




ERNIE是百度自研的持續學習語義理解框架,該框架支持增量引入詞彙(lexical)、語法 (syntactic) 、語義(semantic)等3個層次的自定義預訓練任務,能夠全面捕捉訓練語料中的詞法、語法、語義等潛在信息。
ERNIE2.0實現了在中英文16個任務上的最優效果,具體效果見下方列表。
一、ERNIE2.0中文效果驗證
我們在 9 個任務上驗證 ERNIE 2.0 中文模型的效果。這些任務包括:自然語言推斷任務 XNLI;閱讀理解任務 DRCD、DuReader、CMRC2018;命名實體識別任務 MSRA-NER (SIGHAN2006);情感分析任務 ChnSentiCorp;語義相似度任務 BQ Corpus、LCQMC;問答任務 NLPCC2016-DBQA 。
1、自然語言推斷任務

• XNLI
XNLI 是由 Facebook 和紐約大學的研究者聯合構建的自然語言推斷數據集,包括 15 種語言的數據。我們用其中的中文數據來評估模型的語言理解能力。鏈接: [https://github.com/facebookresearch/XNLI]
2、閱讀理解任務
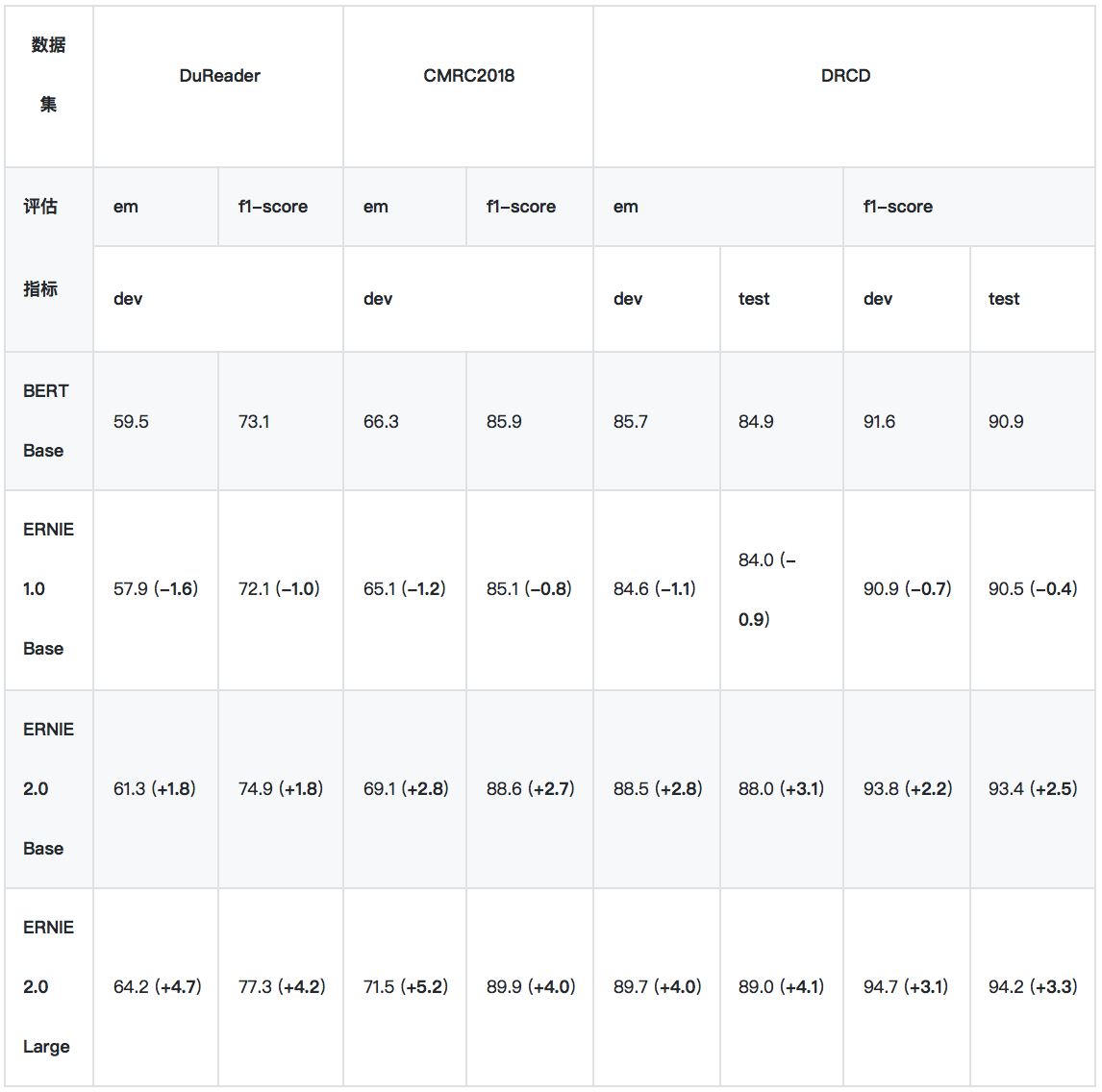
*實驗所用的 DuReader 抽取類、單文檔子集爲內部數據集。
*實驗時將 DRCD 繁體數據轉換成簡體,繁簡轉換工具:https://github.com/skydark/nstools/tree/master/zhtools
*ERNIE 1.0 的預訓練數據長度爲 128,其他模型使用 512 長度的數據訓練,這導致 ERNIE 1.0 BASE 在長文本任務上性能較差, 爲此我們發佈了 ERNIE 1.0 Base (max-len-512) 模型 (2019-07-29)
• DuReader
DuReader 是百度在自然語言處理國際頂會 ACL 2018 發佈的機器閱讀理解數據集,所有的問題、原文都來源於百度搜索引擎數據和百度知道問答社區,答案是由人工整理的。實驗是在 DuReader 的單文檔、抽取類的子集上進行的,訓練集包含15763個文檔和問題,驗證集包含1628個文檔和問題,目標是從篇章中抽取出連續片段作爲答案。鏈接: [https://arxiv.org/pdf/1711.05073.pdf]
• CMRC2018
CMRC2018 是中文信息學會舉辦的評測,評測的任務是抽取類閱讀理解。鏈接: [https://github.com/ymcui/cmrc2018]
• DRCD
DRCD 是臺達研究院發佈的繁體中文閱讀理解數據集,目標是從篇章中抽取出連續片段作爲答案。我們在實驗時先將其轉換成簡體中文。鏈接: [https://github.com/DRCKnowledgeTeam/DRCD]
3、命名實體識別任務
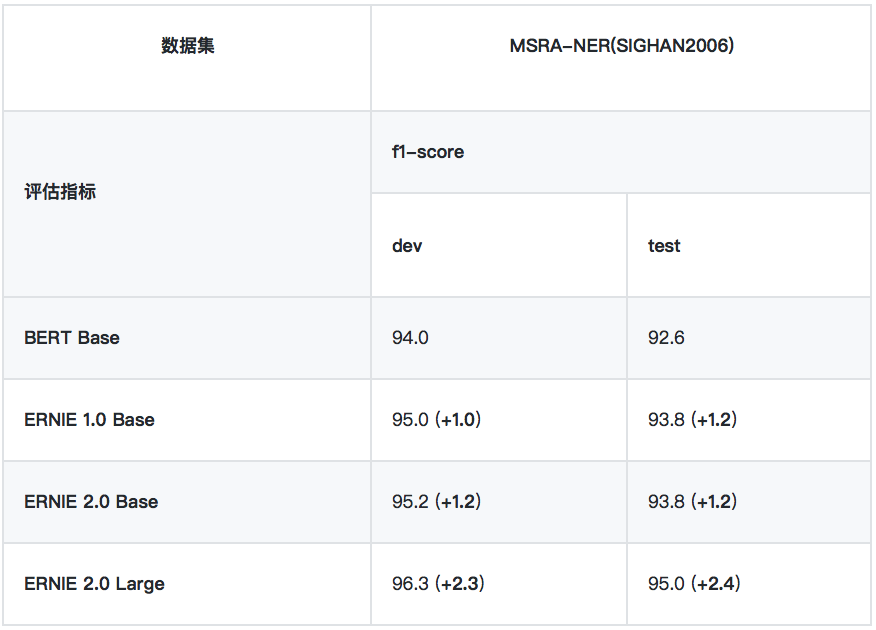
• MSRA-NER (SIGHAN2006)
MSRA-NER (SIGHAN2006) 數據集由微軟亞研院發佈,其目標是識別文本中具有特定意義的實體,包括人名、地名、機構名。
4、情感分析任務
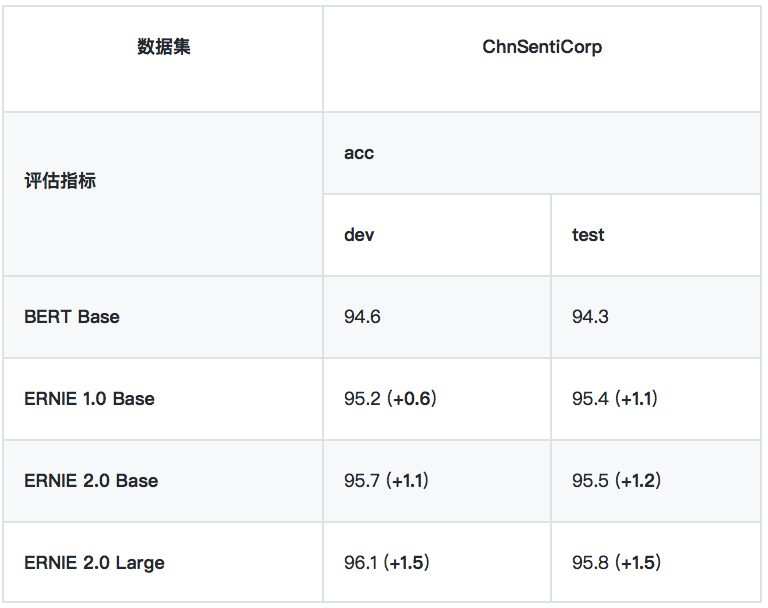
• ChnSentiCorp
ChnSentiCorp 是一箇中文情感分析數據集,包含酒店、筆記本電腦和書籍的網購評論。
5、問答任務
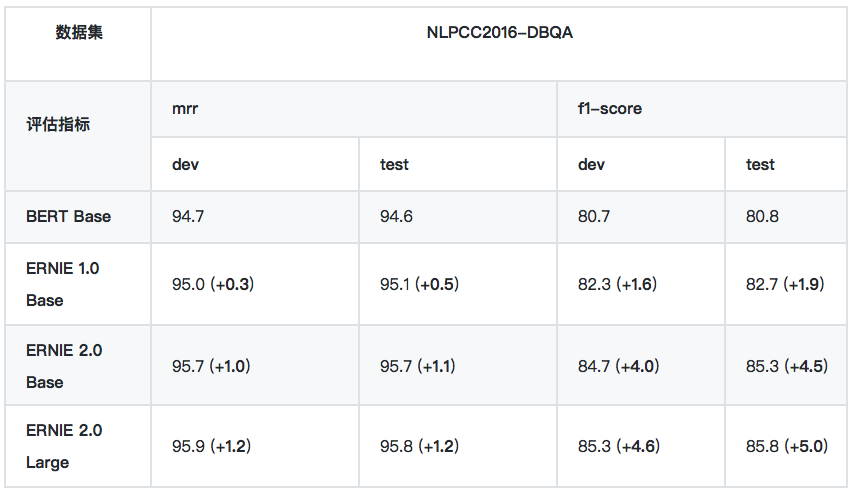
• NLPCC2016-DBQA
NLPCC2016-DBQA 是由國際自然語言處理和中文計算會議 NLPCC 於 2016 年舉辦的評測任務,其目標是從候選中找到合適的文檔作爲問題的答案。鏈接: [http://tcci.ccf.org.cn/conference/2016/dldoc/evagline2.pdf]
6、語義相似度
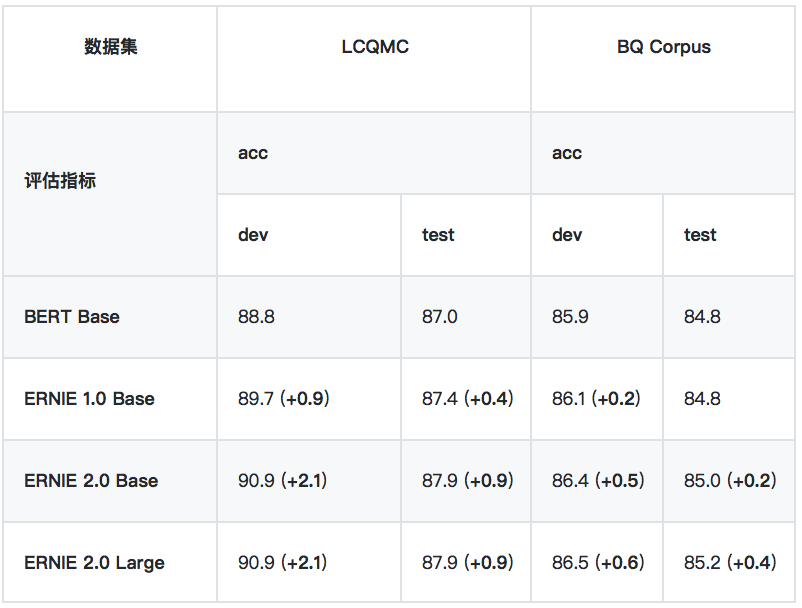
*LCQMC 、BQ Corpus 數據集需要向作者申請,LCQMC 申請地址:http://icrc.hitsz.edu.cn/info/1037/1146.htm, BQ Corpus 申請地址:http://icrc.hitsz.edu.cn/Article/show/175.html
• LCQMC
LCQMC 是在自然語言處理國際頂會 COLING 2018 發佈的語義匹配數據集,其目標是判斷兩個問題的語義是否相同。鏈接: [http://aclweb.org/anthology/C18-1166]
• BQ Corpus
BQ Corpus 是在自然語言處理國際頂會 EMNLP 2018 發佈的語義匹配數據集,該數據集針對銀行領域,其目標是判斷兩個問題的語義是否相同。鏈接: [https://www.aclweb.org/anthology/D18-1536]
二、英文效果驗證
ERNIE 2.0 的英文效果驗證在 GLUE 上進行。GLUE 評測的官方地址爲 https://gluebenchmark.com/ ,該評測涵蓋了不同類型任務的 10 個數據集,其中包含 11 個測試集,涉及到 Accuracy, F1-score, Spearman Corr,. Pearson Corr,. Matthew Corr., 5 類指標。GLUE 排行榜使用每個數據集的平均分作爲總體得分,並以此爲依據將不同算法進行排名。
1、GLUE - 驗證集結果
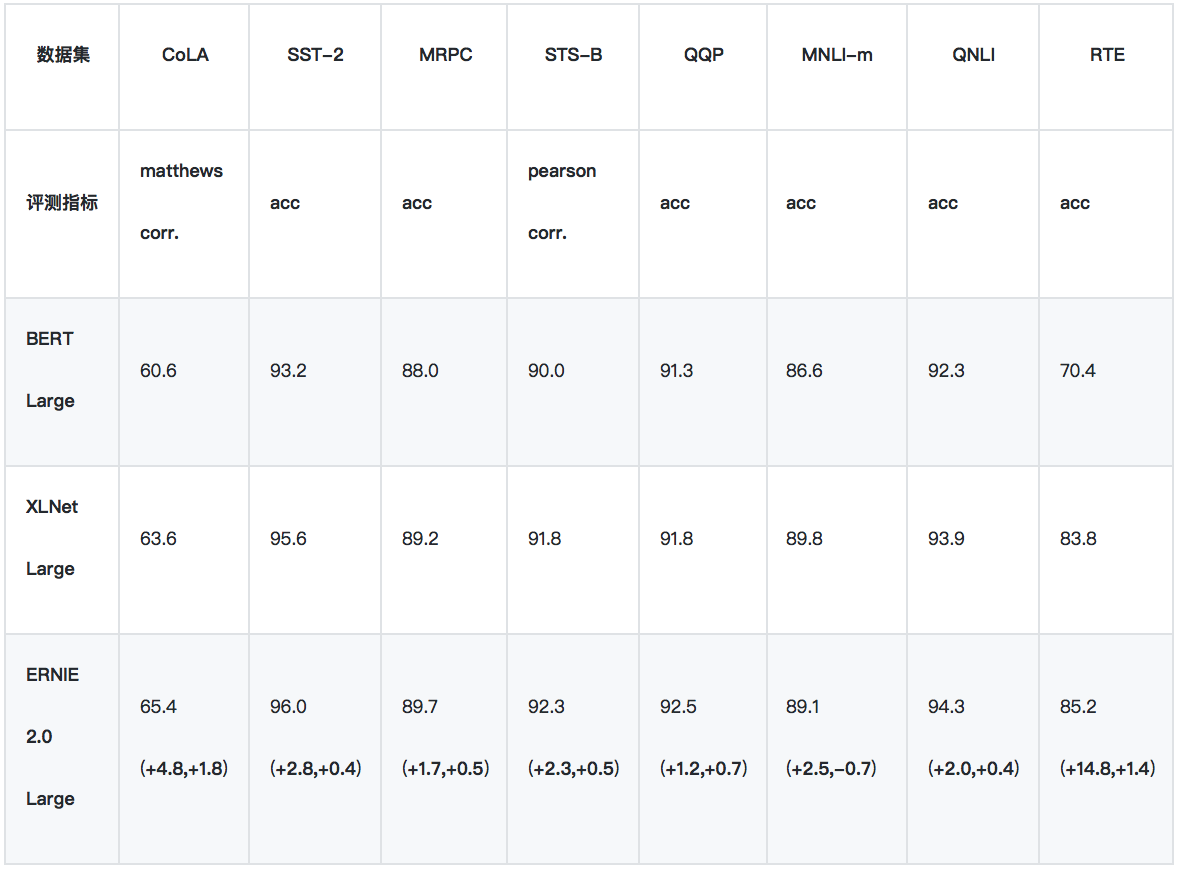
我們使用單模型的驗證集結果,來與 BERT/XLNet 進行比較。
2、GLUE - 測試集結果
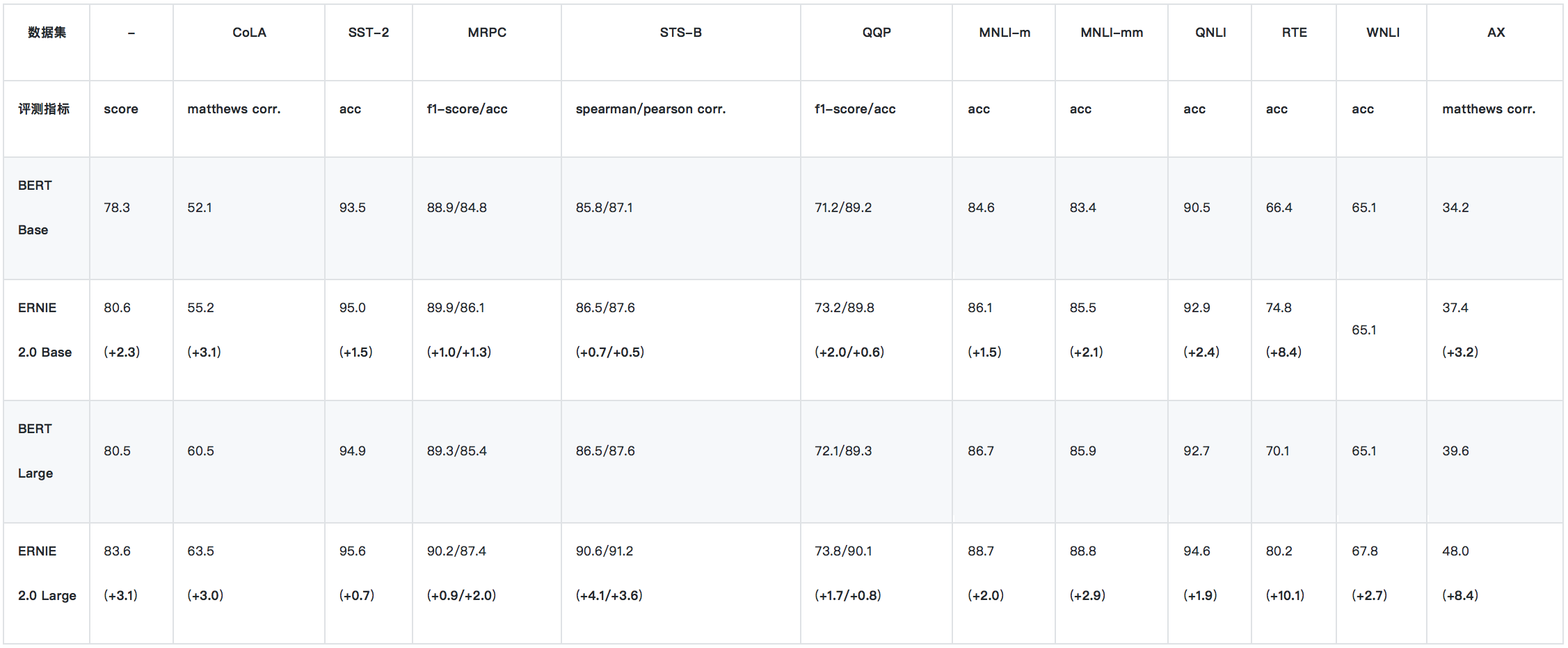
由於 XLNet 暫未公佈 GLUE 測試集上的單模型結果,所以我們只與 BERT 進行單模型比較。上表爲ERNIE 2.0 單模型在 GLUE 測試集的表現結果。
三、真實用戶點評
“評分表數據很炸裂啊”
“我覺得你們這個模型太棒了,既能學習到實體embedding,又能學到Word embedding”
“ERNIE2.0創新地將過去單一的預訓練流程拆解爲串行的多個預訓練任務,無疑是最大的貢獻”
“ERNIE2.0的使用很方便”
“通過預訓練模型BERT, ERNIE, BERT-wwm在公開數據集的對比,發現ERNIE表現較好,原因是採用了非正式數據進行預訓練”
“ERNIE2.0創新性的運用了連續增量式多任務學習”
…
大家用了都說好,感覺來試用吧。
劃重點!
查看ERNIE模型使用的完整內容和教程,請點擊下方鏈接,建議Star收藏到個人主頁,方便後續查看。
GitHub:https://github.com/PaddlePaddle/ERNIE
版本迭代、最新進展都會在GitHub第一時間發佈,歡迎持續關注!
也邀請大家加入ERNIE官方技術交流QQ羣:760439550,可在羣內交流技術問題,會有ERNIE的研發同學爲大家及時答疑解惑。