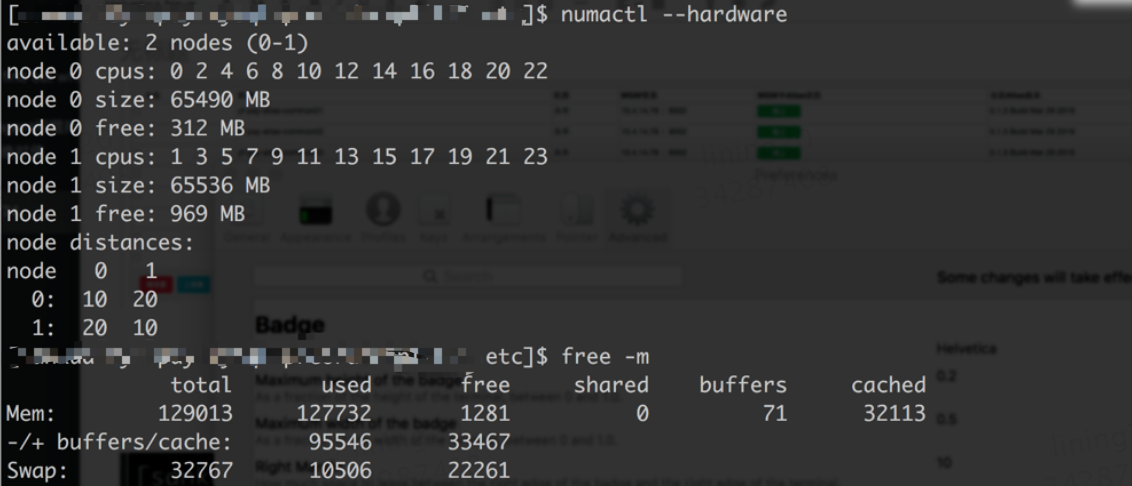
在系統有大量cache的情況下,mysql卻使用到了大量的swap,
分析當時node0和node1節點的內存使用情況如下:
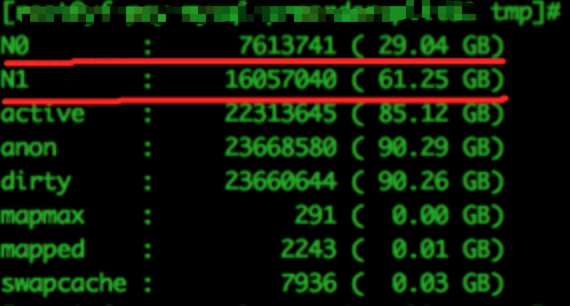
內存分配node1基本使用了全部內存,而node0卻只使用了不到一半內存!
根據這個現象懷疑是NUMA導致的swap,下面對NUMA進行相關的研究和解決方案的探查。
NUMA 架構中 MySQL 的 “swap insanity” 問題
The “swap insanity” problem, in brief
在一臺包括了2個4核CPU,64GB內存的服務器上,給 MySQL 配置了 48GB 之巨的 InnoDB 緩衝,隨着時間的推移,儘管觀察到的數據(見最後注1)表示並沒有真正的內存壓力,Linux 也會把大量的內存交換到磁盤上。通過監控發現,配置的內存超過了實際所需,而且也不存在內存泄漏,mysqld的RSS佔用正常且穩定。
通常來說,少量的交換沒有什麼問題。但在許多情況下,真正有用的內存,尤其是InnoDB緩衝池的主要部分,會被換出。當它再一次被需要時,又會花費很大的性能將它換進,在隨機的查詢會引起隨機的延遲。這可能會在運行系統上造成整體的性能不可預測性,而且一旦開始進行交換,系統可能就會進入性能的“死亡螺旋”。
雖然不是每個系統,或者每個工作負載都會經歷這個問題,但是它已經足夠普通以至於衆所周知,而對於那些十分了解它的人來說,它可能會是一個最主要的麻煩。
The history of “swap insanity”
已經有過許多關於關閉還是開啓Linux swapping和MySQL的討論,這些總被稱爲“swap insanity”(我認爲這是由Kevin Burton創造的)。我緊密關注這些話題,但是我並沒有爲此貢獻很多,因爲我沒有添加任何新的東西。在過去的幾年間,對此討論作出主要貢獻的是:
Kevin Burton — 討論了Linux下的交換和MySQL。
Kevin Burton — 提出使用IO_DIRECT作爲解決方案(並未解決)並且討論了memlock(可能有所幫助,但仍然不是一個完整的解決方案)。
Peter Zaitsev — 討論了交換,內存鎖,並且在評論中進行了一系列的展開討論。
Don MacAskill — 提出一個創新的方案來 swap 到 ramdisk,相關有很多有趣的討論
Dathan Pattishall — 描述了禁止交換後的Linux的行爲可能會更糟糕,並且提出了使用swapoff來清除它,但並未真正解決。
Rik van Riel on the LKML — 給出了一些回答並且提交了Split-LRU補丁
Kevin Burton — 討論了Linux Split-LRU補丁的一些成功之處。
Mark Callaghan — 討論了vmstat和監控方面的事情,並且回顧了一些可能的解決方案。
Kevin Burton — 更多地討論了Linux Split-LRU是優秀的。
Kevin Burton — 通過開啓了交換而選擇了一種折中的方法,但是這樣只有少量空間,而且放棄了這場鬥爭
Peter Zaitsev — 更多地討論了爲什麼交換是糟糕的,但是依然沒有解決方法。
儘管有這麼多的這論,但是並沒有帶來太多的改變。有一些類似於“***式”的解決方法來使得MySQL停止交換,但是什麼都不能確定。我已經瞭解這些解決方案和***式的手法一陣子了,但是核心的問題從來沒有解決:“爲什麼會發生這?”還有它從來不適合我。我最近嘗試去理順這個問題,希望能夠一勞永逸地解決它。因此到目前爲止我做了大量關於這個問題的研究和測試。我學到了很多,我認爲寫一篇博客可能是會分享它的最佳途徑。希望大家喜歡。
從幾年前,已經有許多討論和一些工作進入了加入相對較新的交換方法的調整的方面,我認爲那可能已經解決了一些原始問題,但是此刻,機器的基礎架構已經變爲了NUMA,我認爲這引入了一些新的問題,這些問題有着極爲相似的症狀,並且掩去了原始問題修訂的成功。
對比SMP/UMA和NUMA兩種架構
The SMP/UMA architecture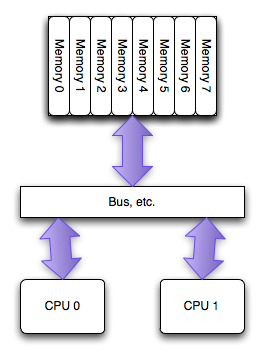
當PC領域最初擁有多處理器時,它們能夠機會均等的進入系統中的所有內存。這叫做對稱多處理器(SMP), 或者有時候叫統一訪存架構(UMA,特意和NUMA進行對比)。在過去的幾年中,每個 socket 上的單個處理器之間訪問內存已經不再使用這種架構,但是在每一個處理器的多個核之間仍然盛行:所有的內核擁有均等的進入內存的機會。
The NUMA architecture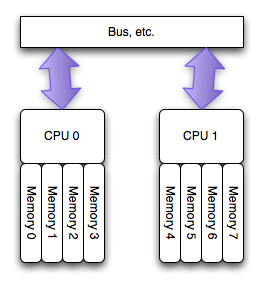
運行在 AMD Opteron 和 Inter Nehalem 處理器(見注2)上的多處理器的新的架構,叫做非勻稱訪存架構(NUMA),更確切的說是一致性緩存非勻稱存儲訪問架構(ccMUMA)。在該架構中,每個處理器擁有一個“本地的”存儲體,使用它可以較快的訪問(延遲小)。整個的系統仍舊可以以整體的形式運行,從任何地方訪問所有的內存,但是這樣有潛在的高延遲和低性能的可能。
從根本上來說,“本地”的那些內存訪問會快些,也就是說,可以比其他的地址(“遠程”的和其他處理器關聯的那些)以更小的代價訪問。如果想得到更詳細的關於NUMA實現的討論以及它在Linux的支持,請去lwn.net上看 Ulrich Drepper 的文章。
How Linux handles a NUMA system
當運行在NUMA架構系統上時,Linux會自動的知道這個事實,並且做以下的事情:
枚舉硬件設施,用來得知物理的佈局。
把處理器(並非內核)分成不同“節點”。對於現代的PC處理器,不考慮內核的數量的話,這意味着一個節點對應一個物理處理器。
將系統中的每個內存模塊和它本地處理器的節點綁定在一起。
收集內部節點通信的代價信息(節點間的“距離”)。
你可以用numactl --hardware命令查看linux是怎麼枚舉你係統上NUMA的佈局
numactl --hardware
available: 2 nodes (0-1)
node 0 size: 32276 MB
node 0 free: 26856 MB
node 1 size: 32320 MB
node 1 free: 26897 MB
node distances:
node 0 1
0: 10 21
1: 21 10
輸出結果裏講了這麼幾件事情:
節點的數量以及這些節點的編號 — 這個例子中,兩種節點被標識爲0和1
每個節點中可用內存的數量 — 一臺雙核計算機共有64G的內存,所以在每個節點上理論上可以分得32G內存。但必須指出的是,在這裏並不是把64G的內存平均分配,這是因爲每個節點的內核需要消耗一些內存。
節點之間的“距離” — 它是從節點1訪問節點0上的內存時,所付出的代價的一種表現形式。這個例子裏,linux爲本地內存聲明距離爲“10”,爲非本地內存聲明的距離爲“21”
NUMA是如何改變 Linux 工作模式的
從技術層面來說,只要一切運行良好,UMA或者NUMA是沒有理由在OS水平級上去改變運行方式。然而,如果要獲得最好的性能,那麼需要要做一些額外的工作,直接去處理NUMA底層的一些事情。如果把CPU和內存當作一個黑盒子,那麼linux會做以下一些意想不到的事情:
每一個進程和線程都繼承成它們的父結點的 NUMA 策略。每個線程都可以修改成獨立的策略。策略包括該進程/線程可在哪些 CPU 甚至內核上運行,從哪裏的內存插槽上申請內存,以及上述兩項限制有多嚴格
初始化時,每一個線程都被分配到一個“首選”的節點上去運行。該線程可以運行在其他任何地方(如果策略允許),但是調度器試圖保證它始終運行在首選的結點上。
爲進程分配的內存被分配在一個特定的節點上,默認情況下是“current”,這意味着相應的線程會首選在同一個節點上運行。在UMA/SMP架構上,所有的內存是一視同仁的,並且有相同的開銷。但是系統如今已經開始考慮它從何而來,這是因爲訪問非本地內存對性能是有影響的,並可能導致高速緩存的一致性延遲。
無論系統需不需要,分配到一個節點的內存肯定不會移動到另一個節點上去。一旦內存分配到一個節點上,那麼它將一直留在那裏。
使用numactl這樣非常簡單的程序,使得任何進程的NUMA策略都是可以改變的,具有廣泛深遠的影響。除此還能做些額外的工作,即通過鏈接到libnuma並寫一些代碼去管理策略,可以使其在細節上做些微調。簡單的應用numactl已經可以做一些有趣的事情:
用特殊的策略分配內存
使用 current 節點 — using --localalloc, and also the default mode
使用某個節點,但是如果有必要也能使用其他的節點 — using --preferred=node
總是使用某個或某組節點 — using --membind=nodes
交錯使用(round-robin )所有節點 — using --interleaved=all or --interleaved=nodes
Run the program on a particular node or set of nodes, in this case that means physical CPUs (--cpunodebind=nodes) or on a particular core or set of cores (--physcpubind=cpus).
What NUMA means for MySQL and InnoDB
InnoDB以及其他所有數據庫服務器( 包括 Oracle 在內),對linux來說都表現爲非典型的工作負載(以大多數程序的角度):一個單一龐大的多線程進程消耗了系統幾乎所有的內存,並且將會不斷消耗系統剩餘資源。
在基於NUMA的系統中,內存被分配到各個節點,系統如何處理這點不是那麼簡單。系統的默認行爲是爲進程運行所在的同一個節點分配內存,這種方式在內存量比較少的情況下效果不錯,但是當你希望分配超過半數的系統內存時,這種方式即便只應用於單一NUMA節點,在物理層面上也變得不再可行:在雙節點系統,每個節點中只有50%的內存。另外,由於大量不同的查詢操作會同時運行在兩個處理器上,任何一個單獨的處理器都無法優先獲取特定查詢所需的那部分特定內存。
這顯然非常重要。使用 /proc/pid/numa_maps 我們可以看到所有mysqld做的分配操作,還有一些關於它們的有意思的信息。如果你進行大量的查找,anon=size,你可以輕易的發現緩存池(它會消耗超過51GB的內存,超過了設置的48GB)
2aaaaad3e000 default anon=13240527 dirty=13223315
swapcache=3440324 active=13202235 N0=7865429 N1=5375098
顯示的各字段如下:
2aaaaad3e000—內存區域的虛擬地址。實際上可以把這個當做該片內存的唯一ID。
default —這塊內存所用的NUMA策略
anon=number—映射的匿名頁面的數量
dirty=number —由於被修改而被認做髒頁的數量。通常在單一進程中分配的內存都會被使用,變成髒頁。但是如果產生一個新進程,它可能有很多copy-on-write pages映射(寫時複製頁),這些可能不是髒頁。
swapcache=number —被交換出但是由於被交換出所以沒有被修改頁面的數量。這些頁面可以在需要的時候被釋放,但是此刻仍然在內存中。
active=number —在“激活列表”中的頁面的數量;如果顯示了該字段,那麼部分內存沒有激活(anon減去active),這也意味着這些可能很快被swapper交換出去。
N0=number and N1=number —節點0和節點1上各自分配的頁面的數量。
整個numa_maps可以用一個簡單的腳本 numa-maps-summary.pl 進行快速的總結:
N0 : 7983584 ( 30.45 GB)
N1 : 5440464 ( 20.75 GB)
active : 13406601 ( 51.14 GB)
anon : 13422697 ( 51.20 GB)
dirty : 13407242 ( 51.14 GB)
mapmax : 977 ( 0.00 GB)
mapped : 1377 ( 0.01 GB)
swapcache : 3619780 ( 13.81 GB)
發現了兩件有趣並出乎意料的事情:
節點0和節點1間內存分配的絕對不平衡。實際上根據默認策略這顯然很正常。使用默認NUMA策略,內存優先分配給節點0,節點1被用作備份。
大量的內存被分配到節點0。這是關鍵 — 節點0用盡了空閒內存!它總共只有32GB內存,同時它分配了一個超過30GB的內存塊放在InnoDB的緩存池中。一些其他進程分配的少量內存把剩餘內存耗盡,此刻沒有任何剩餘內存也無法進行任何緩存。
下圖顯示的是MySQL數據庫的內存分配圖: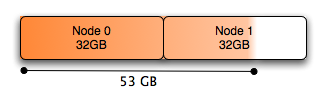
總體來說,Node 0幾乎完全耗盡了空閒的內存,儘管系統有大量的空閒內存(將近有10G用於緩存)給Node 1.如果位於Node 0上的進程調度需要大量的本地內存的話,就會導致已經分配了任務的內存被交換,以滿足一些Node 0頁面的需要。儘管Node 1上存在大量的內存,但是在許多情況下(對這點,到現在我還不理解,見注3),Linux系統內核寧願將Node 0上已分配任務的內存交換,也不願使用Node 1上空閒的內存容量。因爲頁面調度遠遠比本地內存處理花銷更大。
小變化,大效果
上述問題最容易的解決方案是交叉分配內存,運行:
numactl –interleave all command
我們可以憑藉將腳本mysqld_safe.sh只改動一行,在腳本中添加(cmd="$NOHUP_NICENESS"),使得在啓動mysql命令前,啓動numactl命令。該腳本爲已添加(cmd="$NOHUP_NICENESS")命爲的內容:
cmd="$NOHUP_NICENESS"
cmd="/usr/bin/numactl --interleave all $cmd"
for i in "$ledir/$MYSQLD" "$defaults" "--basedir=$MY_BASEDIR_VERSION"
"--datadir=$DATADIR" "$USER_OPTION"
do
修改配置後,會發現當MySQL需要內存得時候,它將採用交叉分配的方式,給所有節點進行分配,使得每個節點都承載有效平衡的內存分配。同時也會在每個節點上留下一些空閒的內存空間,允許Linux內核在兩個節點之間緩存數據,這種方式僅僅釋放緩存的時候(當支持這種情況的時候工作),才允許任何一點節點內存容易釋放,而不是頁面調度的時候。
通過性能迴歸測試,我們已比較了兩種情況下的性能,使用DBT2標準檢測程序(本地內存+溢出內存----交叉內存),最終發現:在一般情況下的性能是等同的,這是可以預料的。突破發生在下面情況:使用交換的所有案例,在重複使用的情況下,系統不再發生交換。
你會看到所有采用numa_maps(NUMA: 非一致內存訪問)分配的內存平均分佈在Node 0和1上:
2aaaaad3e000 interleave=0-1 anon=13359067 dirty=13359067
N0=6679535 N1=6679532
And the summary looks like this:
N0 : 6814756 ( 26.00 GB)
N1 : 6816444 ( 26.00 GB)
anon : 13629853 ( 51.99 GB)
dirty : 13629853 ( 51.99 GB)
mapmax : 296 ( 0.00 GB)
mapped : 1384 ( 0.01 GB)
圖形表示就是這樣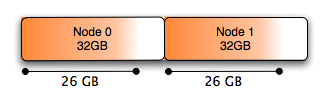
NUMA swap 解決方案
在Linux Kernel啓動參數中加上numa=off(這樣也會影響到其他進程使用NUMA);
在mysqld_safe腳本中加上 "numactl –interleave all" 來啓動mysqld。
5.6.27, 5.7.9 之後mysql提供參數 innodb_numa_interleave 進行控制