




Spark小實例——求文件中的最大值和最小值(IDEA實現)
1、所需軟件
IDEA開發工具
HDFS分佈式文件系統(可選項)
spark-2.1.1-bin-hadoop2.7(版本可自選)
2、所需文件(自定義數據即可)
比如:
3、準備IDEA的環境
首先創建項目
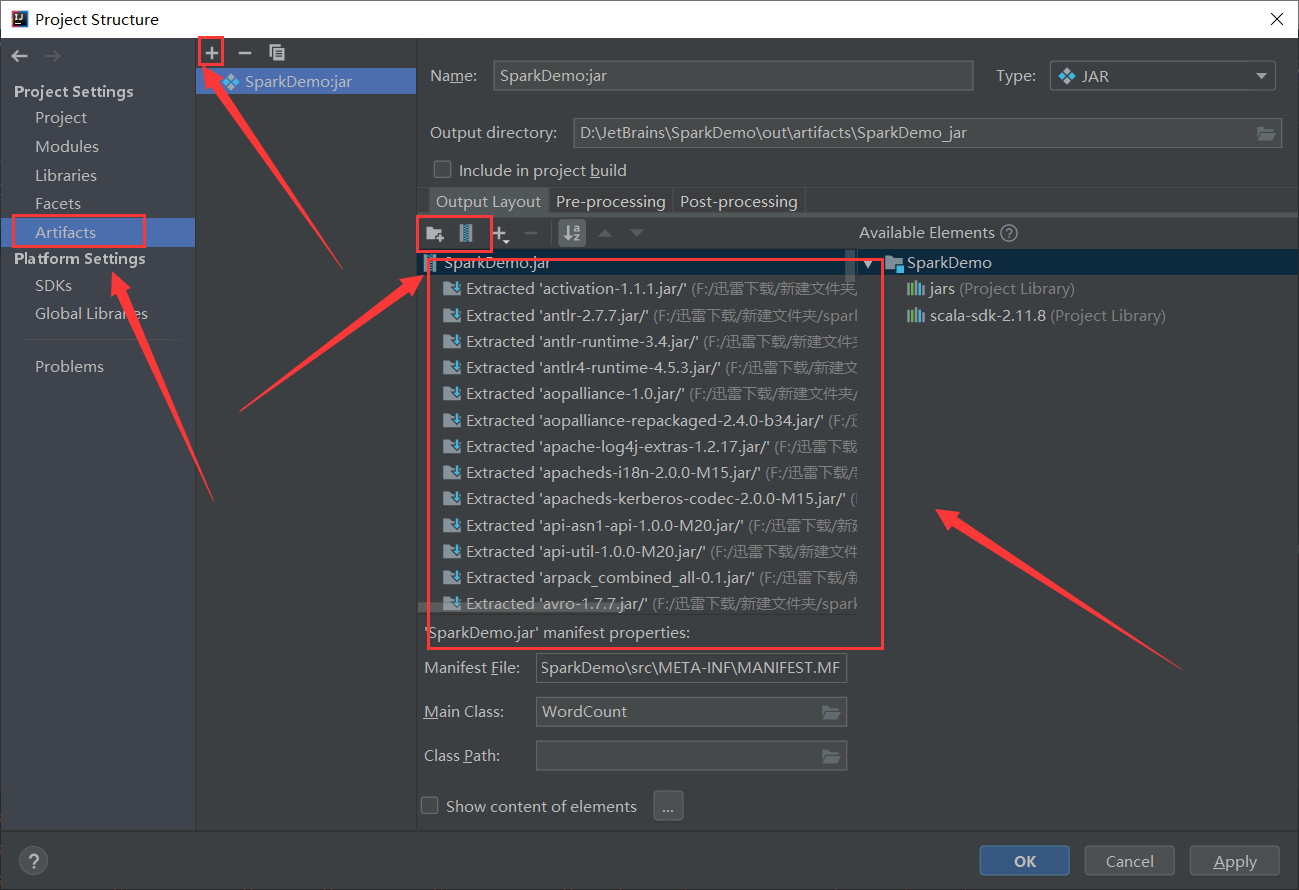
導入所需的JAR文件(spark-2.1.1-bin-hadoop2.7)

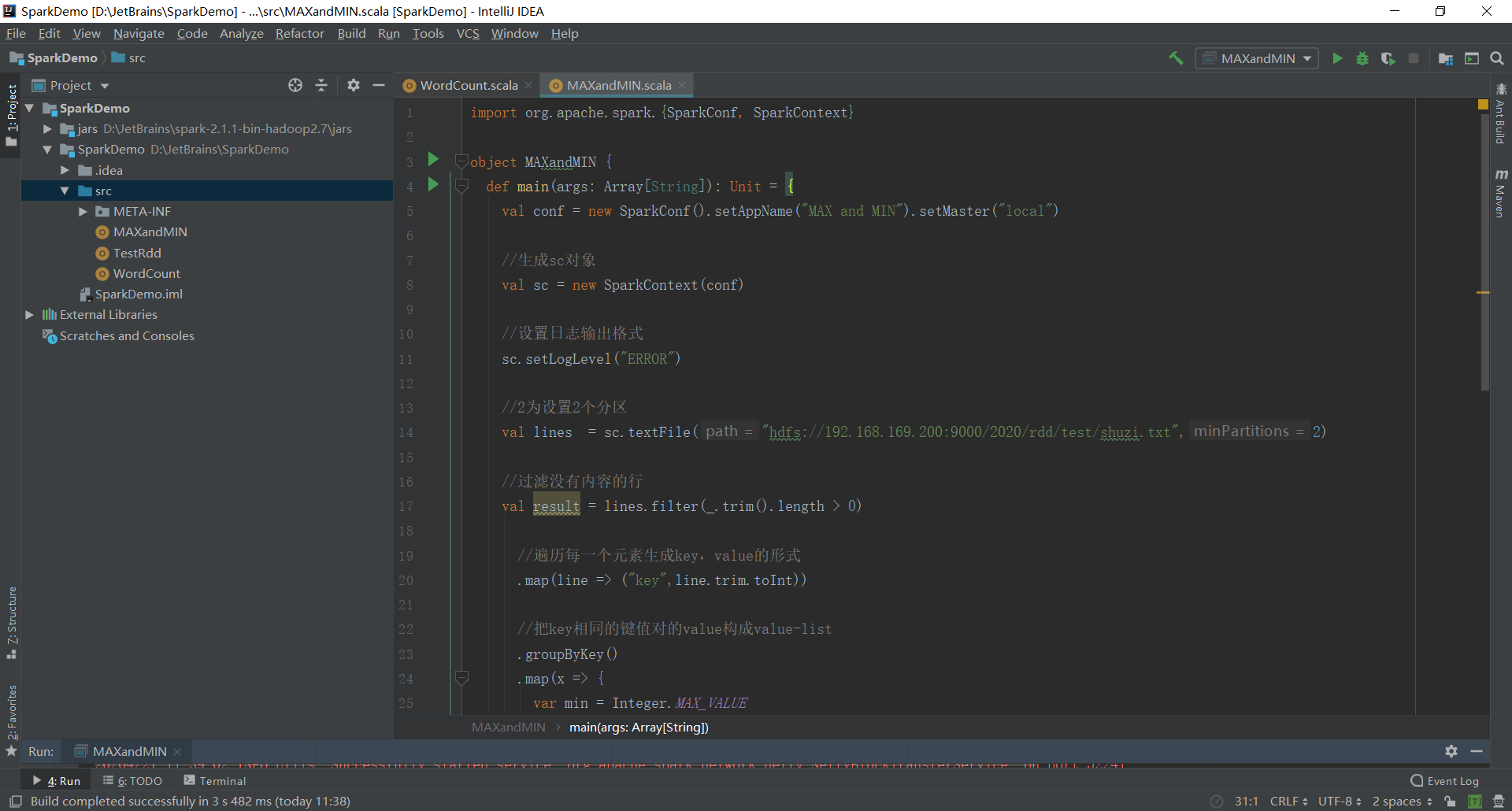
4、編寫Spark程序(創建scala文件)
代碼如下:
import org.apache.spark.{SparkConf, SparkContext}
object MAXandMIN {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("MAX and MIN").setMaster("local")
//生成sc對象
val sc = new SparkContext(conf)
//設置日誌輸出格式
sc.setLogLevel("ERROR")
//2爲設置2個分區
val lines = sc.textFile("hdfs://192.168.169.200:9000/2020/rdd/test/shuzi.txt",2)
//過濾沒有內容的行
val result = lines.filter(_.trim().length > 0)
//遍歷每一個元素生成key,value的形式
.map(line => ("key",line.trim.toInt))
//把key相同的鍵值對的value構成value-list
.groupByKey()
.map(x => {
var min = Integer.MAX_VALUE
var max = Integer.MIN_VALUE
for (num <- x._2) {
if (num > max) {
max = num
}
if (num < min) {
min = num
}
}
//封裝成元組
(max,min)
})
//收集遍歷
.collect.foreach(x => {
//打印結果
println("max:" + x._1)
println("min:" + x._2)
})
}
}
結果爲: