




轉載聲明
本系列文章轉自某技術大佬的博客https://www.cnblogs.com/bangerlee/
該系列文章是我在網上能夠找到的最全面的分佈式理論介紹文章了,一直沒看到有人整理這個系列文章,所以這次我就來做技術好文的搬運工,給整合了一把,覺得寫得好的朋友不妨去這位大佬的博客上打賞一把。
分佈式系統理論 - 從放棄到入門
隨承載用戶數量的增加和容災的需要,越來越多互聯網後臺系統從單機模式切換到分佈式集羣。回顧自己畢業五年來的工作內容,同樣有這樣的轉變。
畢業頭兩年負責維護運行在刀片機上的業務,在機房裏拔插單板的日子是我逝去的青春。設備之間通過VCS組成冷備,但即使有雙機軟件保護,宕機、網絡丟包等問題發生時業務仍會受影響。這樣的系統架構下爲保證SLA,有時候需要深入Linux系統內核或硬件層面分析機器重啓的原因。

接下來負責維護承載在分佈式集羣上的業務,相比前面的工作,這個階段主要關注點不是單節點的異常,更多是系統整體的穩定和健壯。面對紛繁複雜的系統,剛開始的時候有這樣的感覺:

龐大複雜的分佈式系統前,應該從哪方面入手提升對其的認識和理解、提升專業性?網上可以找到很多分佈式系統相關的論文和資料,但歸納起來要表達的主要意思是什麼?
結合自己這幾年的工作經驗,總結分佈式系統的核心就是解決一個問題:不同節點間如何達成共識。
看似簡單的問題因網絡丟包、節點宕機恢復等場景變得複雜,由此才衍生出很多概念、協議和理論。爲探究共識問題最大能解決的程度,於是有FLP、CAP邊界理論;爲在特定條件和範圍內解決該問題,於是有一致性協議Paxos、Raft、Zab和Viewstamped Replication;爲構建這些協議,於是有多數派、Leader選舉、租約、邏輯時鐘等概念和方法。
2016年我閱讀了分佈式系統領域一些代表性的論文和博文,圍繞“不同節點如何達成共識”這個問題,加入自己的認識和理解後有下面7篇小結:
[一致性、2PC和3PC](http://www.cnblogs.com/bangerlee/p/5268485.html)
[選舉、多數派和租約](http://www.cnblogs.com/bangerlee/p/5767845.html)
[時間、時鐘和事件順序](http://www.cnblogs.com/bangerlee/p/5448766.html)
[CAP](http://www.cnblogs.com/bangerlee/p/5328888.html)
[Paxos](http://www.cnblogs.com/bangerlee/p/5655754.html)
[Raft、Zab](http://www.cnblogs.com/bangerlee/p/5991417.html)
[Paxos變種和優化](http://www.cnblogs.com/bangerlee/p/6189646.html)構思和寫作技術類文章是一個辛苦的過程,一方面要閱讀很多資料並轉化成自己的理解、找到儘量不拾人牙慧的立意和角度,一方面要絞盡腦汁組織語言讓預期的讀者能夠容易理解。
但它也是一個有趣的過程,把知識捋一遍後原本一些模糊的概念變得清晰,寫作過程中想到的一些有意思的內容我也會將它穿插到文章裏,有時候會被自己想到的一些小機靈逗樂 :)

希望這幾篇整理能爲系統性地介紹分佈式理論中文資料添一塊磚、加一片瓦。
分佈式系統理論基礎 - 一致性、2PC和3PC
引言
狹義的分佈式系統指由網絡連接的計算機系統,每個節點獨立地承擔計算或存儲任務,節點間通過網絡協同工作。廣義的分佈式系統是一個相對的概念,正如Leslie Lamport所說<sup>[1]</sup>:
What is a distributed systeme. Distribution is in the eye of the beholder.
To the user sitting at the keyboard, his IBM personal computer is a nondistributed system.
To a flea crawling around on the circuit board, or to the engineer who designed it, it's very much a distributed system.
一致性是分佈式理論中的根本性問題,近半個世紀以來,科學家們圍繞着一致性問題提出了很多理論模型,依據這些理論模型,業界也出現了很多工程實踐投影。下面我們從一致性問題、特定條件下解決一致性問題的兩種方法(2PC、3PC)入門,瞭解最基礎的分佈式系統理論。
一致性(consensus)
何爲一致性問題?簡單而言,一致性問題就是相互獨立的節點之間如何達成一項決議的問題。分佈式系統中,進行數據庫事務提交(commit transaction)、Leader選舉、序列號生成等都會遇到一致性問題。這個問題在我們的日常生活中也很常見,比如牌友怎麼商定幾點在哪打幾圈麻將:

《賭聖》,1990
假設一個具有N個節點的分佈式系統,當其滿足以下條件時,我們說這個系統滿足一致性:
- 全認同(agreement): 所有N個節點都認同一個結果
- 值合法(validity): 該結果必須由N個節點中的節點提出
- 可結束(termination): 決議過程在一定時間內結束,不會無休止地進行下去
有人可能會說,決定什麼時候在哪搓搓麻將,4個人商量一下就ok,這不很簡單嗎?
但就這樣看似簡單的事情,分佈式系統實現起來並不輕鬆,因爲它面臨着這些問題:
- 消息傳遞異步無序(asynchronous): 現實網絡不是一個可靠的信道,存在消息延時、丟失,節點間消息傳遞做不到同步有序(synchronous)
- 節點宕機(fail-stop): 節點持續宕機,不會恢復
- 節點宕機恢復(fail-recover): 節點宕機一段時間後恢復,在分佈式系統中最常見
- 網絡分化(network partition): 網絡鏈路出現問題,將N個節點隔離成多個部分
- 拜占庭將軍問題(byzantine failure)<sup>[2]</sup>: 節點或宕機或邏輯失敗,甚至不按套路出牌拋出干擾決議的信息
假設現實場景中也存在這樣的問題,我們看看結果會怎樣:

<pre>我: 老王,今晚7點老地方,搓夠48圈不見不散!
……
(第二天凌晨3點) 隔壁老王: 沒問題! // 消息延遲
我: ……
我: 小張,今晚7點老地方,搓夠48圈不見不散!
小張: No ……
(兩小時後……)
小張: No problem! // 宕機節點恢復
我: ……
我: 老李頭,今晚7點老地方,搓夠48圈不見不散!
老李: 必須的,大保健走起! // 拜占庭將軍 (這是要打麻將呢?還是要大保健?還是一邊打麻將一邊大保健……)</pre>
還能不能一起愉快地玩耍...
我們把以上所列的問題稱爲系統模型(system model),討論分佈式系統理論和工程實踐的時候,必先劃定模型。例如有以下兩種模型:
- 異步環境(asynchronous)下,節點宕機(fail-stop)
- 異步環境(asynchronous)下,節點宕機恢復(fail-recover)、網絡分化(network partition)
2比1多了節點恢復、網絡分化的考量,因而對這兩種模型的理論研究和工程解決方案必定是不同的,在還沒有明晰所要解決的問題前談解決方案都是一本正經地耍流氓。
一致性還具備兩個屬性,一個是強一致(safety),它要求所有節點狀態一致、共進退;一個是可用(liveness),它要求分佈式系統24*7無間斷對外服務。FLP定理(FLP impossibility)<sup>[3][4] </sup>已經證明在一個收窄的模型中(異步環境並只存在節點宕機),不能同時滿足 safety 和 liveness。
FLP定理是分佈式系統理論中的基礎理論,正如物理學中的能量守恆定律徹底否定了永動機的存在,FLP定理否定了同時滿足safety 和 liveness 的一致性協議的存在。

《怦然心動 (Flipped)》,2010
工程實踐上根據具體的業務場景,或保證強一致(safety),或在節點宕機、網絡分化的時候保證可用(liveness)。2PC、3PC是相對簡單的解決一致性問題的協議,下面我們就來了解2PC和3PC。
2PC
2PC(tow phase commit)兩階段提交<sup>[5]</sup>顧名思義它分成兩個階段,先由一方進行提議(propose)並收集其他節點的反饋(vote),再根據反饋決定提交(commit)或中止(abort)事務。我們將提議的節點稱爲協調者(coordinator),其他參與決議節點稱爲參與者(participants, 或cohorts):

2PC, phase one
在階段1中,coordinator發起一個提議,分別問詢各participant是否接受。
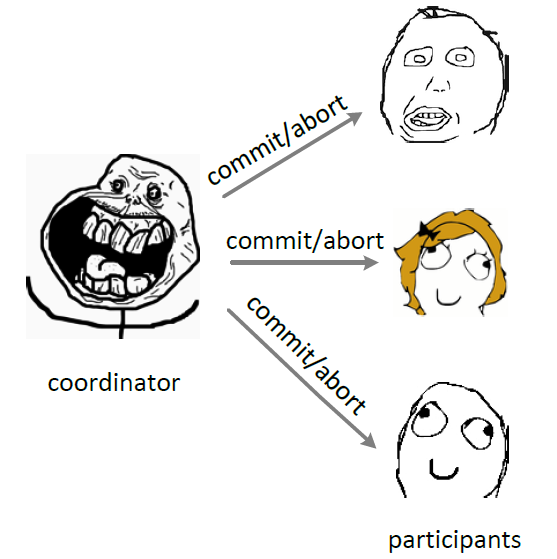
2PC, phase two
在階段2中,coordinator根據participant的反饋,提交或中止事務,如果participant全部同意則提交,只要有一個participant不同意就中止。
在異步環境(asynchronous)並且沒有節點宕機(fail-stop)的模型下,2PC可以滿足全認同、值合法、可結束,是解決一致性問題的一種協議。但如果再加上節點宕機(fail-recover)的考慮,2PC是否還能解決一致性問題呢?
coordinator如果在發起提議後宕機,那麼participant將進入阻塞(block)狀態、一直等待coordinator迴應以完成該次決議。這時需要另一角色把系統從不可結束的狀態中帶出來,我們把新增的這一角色叫協調者備份(coordinator watchdog)。coordinator宕機一定時間後,watchdog接替原coordinator工作,通過問詢(query) 各participant的狀態,決定階段2是提交還是中止。這也要求 coordinator/participant 記錄(logging)歷史狀態,以備coordinator宕機後watchdog對participant查詢、coordinator宕機恢復後重新找回狀態。
從coordinator接收到一次事務請求、發起提議到事務完成,經過2PC協議後增加了2次RTT(propose+commit),帶來的時延(latency)增加相對較少。
3PC
3PC(three phase commit)即三階段提交<sup>[6][7]</sup>,既然2PC可以在異步網絡+節點宕機恢復的模型下實現一致性,那還需要3PC做什麼,3PC是什麼鬼?
在2PC中一個participant的狀態只有它自己和coordinator知曉,假如coordinator提議後自身宕機,在watchdog啓用前一個participant又宕機,其他participant就會進入既不能回滾、又不能強制commit的阻塞狀態,直到participant宕機恢復。這引出兩個疑問:
- 能不能去掉阻塞,使系統可以在commit/abort前回滾(rollback)到決議發起前的初始狀態
- 當次決議中,participant間能不能相互知道對方的狀態,又或者participant間根本不依賴對方的狀態
相比2PC,3PC增加了一個準備提交(prepare to commit)階段來解決以上問題:
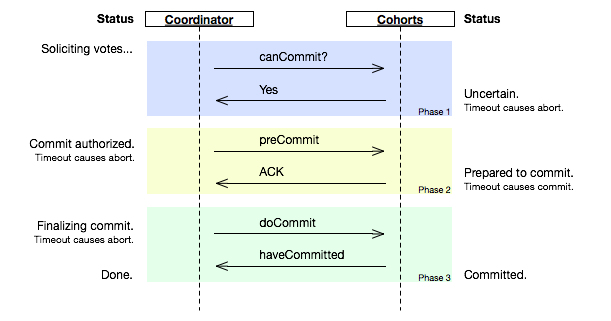
圖片截取自wikipedia
coordinator接收完participant的反饋(vote)之後,進入階段2,給各個participant發送準備提交(prepare to commit)指令。participant接到準備提交指令後可以鎖資源,但要求相關操作必須可回滾。coordinator接收完確認(ACK)後進入階段3、進行commit/abort,3PC的階段3與2PC的階段2無異。協調者備份(coordinator watchdog)、狀態記錄(logging)同樣應用在3PC。
participant如果在不同階段宕機,我們來看看3PC如何應對:
- 階段1: coordinator或watchdog未收到宕機participant的vote,直接中止事務;宕機的participant恢復後,讀取logging發現未發出贊成vote,自行中止該次事務
- 階段2: coordinator未收到宕機participant的precommit ACK,但因爲之前已經收到了宕機participant的贊成反饋(不然也不會進入到階段2),coordinator進行commit;watchdog可以通過問詢其他participant獲得這些信息,過程同理;宕機的participant恢復後發現收到precommit或已經發出贊成vote,則自行commit該次事務
- 階段3: 即便coordinator或watchdog未收到宕機participant的commit ACK,也結束該次事務;宕機的participant恢復後發現收到commit或者precommit,也將自行commit該次事務
因爲有了準備提交(prepare to commit)階段,3PC的事務處理延時也增加了1個RTT,變爲3個RTT(propose+precommit+commit),但是它防止participant宕機後整個系統進入阻塞態,增強了系統的可用性,對一些現實業務場景是非常值得的。
小結
以上介紹了分佈式系統理論中的部分基礎知識,闡述了一致性(consensus)的定義和實現一致性所要面臨的問題,最後討論在異步網絡(asynchronous)、節點宕機恢復(fail-recover)模型下2PC、3PC怎麼解決一致性問題。
閱讀前人對分佈式系統的各項理論研究,其中有嚴謹地推理、證明,有一種數學的美;觀現實中的分佈式系統實現,是綜合各種因素下妥協的結果。
分佈式系統理論基礎 - 選舉、多數派和租約
選舉(election)是分佈式系統實踐中常見的問題,通過打破節點間的對等關係,選得的leader(或叫master、coordinator)有助於實現事務原子性、提升決議效率。 多數派(quorum)的思路幫助我們在網絡分化的情況下達成決議一致性,在leader選舉的場景下幫助我們選出唯一leader。租約(lease)在一定期限內給予節點特定權利,也可以用於實現leader選舉。
下面我們就來學習分佈式系統理論中的選舉、多數派和租約。
選舉(electioin)
一致性問題(consistency)是獨立的節點間如何達成決議的問題,選出大家都認可的leader本質上也是一致性問題,因而如何應對宕機恢復、網絡分化等在leader選舉中也需要考量。
Bully算法<sup>[1]</sup>是最常見的選舉算法,其要求每個節點對應一個序號,序號最高的節點爲leader。leader宕機後次高序號的節點被重選爲leader,過程如下:

(a). 節點4發現leader不可達,向序號比自己高的節點發起重新選舉,重新選舉消息中帶上自己的序號
(b)(c). 節點5、6接收到重選信息後進行序號比較,發現自身的序號更大,向節點4返回OK消息並各自向更高序號節點發起重新選舉
(d). 節點5收到節點6的OK消息,而節點6經過超時時間後收不到更高序號節點的OK消息,則認爲自己是leader
(e). 節點6把自己成爲leader的信息廣播到所有節點
回顧《分佈式系統理論基礎 - 一致性、2PC和3PC》就可以看到,Bully算法中有2PC的身影,都具有提議(propose)和收集反饋(vote)的過程。
在一致性算法Paxos、ZAB<sup>[2]</sup>、Raft<sup>[3]</sup>中,爲提升決議效率均有節點充當leader的角色。ZAB、Raft中描述了具體的leader選舉實現,與Bully算法類似ZAB中使用zxid標識節點,具有最大zxid的節點表示其所具備的事務(transaction)最新、被選爲leader。
多數派(quorum)
在網絡分化的場景下以上Bully算法會遇到一個問題,被分隔的節點都認爲自己具有最大的序號、將產生多個leader,這時候就需要引入多數派(quorum)<sup>[4]</sup>。多數派的思路在分佈式系統中很常見,其確保網絡分化情況下決議唯一。
多數派的原理說起來很簡單,假如節點總數爲2f+1,則一項決議得到多於 f 節點贊成則獲得通過。leader選舉中,網絡分化場景下只有具備多數派節點的部分纔可能選出leader,這避免了多leader的產生。

多數派的思路還被應用於副本(replica)管理,根據業務實際讀寫比例調整寫副本數V<sub>w</sub>、讀副本數V<sub>r</sub>,用以在可靠性和性能方面取得平衡<sup>[5]</sup>。
租約(lease)
選舉中很重要的一個問題,以上尚未提到:怎麼判斷leader不可用、什麼時候應該發起重新選舉?最先可能想到會通過心跳(heart beat)判別leader狀態是否正常,但在網絡擁塞或瞬斷的情況下,這容易導致出現雙主。
租約(lease)是解決該問題的常用方法,其最初提出時用於解決分佈式緩存一致性問題<sup>[6]</sup>,後面在分佈式鎖<sup>[7]</sup>等很多方面都有應用。
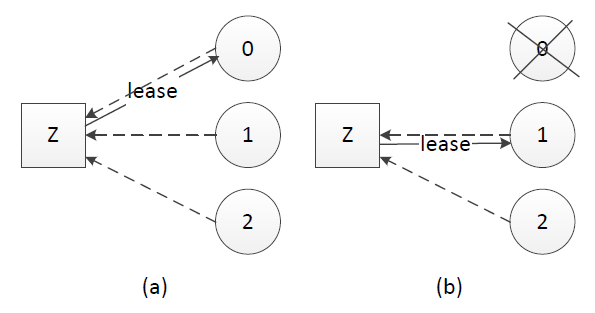
租約的原理同樣不復雜,中心思想是每次租約時長內只有一個節點獲得租約、到期後必須重新頒發租約。假設我們有租約頒發節點Z,節點0、1和2競選leader,租約過程如下:
(a). 節點0、1、2在Z上註冊自己,Z根據一定的規則(例如先到先得)頒發租約給節點,該租約同時對應一個有效時長;這裏假設節點0獲得租約、成爲leader
(b). leader宕機時,只有租約到期(timeout)後才重新發起選舉,這裏節點1獲得租約、成爲leader
租約機制確保了一個時刻最多隻有一個leader,避免只使用心跳機制產生雙主的問題。在實踐應用中,zookeeper、ectd可用於租約頒發。
小結
在分佈式系統理論和實踐中,常見leader、quorum和lease的身影。分佈式系統內不一定事事協商、事事民主,leader的存在有助於提升決議效率。
本文以leader選舉作爲例子引入和講述quorum、lease,當然quorum和lease是兩種思想,並不限於leader選舉應用。
最後提一個有趣的問題與大家思考,leader選舉的本質是一致性問題,Paxos、Raft和ZAB等解決一致性問題的協議和算法本身又需要或依賴於leader,怎麼理解這個看似“蛋生雞、雞生蛋”的問題?<sup>[8]</sup>
分佈式系統理論基礎 - 時間、時鐘和事件順序
十六號…… 四月十六號。一九六零年四月十六號下午三點之前的一分鐘你和我在一起,因爲你我會記住這一分鐘。從現在開始我們就是一分鐘的朋友,這是事實,你改變不了,因爲已經過去了。我明天會再來。
—— 《阿飛正傳》
現實生活中時間是很重要的概念,時間可以記錄事情發生的時刻、比較事情發生的先後順序。分佈式系統的一些場景也需要記錄和比較不同節點間事件發生的順序,但不同於日常生活使用物理時鐘記錄時間,分佈式系統使用邏輯時鐘記錄事件順序關係,下面我們來看分佈式系統中幾種常見的邏輯時鐘。
物理時鐘 vs 邏輯時鐘
可能有人會問,爲什麼分佈式系統不使用物理時鐘(physical clock)記錄事件?每個事件對應打上一個時間戳,當需要比較順序的時候比較相應時間戳就好了。
這是因爲現實生活中物理時間有統一的標準,而分佈式系統中每個節點記錄的時間並不一樣,即使設置了 NTP 時間同步節點間也存在毫秒級別的偏差<sup>[1][2]</sup>。因而分佈式系統需要有另外的方法記錄事件順序關係,這就是邏輯時鐘(logical clock)。

Lamport timestamps
Leslie Lamport 在1978年提出邏輯時鐘的概念,並描述了一種邏輯時鐘的表示方法,這個方法被稱爲Lamport時間戳(Lamport timestamps)<sup>[3]</sup>。
分佈式系統中按是否存在節點交互可分爲三類事件,一類發生於節點內部,二是發送事件,三是接收事件。Lamport時間戳原理如下:
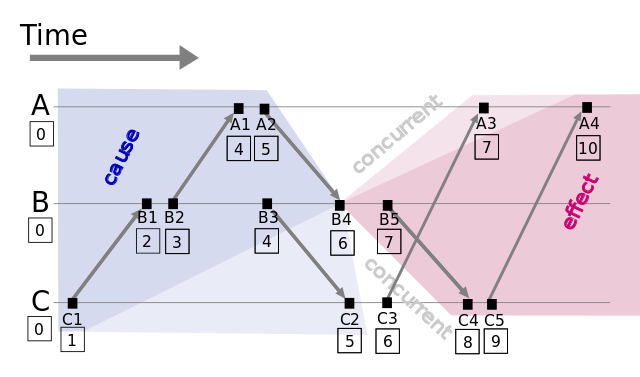
圖1: Lamport timestamps space time (圖片來源: wikipedia)
- 每個事件對應一個Lamport時間戳,初始值爲0
- 如果事件在節點內發生,時間戳加1
- 如果事件屬於發送事件,時間戳加1並在消息中帶上該時間戳
- 如果事件屬於接收事件,時間戳 = Max(本地時間戳,消息中的時間戳) + 1
假設有事件a、b,C(a)、C(b)分別表示事件a、b對應的Lamport時間戳,如果C(a) < C(b),則有a發生在b之前(happened before),記作 a -> b,例如圖1中有 C1 -> B1。通過該定義,事件集中Lamport時間戳不等的事件可進行比較,我們獲得事件的偏序關係(partial order)。
如果C(a) = C(b),那a、b事件的順序又是怎樣的?假設a、b分別在節點P、Q上發生,P<sub>i、</sub>Q<sub>j</sub>分別表示我們給P、Q的編號,如果 C(a) = C(b) 並且 P<sub>i </sub><Q<sub>j</sub>,同樣定義爲a發生在b之前,記作 a => b。假如我們對圖1的A、B、C分別編號A<sub>i</sub> = 1、B<sub>j</sub> = 2、C<sub>k</sub> = 3,因 C(B4) = C(C3) 並且 B<sub>j</sub> < C<sub>k</sub>,則 B4 => C3。
通過以上定義,我們可以對所有事件排序、獲得事件的全序關係(total order)。上圖例子,我們可以從C1到A4進行排序。
Vector clock
Lamport時間戳幫助我們得到事件順序關係,但還有一種順序關係不能用Lamport時間戳很好地表示出來,那就是同時發生關係(concurrent)<sup>[4]</sup>。例如圖1中事件B4和事件C3沒有因果關係,屬於同時發生事件,但Lamport時間戳定義兩者有先後順序。
Vector clock是在Lamport時間戳基礎上演進的另一種邏輯時鐘方法,它通過vector結構不但記錄本節點的Lamport時間戳,同時也記錄了其他節點的Lamport時間戳<sup>[5][6]</sup>。Vector clock的原理與Lamport時間戳類似,使用圖例如下:
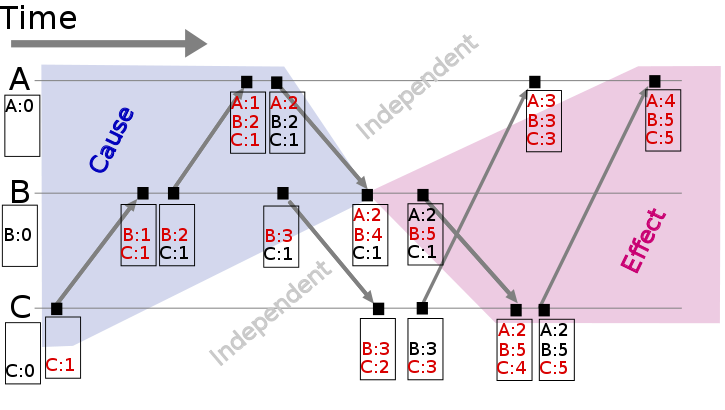
_圖2: Vector clock space time (_圖片來源: wikipedia)__
假設有事件a、b分別在節點P、Q上發生,Vector clock分別爲T<sub>a</sub>、T<sub>b</sub>,如果 T<sub>b</sub>[Q] > T<sub>a</sub>[Q] 並且 T<sub>b</sub>[P] >= T<sub>a</sub>[P],則a發生於b之前,記作 a -> b。到目前爲止還和Lamport時間戳差別不大,那Vector clock怎麼判別同時發生關係呢?
如果 T<sub>b</sub>[Q] > T<sub>a</sub>[Q] 並且 T<sub>b</sub>[P] < T<sub>a</sub>[P],則認爲a、b同時發生,記作 a <-> b。例如圖2中節點B上的第4個事件 (A:2,B:4,C:1) 與節點C上的第2個事件 (B:3,C:2) 沒有因果關係、屬於同時發生事件。
Version vector
基於Vector clock我們可以獲得任意兩個事件的順序關係,結果或爲先後順序或爲同時發生,識別事件順序在工程實踐中有很重要的引申應用,最常見的應用是發現數據衝突(detect conflict)。
分佈式系統中數據一般存在多個副本(replication),多個副本可能被同時更新,這會引起副本間數據不一致<sup>[7]</sup>,Version vector的實現與Vector clock非常類似<sup>[8]</sup>,目的用於發現數據衝突<sup>[9]</sup>。下面通過一個例子說明Version vector的用法<sup>[10]</sup>:
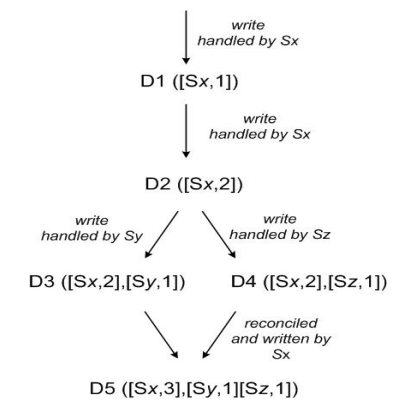
圖3: Version vector
- client端寫入數據,該請求被S<sub>x</sub>處理並創建相應的vector ([S<sub>x</sub>, 1]),記爲數據D1
- 第2次請求也被S<sub>x</sub>處理,數據修改爲D2,vector修改爲([S<sub>x</sub>, 2])
- 第3、第4次請求分別被S<sub>y</sub>、S<sub>z</sub>處理,client端先讀取到D2,然後D3、D4被寫入S<sub>y</sub>、S<sub>z</sub>
- 第5次更新時client端讀取到D2、D3和D4 3個數據版本,通過類似Vector clock判斷同時發生關係的方法可判斷D3、D4存在數據衝突,最終通過一定方法解決數據衝突並寫入D5
Vector clock只用於發現數據衝突,不能解決數據衝突。如何解決數據衝突因場景而異,具體方法有以最後更新爲準(last write win),或將衝突的數據交給client由client端決定如何處理,或通過quorum決議事先避免數據衝突的情況發生<sup>[11]</sup>。
由於記錄了所有數據在所有節點上的邏輯時鐘信息,Vector clock和Version vector在實際應用中可能面臨的一個問題是vector過大,用於數據管理的元數據(meta data)甚至大於數據本身<sup>[12]</sup>。
解決該問題的方法是使用server id取代client id創建vector (因爲server的數量相對client穩定),或設定最大的size、如果超過該size值則淘汰最舊的vector信息<sup>[10][13]</sup>。
小結
以上介紹了分佈式系統裏邏輯時鐘的表示方法,通過Lamport timestamps可以建立事件的全序關係,通過Vector clock可以比較任意兩個事件的順序關係並且能表示無因果關係的事件,將Vector clock的方法用於發現數據版本衝突,於是有了Version vector。
分佈式系統理論基礎 - CAP
引言
CAP是分佈式系統、特別是分佈式存儲領域中被討論最多的理論,“什麼是CAP定理?”在Quora 分佈式系統分類下排名 FAQ 的 No.1。CAP在程序員中也有較廣的普及,它不僅僅是“C、A、P不能同時滿足,最多隻能3選2”,以下嘗試綜合各方觀點,從發展歷史、工程實踐等角度講述CAP理論。希望大家透過本文對CAP理論有更多地瞭解和認識。
CAP定理
CAP由Eric Brewer在2000年PODC會議上提出<sup>[1][2]</sup>,是Eric Brewer在Inktomi<sup>[3]</sup>期間研發搜索引擎、分佈式web緩存時得出的關於數據一致性(consistency)、服務可用性(availability)、分區容錯性(partition-tolerance)的猜想:
It is impossible for a web service to provide the three following guarantees : Consistency, Availability and Partition-tolerance.
該猜想在提出兩年後被證明成立<sup>[4]</sup>,成爲我們熟知的CAP定理:
- 數據一致性(consistency):如果系統對一個寫操作返回成功,那麼之後的讀請求都必須讀到這個新數據;如果返回失敗,那麼所有讀操作都不能讀到這個數據,對調用者而言數據具有強一致性(strong consistency) (又叫原子性 atomic、線性一致性 linearizable consistency)<sup>[5]</sup>
- 服務可用性(availability):所有讀寫請求在一定時間內得到響應,可終止、不會一直等待
- 分區容錯性(partition-tolerance):在網絡分區的情況下,被分隔的節點仍能正常對外服務
在某時刻如果滿足AP,分隔的節點同時對外服務但不能相互通信,將導致狀態不一致,即不能滿足C;如果滿足CP,網絡分區的情況下爲達成C,請求只能一直等待,即不滿足A;如果要滿足CA,在一定時間內要達到節點狀態一致,要求不能出現網絡分區,則不能滿足P。
C、A、P三者最多隻能滿足其中兩個,和FLP定理一樣,CAP定理也指示了一個不可達的結果(impossibility result)。

CAP的工程啓示
CAP理論提出7、8年後,NoSql圈將CAP理論當作對抗傳統關係型數據庫的依據、闡明自己放寬對數據一致性(consistency)要求的正確性<sup>[6]</sup>,隨後引起了大範圍關於CAP理論的討論。
CAP理論看似給我們出了一道3選2的選擇題,但在工程實踐中存在很多現實限制條件,需要我們做更多地考量與權衡,避免進入CAP認識誤區<sup>[7]</sup>。
1、關於 P 的理解
Partition字面意思是網絡分區,即因網絡因素將系統分隔爲多個單獨的部分,有人可能會說,網絡分區的情況發生概率非常小啊,是不是不用考慮P,保證CA就好<sup>[8]</sup>。要理解P,我們看回CAP證明<sup>[4]</sup>中P的定義:
In order to model partition tolerance, the network will be allowed to lose arbitrarily many messages sent from one node to another.
網絡分區的情況符合該定義,網絡丟包的情況也符合以上定義,另外節點宕機,其他節點發往宕機節點的包也將丟失,這種情況同樣符合定義。現實情況下我們面對的是一個不可靠的網絡、有一定概率宕機的設備,這兩個因素都會導致Partition,因而分佈式系統實現中 P 是一個必須項,而不是可選項<sup>[9][10]</sup>。
對於分佈式系統工程實踐,CAP理論更合適的描述是:在滿足分區容錯的前提下,沒有算法能同時滿足數據一致性和服務可用性<sup>[11]</sup>:
In a network subject to communication failures, it is impossible for any web service to implement an atomic read/write shared memory that guarantees a response to every request.
2、CA非0/1的選擇
P 是必選項,那3選2的選擇題不就變成數據一致性(consistency)、服務可用性(availability) 2選1?工程實踐中一致性有不同程度,可用性也有不同等級,在保證分區容錯性的前提下,放寬約束後可以兼顧一致性和可用性,兩者不是非此即彼<sup>[12]</sup>。

CAP定理證明中的一致性指強一致性,強一致性要求多節點組成的被調要能像單節點一樣運作、操作具備原子性,數據在時間、時序上都有要求。如果放寬這些要求,還有其他一致性類型:
- 序列一致性(sequential consistency)<sup>[13]</sup>:不要求時序一致,A操作先於B操作,在B操作後如果所有調用端讀操作得到A操作的結果,滿足序列一致性
- 最終一致性(eventual consistency)<sup>[14]</sup>:放寬對時間的要求,在被調完成操作響應後的某個時間點,被調多個節點的數據最終達成一致
可用性在CAP定理裏指所有讀寫操作必須要能終止,實際應用中從主調、被調兩個不同的視角,可用性具有不同的含義。當P(網絡分區)出現時,主調可以只支持讀操作,通過犧牲部分可用性達成數據一致。
工程實踐中,較常見的做法是通過異步拷貝副本(asynchronous replication)、quorum/NRW,實現在調用端看來數據強一致、被調端最終一致,在調用端看來服務可用、被調端允許部分節點不可用(或被網絡分隔)的效果<sup>[15]</sup>。
3、跳出CAP
CAP理論對實現分佈式系統具有指導意義,但CAP理論並沒有涵蓋分佈式工程實踐中的所有重要因素。
例如延時(latency),它是衡量系統可用性、與用戶體驗直接相關的一項重要指標<sup>[16]</sup>。CAP理論中的可用性要求操作能終止、不無休止地進行,除此之外,我們還關心到底需要多長時間能結束操作,這就是延時,它值得我們設計、實現分佈式系統時單列出來考慮。
延時與數據一致性也是一對“冤家”,如果要達到強一致性、多個副本數據一致,必然增加延時。加上延時的考量,我們得到一個CAP理論的修改版本PACELC<sup>[17]</sup>:如果出現P(網絡分區),如何在A(服務可用性)、C(數據一致性)之間選擇;否則,如何在L(延時)、C(數據一致性)之間選擇。
小結
以上介紹了CAP理論的源起和發展,介紹了CAP理論給分佈式系統工程實踐帶來的啓示。
CAP理論對分佈式系統實現有非常重大的影響,我們可以根據自身的業務特點,在數據一致性和服務可用性之間作出傾向性地選擇。通過放鬆約束條件,我們可以實現在不同時間點滿足CAP(此CAP非CAP定理中的CAP,如C替換爲最終一致性)<sup>[18][19][20]</sup>。
有非常非常多文章討論和研究CAP理論,希望這篇對你認識和了解CAP理論有幫助。
分佈式系統理論進階 - Paxos
引言
《分佈式系統理論基礎 - 一致性、2PC和3PC》一文介紹了一致性、達成一致性需要面臨的各種問題以及2PC、3PC模型,Paxos協議在節點宕機恢復、消息無序或丟失、網絡分化的場景下能保證決議的一致性,是被討論最廣泛的一致性協議。
Paxos協議同時又以其“艱深晦澀”著稱,下面結合 Paxos Made Simple、The Part-Time Parliament 兩篇論文,嘗試通過Paxos推演、學習和了解Paxos協議。
Basic Paxos
何爲一致性問題?簡單而言,一致性問題是在節點宕機、消息無序等場景可能出現的情況下,相互獨立的節點之間如何達成決議的問題,作爲解決一致性問題的協議,Paxos的核心是節點間如何確定並只確定一個值(value)。
也許你會疑惑只確定一個值能起什麼作用,在Paxos協議裏確定並只確定一個值是確定多值的基礎,如何確定多值將在第二部分Multi Paxos中介紹,這部分我們聚焦在“Paxos如何確定並只確定一個值”這一問題上。

和2PC類似,Paxos先把節點分成兩類,發起提議(proposal)的一方爲proposer,參與決議的一方爲acceptor。假如只有一個proposer發起提議,並且節點不宕機、消息不丟包,那麼acceptor做到以下這點就可以確定一個值:
<pre>P1. 一個acceptor接受它收到的第一項提議</pre>
當然上面要求的前提條件有些嚴苛,節點不能宕機、消息不能丟包,還只能由一個proposer發起提議。我們嘗試放寬條件,假設多個proposer可以同時發起提議,又怎樣才能做到確定並只確定一個值呢?
首先proposer和acceptor需要滿足以下兩個條件:
1. proposer發起的每項提議分別用一個ID標識,提議的組成因此變爲(ID, value)
2. acceptor可以接受(accept)不止一項提議,當多數(quorum) acceptor接受一項提議時該提議被確定(chosen)
(注: 注意以上“接受”和“確定”的區別)
我們約定後面發起的提議的ID比前面提議的ID大,並假設可以有多項提議被確定,爲做到確定並只確定一個值acceptor要做到以下這點:
<pre>P2. 如果一項值爲v的提議被確定,那麼後續只確定值爲v的提議</pre>
(注: 乍看這個條件不太好理解,謹記目標是“確定並只確定一個值”)
由於一項提議被確定(chosen)前必須先被多數派acceptor接受(accepted),爲實現P2,實質上acceptor需要做到:
<pre>P2a. 如果一項值爲v的提議被確定,那麼acceptor後續只接受值爲v的提議</pre>
滿足P2a則P2成立 (P2a => P2)。
目前在多個proposer可以同時發起提議的情況下,滿足P1、P2a即能做到確定並只確定一個值。如果再加上節點宕機恢復、消息丟包的考量呢?
假設acceptor c 宕機一段時間後恢復,c 宕機期間其他acceptor已經確定了一項值爲v的決議但c 因爲宕機並不知曉;c 恢復後如果有proposer馬上發起一項值不是v的提議,由於條件P1,c 會接受該提議,這與P2a矛盾。爲了避免這樣的情況出現,進一步地我們對proposer作約束:
<pre>P2b. 如果一項值爲v的提議被確定,那麼proposer後續只發起值爲v的提議</pre>
滿足P2b則P2a成立 (P2b => P2a => P2)。
P2b約束的是提議被確定(chosen)後proposer的行爲,我們更關心提議被確定前proposer應該怎麼做:
<pre>P2c. 對於提議(n,v),acceptor的多數派S中,如果存在acceptor最近一次(即ID值最大)接受的提議的值爲v',那麼要求v = v';否則v可爲任意值</pre>
滿足P2c則P2b成立 (P2c => P2b => P2a => P2)。
條件P2c是Basic Paxos的核心,光看P2c的描述可能會覺得一頭霧水,我們通過 The Part-Time Parliament 中的例子加深理解:
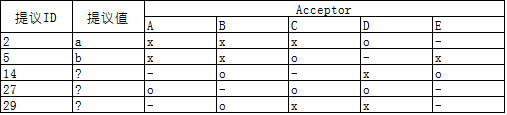
假設有A~E 5個acceptor,- 表示acceptor因宕機等原因缺席當次決議,x 表示acceptor不接受提議,o 表示接受提議;多數派acceptor接受提議後提議被確定,以上表格對應的決議過程如下:
- ID爲2的提議最早提出,根據P2c其提議值可爲任意值,這裏假設爲a
- acceptor A/B/C/E 在之前的決議中沒有接受(accept)任何提議,因而ID爲5的提議的值也可以爲任意值,這裏假設爲b
- acceptor B/D/E,其中D曾接受ID爲2的提議,根據P2c,該輪ID爲14的提議的值必須與ID爲2的提議的值相同,爲a
- acceptor A/C/D,其中D曾接受ID爲2的提議、C曾接受ID爲5的提議,相比之下ID 5較ID 2大,根據P2c,該輪ID爲27的提議的值必須與ID爲5的提議的值相同,爲b;該輪決議被多數派acceptor接受,因此該輪決議得以確定
- acceptor B/C/D,3個acceptor之前都接受過提議,相比之下C、D曾接受的ID 27的ID號最大,該輪ID爲29的提議的值必須與ID爲27的提議的值相同,爲b
以上提到的各項約束條件可以歸納爲3點,如果proposer/acceptor滿足下面3點,那麼在少數節點宕機、網絡分化隔離的情況下,在“確定並只確定一個值”這件事情上可以保證一致性(consistency):
- B1(ß): ß中每一輪決議都有唯一的ID標識
- B2(ß): 如果決議B被acceptor多數派接受,則確定決議B
- B3(ß): 對於ß中的任意提議B(n,v),acceptor的多數派中如果存在acceptor最近一次(即ID值最大)接受的提議的值爲v',那麼要求v = v';否則v可爲任意值
(注: 希臘字母ß表示多輪決議的集合,字母B表示一輪決議)
另外爲保證P2c,我們對acceptor作兩個要求:
1. 記錄曾接受的ID最大的提議,因proposer需要問詢該信息以決定提議值
2. 在迴應提議ID爲n的proposer自己曾接受過ID最大的提議時,acceptor同時保證(promise)不再接受ID小於n的提議
至此,proposer/acceptor完成一輪決議可歸納爲prepare和accept兩個階段。prepare階段proposer發起提議問詢提議值、acceptor迴應問詢並進行promise;accept階段完成決議,圖示如下:
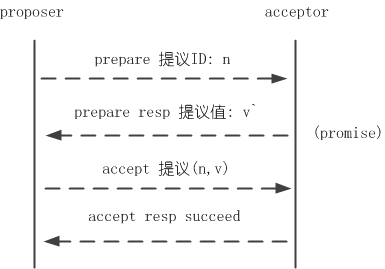
還有一個問題需要考量,假如proposer A發起ID爲n的提議,在提議未完成前proposer B又發起ID爲n+1的提議,在n+1提議未完成前proposer C又發起ID爲n+2的提議…… 如此acceptor不能完成決議、形成活鎖(livelock),雖然這不影響一致性,但我們一般不想讓這樣的情況發生。解決的方法是從proposer中選出一個leader,提議統一由leader發起。
最後我們再引入一個新的角色:learner,learner依附於acceptor,用於習得已確定的決議。以上決議過程都只要求acceptor多數派參與,而我們希望儘量所有acceptor的狀態一致。如果部分acceptor因宕機等原因未知曉已確定決議,宕機恢復後可經本機learner採用pull的方式從其他acceptor習得。
Multi Paxos
通過以上步驟分佈式系統已經能確定一個值,“只確定一個值有什麼用?這可解決不了我面臨的問題。” 你心中可能有這樣的疑問。

其實不斷地進行“確定一個值”的過程、再爲每個過程編上序號,就能得到具有全序關係(total order)的系列值,進而能應用在數據庫副本存儲等很多場景。我們把單次“確定一個值”的過程稱爲實例(instance),它由proposer/acceptor/learner組成,下圖說明了A/B/C三機上的實例:
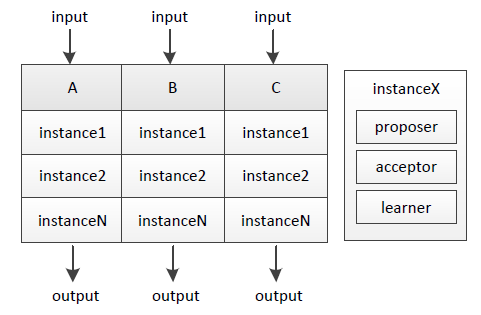
不同序號的實例之間互相不影響,A/B/C三機輸入相同、過程實質等同於執行相同序列的狀態機(state machine)指令 ,因而將得到一致的結果。
proposer leader在Multi Paxos中還有助於提升性能,常態下統一由leader發起提議,可節省prepare步驟(leader不用問詢acceptor曾接受過的ID最大的提議、只有leader提議也不需要acceptor進行promise)直至發生leader宕機、重新選主。
小結
以上介紹了Paxos的推演過程、如何在Basic Paxos的基礎上通過狀態機構建Multi Paxos。Paxos協議比較“艱深晦澀”,但多讀幾遍論文一般能理解其內涵,更難的是如何將Paxos真正應用到工程實踐。
微信後臺開發同學實現並開源了一套基於Paxos協議的多機狀態拷貝類庫PhxPaxos,PhxPaxos用於將單機服務擴展到多機,其經過線上系統驗證並在一致性保證、性能等方面作了很多考量。
分佈式系統理論進階 - Raft、Zab
引言
《分佈式系統理論進階 - Paxos》介紹了一致性協議Paxos,今天我們來學習另外兩個常見的一致性協議——Raft和Zab。通過與Paxos對比,瞭解Raft和Zab的核心思想、加深對一致性協議的認識。
Raft
Paxos偏向於理論、對如何應用到工程實踐提及較少。理解的難度加上現實的骨感,在生產環境中基於Paxos實現一個正確的分佈式系統非常難<sup>[1]</sup>:
There are significant gaps between the description of the Paxos algorithm and the needs of a real-world system. In order to build a real-world system, an expert needs to use numerous ideas scattered in the literature and make several relatively small protocol extensions. The cumulative effort will be substantial and the final system will be based on an unproven protocol.

Raft<sup>[2][3]</sup>在2013年提出,提出的時間雖然不長,但已經有很多系統基於Raft實現。相比Paxos,Raft的買點就是更利於理解、更易於實行。
爲達到更容易理解和實行的目的,Raft將問題分解和具體化:Leader統一處理變更操作請求,一致性協議的作用具化爲保證節點間操作日誌副本(log replication)一致,以term作爲邏輯時鐘(logical clock)保證時序,節點運行相同狀態機(state machine)<sup>[4]</sup>得到一致結果。Raft協議具體過程如下:
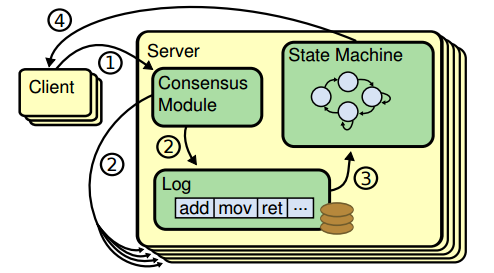
- Client發起請求,每一條請求包含操作指令
- 請求交由Leader處理,Leader將操作指令(entry)追加(append)至操作日誌,緊接着對Follower發起AppendEntries請求、嘗試讓操作日誌副本在Follower落地
- 如果Follower多數派(quorum)同意AppendEntries請求,Leader進行commit操作、把指令交由狀態機處理
- 狀態機處理完成後將結果返回給Client
指令通過log index(指令id)和term number保證時序,正常情況下Leader、Follower狀態機按相同順序執行指令,得出相同結果、狀態一致。
宕機、網絡分化等情況可引起Leader重新選舉(每次選舉產生新Leader的同時,產生新的term)、Leader/Follower間狀態不一致。Raft中Leader爲自己和所有Follower各維護一個nextIndex值,其表示Leader緊接下來要處理的指令id以及將要發給Follower的指令id,L<sub>nextIndex</sub>不等於F<sub>nextIndex</sub>時代表Leader操作日誌和Follower操作日誌存在不一致,這時將從Follower操作日誌中最初不一致的地方開始,由Leader操作日誌覆蓋Follower,直到L<sub>nextIndex、</sub>F<sub>nextIndex</sub>相等。
Paxos中Leader的存在是爲了提升決議效率,Leader的有無和數目並不影響決議一致性,Raft要求具備唯一Leader,並把一致性問題具體化爲保持日誌副本的一致性,以此實現相較Paxos而言更容易理解、更容易實現的目標。
Zab
Zab<sup>[5][6]</sup>的全稱是Zookeeper atomic broadcast protocol,是Zookeeper內部用到的一致性協議。相比Paxos,Zab最大的特點是保證強一致性(strong consistency,或叫線性一致性linearizable consistency)。
和Raft一樣,Zab要求唯一Leader參與決議,Zab可以分解成discovery、sync、broadcast三個階段:
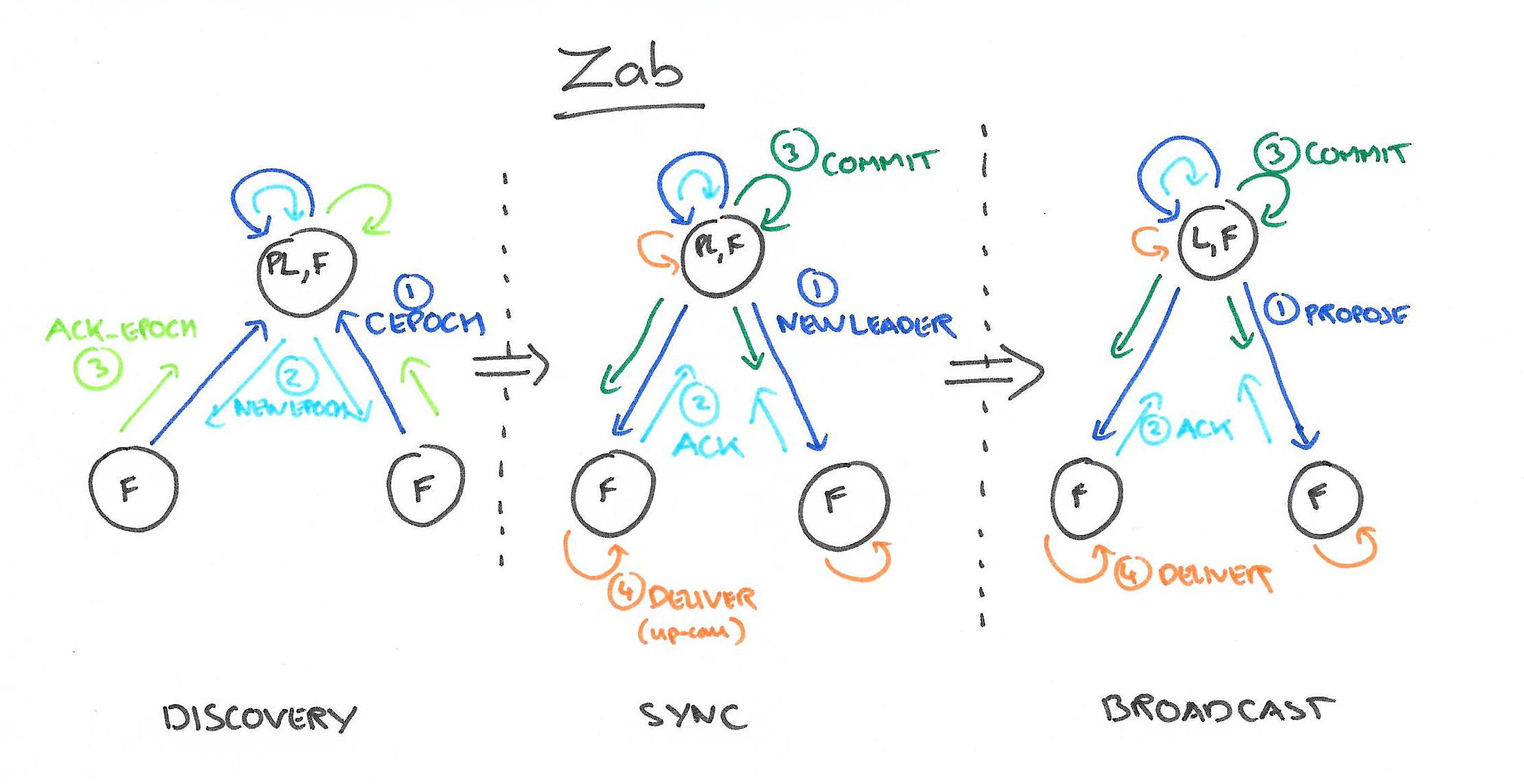
- discovery: 選舉產生PL(prospective leader),PL收集Follower epoch(cepoch),根據Follower的反饋PL產生newepoch(每次選舉產生新Leader的同時產生新epoch,類似Raft的term)
- sync: PL補齊相比Follower多數派缺失的狀態、之後各Follower再補齊相比PL缺失的狀態,PL和Follower完成狀態同步後PL變爲正式Leader(established leader)
- broadcast: Leader處理Client的寫操作,並將狀態變更廣播至Follower,Follower多數派通過之後Leader發起將狀態變更落地(deliver/commit)
Leader和Follower之間通過心跳判別健康狀態,正常情況下Zab處在broadcast階段,出現Leader宕機、網絡隔離等異常情況時Zab重新回到discovery階段。
瞭解完Zab的基本原理,我們再來看Zab怎樣保證強一致性,Zab通過約束事務先後順序達到強一致性,先廣播的事務先commit、FIFO,Zab稱之爲primary order(以下簡稱PO)。實現PO的核心是zxid。
Zab中每個事務對應一個zxid,它由兩部分組成:<e, c>,e即Leader選舉時生成的epoch,c表示當次epoch內事務的編號、依次遞增。假設有兩個事務的zxid分別是z、z',當滿足 z.e < z'.e 或者 z.e = z'.e && z.c < z'.c 時,定義z先於z'發生(z < z')。
爲實現PO,Zab對Follower、Leader有以下約束:
- 有事務z和z',如果Leader先廣播z,則Follower需保證先commit z對應的事務
- 有事務z和z',z由Leader p廣播,z'由Leader q廣播,Leader p先於Leader q,則Follower需保證先commit z對應的事務
- 有事務z和z',z由Leader p廣播,z'由Leader q廣播,Leader p先於Leader q,如果Follower已經commit z,則q需保證已commit z才能廣播z'
第1、2點保證事務FIFO,第3點保證Leader上具備所有已commit的事務。
相比Paxos,Zab約束了事務順序、適用於有強一致性需求的場景。
Paxos、Raft、Zab再比較
除Paxos、Raft和Zab外,Viewstamped Replication(簡稱VR)<sup>[7][8]</sup>也是討論比較多的一致性協議。這些協議包含很多共同的內容(Leader、quorum、state machine等),因而我們不禁要問:Paxos、Raft、Zab和VR等分佈式一致性協議區別到底在哪,還是根本就是一回事?<sup>[9]</sup>
Paxos、Raft、Zab和VR都是解決一致性問題的協議,Paxos協議原文傾向於理論,Raft、Zab、VR傾向於實踐,一致性保證程度等的不同也導致這些協議間存在差異。下圖幫助我們理解這些協議的相似點和區別<sup>[10]</sup>:
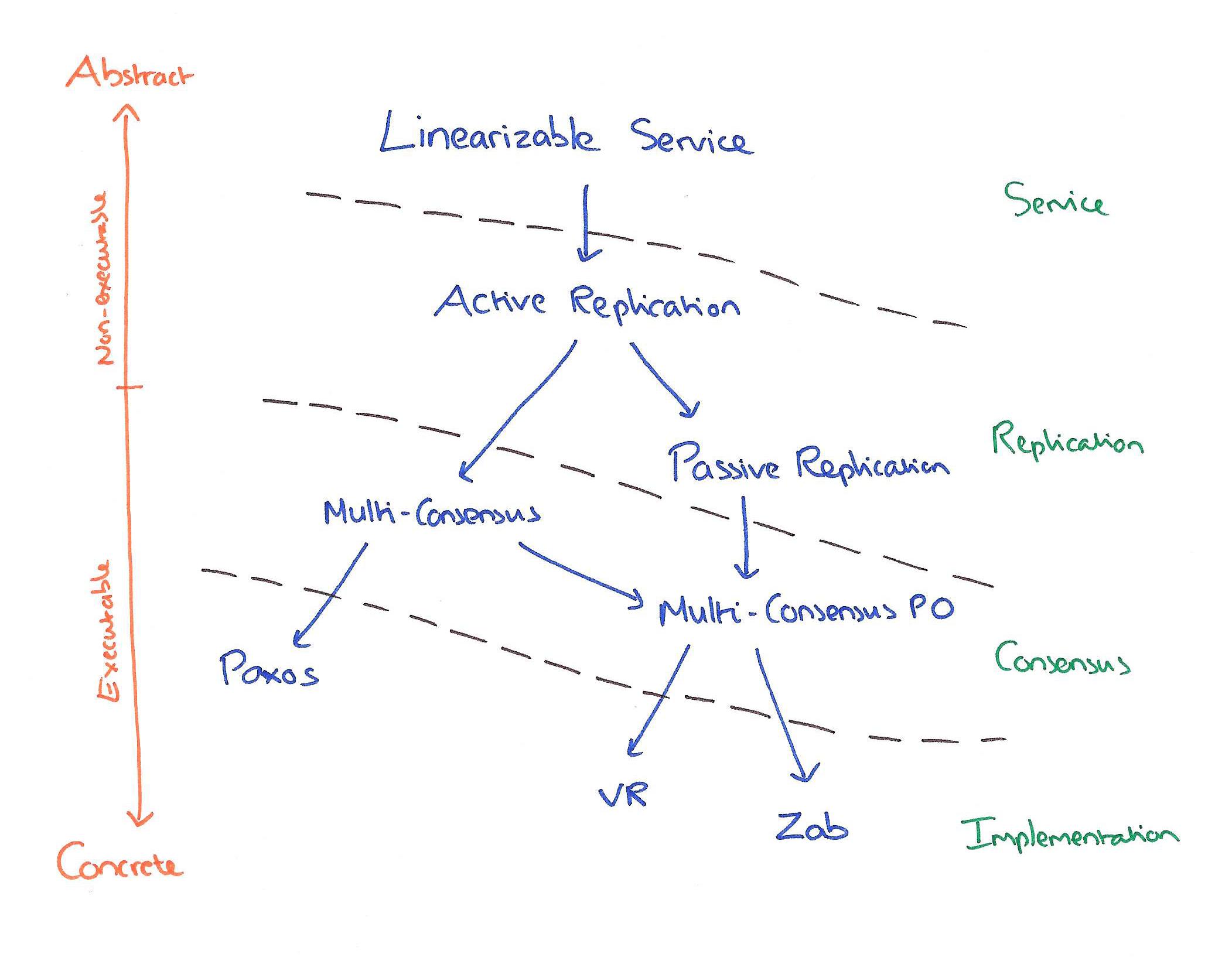
相比Raft、Zab、VR,Paxos更純粹、更接近一致性問題本源,儘管Paxos傾向理論,但不代表Paxos不能應用於工程。基於Paxos的工程實踐,須考慮具體需求場景(如一致性要達到什麼程度),再在Paxos原始語意上進行包裝。
小結
以上介紹分佈式一致性協議Raft、Zab的核心思想,分析Raft、Zab與Paxos的異同。實現分佈式系統時,先從具體需求和場景考慮,Raft、Zab、VR、Paxos等協議沒有絕對地好與不好,只是適不適合。
分佈式系統理論進階 - Paxos變種和優化
引言
《分佈式系統理論進階 - Paxos》中我們瞭解了Basic Paxos、Multi Paxos的基本原理,但如果想把Paxos應用於工程實踐,瞭解基本原理還不夠。
有很多基於Paxos的優化,在保證一致性協議正確(safety)的前提下,減少Paxos決議通信步驟、避免單點故障、實現節點負載均衡,從而降低時延、增加吞吐量、提升可用性,下面我們就來了解這些Paxos變種。

Multi Paxos
首先我們來回顧一下Multi Paxos,Multi Paxos在Basic Paxos的基礎上確定一系列值,其決議過程如下:

phase1a: leader提交提議給acceptor
phase1b: acceptor返回最近一次接受的提議(即曾接受的最大的提議ID和對應的value),未接受過提議則返回空
phase2a: leader收集acceptor的應答,分兩種情況處理
phase2a.1: 如果應答內容都爲空,則自由選擇一個提議value
phase2a.2: 如果應答內容不爲空,則選擇應答裏面ID最大的提議的value
phase2b: acceptor將決議同步給learner
Multi Paxos中leader用於避免活鎖,但leader的存在會帶來其他問題,一是如何選舉和保持唯一leader(雖然無leader或多leader不影響一致性,但影響決議進程progress),二是充當leader的節點會承擔更多壓力,如何均衡節點的負載。Mencius<sup>[1]</sup>提出節點輪流擔任leader,以達到均衡負載的目的;租約(lease)可以幫助實現唯一leader,但leader故障情況下可導致服務短期不可用。
Fast Paxos
在Multi Paxos中,proposer -> leader -> acceptor -> learner,從提議到完成決議共經過3次通信,能不能減少通信步驟?
對Multi Paxos phase2a,如果可以自由提議value,則可以讓proposer直接發起提議、leader退出通信過程,變爲proposer -> acceptor -> learner,這就是Fast Paxos<sup>[2]</sup>的由來。

Multi Paxos裏提議都由leader提出,因而不存在一次決議出現多個value,Fast Paxos裏由proposer直接提議,一次決議裏可能有多個proposer提議、出現多個value,即出現提議衝突(collision)。leader起到初始化決議進程(progress)和解決衝突的作用,當衝突發生時leader重新參與決議過程、回退到3次通信步驟。
Paxos自身隱含的一個特性也可以達到減少通信步驟的目標,如果acceptor上一次確定(chosen)的提議來自proposerA,則當次決議proposerA可以直接提議減少一次通信步驟。如果想實現這樣的效果,需要在proposer、acceptor記錄上一次決議確定(chosen)的歷史,用以在提議前知道哪個proposer的提議上一次被確定、當次決議能不能節省一次通信步驟。
EPaxos
除了從減少通信步驟的角度提高Paxos決議效率外,還有其他方面可以降低Paxos決議時延,比如Generalized Paxos<sup>[3]</sup>提出不衝突的提議(例如對不同key的寫請求)可以同時決議、以降低Paxos時延。
更進一步地,EPaxos<sup>[4]</sup>(Egalitarian Paxos)提出一種既支持不衝突提議同時提交降低時延、還均衡各節點負載、同時將通信步驟減少到最少的Paxos優化方法。
爲達到這些目標,EPaxos的實現有幾個要點。一是EPaxos中沒有全局的leader,而是每一次提議發起提議的proposer作爲當次提議的leader(command leader);二是不相互影響(interfere)的提議可以同時提交;三是跳過prepare,直接進入accept階段。EPaxos決議的過程如下:

左側展示了互不影響的兩個update請求的決議過程,右側展示了相互影響的兩個update請求的決議。Multi Paxos、Mencius、EPaxos時延和吞吐量對比:

爲判斷決議是否相互影響,實現EPaxos得記錄決議之間的依賴關係。
小結
以上介紹了幾個基於Paxos的變種,Mencius中節點輪流做leader、均衡節點負載,Fast Paxos減少一次通信步驟,Generalized Paxos允許互不影響的決議同時進行,EPaxos無全局leader、各節點平等分擔負載。
優化無止境,對Paxos也一樣,應用在不同場景和不同範圍的Paxos變種和優化將繼續不斷出現。