




轉自:http://my.oschina.net/ielts0909/blog/92972
在我們大量使用分佈式數據庫、分佈式計算集羣的時候,是否會遇到這樣的一些問題:
l 我想分析一下用戶行爲(pageviews),以便我能設計出更好的廣告位
l 我想對用戶的搜索關鍵詞進行統計,分析出當前的流行趨勢。這個很有意思,在經濟學上有個長裙理論,就是說,如果長裙的銷量高了,說明經濟不景氣了,因爲姑娘們沒錢買各種絲襪了。
l 有些數據,我覺得存數據庫浪費,直接存硬盤又怕到時候操作效率低。
這個時候,我們就可以用到分佈式消息系統了。雖然上面的描述更偏向於一個日誌系統,但確實kafka在實際應用中被大量的用於日誌系統。
首先我們要明白什麼是消息系統,在kafka官網上對kafka的定義叫:A distributed publish-subscribe messaging system。publish-subscribe是發佈和訂閱的意思,所以更準確的說kafka是一個消息訂閱和發佈的系統。publish-subscribe這個概念很重要,因爲kafka的設計理念就可以從這裏說起。
我們將消息的發佈(publish)暫時稱作producer,將消息的訂閱(subscribe)表述爲consumer,將中間的存儲陣列稱作broker,這樣我們就可以大致描繪出這樣一個場面:
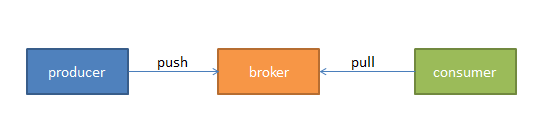
生產者(藍色,藍領麼,總是辛苦點兒)將數據生產出來,丟給broker進行存儲,消費者需要消費數據了,就從broker中去拿出數據來,然後完成一系列對數據的處理。
乍一看這也太簡單了,不是說了它是分佈式麼,難道把producer、broker和consumer放在三臺不同的機器上就算是分佈式了麼。我們看kafka官方給出的圖:
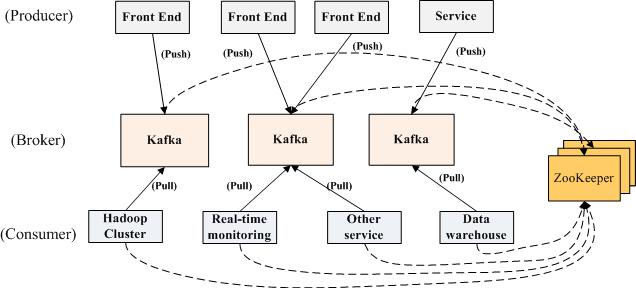
多個broker協同合作,producer和consumer部署在各個業務邏輯中被頻繁的調用,三者通過zookeeper管理協調請求和轉發。這樣一個高性能的分佈式消息發佈與訂閱系統就完成了。圖上有個細節需要注意,producer到broker的過程是push,也就是有數據就推送到broker,而consumer到broker的過程是pull,是通過consumer主動去拉數據的,而不是broker把數據主動發送到consumer端的。
這樣一個系統到底在哪裏體現出了它的高性能,我們看官網上的描述:
- Persistent messaging with O(1) disk structures that provide constant time performance even with many TB of stored messages.
- High-throughput: even with very modest hardware Kafka can support hundreds of thousands of messages per second.
- Explicit support for partitioning messages over Kafka servers and distributing consumption over a cluster of consumer machines while maintaining per-partition ordering semantics.
- Support for parallel data load into Hadoop.
至於爲什麼會有O(1)這樣的效率,爲什麼能有很高的吞吐量我們在後面的文章中都會講述,今天我們主要關注的還是kafka的設計理念。瞭解完了性能,我們來看下kafka到底能用來做什麼,除了我開始的時候提到的之外,我們看看kafka已經實際在跑的,用在哪些方面:
- LinkedIn - Apache Kafka is used at LinkedIn for activity stream data and operational metrics. This powers various products like LinkedIn Newsfeed, LinkedIn Today in addition to our offline analytics systems like Hadoop.
- Tumblr - http://highscalability.com/blog/2012/2/13/tumblr-architecture-15-billion-page-views-a-month-and-harder.html
- Mate1.com Inc. - Apache kafka is used at Mate1 as our main event bus that powers our news and activity feeds, automated review systems, and will soon power real time notifications and log distribution.
- Tagged - Apache Kafka drives our new pub sub system which delivers real-time events for users in our latest game - Deckadence. It will soon be used in a host of new use cases including group chat and back end stats and log collection.
- Boundary - Apache Kafka aggregates high-flow message streams into a unified distributed pubsub service, brokering the data for other internal systems as part of Boundary's real-time network analytics infrastructure.
- DataSift - Apache Kafka is used at DataSift as a collector of monitoring events and to track user's consumption of data streams in real time. http://highscalability.com/blog/2011/11/29/datasift-architecture-realtime-datamining-at-120000-tweets-p.html
- Wooga - We use Kafka to aggregate and process tracking data from all our facebook games (which are hosted at various providers) in a central location.
- AddThis - Apache Kafka is used at AddThis to collect events generated by our data network and broker that data to our analytics clusters and real-time web analytics platform.
- Urban Airship - At Urban Airship we use Kafka to buffer incoming data points from mobile devices for processing by our analytics infrastructure.
- Metamarkets - We use Kafka to collect realtime event data from clients, as well as our own internal service metrics, that feed our interactive analytics dashboards.
- SocialTwist - We use Kafka internally as part of our reliable email queueing system.
- Countandra - We use a hierarchical distributed counting engine, uses Kafka as a primary speedy interface as well as routing events for cascading counting
- FlyHajj.com - We use Kafka to collect all metrics and events generated by the users of the website.
至此你應該對kafka是一個什麼樣的系統有所體會,並能瞭解他的基本結構,還有就是他能用來做什麼。那麼接下來,我們再回到producer、consumer、broker以及zookeeper這四者的關係中來。

我們看上面的圖,我們把broker的數量減少,只有一臺。現在假設我們按照上圖進行部署:
l Server-1 broker其實就是kafka的server,因爲producer和consumer都要去連它。Broker主要還是做存儲用。
l Server-2是zookeeper的server端,zookeeper的具體作用你可以去官網查,在這裏你可以先想象,它維持了一張表,記錄了各個節點的IP、端口等信息(以後還會講到,它裏面還存了kafka的相關信息)。
l Server-3、4、5他們的共同之處就是都配置了zkClient,更明確的說,就是運行前必須配置zookeeper的地址,道理也很簡單,這之間的連接都是需要zookeeper來進行分發的。
l Server-1和Server-2的關係,他們可以放在一臺機器上,也可以分開放,zookeeper也可以配集羣。目的是防止某一臺掛了。
簡單說下整個系統運行的順序:
1. 啓動zookeeper的server
2. 啓動kafka的server
3. Producer如果生產了數據,會先通過zookeeper找到broker,然後將數據存放進broker
4. Consumer如果要消費數據,會先通過zookeeper找對應的broker,然後消費。
對kafka的初步認識就寫到這裏,接下去我會寫如何搭建kafka的環境。最後感謝大神 @rockybean 的指導和幫助。