




轉自: http://blog.csdn.net/wzht82/archive/2007/08/30/1765503.aspx
1
背景
我們知道數據是一個公司的命脈,隨着業務越做越大,數據量也會越來越大,計算也會越來越複雜,性能,可靠性,可擴展性的需求就會越來越強烈,這個時候一個集中式的數據庫顯然已經滿足不了需求了。對於技術決策者來說有兩條路可以走,第一:按照現有的大型數據庫的解決方案,比如SQL
SERVER Cluster或者Oracle RAC等,但是這也就等於走上了一條燒錢的道路,小則幾十萬,大則上百萬乃至更多;第二:使用真正能夠擴展的分佈式數據庫,利用中小型服務器甚至是PC機的累加來替代大型的服務器,這也是很多公司希望的,卻苦於沒有合適產品,現在有了ClusterKiller,用它真正能給您帶來:
高性能,高可用性,高擴展性,高性價比。
http://www.mediafire.com/?bd0bdjm2gxh
介紹的錄像版本
http://www.mediafire.com/?0tygenydtdg
demo的錄像版本
http://www.mediafire.com/?bhfalz09i4e 試用版
2
方案比較
2.1 SQL SERVER的集羣模式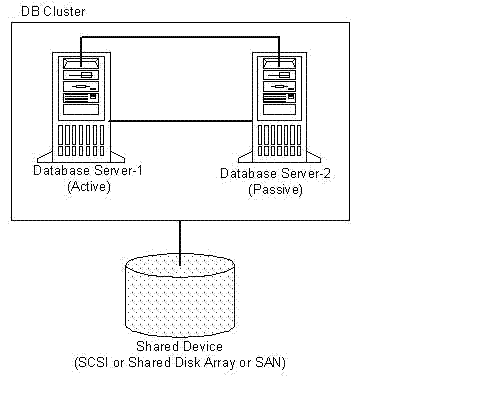
這種結構只能說是一種故障轉移的機制,當有一個節點出現問題後把負載轉移到另一個節點上。在負載能力上和擴展性上沒有任何辦法,而且還浪費了硬件資源
2.2 Oracle Real Application Clusters
(RAC)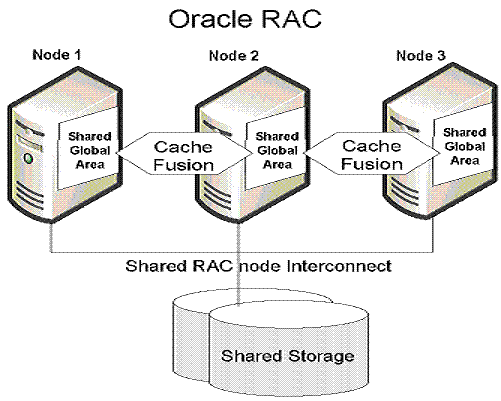
Oracle Rac最多可支持64個節點,基本上算是解決了性能,擴展性的問題了,但是它在存儲上還是一個單點,且不說出現故障怎麼辦,IO也可能會成爲性能瓶頸。 我們都知道一個數據庫大到一定程度的時候,在物理上分區才能從根本上解決問題,對幾十萬數據進行查找和幾百萬上千萬的數據進行查找在系統的消耗上以及響應時間上有着幾何級的降低。
2.3 Cluster Killer
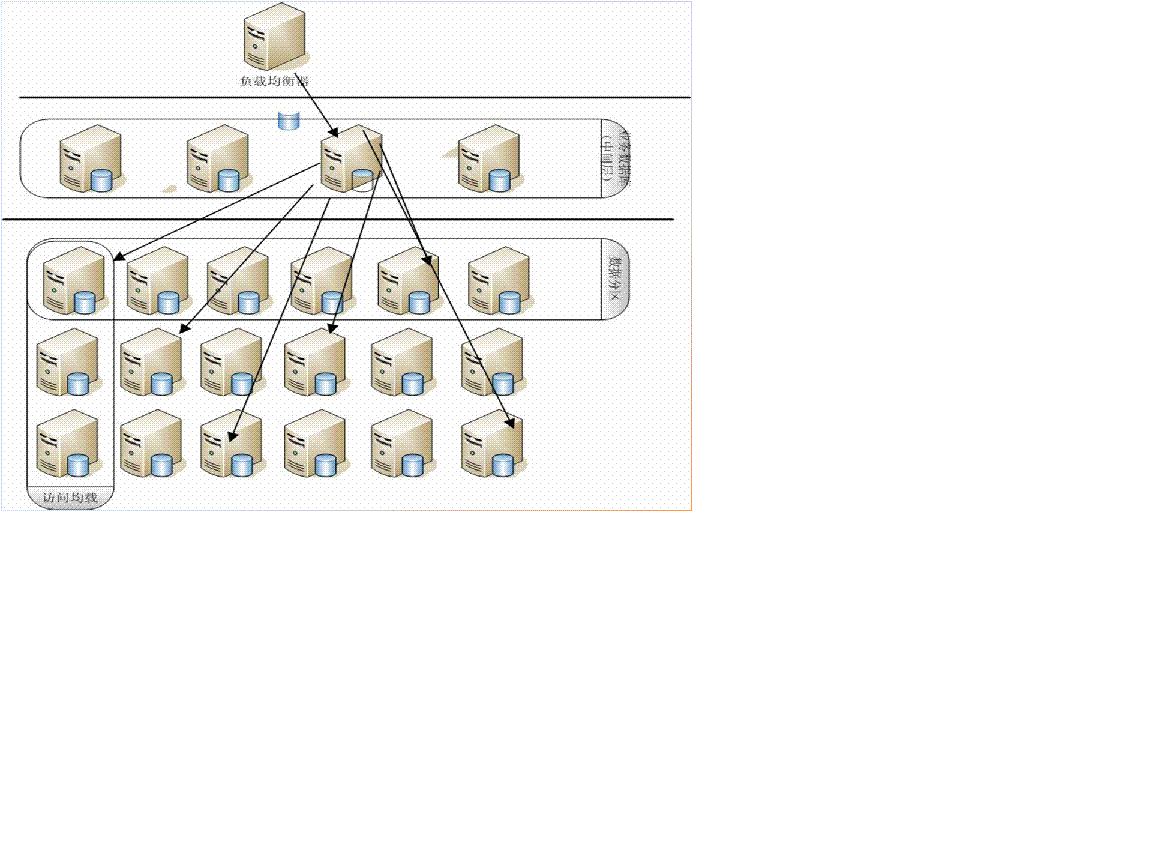
從圖例中可以看出,下面的像網格一樣的機器叫數據層,每個機器上存儲着數據全集的一個分區,每一行組成一個數據全集,每一列是某個分區的多份相同的數據從而達到查詢時負載均衡的效果,同時也是高可用性的保障:某個列的機器出現問題後其他的機器會負載訪問。爲了不讓這樣一個複雜的結構暴露給應用程序,在數據層上面又放了一層機器叫中間層,中間層機器的數據庫中駐留着的中間件來處理SQL語句,根據SQL語句的類型和條件來決定由哪些機器來提供服務。在中間層的外面加一個負載均衡設備, 這樣應用程序或者開發/維護的人員通過負載均衡設備連接到中間層的任意一臺機器上操作,感覺就像還在使用原來的一個數據庫那樣,易用性非常好。以下從各個角度具體的說明一下:
l
開發:中間件是宿主在數據庫中的,所以面對數據庫寫SQL語句的方式沒有改變,只需要把SQL語句從語法的角度上封裝一下即可。還是利用原有的數據庫的管理工具,不需要使用的新的管理工具,不需要改變原有的使用習慣,不需要學習新的知識。
l
數據庫維護:對於維護表,存儲過程,安全等數據庫對象還是像使用一個數據庫那樣在中間層的任意一臺機器上執行,中間件會抓取到更改並分發到其他的機器上。不會增加額外的工作量。
l
機器維護:因爲這個結構比集中式的結構在機器的數量上要增加了很多,所以在機器層面上的維護成本比以前要有所增加。不過對於機器的維護不會影響整個結構的可用性,只需要在中間層的任意一臺機器上更改一下配置就可以把某臺機器添加到結構中或從結構中移出。
l
診斷:當出現異常後會明確的指定出錯原因以及出錯的機器,另外還有執行日誌詳細的記錄每個執行步驟的細節。
l
分區:支持多種數據類型的分區,分區方式有靜態分區和線形增長兩種方式。靜態分區不言而喻就是一開始就要規劃好分區的個數;線形增長方式就是一開始只有一個或少數幾個分區列,隨着數據量和訪問的增長的時候再添加新的分區從而達到了線性擴展的效果
l
總結:中間件的定位和作用是隻是把很多的數據庫服務器聯合起來最終實現高擴展性,高可用性以及高性能。許多關鍵的數據庫技術比如事務,連接池,鎖,安全等還是依靠數據庫來完成,無論從研發成本還是實施的風險都降到最低。
2.4 指標比較
l
故障轉移/可靠性
n
SQL SERVER Cluster:能做到前面的計算節點的故障轉移,後面的存儲設備還是單點
n
Oracle RAC:能做到前面的計算節點的故障轉移,後面的存儲設備還是單點
n
Cluster Killer:從每個維度上都是可擴展的,所以無論從哪個維度上的機器損壞以後都能找到替代者從而實現故障轉移。
l
負載均衡
n
SQL SERVER Cluster:從它的工作機制上可以看出它的兩個節點只能有一個處於工作狀態,所以沒有負載均衡能力
n
Oracle RAC:它前面的幾個計算節點是可以同時提供服務的,但是後面的存儲設備只有一個。所以說是計算能夠均載,存儲不能均載
n
Cluster Killer:即能夠計算均載也能存儲均載
l
擴展性
n
SQL SERVER Cluster:只能夠兩個計算節點帶一個存儲組成
n
Oracle RAC:最多64個節點帶一個存儲組成
n
Cluster Killer:每個維度上都能擴展,而且能夠根據數據的增加線形擴展,最小用兩臺機器就可以搭建起來,另外每個機器之間的關係是鬆散耦合的,擴展起來不需要複雜的安裝,配置。
l
硬件要求
n
SQL SERVER Cluster:因爲要使用能夠連接存儲設備的服務器,而這類服務器的配置都很高,都是中高檔服務器,價格不菲。而且還有一個節點在正常情況下是閒置的,所以性價比低
n
Oracle RAC:它的硬件配置要求同上,但是起碼沒有閒置的資源,性價比中
n
Cluster Killer:不需要每個機器的緊密耦合,對機器的配置沒有要求,用買一個集羣的錢可以買幾十臺小型服務器或者上百臺的PC機,Google的分佈式結構已經驗證了它的高性價比。
3
成功案例
3.1 某大型求職/招聘網站
l
項目背景:給企業方使用的一個搜索個人簡歷的系統,特點是數據量大,查詢條件複雜,更新頻繁。具體數據爲:簡歷主表700萬,子表從1600萬到2000萬不等;每天查詢12萬次,40%的查詢條件中帶有關鍵詞;個人用戶每天新增/更新簡歷的事務數爲120萬次。
l
解決方案:使用30臺DELL 2950小型PC服務器搭建起分佈式數據庫結構。
l
性能測試數據:
n
測試模型:查詢
n
查詢條件:大於等於線上用戶的實際條件
n
測試工具:LoadRunner8.0
n
測試時間:20小時
n
併發數:50
n
響應時間:平均1.5秒,90%的響應時間在1.9秒以下,方差:1.1
n
查詢次數:成功487325,超時:98,沒有其它類型錯誤
l
收益:
n
因爲組件不會影響業務邏輯,所以業務程序不用重構,只用2天就升級到新的架構上
n
查詢時間從原來的10秒縮減到不到1秒,92%的查詢在秒以下,大大提高客戶體驗
n
真正的7*24的持續提供服務
n
系統的擴展能力大大增強,使得客戶有能力上原來不能上的更復雜的業務邏輯,建立更好的搜索模型,從而提升了客戶在行業內的競爭實力。