




通用爬蟲和聚焦爬蟲
根據使用場景,網絡爬蟲可分爲 通用爬蟲 和 聚焦爬蟲 兩種.
通用網絡爬蟲 是 捜索引擎抓取系統(Baidu、Google、Yahoo等)的重要組成部分。主要目的
是將互聯網上的網 頁下載到本地,形成一個互聯網內容的鏡像備份。
通用網絡爬蟲 從互聯網中搜集網頁,採集信息,這些網頁信息用於爲搜索引擎建立索
引從而提供支持,它決定着 整個引擎系統的內容是否豐富,信息是否即時,因此其性
能的優劣直接影響着搜索引擎的效果
搜索引擎如何獲取一個新網站的URL:
- 新網站向搜索引擎主動提交網址:
- 在其他網站上設置新網站外鏈
- 和DNS解析服務商(如DNSPod等)合作,新網站域名將被迅速抓取。
爬蟲限制
搜索引擎蜘蛛的爬行是被輸入了一定的規則的,它需要遵從
一些命令或文件的內容。 - rel="nofollow",,告訴搜索引擎爬蟲無需抓
取目標頁,同時告訴搜索引擎無需將的當前頁的Pagerank
傳遞到目標頁. - Robots協議(也叫爬蟲協議、機器人協議等),
全稱是“網絡爬蟲排除標準”(Robots Exclusion
Protocol),網站通過Robots協議告訴搜索引擎哪些頁面可
以抓取,哪些頁面不能抓取。
侷限性
1.大多情況下,網頁裏90%的內容對用戶來說都是無用的。
- 搜索引擎無法提供針對具體某個用戶的搜索結果。
- 圖片、數據庫、音頻、視頻多媒體等不能很好地發現和獲取。
- 基於關鍵字的檢索,難以支持根據語義信息提出的查詢,無法準確理解用戶的具體需求
聚焦爬蟲
聚焦爬蟲,是"面向特定主題需求"的一種網絡爬蟲程序,它與通用搜索引擎爬蟲的區別在
於:聚焦爬蟲在實施網頁 抓取時會對內容進行處理篩選,儘量保證只抓取與需求相關的
網頁信息。
要學習的,就是聚焦爬蟲。
HTTP和HTTPS
• HTTP協議-80端口
HyperTextTransferProtocol ,
超文本傳輸協議是一種發佈和接收HTML頁面的方法。
• HTTPS-443端口
HypertextTransferProtocoloverSecureSocketLayer ,
簡單講是HTTP的安全版,在HTTP下加入SSL 層。
HTTP工作原理
網絡爬蟲抓取過程可以理解爲模擬瀏覽器操作的過程。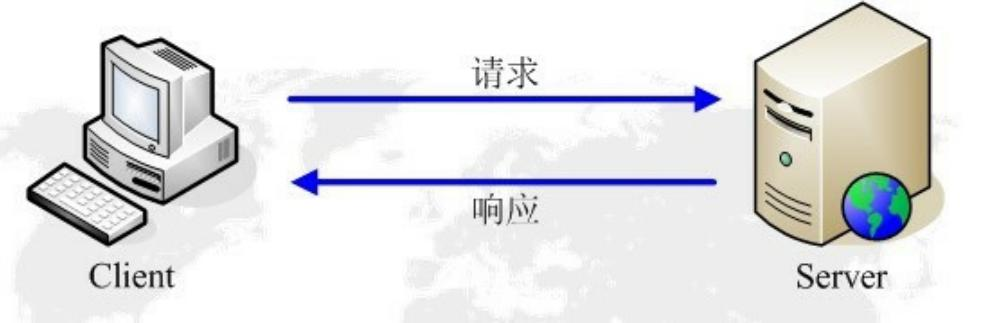
瀏覽器發送HTTP請求的過程
1.當用戶在瀏覽器的地址欄中輸入一個URL並按回車鍵之後,瀏覽器會向HTTP服務
器發送HTTP請求。HTTP請求主要分爲“Get”和“Post”兩種方法。
- 當我們在瀏覽器輸入URLhttp://www.baidu.com的時候,瀏覽器發送一個
Request請求去獲取http://www.baidu.com的html文件,服務器把Response文
件對象發送回給瀏覽器。
3.瀏覽器分析Response中的HTML,發現其中引用了很多其他文件,比如Images
文件,CSS文件,JS文件。瀏覽器會自動再次發送Request去獲取圖片,CSS文件,
或者JS文件。 - 當所有的文件都下載成功後,網頁會根據HTML語法結構,完整的顯示出來了。
URL
URL(Uniform/UniversalResourceLocator的縮寫):統一資源定位符,是用於完
整地描述Internet上網頁和其他資源的地址的一種標識方法。
基本格式: scheme://host[:port#]/path/.../[?query-string][#anchor]
• query-string:參數,發送給http服務器的數據
• anchor:錨(跳轉到網頁的指定錨點位置)
客戶端HTTP請求
客戶端發送一個HTTP請求到服務器的請求消息,包括以下格式:
請求方法Method
根據HTTP標準,HTTP請求可以使用多種請求方法.
HTTP0.9:只有基本的文本GET功能。
HTTP1.0:完善的請求/響應模型,並將協議補充完整,定義了三種請求方法:GET,POST和HEAD方法。
HTTP1.1:在1.0基礎上進行更新,新增了五種請求方法:OPTIONS,PUT,DELETE,TRACE和CONNECT方法。
Get 和 Post 詳解
- GET是從服務器上獲取數據,POST是向服務器傳送數據
- GET請求參數顯示,都顯示在瀏覽器網址上,即“Get”請求的參數是URL的一部分。
- POST請求參數在請求體當中,消息長度沒有限制而且以隱式的方式進行發送,通常用來向
HTTP服務器提交量比較大的數據(比如請求中包含許多參數或者文件上傳操作等),請求的參數
包含在“Content-Type”消息頭裏,指明該消息體的媒體類型和編碼,
常用的請求報頭
Host: 主機和端口號
Connection : 客戶端與服務連接類型, 默認爲keep-alive
User-Agent: 客戶瀏覽器的名稱
Accept: 瀏覽器或其他客戶端可以接受的MIME文件類型![python學習之爬蟲理論總結]()
常用的請求報頭
Referer:表明產生請求的網頁來自於哪個URL
Accept-Encoding:指出瀏覽器可以接受的編碼方式。
Accept-Language:語言種類
Accept-Charset: 字符編碼![python學習之爬蟲理論總結]()
常用的請求報頭
Cookie:瀏覽器用這個屬性向服務器發送Cookie
Content-Type:POST請求裏用來表示的內容類型。HTTP響應
HTTP響應由四個部分組成,分別是: 狀態行 、 消息報頭 、 空行 、 響應正文
![python學習之爬蟲理論總結]()
響應狀態碼
![python學習之爬蟲理論總結]()
200: 請求成功
302: 請求頁面臨時轉移至新url
307和304: 使用緩存資源
404: 服務器無法找到請求頁面
403: 服務器拒絕訪問,權限不夠
500: 服務器遇到不可預知的情況Cookie和Session
服務器和客戶端的交互僅限於請求/響應過程,結束之後便斷開,在下一次請求時,服
務器會認爲新的客戶端。爲了維護他們之間的鏈接,讓服務器知道這是前一個用戶發送
的請求,必須在一個地方保存客戶端的信息。
•
Cookie:通過在客戶端記錄的信
息確定用戶的身份。
•
Session:通過在服務器端記錄
的信息確定用戶的身份。圖片下載器
製作爬蟲的基本步驟
- 需求分析:
http://image.baidu.com/search/index?tn=baiduimage&word=cat - 分析網頁源代碼,配合F12
- 編寫正則表達式或者其他解析器代碼
- 存儲數據到本地
- 正式編寫python爬蟲代碼
"我想要圖片,我又不想上網搜“
"最好還能自動下載"
......
這就是需求,至少要實現兩個功能,一是搜索圖片,二是自動下載。




分析網頁

pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
編寫爬蟲代碼