




數據準備
工具包導入及工作路徑設置:

數據導入:
爲了方便讀者實操,這裏附上原表:jingdian1.csv
增
增加列
增加列的方法有多種,這裏列舉兩種。
增加“評級”列,level大於等於90的設爲“高”,小於90設爲“低”:
上面的插入方法相當於先按給定條件創建了一個數組,再將數組插入到df1中作爲最後一列,利用insert方法可以指定插入位置,但列名不能使用中文:
增加行
增加行的方法也有多種,通常都是在表格最後一行後增加,如loc、append和row_stack方法。
loc:
PS:當此表格改變時,這裏自定義的索引會被重置,從下面的操作中就可以看出。
append:
需要合併數據表的可以這樣:
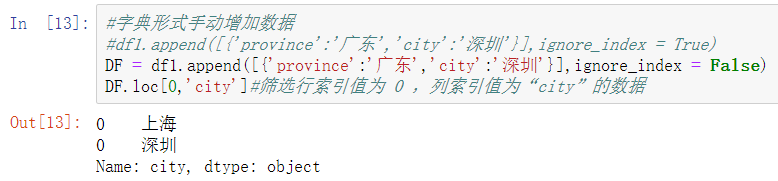
這裏的 ignore_index 默認值爲 False,此時插入的行默認索引將從0開始計算,此時若通過默認索引來篩選數據,則會出現同一索引條件可篩選出多個結果,類似下圖:(讀者可自行測試)
row_stack:(處理DataFrame不推薦使用,對應column_stack爲增加列)
row_stack方法輸出結果爲數組,需再將其轉換成DataFrame,並且列標籤也需重新定義。
刪
刪除行
刪除行通常使用drop方法,可以利用參數 inplace 自行選擇是否更改原數據,默認 inplace = False,即不更改原表。
也可以通過“inplace = True”改變原表:
除了根據默認索引刪除外,也可以指定行標籤進行刪除:
一次性刪除多行也可以使用迭代器(range):
刪除列
這裏展示3種刪除列的方法:
1)del方法:
2)pop方法:
pop方法能將所選列從原數據表中取出,並且原數據表將不在含有該列。
3)drop方法:
drop方法刪除列與刪除行都可以通過 inplace 參數設置是否更改原表,繼續使用上面更改後的表df1:
這裏的 axis = 1 表示對列進行操作。
改
修改表元素
這裏的修改是先選擇了特定的行列值,再重新賦值。
修改列標籤
修改行標籤
重置索引:
查
單條件查詢
查找評論數大於20000的景點:
可以使用 “~” 符號查找相反條件,即評論數小於等於20000:
多條件查詢
PS:單個條件需要用括號括起來,條件之間用 “&” 連接。
between方法:
這裏的“inclusive = True”表示區間包含500和1500,即取閉區間,對應“inclusive = False”表示取開區間
isin方法:
指定元素值查找可以使用 isin 方法,字符型數據需加引號。
附錄代碼
import pandas as pd
import numpy as np
import os
os.chdir('D:\practice')#設置當前工作路徑
df1 = pd.read_csv('jingdian1.csv',encoding = 'utf-8') #讀取數據
df1
*****增*****
#增加“評級”列
df1['評級'] = np.where(df1['level'] >= 90,'高','低')
df1
#按給定條件生成數組
df2 = np.where(df1['level'] >= 90,'高','低')
#將數組df2放到df1的第8列
df1.insert(7,'pingji',df2)#列名只能用英文字符或數字
df1
#自定義行標籤/索引增加行
df1.loc['aa'] = [1,2,3,4,5,6,7,8,9,10,11]
df1鄭州做人流醫院 http://3g.zyfuke.com/
#字典形式手動增加數據
df1.append([{'province':'廣東','city':'深圳'}],ignore_index = True)
#DF = df1.append([{'province':'廣東','city':'深圳'}],ignore_index = False)
#DF.loc[0,'city']#篩選行索引值爲 0 ,列索引值爲“city”的數據
#DataFrame合併
df3 = df1[0:2]
df1.append([df3],ignore_index = True)
#row_stack方法
arr1 = np.array([1,2,3,4,5,6,7,8,9,10,11])
arr2 = np.row_stack((df1,arr1))
df4 = pd.DataFrame(arr2)
df4
*****刪*****
#刪除上面 df4 的最後三行
dfa = df4.drop([9,10,11])
dfa
#按默認索引值刪除
df4.drop([9,10,11],inplace = True)
df4
#按行標籤刪除
df4.drop(labels=[0,1],inplace = True)
df4
#使用迭代器快速刪除多行
df4.drop(labels=range(3,8),inplace = True)#區間左閉右開
df4
#將df1的插入列“pingji”刪除
del df1['pingji']
df1
#取出df1中的“評級”列
PingJi = df1.pop('評級')
PingJi
df1
#刪除df1中的經緯度兩列
dfa = df1.drop(['lat','lng'],axis = 1,inplace = False)
dfa
*****改*****
#修改df1的dname值
df1.loc[df1['dname']=='外灘','dname'] = '上海外灘'
df1
#修改列標籤/列名/列索引值
df1.rename(columns = {'strategy':'攻略數','comment':'評論數'},inplace = True)
df1
#修改行標籤/行索引值
df1.rename(index = {2:2333,6:666},inplace = True)
df1
#重置索引
df1.reset_index(drop = True,inplace = True)
df1
*****查*****
#查找評論數大於20000的行
df1['評論數'] > 20000 #返回布爾值
df1[df1['評論數'] > 20000] #返回DataFrame
#查找相反條件
df1[~(df1['評論數'] > 20000)]
#查找評論數大於20000且攻略數小於1000的景點
df1[(df1['評論數'] > 20000) & (df1['攻略數'] < 1000)]
#between方法
df1['攻略數'].between(500,1500,inclusive = True) #返回布爾值
df1[df1['攻略數'].between(500,1500,inclusive = True)] #返回DataFrame
#isin方法
df1[ df1['評論數'].isin([35824,13811]) ]