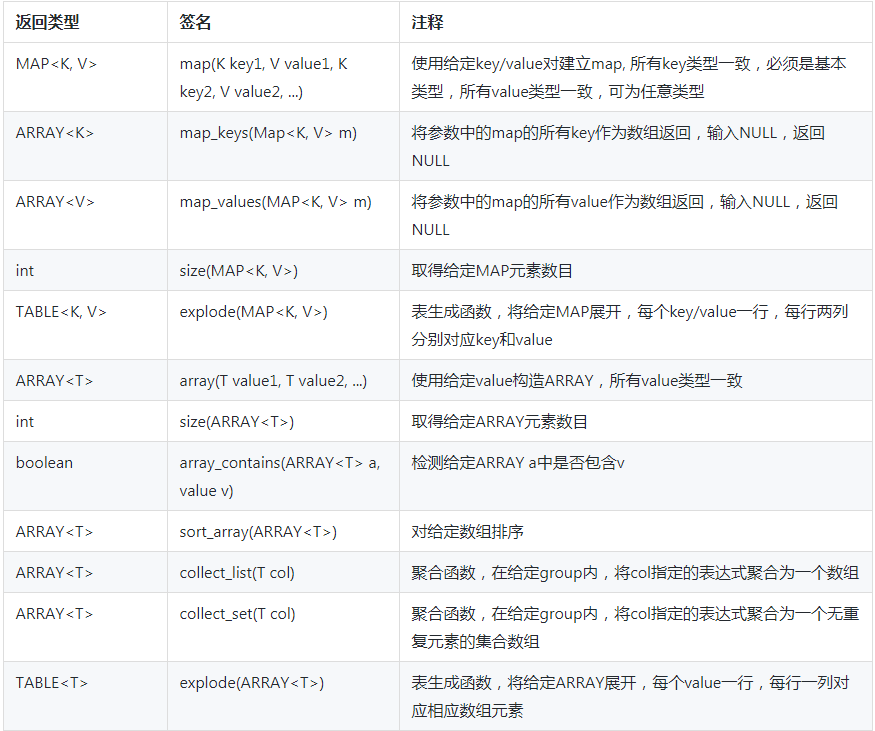
使用場景
場景一 (博主實際使用場景)
- 因爲公司近期涉及埋點數據的業務邏輯,對於擴展字進行補充因此採用map數據類型存儲擴展字段.
場景二 (其他業務場景)
-
場景2.1
我的項目裏,生成的一箇中間表,爲了優化性能,裏面有一列最好是個數組,因爲如果把數組打散,每行上存一個元素,會因爲其他列的重複導致數據量爆炸。首先想從上游表中生成這個數組,搜索半天文檔,發現唯一的方式是把源數據列先轉STRING,再用wm_concat聚合,再用split函數打散成ARRAY ,這樣原來類型信息丟了,不過STRING似乎也能用,好,繼續。後面的運算有個地方需要取數組最後一個元素,試圖用數組下標配合size函數,my_array[size(my_array)], 發現報告錯誤,下標必須是常量,可是我的數組不是定長的,看看有沒有函數能反轉數組呢?沒有!最後不得不放棄使用數組。。。 -
場景2.2
我的任務是爲每個廣告生成一個曲線,代表隨着廣告商的出價由低到高,預計的impression, click次數的曲線。最自然的表達是有個數據結構,裏面存着出價,impression次數,click次數。可是ODPS不支持這樣的用法,只好encode成一個字符串,每次操作先編碼,再解碼。好麻煩,效率也很差,可是沒有辦法。。。
工具
-
作者使用的阿里雲maxcompute工具,數據源在ES 使用阿里雲數據集成腳本方式實現數據同步.備註因爲數據源是String類型,阿里雲的同步工具不支持將string 轉爲 map 數據類型.因此在數據同步過程中也就是ods層採用String類型進行數據存儲,後續處理採用map數據類型. 使用Sqoop同步數據的話採用的方式作者一致
-
如果你採用dataX的支持在序列換過程中將String類型轉化爲Map數據類型
建議格式
-
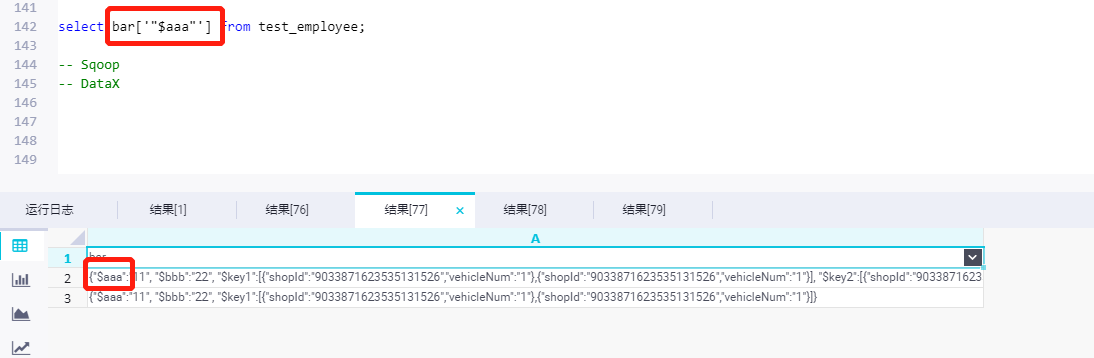
擴展字段必須用String 同步源數據格式爲 (KaTeX parse error: Expected 'EOF', got '#' at position 7: aaa:11#̲bbb:22#KaTeX parse error: Expected 'EOF', got '#' at position 13: key1:[{},{}]#̲key2:[{},{}])
- 1.1 $的含義是用來區分擴展字段 (提高易讀性)
- 1.2 # 用來切分文本數據
- 1.3 $key1":[{},{}] 這種複雜的數據格式 需要單獨處理
- 1.4 後續數據格式的處理使用map字段數據類型
樣例場景
- 建表語句
CREATE TABLE test_employee ( bar MAP<STRING,STRING>);
- 導入數據
數據一
insert into TABLE test_employee
select str_to_map('"$aaa":"11"#"$bbb":"22"#"$key1":[{"shopId":"9033871623535131526","vehicleNum":"1"},{"shopId":"9033871623535131526","vehicleNum":"1"}]#"$key2":[{"shopId":"9033871623535131526","vehicleNum":"2"},{"shopId":"9033871623535131526","vehicleNum":"2"}]',"#",":");
數據二
insert into TABLE test_employee
select str_to_map('$aaa:11#$bbb:22#$key1:[{"shopId":"9033871623535131526","vehicleNum":"1"},{"shopId":"9033871623535131526","vehicleNum":"1"}]',"#",":");
- 執行SQL (想知道結果的輸出一定要自己動手、做人不可以懶啊)
select aa.user_id,bb.col,rr.shopId,rr.vehicleNum
from
(SELECT user_id
--arg3
,split(regexp_replace(regexp_extract(
arg3,
'^\\[(.+)\\]$',1),
'\\}\\,\\{', '}||{'),'\\|\\|' -- odps 格式
) as arg3_str
-- '\\}\\,\\{', '}||{') 第三方雲格式
FROM prod_es_user_behavior_data_integration
WHERE dt = 20200412
and arg3 is not null
and user_id in ("677132")
) aa
-- 原因 1
-- 對於 [{},{},{}] 這種格式是無法直接進行解析 需要進行單獨處理
-- regexp_replace,regexp_extract 這兩種函數的使用要清楚
-- 上面的匹配原則可以通用、注意odps 與 第三方雲平臺的區別。
-- 不建議採用自定義函數處理上述結果、原因就是效率低
lateral view explode(aa.arg3_str) bb as col
-- 原因 2 實現行轉列
-- 使用json_tuple 對key 進行解析
lateral view json_tuple(bb.col,'shopId','vehicleNum') rr as shopId,vehicleNum
;
- size函數 用來查看key的個數,返回的是int類型
select size(bar) from test_employee;
- map_keys 函數 用來查看key 返回array類型
select map_keys(bar) from test_employee;
- map_values 函數 用來查看值 返回array類型
select map_values(bar) from test_employee;
- str__to_map(str_,Delimiter1,Delimiter2)
Delimiter1 切分文本(文本的含義代表字符串的值)
Delimiter2 切分KV
樣例1
select str_to_map('"aaa":"11"&"bbb":"22"', ':');
錯誤輸出 {"11"&"bbb":NULL, "22":NULL, "aaa":NULL}
樣例2
select str_to_map('"aaa":"11"&"bbb":"22"', '&',':');
正確輸出 {"aaa":"11", "bbb":"22"}
樣例3
select str_to_map('"aaa":"11","bbb":"22","key1":"[{},{},{}]"', ',',':'); -- {"aaa":"11", "bbb":"22", "key1":"[{}, {}:NULL, {}]":NULL}
錯誤輸出: 複雜的數據格式無法輸出
特殊場景用法
- 注意事項 1
- 注意事項 2
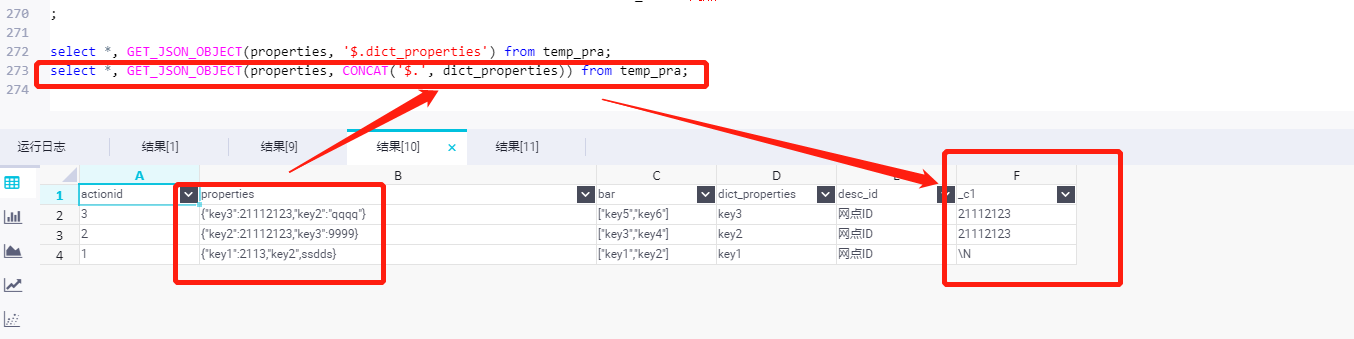
-
注意事項 3
- 採用 lateral view + json__tuple 對於key進行解析,備註json_object 與 json_tuple 的區別就是可以解析 可以解析多個字段還是解析一個字段。
- explode (array) 輸入是數組 輸出是行 一行轉多行

福利分享
- 複雜的數據類型可以進行嵌套 (擴展部分可以濾過)

- 低頻函數