




大衆點評數據爬蟲獲取教程 --- 【SVG映射版本】
前言:
大衆點評是一款非常受大衆喜愛的一個第三方的美食相關的點評網站。從網站內可以推薦吃喝玩樂優惠信息,提供美食餐廳、酒店旅遊、電影票、家居裝修、美容美髮、運動健身等各類生活服務,通過海量真實消費評論的聚合,幫助大家選到服務滿意商家。
因此,該網站的數據也就非常有價值。優惠,評價數量,好評度等數據也就非常受數據公司的歡迎。
接上文,本篇是SVG映射版本
希望對看到這篇文章的朋友有所幫助。
- 環境和工具包:
- python 3.6
- 自建的IP池(代理)(使用的是ipidea的國內代理)
- parsel(頁面解析)
下面就讓我看開啓探索之旅
這次我們以“http://www.dianping.com/shop/16790071/review_all”爲例子。
既然讀者能看到這個,那麼就一定自己有過一定了解了。
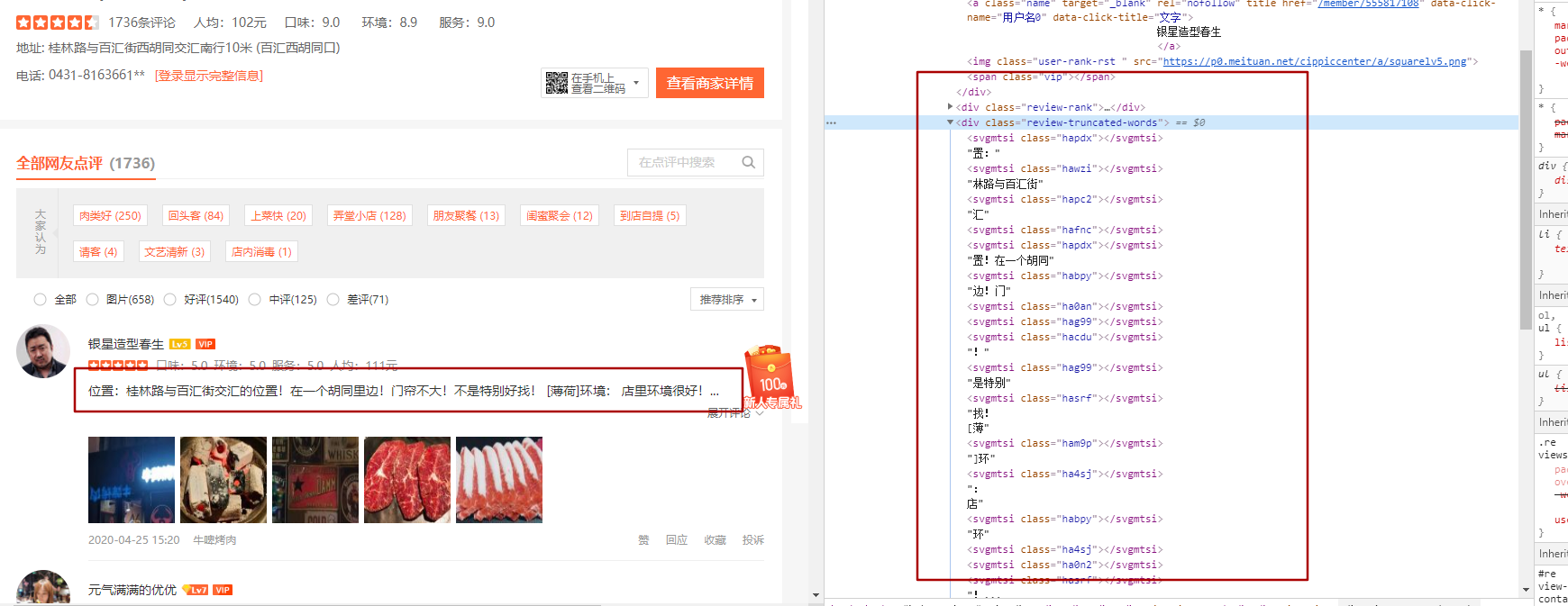
從圖中的紅框對比,可以看到左右內容的對比。可見並不是看到的結果就是頁面返回的結果。
<svgmtsi>標籤內容的class其實是對應的class文件裏的設置,通過下圖我們可以看到,對應的css個實例有個鏈接,這個鏈接就是指向對應svg映射的連接
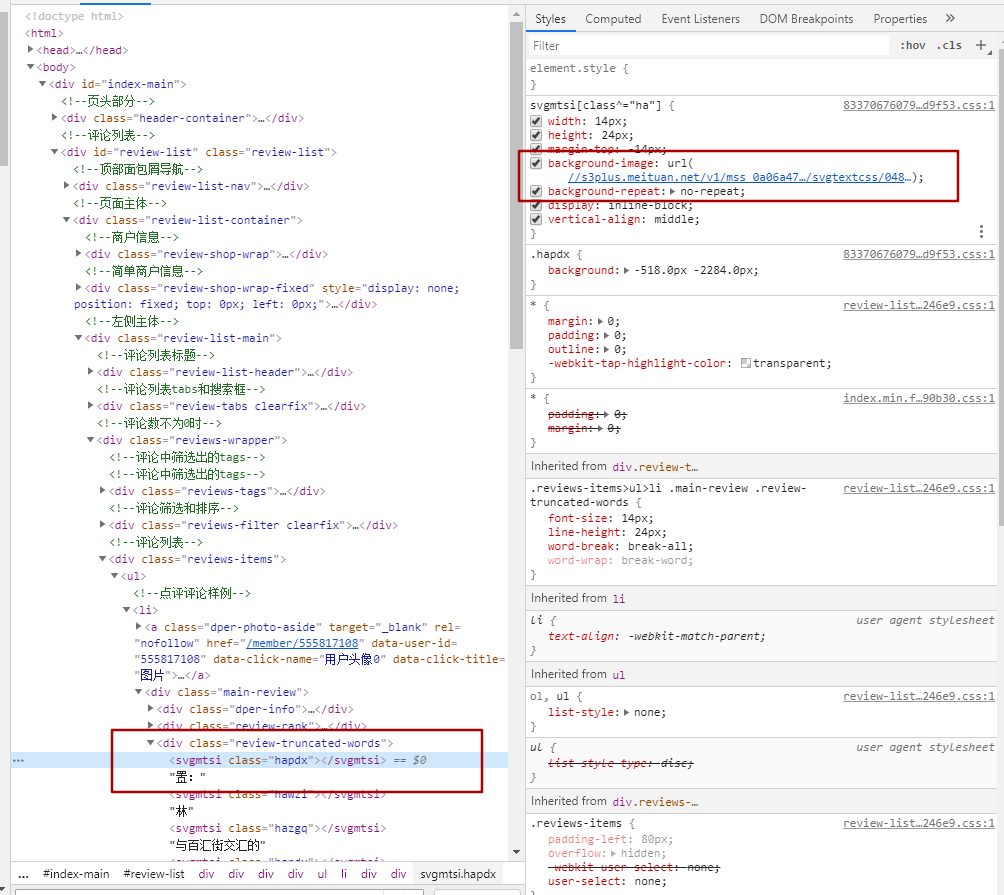

{kind=link}
打開這個鏈接後看到的是如下的內容:

請注意上面的對比圖,右側的洪寬下的。hapdx屬性,這個屬性就是對應知道svg文字位置的背景圖。可以自己動手修改參數值,相對應的位置就變了。
因此我們只需要做三步走。
一。找到對應頁面的css路徑,加載解析內容。處理。
二。替換頁面內容,將需要替換的文字從通過屬性,找到在css中對應的位置。
三。解析頁面,獲取對應的頁面的值。
代碼如下:
import re
import requests
def svg_parser(url):
r = requests.get(url, headers=headers)
font = re.findall('" y="(\d+)">(\w+)</text>', r.text, re.M)
if not font:
font = []
z = re.findall('" textLength.*?(\w+)</textPath>', r.text, re.M)
y = re.findall('id="\d+" d="\w+\s(\d+)\s\w+"', r.text, re.M)
for a, b in zip(y, z):
font.append((a, b))
width = re.findall("font-size:(\d+)px", r.text)[0]
new_font = []
for i in font:
new_font.append((int(i[0]), i[1]))
return new_font, int(width)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36",
"Cookie": "_lxsdk_cuid=171c55eb43ac8-07f006bde8dc41-5313f6f-1fa400-171c55eb43ac8; _lxsdk=171c55eb43ac8-07f006bde8dc41-5313f6f-1fa400-171c55eb43ac8; _hc.v=970ed851-cbab-8871-10cf-06251d4e64a0.1588154251; t_lxid=17186f9fa02c8-02b79fa94db2c8-5313f6f-1fa400-17186f9fa03c8-tid; _lxsdk_s=171c55ea204-971-8a9-eae%7C%7C368"}
r = requests.get("http://www.dianping.com/shop/73408241/review_all", headers=headers)
print(r.status_code)
# print(r.text)
css_url = "http:" + re.findall('href="(//s3plus.meituan.net.*?svgtextcss.*?.css)', r.text)[0]
print(css_url)
css_cont = requests.get(css_url, headers=headers)
print(css_cont.text)
svg_url = re.findall('class\^="(\w+)".*?(//s3plus.*?\.svg)', css_cont.text)
print(svg_url)
s_parser = []
for c, u in svg_url:
f, w = svg_parser("http:" + u)
s_parser.append({"code": c, "font": f, "fw": w})
print(s_parser)
css_list = re.findall('(\w+){background:.*?(\d+).*?px.*?(\d+).*?px;', '\n'.join(css_cont.text.split('}')))
css_list = [(i[0], int(i[1]), int(i[2])) for i in css_list]
def font_parser(ft):
for i in s_parser:
if i["code"] in ft[0]:
font = sorted(i["font"])
if ft[2] < int(font[0][0]):
x = int(ft[1] / i["fw"])
return font[0][1][x]
for j in range(len(font)):
if (j + 1) in range(len(font)):
if (ft[2] >= int(font[j][0]) and ft[2] < int(font[j + 1][0])):
x = int(ft[1] / i["fw"])
return font[j + 1][1][x]
replace_dic = []
for i in css_list:
replace_dic.append({"code": i[0], "word": font_parser(i)})
rep = r.text
# print(rep)
for i in range(len(replace_dic)):
# print(replace_dic[i]["code"])
try:
if replace_dic[i]["code"] in rep:
a = re.findall(f'<\w+\sclass="{replace_dic[i]["code"]}"><\/\w+>', rep)[0]
rep = rep.replace(a, replace_dic[i]["word"])
except Exception as e:
print(e)
# print(rep)
from parsel import Selector
response = Selector(text=rep)
li_list = response.xpath('//div[@class="reviews-items"]/ul/li')
for li in li_list:
infof = li.xpath('.//div[@class="review-truncated-words"]/text()').extract()
print(infof[0].strip().replace("\n",""))運行結果對比圖如下:
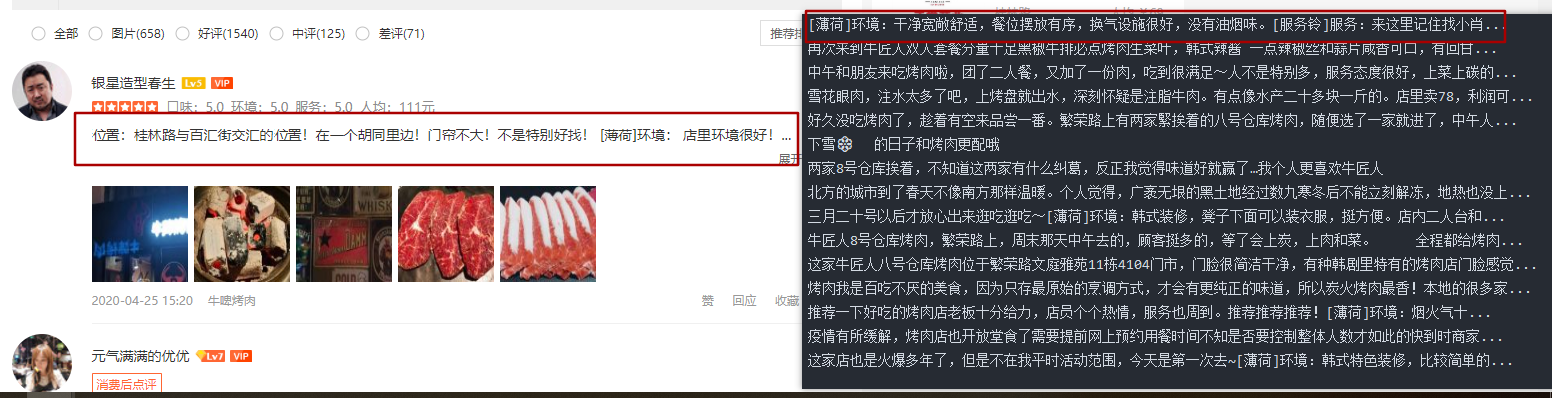
具體的流程就是代碼中顯示的,細節還需要完善,但內容相對應的都是可以展示出來了。
本次兩篇大衆點評的採集教程到這裏就結束了,詳細交流歡迎與我聯繫。
本文章旨在用於交流分享,【未經允許,謝絕轉載】