




轉自:http://my.oschina.net/ielts0909/blog/94153
如果你第一次看kafka的文章,請先看《分佈式消息系統kafka初步》
之前有人問kafka和一般的MQ之間的區別,這個問題挺難回答,我覺得不如從kafka的實現原理來分析更爲透徹,這篇將依據官網上給出的design來詳細的分析,kafka是如何實現其高性能、高吞吐的。這一段應該會挺長的我想分兩篇來寫。今天這一篇主要從宏觀上說kafka實現的細節,下一篇,在從具體的技術上去分析。
我們先看kafka的設計元素:
1. 通常來說,kafka的使用是爲了消息的持久化(persistent messages)
2. 吞吐量是kafka設計的主要目標
3. 關於消費的狀態被記錄爲consumer的一部分,而不是server。這點稍微解釋下,這裏的server還是隻broker,誰消費了多少數據都記錄在消費者自己手中,不存在broker中。按理說,消費記錄也是一個日誌,可以放在broker中,至於爲什麼要這麼設計,我們寫下去了再說。
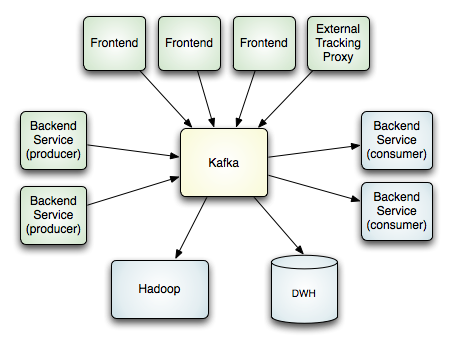
4. Kafka的分佈式可以表現在producer、broker、consumer都可以分佈在多臺機器上。
在講實現原理之前,我們還得了解幾個術語:
l Topic:其實官網上沒有單獨提這個詞,但topic其實才是理解的關鍵,在kafka中,不同的數據可以按照不同的topic存儲。
l Message:消息是kafka處理的對象,在kafka中,消息是被髮布到broker的topic中。而consumer也是從相應的topic中拿數據。也就是說,message是按topic存儲的。
l Consumer Group:雖然上面的設計元素第四條,我們說三者都可以部署到多臺機器上,三者分別並作爲一個邏輯的group,但對於consumer來說這樣的部署需要特殊的支持。Consumer Group就是讓多個(相關的)進程(機器)在邏輯上扮演一個consumer。這個group的定義其實是爲了去支持topic這樣的語義。在JMS中,大家最熟悉的是隊列,我們將所有的consumer放到一個group中,這樣就是隊列。而topic則是將consumer放置到與它相關的topic中去。所以無論一個topic存在於多少個consumer中, a message is stored only a single time。你可能會有疑問,備份怎麼辦,接着看下去。
接下來,我們來看kafka的實現究竟依賴了哪些東西。
1. 硬件上,kafka選用了硬盤直接讀寫,當然這裏也有策略。一個67200rpm STAT RAID5的陣列,線性讀寫速度是300MB/sec,如果是隨機讀寫,速度則是50K/sec。差距很明顯,所以kafka選的策略就是利用線性存儲,至於怎麼存,我們在存儲中會說到。
2. 關於緩存,kafka沒有使用內存作爲緩存。操作系統用個特性,如果不用direct I/O,那些閒置的memory會去做disk caching,如果 a process maintains an in-process cache of the data,這樣的情況下可能會產生雙份的pagecache,會存儲兩遍。另外Kafka跑在JVM上,本身JVM垃圾回收、創建對象都非常的耗內存,所以不再依賴於內存做緩存。All data is immediately written to a persistent log on the filesystem without any call to flush the data. 當然內核自己的flush不算了。溫泉做一次32G的內存緩存,需要大概10多分鐘。
3. Liner writer/reader:這樣做的雖然沒有B樹那樣多樣的變化,但卻有O(1)的操作,而且讀寫不會相互影響。同時,線性的讀寫也解耦了數據規模的問題。用廉價的存儲就可以達到很高的性價比。
4. Zero-copy:將數據從硬盤寫到socket一般需要經過…你可以自己算一下,這是操作系統裏的知識,答案在文章末尾,具體也可以看這裏:http://my.oschina.net/ielts0909/blog/85147。一句話,Zero-copy減少了IO的操作步驟。
5. GZIP and Snappy compression:考慮到傳輸最大的瓶頸就在於網絡上,kafka提供了對數據壓縮的各種協議。
6. 事務機制:雖然kafka對事務的處理比較薄弱,但是在message的分發上還是做了一定的策略來保證數據遞送的準確性:
At most once—this handles the first case described. Messages are immediately marked as consumed, so they can't be given out twice, but many failure scenarios may lead to losing messages.
At least once—this is the second case where we guarantee each message will be delivered at least once, but in failure cases may be delivered twice.
Exactly once—this is what people actually want, each message is delivered once and only once.
上述就是關於kafka的實現細節,主要寫了關於kafka採用到的技術和使用技術的原因,在後面一篇中,我將主要講述producer、broker、consumer之間的配合以及kafka的存儲問題。
--------------------------------------------------------------------------------
To understand the impact of sendfile, it is important to understand the common data path for transfer of data from file to socket:
- The operating system reads data from the disk into pagecache in kernel space
- The application reads the data from kernel space into a user-space buffer
- The application writes the data back into kernel space into a socket buffer
- The operating system copies the data from the socket buffer to the NIC buffer where it is sent over the network