




join 是 SQL查詢中很常見的一種操作,具體來講有join,left join, right join,full join等很多形式。具體的原理如下圖所示。但其中最常見的還是使用left join 。
本文代碼在mysql和hive中均測試通過,代碼本身難度和長度都不大,我準備了測試數據的mysql和hive代碼,如果覺得有必要,你可以在後臺回覆“left”獲取,方便自己修改和練習。

left join 通俗的解釋:以左表爲主表,返回左表的所有行,如果右表中沒有匹配,則依然會有左表的記錄,右表字段用null填充。看起來非常好理解,但實際操作的過程中可能會有一些很容易被忽略的點。
一、left join 之後的記錄有幾條
關於這一點,是要理解left join執行的條件。在A join B的時候,我們在on語句裏指定兩表關聯的鍵。只要是符合鍵值相等的,都會出現在結果中。這裏面有一對一,一對多,多對多等幾種情況。我們用例子來說明。
1、一對一
這種情況最好理解。t_name表,有id,name(用戶名稱),sex(性別),dt(註冊日期)等字段。t_age表。有id,age(年齡),province(省份),dt(更新日期)等字段。表中包含的信息如下:
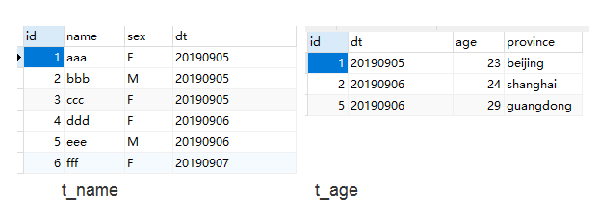
現在我們進行t_name(左表,別名a)和t_age(右表,別名b)的left join 操作,關聯鍵爲id。a表有6條記錄,b表有3條記錄,且關鍵的鍵是唯一的,因此最終結果以a表爲準有6條記錄,b表有3條關聯不上,相應的記錄中,b表所有的字段都爲空。
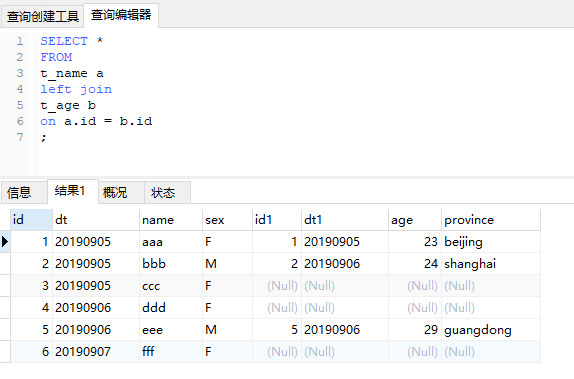
2、一對多
這回我們用t_age作爲左表,關聯條件爲dt。重點看dt爲20190905的記錄。由於右表有3條20190905,這三條在關聯的時候都滿足關聯條件,因此最終的結果會有3條記錄是20190905。
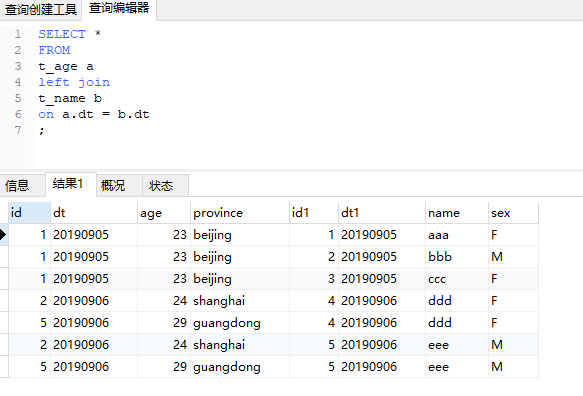
這回爲準的表是t_age表,但顯然結果並不是原本的3條記錄,而是7條:20190905 3條,20190906 4條。如果你不太理解,可以繼續往下看。
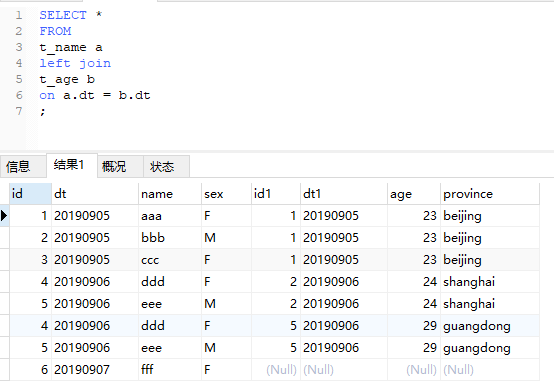
3、多對多
上面例子中,20190906的記錄最終有4條,同樣是因爲滿足了關聯條件,是一種2對2的情況。這裏我們還是回到t_name表做主表的情況,用dt來關聯。可以預見,與2中相比,這次結果中會多一行20190907的,而b表相應的字段依然爲空。
2和3中我們看到了一對多和多對多的情況,其實前者是後者的特例。我們只是很簡要的把兩個表關聯之後所有的字段都列出來了,但實際中可能需要做一些統計,聚合等。這裏提醒大家在寫關聯條件之前,最好思考一下最終的結果是什麼樣的,最終可能有幾行,會不會在計數的時候多統計,哪些行可能會存在空值,哪些字段可能會存在空值等。不要因爲想當然而犯了錯誤。這裏算是拋磚引玉,感興趣的同學可以看看這篇博客,進一步學習,
https://www.cnblogs.com/qdhxhz/p/10897315.html
二、left join 的執行原理
接下來我們進一步看一下連接條件寫在on裏和寫在where裏的區別。在這之前,我們可以看看left join的具體執行邏輯。我參考了網上以爲大神的博客:
https://developer.aliyun.com/article/718897,總結如下
mysql採用嵌套循環的方式處理left join。
SELECT * FROM LT LEFT JOIN RT ON P1(LT,RT)) WHERE P2(LT,RT)
其中P1是on過濾條件,缺失則認爲是TRUE,P2是where過濾條件,缺失也認爲是TRUE,該語句的執行邏輯可以描述爲:
- FOR each row lt in LT {// 遍歷左表的每一行
- BOOL b = FALSE;
- FOR each row rt in RT such that P1(lt, rt) {// 遍歷右表每一行,找到滿足join條件的行
- IF P2(lt, rt) {//滿足 where 過濾條件
- t:=lt||rt;//合併行,輸出該行
- }
- b=TRUE;// lt在RT中有對應的行
- }
- IF (!b) { // 遍歷完RT,發現lt在RT中沒有有對應的行,則嘗試用null補一行
- IF P2(lt,NULL) {// 補上null後滿足 where 過濾條件
- t:=lt||NULL; // 輸出lt和null補上的行
- }
- }
- }
如果代碼看不懂,直接看結論就好:
- 如果想對右表進行限制,則一定要在on條件中進行,若在where中進行則可能導致數據缺失,導致左表在右表中無匹配行的行在最終結果中不出現,違背了我們對left join的理解。因爲對左表無右表匹配行的行而言,遍歷右表後b=FALSE,所以會嘗試用NULL補齊右表,但是此時我們的P2對右錶行進行了限制,NULL若不滿足P2(NULL一般都不會滿足限制條件,除非IS NULL這種),則不會加入最終的結果中,導致結果缺失。
2. 如果沒有where條件,無論on條件對左表進行怎樣的限制,左表的每一行都至少會有一行的合成結果,對左錶行而言,若右表若沒有對應的行,則右表遍歷結束後b=FALSE,會用一行NULL來生成數據,而這個數據是多餘的。所以對左表進行過濾必須用where。
我們再來看看實例,返回來研究這段話可能更好理解一些。
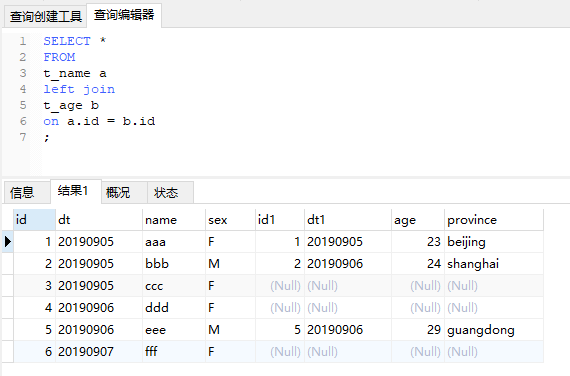
1、只有1個on條件
這裏可以直接看第一部分中的例子。最終會輸出以左表爲準,右表匹配不上補null的結果,但可能會有多對多的情況。
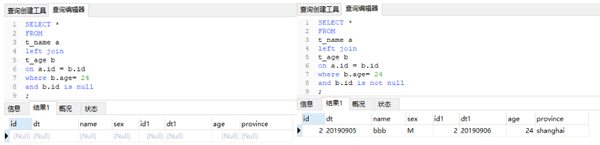
2、有2個on條件
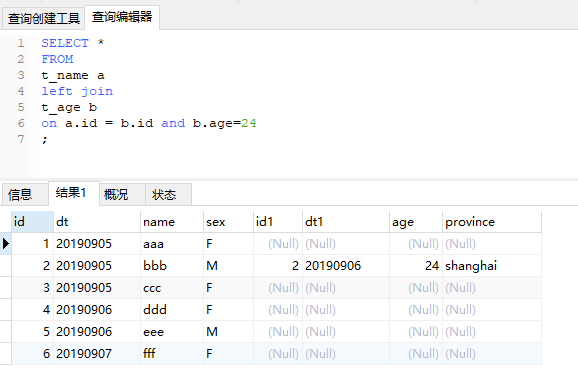
上圖是在關聯條件中增加了b.age=24之後的輸出結果。由於對b表進行了限制,滿足條件的只有一個,但是由於沒有where條件,因此依然要以左表爲準,又因爲是一對一,所以輸出還是左表的記錄數。更極端的,我們可以“清空”b表。
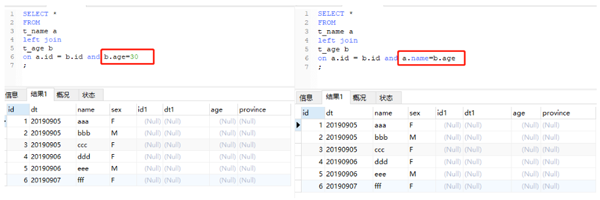
以上兩種情況,在b表中都沒有符合條件的結果,因此在以左表爲準的基礎上,右邊的所有字段都爲空。
3、有where的情況
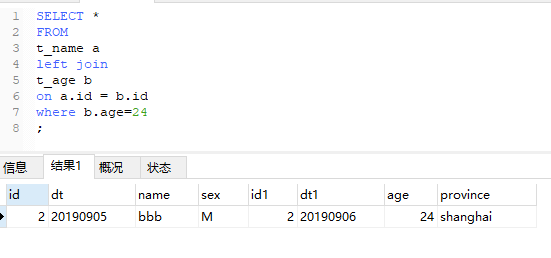
將b.age=24寫到where裏,發現結果中只有這一行,打破了“left join”以左表爲主的限制。同樣再來看下後兩種情況寫到where裏會發生什麼:
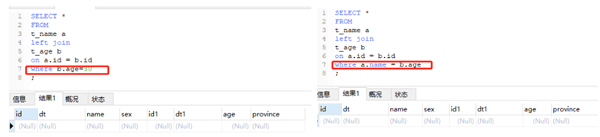
沒錯,結果全部是爲空的。因爲where 在 on 後面執行,而on生成的結果裏沒有滿足條件的記錄!
這裏給出兩個結論:
1、 on條件是在生成臨時表時使用的條件,它不管on中的條件是否爲真,都會返回左邊表中的記錄。
2、where條件是在臨時表生成好後,再對臨時表進行過濾的條件。這時已經沒有left join的含義(必須返回左邊表的記錄)了,條件不爲真的就全部過濾掉。
4、有is null 或者有 is not null的情況
當條件寫在on中:
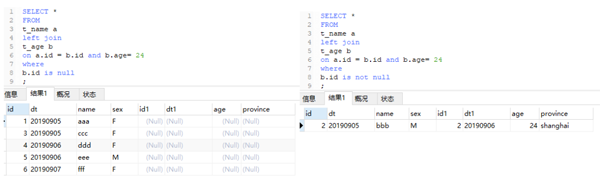
當條件寫在where 中:
直觀的我們理解,WHERE … IS NULL 子句將從匹配階段後的數據中過濾掉不滿足匹配條件的數據行。對於條件寫在on中的情況,又可以說,is null是否定匹配條件,is not null是肯定匹配條件。對於條件寫在where中的,其實相比之下更容易理解,要看已有的where條件產生的結果是什麼。讀者可以從上面的例子中思考一下。
三、看兩個實際案例
經過上面的討論,我們來看兩個案例,進一步理解和思考一下left join 的用法。
1、案例1
這個案例來自於一篇網絡博客,前文有提到。鏈接:
https://developer.aliyun.com/article/718897
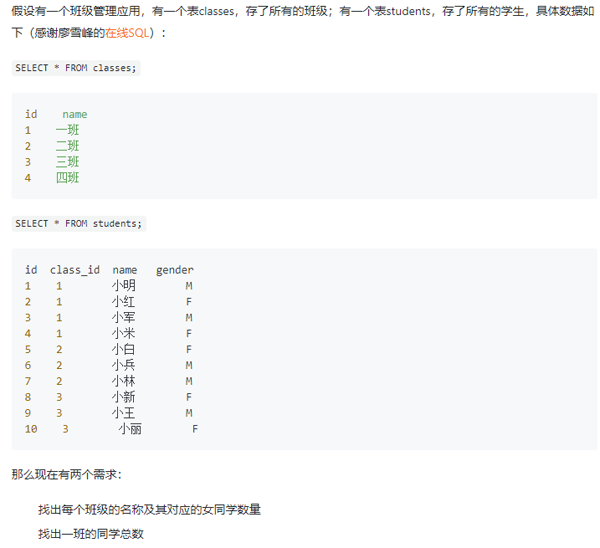
大家可以先思考一下怎麼寫再到原文看答案。事實上,每個需求都很容易有兩種寫法,區別就在於條件是寫在where中還是寫在on中。判斷的原則就是我們需要保證結果中數據不缺失也不多餘。需求1的條件需要寫在on中(保證結果不缺失),需求2的條件需要寫在where中(保證結果不多餘)。
2、案例2
假設現在有一個用戶活躍表t_active,記錄了每天活躍的uid和相應的活躍日期。現在想要看距離某一天日期差爲0天,1天,2天,3天…活躍的用戶在當天還有多少活躍(也就是一個留存的概念)。期望得到的如下表所示:
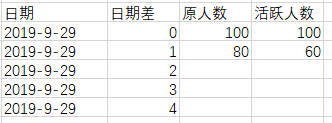
對於表中數據,我們可以這樣理解。距離2019-09-29 0天(也就是2019-09-29)的活躍人數爲100,2019-09-29當天活躍的還剩100,距離2019-09-29 1天(也就是2019-09-28)的活躍人數爲80,2019-09-29當天還剩60。以此類推。
對於這個需求,我們可以使用left join進行自關聯,用之前活躍的天作爲左表,最終期望計算的天作爲右表,計算日期差,並進行左右表分別計數。初步的SQL如下:(數據是自己編的)
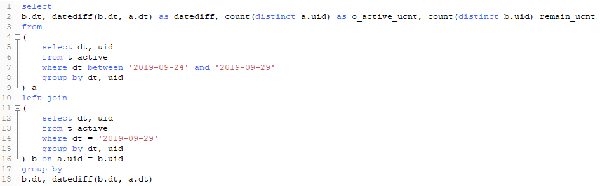
在往下看之前請確認你理解了需求目標,並先思考下,以上的寫法有問題嗎?能否得到上面期望的結果?
原始數據和這段SQL運行的結果如下:
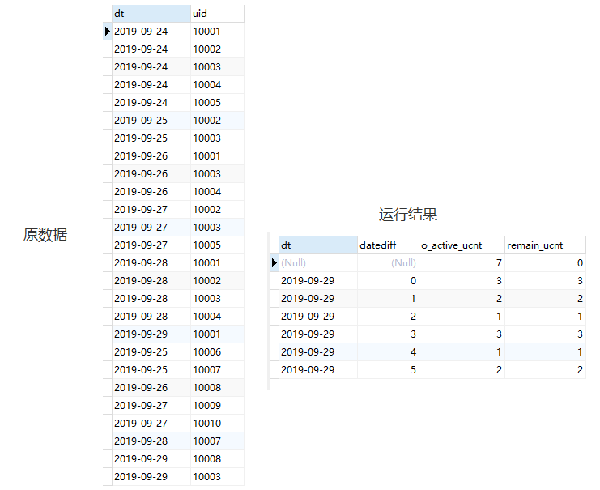
運行結果中出現了dt和datediff爲null的情況,你能想象的到這是爲什麼嗎?而且當dt不爲null的時候,最後兩列的數據是相同的,顯然和我們的預期不符。這是什麼原因呢?我們來逐步看一下。
首先,我們使用left join 的方式應該是沒有問題的,我們先看看不加任何計算的,select * 的結果是啥。
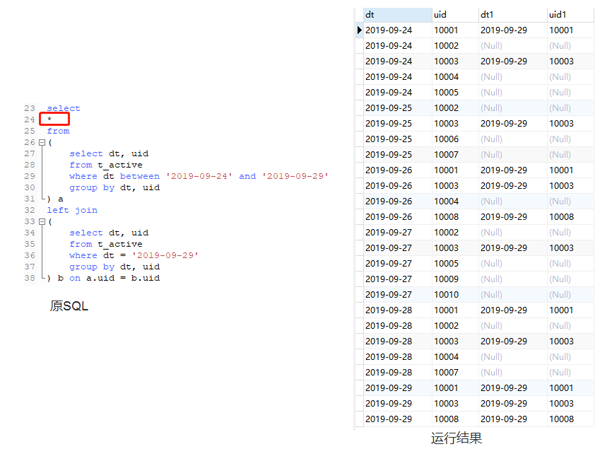
可以看到,這相當於是前文提到的不加where 條件的一對一關聯,結果會以左表爲準,關聯不上的用null補齊。值得注意的是,關聯不上的日期是null值,而null值在參與datediff的計算時,結果會是null。到這裏你是不是明白一點了。由於null值參與計算,導致最終datediff 有null值,並且計數的時候,由於null值存在,最終用日期差作爲維度的時候,導致左表和右表的數量是一樣的。如下面代碼所示:
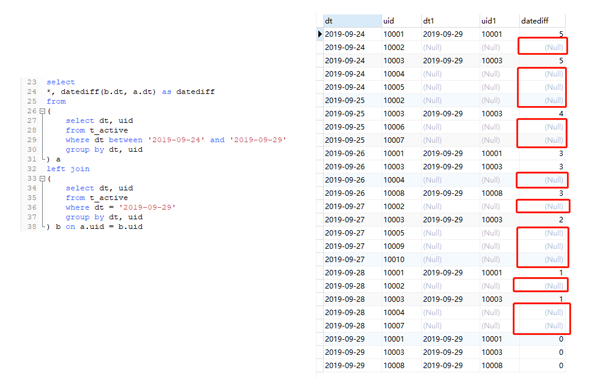
從上面的結果我們可以推演出最開始的SQL運行結果。例如,datediff=5的時候,共兩條記錄,左表右表的count(distinct uid)都爲2。datediff爲null的時候,左表結果爲7,右表爲0,其他的以此類推,和前面的結果是一樣的。這樣我們就知道了,沒有達到預期的根源在於存在空的日期。那麼怎麼解決這個問題呢,顯然就是把空日期填補上就可以了。可以使用case when 當右表日期關聯不上的時候,用相應日期補足。代碼如下:
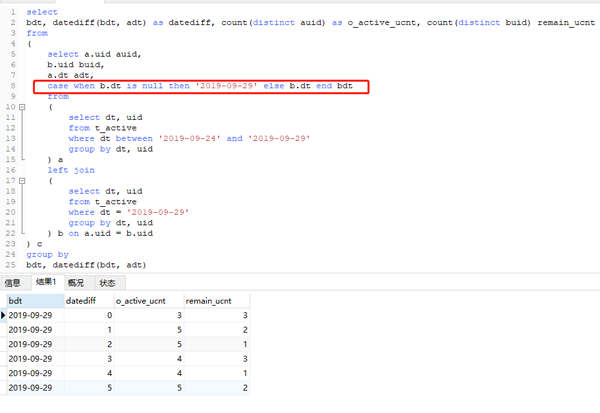
可以看到最終得到了想要的結果,以最後一行爲例,它表示,距離2019-09-29 5天的那天(也就是2019-09-24)活躍的人數有5個,那些人在2019-09-29仍然活躍的有2人,你可以看一下明細數據覈對一下。其餘的以此類推。我們使用case when 把日期寫死了,這個是建立在我們知道是哪天的基礎上的。實際中可能是一個變量,但一定也是一個固定的值,需要具體情況具體分析。
四、總結
本文我們學習了left join的原理和實踐中可能會遇到的問題。包括關聯時結果中的記錄數,關聯條件寫在on和where中的區別,where語句中存在is null的時候如何理解,最後用實例幫助大家進行理解。在此過程中參考了網上的一些博客,大家可以在閱讀本文的基礎上進行查閱。希望對你有所幫助!後臺回覆“left”,可以獲取本文測試所用的數據集合代碼;