




筆者在進行Tensorflow訓練ssd網絡進行目標檢測訓練時,發現會假卡死。故記錄下,供大家參考。
系統:
硬件 i5-8500 ddr4 2666 8G內存 gtx1070(8G顯存)。
軟件 win10 64bit CUDA 10.0(不要用10.1) cudnn 7.x Tensorflow 1.15.0
不賣館子,內存是關鍵
當然,在這種多架構需要一起搭配運行的系統。確實還可能存在其他不確定因素,筆者只是總結自己的經驗,大家少走彎路。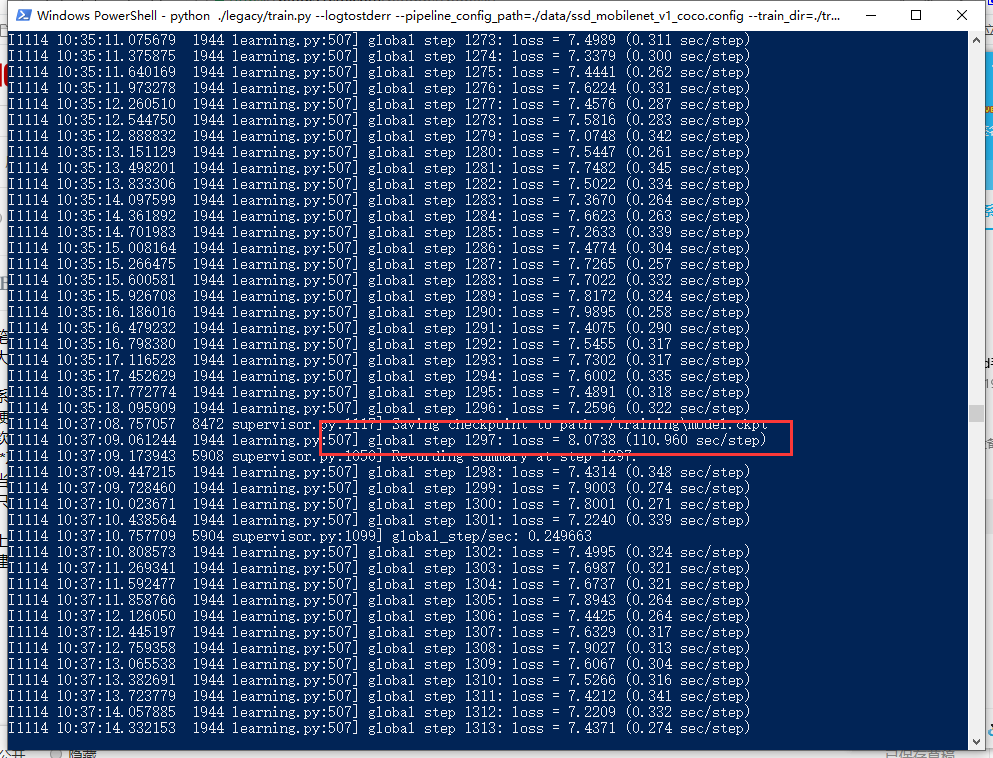
上圖就是筆者用上述軟件版本跑的結果,有標出一次step大約0.3秒。還有一次卡住用了110秒。但是這種卡死會隨着系統負載緩解後,繼續恢復。
一般情況,都是CPU負載一般,GPU計算負載一般(估計任務還不夠重),但是GPU顯存幾乎佔滿。
因爲當時開着Pycharm幹活,出現了內存滿,提示關閉Pycharm。
筆者估計需要用系統內存來坐交換,這時就會卡住。(任務管理器裏看不出來)
建議內存至少16G起配。若只有8G,可以換下
CUDA 9 cudnn 7.x Tensorflow <1.13.0(筆者用着1.11.0的版本試過可行。過高版本會報調用CUDA10.0的庫,找不到。)
這種搭配,CPU佔用比較高,GPU佔用一般,顯存負載也是滿。(任務管理器裏看)
測試同樣的訓練任務。一次step用時大約1.2秒。
爲了能提高效率,現在就用CUDA10.0 Tensorflow1.15.0 升級內存到16G
還是會出現假死,但是會明顯緩解。
Ubuntu上沒試過,如果大家有經驗,歡迎留言。