




explain
explain可以对select,update,insert,replace,delete进行sql分析
对评论进行分页展示

结果(检查是否正确执行索引)
SQL如何使用索引
关联查询的执行顺序(mysql优化器根据索引的信息,会自动的调整索引的顺序)
查询扫描的数据行数
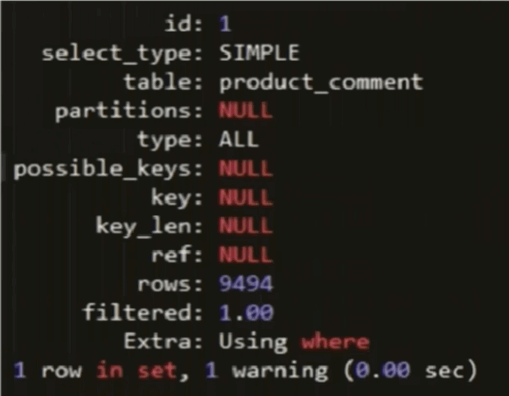
ID列
ID列中的数据为一组数字,表示执行SELECT语句的顺序
ID值相同时,执行顺序由上至下
ID值越大优先级越高,越先被执行
查询一组分类下商品的标题

查询最小分类的ID对应最大商品ID的一个评论标题(3个select语句)

SELECT_TYPE列
UNION RESULT时,ID值为null.
DERIVED 衍生表,用来表示包含在FROM字句中的字查询。myslq递归的执行,并将结果放在临时表中,临时表就是派生表。

TABLE列,执行计划中的数据是由哪个表输出的
输出数据行所在的表的名称(如果有别名就显示别名)
由ID为M,N查询union产生的结果集(临时表)
/由ID为N的查询产生的结果(临时表,衍生表)
PARTITIONS列,查询分区表
如果不按照分区键选择,就会显示全部的分区,因为是跨分区扫描
对于分区表,显示查询的分区ID
对于非分区表,显示为NULL
TYPE列,查询中使用的一个类型(mysql访问数据的方式)

Extra列(扩展列,包含mysql如何执行查询的一些附加信息)

POSSIBLE_KEYS列
指出MySQL能使用那些索引来优化查询
查询列所涉及到的列上的索引都会被列出,但不一定会被使用
KEY列
查询优化器优化查询实际所使用的索引
如果没有可用的索引,则显示为NULL
如查询使用了覆盖索引,则该索引仅出现在Key列中
KEY_LEN列
表示索引字段的最大可能长度
Key len的长度由字段定义计算而来,并非数据的实际长度
Ref列(当前表在利用key列中的索引进行查询时,所用到的列或者常量)
表示那些列或常量被用于查找索引列上的值
Rows列
表示MySQL通过索引统计信息,估算的所需读取的行数
Rows值的大小是个统计抽样结果,并不十分准确
Filtered列
表示返回结果的行数占需读取行数的百分比
Filtered列的值越大越好
Filtered列的值依赖说统计信息
执行计划的限制
无法展示存储过程,触发器,UDF对查询的影响
无法使用EXPLAIN对存储过程进行分析
早期版本的MySQL只支持对SELECT语句进行分析。
优化评论分页查询(添加索引)
使用情况:中间结果集差距很小的情况,或者数据量很小的情况
首先,我们可以考虑对where条件添加索引,就是audit_status 和 product_id添加一个联合索引
问题:audit_status 和 product_id哪个放在最左侧 ?
根据索引设计规范,先计算一下这两列在表中的区分度 ,数据越接近1,区分度越高


缺点:越往后翻页,查询效率越来越差,时间也越来越长,尤其数据量很大
进一步优化:改写
数据库访问开销=索引IO+索引全部记录结果对应表数据的IO
数据库访问开销=索引IO+索引返回15条记录对应表数据的IO
IO节约很多
在任意位置翻页的消耗都是相同的
使用情况:中间结果集差距很大的情况,或者ORDER BY,WHERE有对应的覆盖索引

该SQL使用前提:comment_id是主键,而且有覆盖索引(product_id和audit_status联合索引)
需求:删除重复数据
删除评论表中对同一订单同一商品的重复评论,只保留最早的一条
步骤一:意看是否存在对于一订单同一商品的重复评论
步骤二:备份product_comment表
步骤三:删除同一订单的重复评论

测试查询数据

第二步
CREATE TABLE bak_product_comment_161022 LIKE product_comment;
INSERT INTO bak_product_comment_161022 SELECT * FROM product_comment;
或者
CREATE TABLE bak_product_comment_161022 AS SELECT * FROM product_comment;
子查询:查询出所有商品中订单的重复评论的最小评论ID(要保留,最早的) 关联商品评论表,删除,相同订单,相同商品,大的评论ID

需求:分区间统计
根据订单主表(order_master)查询出所有用户消费总金额
关联登陆日志表和订单主表
CASE区间分隔
COUNT 用户量统计



需求:捕获有问题的SQL-慢查日志


快速分析慢查询日志-mysqldumpslow

