




本文將總結句法分析的相關內容。
自然語言處理的分析技術,可以大致分爲三個層面。
第一層是詞法分析,包括分詞(Word Segmentation)、詞性標註(Part-of-speech Tagging)、命名實體識別(Named Entity Recognition)、詞義消歧(Word Sense Disambiguation)。
第二層爲句法分析(syntactic parsing),句法分析將輸入句子從序列形式變爲樹狀結構,從而可以捕捉到句子內部詞語之間的遠距離搭配或修飾關係。目前研究界存在兩種主流的句法標註體系:
1)句法結構分析(syntactic structure parsing),又稱短語結構分析(phrase structure parsing),也叫成分句法分析(constituent syntactic parsing)。作用是識別出句子中的短語結構以及短語之間的層次句法關係。
2)依存句法分析(dependency syntactic parsing),作用是識別句子中詞彙與詞彙之間的相互依存關係。最常見也是最常用的。
3)更深一層次的語義分析,也會包含句法的信息在裏面,例如AMR,語義角色標註(Semantic Role Labeling,SRL)是目前比較成熟的淺層語義分析技術[6, 7]。給定句子中一個謂詞,語義角色標註的任務是從句子中標註出這個謂詞的施事、受事、時間、地點等參數(argument)。
延伸 目前語義分析在智能系統中仍然是一個瓶頸問題。句法依存能夠預測出句子完整的語法結構,並能給出各個結構之間的句法關係。但是句法依存能夠表達的語義信息還是不夠的。比如“手機在屏幕尺寸方面很受歡迎”,句法依存能夠給出“手機”是句子主語,“受”是核心動詞,“歡迎”是賓語,“在手機屏幕方面”是狀中結構,語義信息全無。通過語義依存分析可以給出“在尺寸方面”是“手機受歡迎”的範圍。而“尺寸”是指“手機屏幕”的尺寸。這些完整的信息都是語義依存的研究目標。因此語義依存區別於句法依存而存在。
目錄
一. 依存句法分析
1. 前言
與短語結構語法相比,依存語法有以下優勢:
- 依存語法表示形式簡潔,易於理解和標註。
- 依存語法可以很容易的表示詞語之間的語義關係,這種語義關係可以很方便的應用於語義分析、信息抽取等。
- 更高效的解碼算法。
- 可以方便的表示一些語序比較靈活的語言。
目前,依存句法分析是主流,本人推薦使用哈工大開發的LTP平臺或HanLP的開源項目。
2. 定義
依存句法是由法國語言學家L.Tesniere最先提出。依存語法的含義是用詞與詞之間的依存關係來描述語言結構,主張句子中核心動詞是支配其它成分的中心成分,而它本身卻不受其它任何成分的支配,所有受支配成分都以某種依存關係從屬於支配者。它將句子分析成一顆依存句法樹,描述出各個詞語之間的依存關係。
計算語言學家Robinson總結了依存語法的4條公理:
(1) 一個句子中只有一個獨立成分不依存於其他任何成分;
(2) 句子的其他成分都必須依存於某一成分;
(3) 任何一個成分都不能依存於兩個或兩個以上的其他成分;
(4) 如果成分A直接依存於成分B,而成分C位於A和B之間,則C依存於A或者B,或者依存於A和B之間的某一成分。
依存句法分析可以反映出句子各成分之間的語義修飾關係,它可以獲得長距離的搭配信息,並與句子成分的物理位置無關。
LTP依存分析模塊所使用的依存關係標記含義 (http://www.ltp-cloud.com/demo/) (共14種) 如下:
|
關係類型 |
Tag |
Description |
Example |
|
主謂關係 |
SBV |
subject-verb |
我送她一束花 (我 <-- 送) |
|
動賓關係 |
VOB |
直接賓語,verb-object |
我送她一束花 (送 --> 花) |
|
間賓關係 |
IOB |
間接賓語,indirect-object |
我送她一束花 (送 --> 她) |
|
前置賓語 |
FOB |
前置賓語,fronting-object |
他什麼書都讀 (書 <-- 讀) |
|
兼語 |
DBL |
double |
他請我吃飯 (請 --> 我) |
|
定中關係 |
ATT |
attribute |
紅蘋果 (紅 <-- 蘋果) |
|
狀中結構 |
ADV |
adverbial |
非常美麗 (非常 <-- 美麗) |
|
動補結構 |
CMP |
complement |
做完了作業 (做 --> 完) |
|
並列關係 |
COO |
coordinate |
大山和大海 (大山 --> 大海) |
|
介賓關係 |
POB |
preposition-object |
在貿易區內 (在 --> 內) |
|
左附加關係 |
LAD |
left adjunct |
大山和大海 (和 <-- 大海) |
|
右附加關係 |
RAD |
right adjunct |
孩子們 (孩子 --> 們) |
|
獨立結構 |
IS |
independent structure |
兩個單句在結構上彼此獨立 |
|
核心關係 |
HED |
head |
指整個句子的核心 |
爲了直觀描述句子的形式模型,可根據句法模型將一個句子中各成分之間的關係顯式表達爲某種句法結構圖(有向圖或依存樹)形式,

樹庫語料都是CoNLL格式的,CoNLL格式的語料以.conll結尾。CONLL標註格式包含10列,分別爲:
ID FORM LEMMA CPOSTAG POSTAG FEATS HEAD DEPREL PHEAD PDEPREL _ _

3. 依存句法分析方法
依存句法分析是針對給定的句子序列應用某一依存語法體系對自然語言進行自動分析構建句子對應的依存樹的一種方法。一般來說,句法分析方法可分爲基於規則的分析方法、基於統計的分析方法以及統計與規則相結合的方法。
3.1 基於規則的依存句法分析方法
基於規則方法的基本思路是由人工組織語法規則,建立語法知識庫,通過條件約束和檢查來實現句法結構歧義的消除。例如,基於上下文無關文法的分析方法、基於約束依存文法Constraint dependency grammar, CDG)的分析方法。
3.2 基於統計的依存句法分析方法
由於大規模語料庫的構建,目前依存分析方法中以統計分析方法爲主流。
給定輸入句子x,依存句法分析的目標是給出分值最大的依存樹ˆd,如公式所示
![]()
依存分析的兩個基本問題:
(1)如何定義Score(x,d),即計算句子和對應的依存樹的分值。這是建模問題。
(2)給定模型參數,即特徵權重,如何建立滿足依存樹約束的d。這是解碼問題。
依存句法分析兩個主流的方法分別是:一種是基於圖的方法,將依存句法分析看成從完全有向圖中尋找最大生成樹的問題。另一種是基於轉移的方法,通過一個移進規約轉移動作序列構建一棵依存句法樹,將依存分析問題建模爲尋找最優動作序列的問題。
基於圖的依存句法分析方法
McDonald等(2005)首先提出基於圖的依存句法分析方法,將問題建模爲從一個有向多重圖(完全依存圖)中找到概率(分值)最大的依存樹的問題。
基於圖的方法是一種全局優化的算法,它將句子中的每個詞看作一個節點,任意兩個詞可以有一條加權邊,算法的目的就是尋找一顆最大生成樹,使得最終邊的權重總和最大。
該方法將依存句法分析問題歸結爲在一個有向圖中尋找最大生成樹(Maximum Spanning Tree)的問題;邊權重使用 Online 算法來學習獲得,搜索算法採用 Eisner 算法。特徵選擇是決定該算法性能的重要因素。本文使用的特徵將由兩部分構成,一部分爲依存弧本身構成的特徵,另一部分爲語義關係構成的特徵。其中弧特徵用來計算兩個節點之間構成一條弧的概率;關係特徵計算了節點 k 作爲兒子節點(is-child)或者核心節點(not-child),依存弧方向爲 dir 時,對應依存關係爲 t 的概率。
基於轉移的依存句法分析方法
基於轉移的方法,該算法一般事先定義多種轉移操作,如:檢驗、歸約、插入、刪除等。然後計算新加入的詞應該採用何種操縱。該分析方法在決定對當前待分析的詞采取何種操作時,可以利用已經分析的結果,即更寬泛的上下文,但是其分析過程不能夠回溯,是一種貪心的算法。
基於轉移的方法將依存樹的搜索過程建模爲一個動作序列,依存分析問題轉化爲尋找最優動作序列的問題,
3.3 依存句法分析的評價方法
目前最常用的兩個評價指標都以詞爲單位。
• 只考慮依存骨架,不考慮依存關係類型
• 同時考慮依存骨架和關係類型
4. 工具
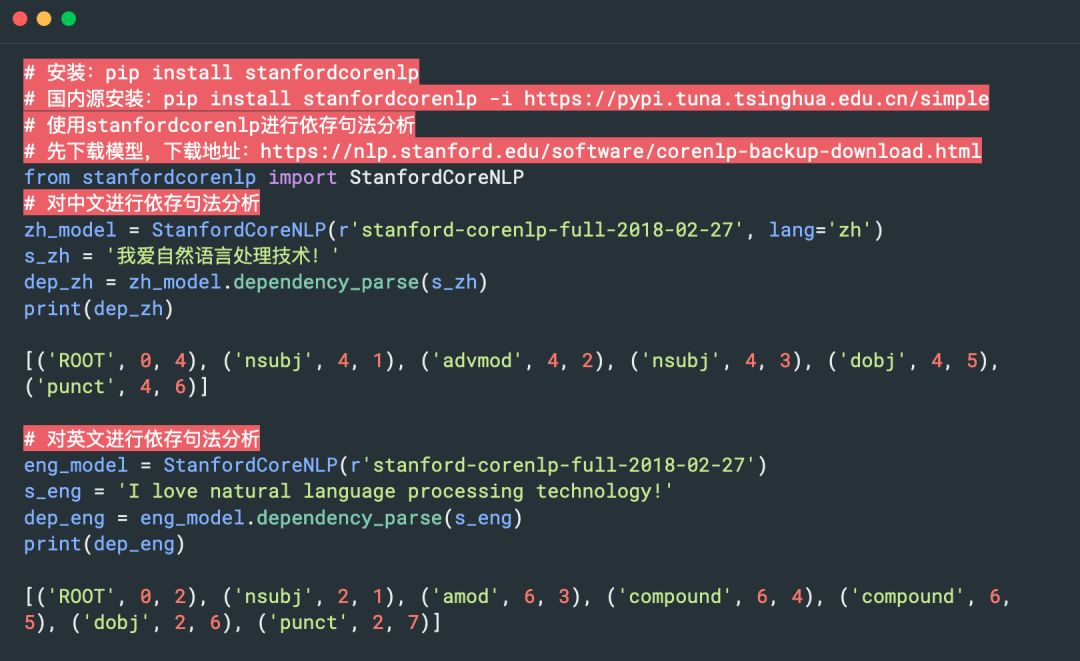
1. StanfordCoreNLP
英文最爲經典的tool,當然也提供中文的分析功能,斯坦福大學開發的,提供依存句法分析功能。
Github 地址:https://github.com/TJUNLP/stanford-corenlp
官網:https://stanfordnlp.github.io/CoreNLP/
2. HanLP
提供了中文依存句法分析功能。支持多種自然語言處理基本功能。
Github 地址:https://github.com/hankcs/pyhanlp
3. SpaCy
工業級的自然語言處理工具,目前不支持中文。支持多種自然語言處理基本功能。
Gihub 地址:https://github.com/explosion/spaCy
官網:https://spacy.io/
4. FudanNLP
復旦大學自然語言處理實驗室開發的中文自然語言處理工具包。支持多種自然語言處理基本功能。
Github 地址:https://github.com/FudanNLP/fnlp
如有侵權,請聯繫本人([email protected]),將誠意修改或刪除。

