




轉自:http://my.oschina.net/ielts0909/blog/93190
這篇文章將介紹如何搭建kafka環境,我們會從單機版開始,然後逐漸往分佈式擴展。單機版的搭建官網上就有,比較容易實現,這裏我就簡單介紹下即可,而分佈式的搭建官網卻沒有描述,我們最終的目的還是用分佈式來解決問題,所以這部分會是重點。
Kafka的中文文檔並不多,所以我們儘量詳細點兒寫。要交會你搭建分佈式其實很簡單,手把手的教程大不了我錄個視頻就好了,可我覺得那不是走這條路的方式。只有真正瞭解原理,並且理解的透徹了才能最大限度的發揮一個框架的作用。所以,如果你不瞭解什麼事kafka,請先看:《kafka初步》
我們從搭建單機版的環境開始說起,如果你喜歡看英文版:這裏有官方的《quick start》
單機版的部署很簡單,我就講幾點比較重要的,首先kafka是用scala編寫的,可以跑在JVM上,所以我們並不需要單獨去搭建scala的環境,後面會涉及到編程的時候我們再說如何去配置scala的問題,這裏用不到,當然你要知道這個是跑在linux上的。第二,我用的是最新版0.7.2的版本,你下載完kafka你可以打開它的目錄瀏覽一下:
我就不介紹每個包裏的內容是幹嘛的,我就着重說一點,你在這個文件夾裏只能找到3個jar包,並且這3個還不能用於後面的編程,而且你也沒法在裏面找到pom這樣用於構建的xml。也別急,也別滿世界找,這些依賴庫得等你把它放到linux上纔會出現(當然需要命令)。
搭建單機版環境,簡單的說有那麼幾步:
1. 安裝java環境,我用的是最新的版本jdk7的
2. 將下載下來的kafka扔到linux上,並解壓。我用的red het server的linux。
3. 接下來就是下載kafka的依賴包和構建kafka的環境。注意,這一步需要電腦聯網。具體命令就是官網介紹的./sbt update 和 ./sbt package。
4. 執行完上面這步大概會花個10多分鐘吧,我在自己家裏ubuntu沒有成功,報了下載不到jline的錯。單位裏用虛擬機ubuntu成功了,我深刻懷疑是網的問題。上面這不執行完了有兩點要注意,一是sbt幫你下載完了所有依賴庫,但是這些jar都是分散在各個目錄下的,注意區分。二是,這些jar一部分是kafka的編程包,一部分是scala的環境包,上面說了沒必要自己去搭scala的環境道理就在這邊,你自己去下一個2.9的scala,但人家kafka只支持2.8、2.7。所以編程的時候就用sbt給你下好的包即可。後面講到編程的時候,會寫怎麼搭編程環境,很簡單的。
上面的步驟都執行完了,環境算是好了,下面我們要測試下是否能成功運行kafka:
1. 啓動zookeeper server :bin/zookeeper-server-start.sh ../config/zookeeper.properties & (用&是爲了能退出命令行)
2. 啓動kafka server: bin/kafka-server-start.sh ../config/server.properties &
3. Kafka爲我們提供了一個console來做連通性測試,下面我們先運行producer:bin/kafka-console-producer.sh --zookeeper localhost:2181 --topic test 這是相當於開啓了一個producer的命令行。命令行的參數我們一會兒再解釋。
4. 接下來運行consumer,新啓一個terminal:bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
5. 執行完consumer的命令後,你可以在producer的terminal中輸入信息,馬上在consumer的terminal中就會出現你輸的信息。有點兒像一個通信客戶端。
具體可看《quick start》
如果你能看到5執行了,說明你單機版部署成功了。下面解釋下兩條命令中參數的意思。--zookeeper localhost:2181 這個說明了去連本機2181端口的zookeeper server,--topic test,在kafka裏,消息按topic來區分,我們這裏的topic叫test,所以不管是consumer還是producer都指向了test。其他的參數,我就截圖了,首先是producer的參數:
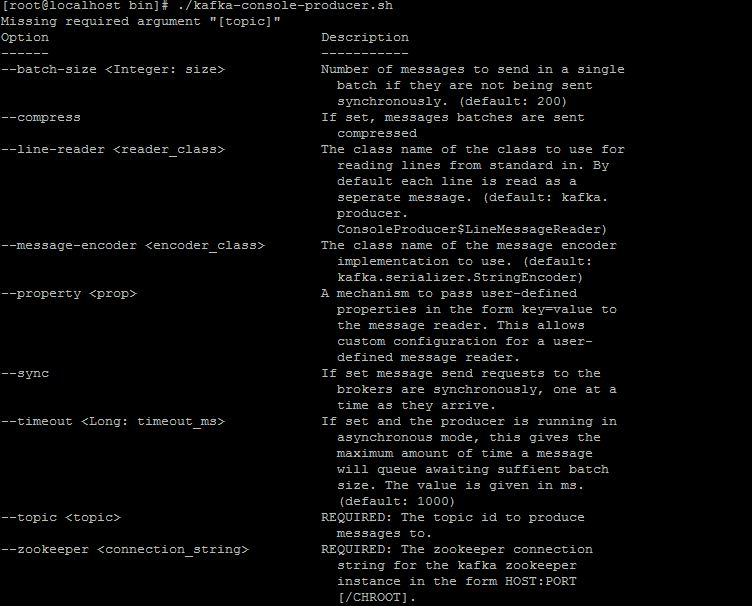
Consumer的參數:
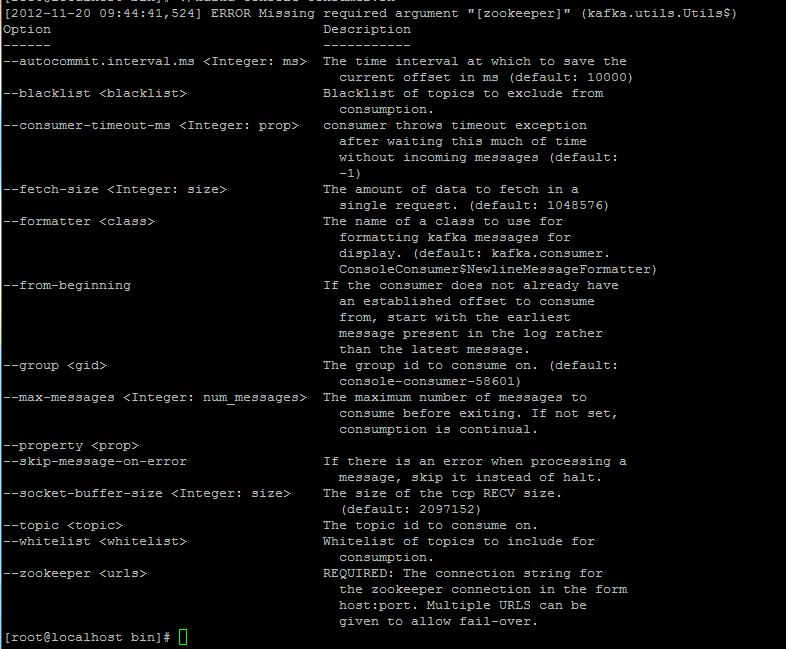
這些參數你可以先看個大概,之後會在編程中使用到,都可以動態的配置。
好了單機版就部署完了,那是不是我把consumer的放到另一臺機器上就算分佈式了呢。是的,前提是,你還能運行到上面的第5步。在講配置之前,我們還是將上篇寫的分佈式來回顧一下,當然我們簡化一下情況,按照實際部署的分析:

假設我只有兩臺機器,server1和server2。我現在想把zookeeper server和kafka server 和producer都放在一臺機器上server1,把consumer放在server2上。這當然也叫分佈式了,雖然機子不多,但是這個部署成功了,擴展是相當的容易。
我們還是按照那5個步驟來做,當然你肯定能知道,3、4兩步的參數要改了,我們假設server1的IP是192.168.10.11 server2的IP是192.168.10.10:
1. 啓動zookeeper server :bin/zookeeper-server-start.sh ../config/zookeeper.properties & (用&是爲了能退出命令行)
2. 啓動kafka server: bin/kafka-server-start.sh ../config/server.properties &
3. Kafka爲我們提供了一個console來做連通性測試,下面我們先運行producer:bin/kafka-console-producer.sh --zookeeper 192.168.10.11:2181 --topic test 這是相當於開啓了一個producer的命令行。
4. 接下來運行consumer,新啓一個terminal:bin/kafka-console-consumer.sh --zookeeper 192.168.10.11:2181 --topic test --from-beginning
5. 執行完consumer的命令後,你可以在producer的terminal中輸入信息,馬上在consumer的terminal中就會出現你輸的信息。
這個時候你能執行出第5步的效果麼,是不是報了下面的錯了:

我來說原因,在這之前想請你再回去看看《kafka初步》,看看裏面講分佈式的內容:
這裏的kafka server就是broker,broker是存數據的,producer把數據給broker,consumer從broker取數據。那zookeeper是幹嘛的,說的膚淺點兒,zookeeper就是他們之間的選擇分發器,所有的連接都要先註冊到zookeeper上。你可以把它想象成NIO,zookeeper就是selector,producer、consumer和broker都要註冊到selector上,並且留下了相應的key。
所以問題就出在了kafka server的配置server.properties上。Kafka註冊到zookeeper上的信息不對,才導致了上面的錯誤。我們看config中server.properties的配置就可以知道:
1 |
#
Hostname the broker will advertise to consumers. If not set, kafka will use the value returned |
2 |
#
from InetAddress.getLocalHost(). If there are multiple interfaces getLocalHost |
3 |
#
may not be what you want. |
4 |
#hostname= |
默認的hostname如果你不設置,就是127.0.0.1,所以你把這個hostname設置成192.168.10.11即可,這樣你重啓下kafka server端,就能執行第5步了。
成功配置的話,你能看到下面的效果,左邊的是producer,右邊的是consumer,看最下面兩行好了,前面的是我之前測試用過的:

如果你還是雲裏霧裏的,建議你回頭去看看上篇文章,將kafka分佈式基本原理的,kafka實際操作是要建立在對原理熟悉的情況下的。
搭建完了環境,後面就要開始寫程序去處理實際問題了。當然再寫程序之前,下一篇我會先寫一點kafka爲什麼會有如此高的性能,它是怎麼保障這些性能的。