



想問一下關於scrapyd部署時候出現了這個問題是什麼原因,因爲本人的scrapy 是外部導包的現在把他改成了 scrapy文件但有一個文件我加進去不是框架裏面的文件。想問一下大佬怎麼解決
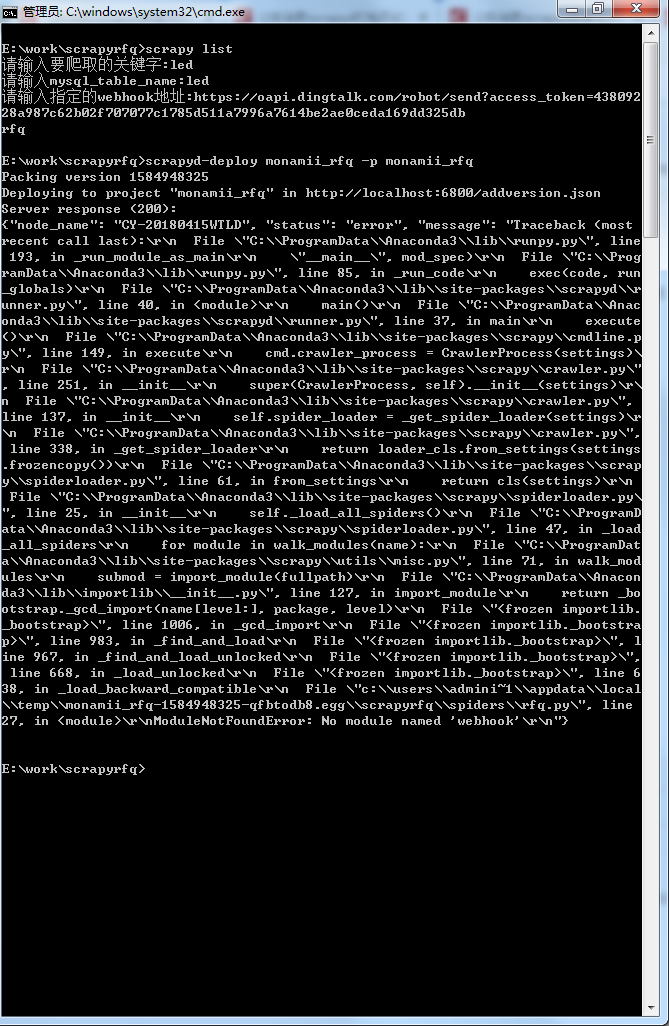

想問一下關於scrapyd部署時候出現了這個問題是什麼原因,因爲本人的scrapy 是外部導包的現在把他改成了 scrapy文件但有一個文件我加進去不是框架裏面的文件。想問一下大佬怎麼解決
一.利用pandas庫直接存儲爲Excel文件; 主要技術點: 1.首先建立列表,存儲每一次爬取的內容,爲後面的字典存儲做準備; 2.利用字典格式儲存數據; 3. 利用pandas中DataFram