HPC系統體系架構
名詞解釋
HPC-High Performance Computing or High Performance Clustering
COW-Cluster of Workstations
NOW-Network of Workstations
PoP-Pile of PCs
HPS-High Performance Switch
MPP-Massi vely Parallel Processing 大規模並行處理
SMP-Symmetrical MultiProcessing 對稱多處理
分佈式計算與並行計算
分佈式計算(Distributed Computing)是一門研究分佈式系統的計算機科學,一個分佈式系統有多臺自治的計算機通過計算機網絡聯網組成,網絡內的計算機(也叫節點)通過協作完成一個共同的任務。分佈式計算也研究如何把一個需要非常巨大的計算能力才能解決的問題分成許多小的部分,然後把這些部分分配給許多計算機進行處理,最後把這些計算結果綜合起來得到最終的結果。
並行計算(Parallel Computing)這個詞的出現比分不是計算稍晚,其定義和分佈式計算的含義基本相同,也可以把並行計算說成是分佈式計算的一種。分佈式計算和並行計算沒有嚴格意義上的定義,但業界一般認爲分佈式系統是一種鬆耦合(Loosly-coupled)架構,而並行計算(Massively Parallel)系統是一種緊耦合(Tighly-coupled)架構。
HPC系統體系架構
Flynn-Johnson分類法
有很多HPC體系架構分類方法,其中Michael Flynn的分類法在1996年提出後被大家廣爲接受。Flynn分類法是根據計算機指令對數據的處理方式進行分類的,共4種組合,即
SISD-Single Instruction, Single Data:就是一般的單CPU計算機,老一代的大型機、微機和工作站,現在大多數的PC都是這種架構。
MISD-Multiple Instruction, Single Data:這種計算機在市面上很少看到,在工業實時控制和信號處理系統的FPGA等ASIC芯片,或許可以算是MISD架構。
SIMD-Single Instruction, Multiple Data:所有的處理單元在給定的時鐘週期都執行相同的指令,每一個處理單元可以同時處理不同的數據,最合適處理高貴度的問題,如圖像處理等。
MIMD-Multiple Instruction, Multiple Data:這是目前大多數通用並行計算機採用的架構,包括大多數的MPP超級計算機,網格計算機、多核SMP計算機,以及採用多核CPU的單PC。

Flynn分類表述
MIMD的進一步細分,如下圖:

MIMD進一步分類法
共享內存與SMP
共享內存(Shared Memory)的機器可以根據CPU對內存的存取方式分爲兩大類:UMA(Uniform Memory Access)和NUMA(Non Uniform Menory Access)。UMA和NUMA的一個區別是UMA架構中的CPU和內存之間沒有獨立的HPS高速連接網絡。
UMA體系架構一般被用在SMP(對稱多處理,Symmetrical MultiProcessing)計算機中。在SMP架構中,多個處理器與同一個集中的存儲器相連,運行同一個操作系統,並且共享同一臺計算機的所有其他資源。很顯然,SMP的缺點是可伸縮性有限,因爲在存儲器接口達到飽和的時候,增加處理器並不能獲得的更高的性能。
非均勻存儲訪問NUMA,屬於分佈式共享存儲DSM(Distributed Shared Memory)架構,NUMA的物理內存分佈在不同節點上,在一個處理器存取遠程節點的數據,比存取同一點的局部數據路徑遠一些,時間長一些,所以叫非均勻存儲訪問。NUMA保持了SMP架構的單一操作系統、簡便的應用程序編程模式及易於管理的特點,又繼承了MPP模式的可擴充性,可以有效地擴充系統的規模,這也是NUMA的優勢所在。
CC-NUMA(Cache Coherent Non-Uniform Memory Access)是NUMA的一種類型。Cache Coherent是指緩存中的數據和共享內存中的數據有專門的硬件來保持一致,不需要軟件來保持多個數據複製的一致性,也不需要軟件來實現操作系統與應用系統的數據傳輸。
COMA(Cache-Only Memory Architecture)從硬件上來說不完全是一種共享內存架構,他不通過互聯設備是整個內存系統保持一致性,他的架構接近NUMA,但提供UMA那樣的方便性。
分佈式內存與MPP
分佈式內存架構基於同一個總線(Interconnect Network)把所有的及其連接起來,共享內存架構與分佈式內存架構的關鍵區別在於,在共享內存架構中,數據一致性由硬件專門管理,而在分佈式內存架構中,節點之間的數據一致性由系統軟件甚至是應用程序來管理,結果是應用編程模式完全不一樣。
從邏輯上來說,共享內存架構的HPC計算機,不論其中CPU數量有多少,按照前文的說法,他都是一臺“單機系統”,集中在一個緊湊的機構裏,從虛擬化的角度來說,他可以運行一個Hypervisor。而分佈式內存架構是一個“多機系統”,可以跨地域分佈,其中的單機(節點)可以包含一個或多個共享內存的HPC計算機。
一個分佈式內存架構的HPC計算機具有多個節點,每個節點都有自己的存儲器,他可以是一個COW那樣的鬆耦合、開放式分佈式機羣系統,也可以是一個緊耦合的MPP超級計算機。MPP體系結構由於沒有硬件支持共享內存或高速緩存一致性的問題,所以比較容易實現大量處理器的鏈接,具有“無限”的可伸縮性,這也是爲什麼現代的TOP 500超級計算機大部分都採用MPP分佈式內存架構的原因。
機羣與集羣
機羣與集羣這兩個詞都翻譯自英文Cluster這同一個詞,Cluster在英文中的確由多重含義,最主要的是兩種:
一種是COW(Cluster of Workstation)中的Cluster及超級計算TOP500中的Cluster,這樣的Cluster通過多臺計算機完成同一個工作,達到更高的效率,對HA(High Availability)和RAS(Reliablity, Availability, Servicability),即高可用性和高可靠性的要求不是非常高,基本上是基於MPI/調度等軟件的一個多機的簡單整合和簡單虛擬化,翻譯成中文更確切的意思應該是“機羣”。
另一種是指用在商業系統中的Cluster,或叫HA Cluster,是另一類技術打造的高可用性和高可靠性系統,例如,建立一個雙機內容、工作過程等完全一樣的系統,如果一臺死機,另一臺可以繼續其作用,實現Fail-Over、Fail-Safe等容錯和對用戶的無縫、無間斷服務功能。這種Cluster翻譯成中文是“集羣”,打造一個HA集羣非常複雜,和開發TP(Transaction Processing)系統差不多,按照美國人的說法,那“Rocket Science“(尖端科學)。
Cluster 分爲通過與異構兩種,再同構系統中,所有的計算機都是同類,而在異構系統中,計算機可以是不同種類。Cluster按功能和結構還可以分成以下幾類。
高可用性集羣(HA Cluster):一般是指當集羣中有摸個節點失效的情況下,其上的任務會自動轉移到其他正常的節點上。還指可以將集羣中的某節點進行離線維護再上線,該過程並不影響真個集羣的運行。
負載均衡集羣(Load Balancing Cluster):負載均衡集羣運行時,一般通過一個或者多個前端負載均衡器,將工作負載分發到後端的一組服務器上,從而達到整個系統的高性能和高可用性。這樣的計算機集羣優勢也被稱爲服務器羣。一般高可用性集羣和負載均衡集羣會使用類似的技術。
高性能計算機羣(HPC Cluster):HPC機羣基於MPI/調度等軟件,將計算任務分配到機羣的不同計算節點而提高計算能力,主要應用在科學計算領域。
網格計算(Grid Computing):網格計算或網絡集羣是上述Cluster技術的提升。網格與傳統Cluster的主要差別是網格可以是連接一組相互並不信任的計算機,他的運作更像一個計算公共設施而不是一個獨立的計算機。
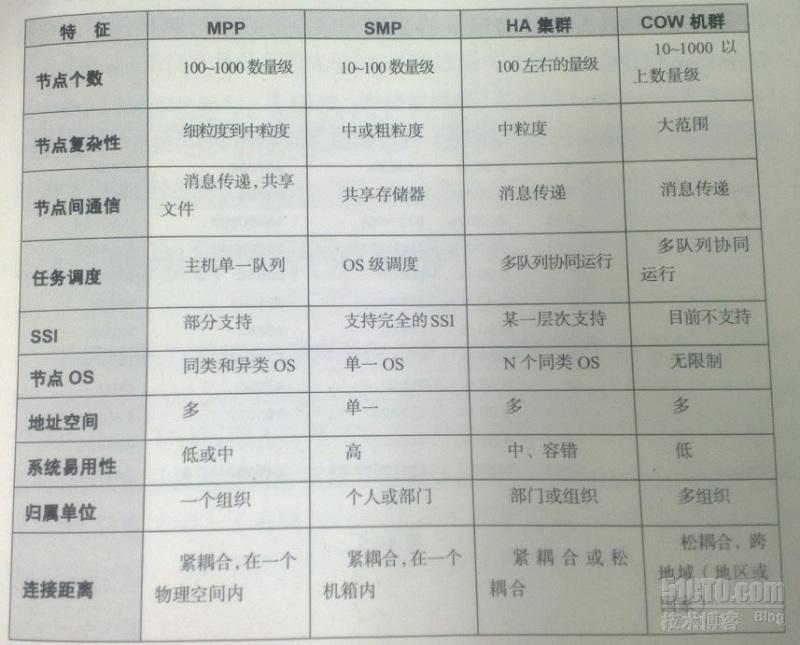
MPP, SMP, HA集羣, COW機羣對比表: